Community structure
In the study of complex networks, a network is said to have community structure if the nodes of the network can be easily grouped into (potentially overlapping) sets of nodes such that each set of nodes is densely connected internally. In the particular case of non-overlapping community finding, this implies that the network divides naturally into groups of nodes with dense connections internally and sparser connections between groups. But overlapping communities are also allowed. The more general definition is based on the principle that pairs of nodes are more likely to be connected if they are both members of the same community(ies), and less likely to be connected if they do not share communities. A related but different problem is community search, where the goal is to find a community that a certain vertex belongs to.
| Part of a series on | ||||
| Network science | ||||
|---|---|---|---|---|
| Network types | ||||
| Graphs | ||||
|
||||
| Models | ||||
|
||||
| ||||
|
||||
Properties
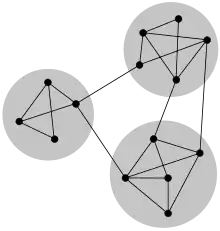
In the study of networks, such as computer and information networks, social networks and biological networks, a number of different characteristics have been found to occur commonly, including the small-world property, heavy-tailed degree distributions, and clustering, among others. Another common characteristic is community structure.[1][2][3][4][5] In the context of networks, community structure refers to the occurrence of groups of nodes in a network that are more densely connected internally than with the rest of the network, as shown in the example image to the right. This inhomogeneity of connections suggests that the network has certain natural divisions within it.
Communities are often defined in terms of the partition of the set of vertices, that is each node is put into one and only one community, just as in the figure. This is a useful simplification and most community detection methods find this type of community structure. However, in some cases a better representation could be one where vertices are in more than one community. This might happen in a social network where each vertex represents a person, and the communities represent the different groups of friends: one community for family, another community for co-workers, one for friends in the same sports club, and so on. The use of cliques for community detection discussed below is just one example of how such overlapping community structure can be found.
Some networks may not have any meaningful community structure. Many basic network models, for example, such as the random graph and the Barabási–Albert model, do not display community structure.
Importance
Community structures are quite common in real networks. Social networks include community groups (the origin of the term, in fact) based on common location, interests, occupation, etc.[5][6]
Finding an underlying community structure in a network, if it exists, is important for a number of reasons. Communities allow us to create a large scale map of a network since individual communities act like meta-nodes in the network which makes its study easier.[7]
Individual communities also shed light on the function of the system represented by the network since communities often correspond to functional units of the system. In metabolic networks, such functional groups correspond to cycles or pathways whereas in the protein interaction network, communities correspond to proteins with similar functionality inside a biological cell. Similarly, citation networks form communities by research topic.[1] Being able to identify these sub-structures within a network can provide insight into how network function and topology affect each other. Such insight can be useful in improving some algorithms on graphs such as spectral clustering.[8]
Importantly, communities often have very different properties than the average properties of the networks. Thus, only concentrating on the average properties usually misses many important and interesting features inside the networks. For example, in a given social network, both gregarious and reticent groups might exists simultaneously.[7]
Existence of communities also generally affects various processes like rumour spreading or epidemic spreading happening on a network. Hence to properly understand such processes, it is important to detect communities and also to study how they affect the spreading processes in various settings.
Finally, an important application that community detection has found in network science is the prediction of missing links and the identification of false links in the network. During the measurement process, some links may not get observed for a number of reasons. Similarly, some links could falsely enter into the data because of the errors in the measurement. Both these cases are well handled by community detection algorithm since it allows one to assign the probability of existence of an edge between a given pair of nodes.[9]
Algorithms for finding communities
Finding communities within an arbitrary network can be a computationally difficult task. The number of communities, if any, within the network is typically unknown and the communities are often of unequal size and/or density. Despite these difficulties, however, several methods for community finding have been developed and employed with varying levels of success.[4]
Minimum-cut method
One of the oldest algorithms for dividing networks into parts is the minimum cut method (and variants such as ratio cut and normalized cut). This method sees use, for example, in load balancing for parallel computing in order to minimize communication between processor nodes.
In the minimum-cut method, the network is divided into a predetermined number of parts, usually of approximately the same size, chosen such that the number of edges between groups is minimized. The method works well in many of the applications for which it was originally intended but is less than ideal for finding community structure in general networks since it will find communities regardless of whether they are implicit in the structure, and it will find only a fixed number of them.[10]
Hierarchical clustering
Another method for finding community structures in networks is hierarchical clustering. In this method one defines a similarity measure quantifying some (usually topological) type of similarity between node pairs. Commonly used measures include the cosine similarity, the Jaccard index, and the Hamming distance between rows of the adjacency matrix. Then one groups similar nodes into communities according to this measure. There are several common schemes for performing the grouping, the two simplest being single-linkage clustering, in which two groups are considered separate communities if and only if all pairs of nodes in different groups have similarity lower than a given threshold, and complete linkage clustering, in which all nodes within every group have similarity greater than a threshold. An important step is how to determine the threshold to stop the agglomerative clustering, indicating a near-to-optimal community structure. A common strategy consist to build one or several metrics monitoring global properties of the network, which peak at given step of the clustering. An interesting approach in this direction is the use of various similarity or dissimilarity measures, combined through convex sums,[11]. Another approximation is the computation of a quantity monitoring the density of edges within clusters with respect to the density between clusters, such as the partition density, which has been proposed when the similarity metric is defined between edges (which permits the definition of overlapping communities),[12] and extended when the similarity is defined between nodes, which allows to consider alternative definitions of communities such as guilds (i.e. groups of nodes sharing a similar number of links with respect to the same neighbours but not necessarily connected themselves).[13] These methods can be extended to consider multidimensional networks, for instance when we are dealing with networks having nodes with different types of links.[13]
Girvan–Newman algorithm
Another commonly used algorithm for finding communities is the Girvan–Newman algorithm.[1] This algorithm identifies edges in a network that lie between communities and then removes them, leaving behind just the communities themselves. The identification is performed by employing the graph-theoretic measure betweenness centrality, which assigns a number to each edge which is large if the edge lies "between" many pairs of nodes.
The Girvan–Newman algorithm returns results of reasonable quality and is popular because it has been implemented in a number of standard software packages. But it also runs slowly, taking time O(m2n) on a network of n vertices and m edges, making it impractical for networks of more than a few thousand nodes.[14]
Modularity maximization
In spite of its known drawbacks, one of the most widely used methods for community detection is modularity maximization.[14] Modularity is a benefit function that measures the quality of a particular division of a network into communities. The modularity maximization method detects communities by searching over possible divisions of a network for one or more that have particularly high modularity. Since exhaustive search over all possible divisions is usually intractable, practical algorithms are based on approximate optimization methods such as greedy algorithms, simulated annealing, or spectral optimization, with different approaches offering different balances between speed and accuracy.[15][16] A popular modularity maximization approach is the Louvain method, which iteratively optimizes local communities until global modularity can no longer be improved given perturbations to the current community state.[17][18] An algorithm that utilizes the RenEEL scheme, which is an example of the Extremal Ensemble Learning (EEL) paradigm, is currently the best modularity maximizing algorithm.[19] [20]
The usefulness of modularity optimization is questionable, as it has been shown that modularity optimization often fails to detect clusters smaller than some scale, depending on the size of the network (resolution limit[21]); on the other hand the landscape of modularity values is characterized by a huge degeneracy of partitions with high modularity, close to the absolute maximum, which may be very different from each other.[22]
Statistical inference
Methods based on statistical inference attempt to fit a generative model to the network data, which encodes the community structure. The overall advantage of this approach compared to the alternatives is its more principled nature, and the capacity to inherently address issues of statistical significance. Most methods in the literature are based on the stochastic block model[23] as well as variants including mixed membership,[24][25] degree-correction,[26] and hierarchical structures.[27] Model selection can be performed using principled approaches such as minimum description length[28][29] (or equivalently, Bayesian model selection[30]) and likelihood-ratio test.[31] Currently many algorithms exist to perform efficient inference of stochastic block models, including belief propagation[32][33] and agglomerative Monte Carlo.[34]
In contrast to approaches that attempt to cluster a network given an objective function, this class of methods is based on generative models, which not only serve as a description of the large-scale structure of the network, but also can be used to generalize the data and predict the occurrence of missing or spurious links in the network.[35][36]
Clique-based methods
Cliques are subgraphs in which every node is connected to every other node in the clique. As nodes can not be more tightly connected than this, it is not surprising that there are many approaches to community detection in networks based on the detection of cliques in a graph and the analysis of how these overlap. Note that as a node can be a member of more than one clique, a node can be a member of more than one community in these methods giving an "overlapping community structure".
One approach is to find the "maximal cliques". That is to find the cliques which are not the subgraph of any other clique. The classic algorithm to find these is the Bron–Kerbosch algorithm. The overlap of these can be used to define communities in several ways. The simplest is to consider only maximal cliques bigger than a minimum size (number of nodes). The union of these cliques then defines a subgraph whose components (disconnected parts) then define communities.[37] Such approaches are often implemented in social network analysis software such as UCInet.
The alternative approach is to use cliques of fixed size . The overlap of these can be used to define a type of -regular hypergraph or a structure which is a generalisation of the line graph (the case when ) known as a "Clique graph".[38] The clique graphs have vertices which represent the cliques in the original graph while the edges of the clique graph record the overlap of the clique in the original graph. Applying any of the previous community detection methods (which assign each node to a community) to the clique graph then assigns each clique to a community. This can then be used to determine community membership of nodes in the cliques. Again as a node may be in several cliques, it can be a member of several communities. For instance the clique percolation method[39] defines communities as percolation clusters of -cliques. To do this it finds all -cliques in a network, that is all the complete sub-graphs of -nodes. It then defines two -cliques to be adjacent if they share nodes, that is this is used to define edges in a clique graph. A community is then defined to be the maximal union of -cliques in which we can reach any -clique from any other -clique through series of -clique adjacencies. That is communities are just the connected components in the clique graph. Since a node can belong to several different -clique percolation clusters at the same time, the communities can overlap with each other.



Community detection in latent feature spaces
A network can be represented or projected onto a latent space via representation learning methods to efficiently represent a system. Then, various clustering methods can be employed to detect community structures. For Euclidean spaces, methods like embedding-based Silhouette community detection[40] can be utilized. For Hypergeometric latent spaces, critical gap method or modified density-based, hierarchical, or partitioning-based clustering methods can be utilized.[41]
Testing methods of finding communities algorithms
The evaluation of algorithms, to detect which are better at detecting community structure, is still an open question. It must be based on analyses of networks of known structure. A typical example is the "four groups" test, in which a network is divided into four equally-sized groups (usually of 32 nodes each) and the probabilities of connection within and between groups varied to create more or less challenging structures for the detection algorithm. Such benchmark graphs are a special case of the planted l-partition model[42] of Condon and Karp, or more generally of "stochastic block models", a general class of random network models containing community structure. Other more flexible benchmarks have been proposed that allow for varying group sizes and nontrivial degree distributions, such as LFR benchmark[43] [44] which is an extension of the four groups benchmark that includes heterogeneous distributions of node degree and community size, making it a more severe test of community detection methods.[45][46]
Commonly used computer-generated benchmarks start with a network of well-defined communities. Then, this structure is degraded by rewiring or removing links and it gets harder and harder for the algorithms to detect the original partition. At the end, the network reaches a point where it is essentially random. This kind of benchmark may be called "open". The performance on these benchmarks is evaluated by measures such as normalized mutual information or variation of information. They compare the solution obtained by an algorithm [44] with the original community structure, evaluating the similarity of both partitions.
Detectability
During recent years, a rather surprising result has been obtained by various groups which shows that a phase transition exists in the community detection problem, showing that as the density of connections inside communities and between communities become more and more equal or both become smaller (equivalently, as the community structure becomes too weak or the network becomes too sparse), suddenly the communities become undetectable. In a sense, the communities themselves still exist, since the presence and absence of edges is still correlated with the community memberships of their endpoints; but it becomes information-theoretically impossible to label the nodes better than chance, or even distinguish the graph from one generated by a null model such as the Erdos–Renyi model without community structure. This transition is independent of the type of algorithm being used to detect communities, implying that there exists a fundamental limit on our ability to detect communities in networks, even with optimal Bayesian inference (i.e., regardless of our computational resources).[47][48][49]
Consider a stochastic block model with total nodes, groups of equal size, and let and be the connection probabilities inside and between the groups respectively. If , the network would possess community structure since the link density inside the groups would be more than the density of links between the groups. In the sparse case, and scale as so that the average degree is constant:






- and


Then it becomes impossible to detect the communities when:[48]

References
- M. Girvan; M. E. J. Newman (2002). "Community structure in social and biological networks". Proc. Natl. Acad. Sci. USA. 99 (12): 7821–7826. arXiv:cond-mat/0112110. Bibcode:2002PNAS...99.7821G. doi:10.1073/pnas.122653799. PMC 122977. PMID 12060727.
- S. Fortunato (2010). "Community detection in graphs". Phys. Rep. 486 (3–5): 75–174. arXiv:0906.0612. Bibcode:2010PhR...486...75F. doi:10.1016/j.physrep.2009.11.002. S2CID 10211629.
- F. D. Malliaros; M. Vazirgiannis (2013). "Clustering and community detection in directed networks: A survey". Phys. Rep. 533 (4): 95–142. arXiv:1308.0971. Bibcode:2013PhR...533...95M. doi:10.1016/j.physrep.2013.08.002. S2CID 15006738.
- M. A. Porter; J.-P. Onnela; P. J. Mucha (2009). "Communities in Networks" (PDF). Notices of the American Mathematical Society. 56: 1082–1097, 1164–1166. Archived (PDF) from the original on 2021-06-13. Retrieved 2021-04-28.
- Fani, Hossein; Bagheri, Ebrahim (2017). "Community detection in social networks". Encyclopedia with Semantic Computing and Robotic Intelligence. Vol. 1. pp. 1630001 [8]. doi:10.1142/S2425038416300019. S2CID 52471002.
- Hamdaqa, Mohammad; Tahvildari, Ladan; LaChapelle, Neil; Campbell, Brian (2014). "Cultural Scene Detection Using Reverse Louvain Optimization". Science of Computer Programming. 95: 44–72. doi:10.1016/j.scico.2014.01.006. Archived from the original on 2020-08-07. Retrieved 2019-08-29.
- M.E.J.Neman (2006). "Finding community structure in networks using the eigenvectors of matrices". Phys. Rev. E. 74 (3): 1–19. arXiv:physics/0605087. Bibcode:2006PhRvE..74c6104N. doi:10.1103/PhysRevE.74.036104. PMID 17025705. S2CID 138996.
- Zare, Habil; P. Shooshtari; A. Gupta; R. Brinkman (2010). "Data reduction for spectral clustering to analyze high throughput flow cytometry data". BMC Bioinformatics. 11 (1): 403. doi:10.1186/1471-2105-11-403. PMC 2923634. PMID 20667133.
- Aaron Clauset; Cristopher Moore; M.E.J. Newman (2008). "Hierarchical structure and the prediction of missing links in networks". Nature. 453 (7191): 98–101. arXiv:0811.0484. Bibcode:2008Natur.453...98C. doi:10.1038/nature06830. PMID 18451861. S2CID 278058.
- M. E. J. Newman (2004). "Detecting community structure in networks". Eur. Phys. J. B. 38 (2): 321–330. Bibcode:2004EPJB...38..321N. doi:10.1140/epjb/e2004-00124-y. hdl:2027.42/43867. S2CID 15412738.
- Alvarez, Alejandro J.; Sanz-Rodríguez, Carlos E.; Cabrera, Juan Luis (2015-12-13). "Weighting dissimilarities to detect communities in networks". Phil. Trans. R. Soc. A. 373 (2056): 20150108. Bibcode:2015RSPTA.37350108A. doi:10.1098/rsta.2015.0108. ISSN 1364-503X. PMID 26527808.
- Ahn, Y.-Y.; Bagrow, J.P.; Lehmann, S. (2010). "Link communities reveal multi-scale complexity in networks". Nature. 466 (7307): 761–764. arXiv:0903.3178. Bibcode:2010Natur.466..761A. doi:10.1038/nature09182. PMID 20562860. S2CID 4404822.
- Pascual-García, Alberto; Bell, Thomas (2020). "functionInk: An efficient method to detect functional groups in multidimensional networks reveals the hidden structure of ecological communities". Methods Ecol Evol. 11 (7): 804–817. doi:10.1111/2041-210X.13377. S2CID 214033410.
- M. E. J. Newman (2004). "Fast algorithm for detecting community structure in networks". Phys. Rev. E. 69 (6): 066133. arXiv:cond-mat/0309508. Bibcode:2004PhRvE..69f6133N. doi:10.1103/PhysRevE.69.066133. PMID 15244693. S2CID 301750.
- L. Danon; J. Duch; A. Díaz-Guilera; A. Arenas (2005). "Comparing community structure identification". J. Stat. Mech. 2005 (9): P09008. arXiv:cond-mat/0505245. Bibcode:2005JSMTE..09..008D. doi:10.1088/1742-5468/2005/09/P09008. S2CID 14798969.
- R. Guimera; L. A. N. Amaral (2005). "Functional cartography of complex metabolic networks". Nature. 433 (7028): 895–900. arXiv:q-bio/0502035. Bibcode:2005Natur.433..895G. doi:10.1038/nature03288. PMC 2175124. PMID 15729348.
- V.D. Blondel; J.-L. Guillaume; R. Lambiotte; E. Lefebvre (2008). "Fast unfolding of community hierarchies in large networks". J. Stat. Mech. 2008 (10): P10008. arXiv:0803.0476. Bibcode:2008JSMTE..10..008B. doi:10.1088/1742-5468/2008/10/P10008. S2CID 334423.
- "Lightning-fast Community Detection in Social Media: A Scalable Implementation of the Louvain Algorithm" (PDF). Auburn University. 2013. S2CID 16164925.
- J. Guo; P. Singh; K.E. Bassler (2019). "Reduced network extremal ensemble learning (RenEEL) scheme for community detection in complex networks". Scientific Reports. 9 (14234): 14234. arXiv:1909.10491. Bibcode:2019NatSR...914234G. doi:10.1038/s41598-019-50739-3. PMC 6775136. PMID 31578406.
- "RenEEL-Modularity". GitHub. 31 October 2019. Archived from the original on 1 January 2021. Retrieved 4 November 2019.
- S. Fortunato; M. Barthelemy (2007). "Resolution limit in community detection". Proceedings of the National Academy of Sciences of the United States of America. 104 (1): 36–41. arXiv:physics/0607100. Bibcode:2007PNAS..104...36F. doi:10.1073/pnas.0605965104. PMC 1765466. PMID 17190818.
- B. H. Good; Y.-A. de Montjoye; A. Clauset (2010). "The performance of modularity maximization in practical contexts". Phys. Rev. E. 81 (4): 046106. arXiv:0910.0165. Bibcode:2010PhRvE..81d6106G. doi:10.1103/PhysRevE.81.046106. PMID 20481785. S2CID 16564204.
- Holland, Paul W.; Kathryn Blackmond Laskey; Samuel Leinhardt (June 1983). "Stochastic blockmodels: First steps". Social Networks. 5 (2): 109–137. doi:10.1016/0378-8733(83)90021-7. ISSN 0378-8733. S2CID 34098453.
- Airoldi, Edoardo M.; David M. Blei; Stephen E. Fienberg; Eric P. Xing (June 2008). "Mixed Membership Stochastic Blockmodels". J. Mach. Learn. Res. 9: 1981–2014. ISSN 1532-4435. PMC 3119541. PMID 21701698. Archived from the original on 2018-11-21. Retrieved 2013-10-09.
- Ball, Brian; Brian Karrer; M. E. J. Newman (2011). "Efficient and principled method for detecting communities in networks". Physical Review E. 84 (3): 036103. arXiv:1104.3590. Bibcode:2011PhRvE..84c6103B. doi:10.1103/PhysRevE.84.036103. PMID 22060452. S2CID 14204351.
- Karrer, Brian; M. E. J. Newman (2011-01-21). "Stochastic blockmodels and community structure in networks". Physical Review E. 83 (1): 016107. arXiv:1008.3926. Bibcode:2011PhRvE..83a6107K. doi:10.1103/PhysRevE.83.016107. PMID 21405744. S2CID 9068097.
- Peixoto, Tiago P. (2014-03-24). "Hierarchical Block Structures and High-Resolution Model Selection in Large Networks". Physical Review X. 4 (1): 011047. arXiv:1310.4377. Bibcode:2014PhRvX...4a1047P. doi:10.1103/PhysRevX.4.011047. S2CID 5841379.
- Martin Rosvall; Carl T. Bergstrom (2007). "An information-theoretic framework for resolving community structure in complex networks". Proceedings of the National Academy of Sciences of the United States of America. 104 (18): 7327–7331. arXiv:physics/0612035. Bibcode:2007PNAS..104.7327R. doi:10.1073/pnas.0611034104. PMC 1855072. PMID 17452639.
- P. Peixoto, T. (2013). "Parsimonious Module Inference in Large Networks". Phys. Rev. Lett. 110 (14): 148701. arXiv:1212.4794. Bibcode:2013PhRvL.110n8701P. doi:10.1103/PhysRevLett.110.148701. PMID 25167049. S2CID 2668815.
- P. Peixoto, T. (2019). "Bayesian stochastic blockmodeling". Advances in Network Clustering and Blockmodeling. pp. 289–332. arXiv:1705.10225. doi:10.1002/9781119483298.ch11. ISBN 978-1-119-22470-9. S2CID 62900189.
- Yan, Xiaoran; Jacob E. Jensen; Florent Krzakala; Cristopher Moore; Cosma Rohilla Shalizi; Lenka Zdeborová; Pan Zhang; Yaojia Zhu (2012-07-17). "Model Selection for Degree-corrected Block Models". Journal of Statistical Mechanics: Theory and Experiment. 2014 (5): P05007. arXiv:1207.3994. Bibcode:2014JSMTE..05..007Y. doi:10.1088/1742-5468/2014/05/P05007. PMC 4498413. PMID 26167197.
- Gopalan, Prem K.; David M. Blei (2013-09-03). "Efficient discovery of overlapping communities in massive networks". Proceedings of the National Academy of Sciences. 110 (36): 14534–14539. Bibcode:2013PNAS..11014534G. doi:10.1073/pnas.1221839110. ISSN 0027-8424. PMC 3767539. PMID 23950224.
- Decelle, Aurelien; Florent Krzakala; Cristopher Moore; Lenka Zdeborová (2011-12-12). "Asymptotic analysis of the stochastic block model for modular networks and its algorithmic applications". Physical Review E. 84 (6): 066106. arXiv:1109.3041. Bibcode:2011PhRvE..84f6106D. doi:10.1103/PhysRevE.84.066106. PMID 22304154. S2CID 15788070.
- Peixoto, Tiago P. (2014-01-13). "Efficient Monte Carlo and greedy heuristic for the inference of stochastic block models". Physical Review E. 89 (1): 012804. arXiv:1310.4378. Bibcode:2014PhRvE..89a2804P. doi:10.1103/PhysRevE.89.012804. PMID 24580278. S2CID 2674083.
- Guimerà, Roger; Marta Sales-Pardo (2009-12-29). "Missing and spurious interactions and the reconstruction of complex networks". Proceedings of the National Academy of Sciences. 106 (52): 22073–22078. arXiv:1004.4791. Bibcode:2009PNAS..10622073G. doi:10.1073/pnas.0908366106. PMC 2799723. PMID 20018705.
- Clauset, Aaron; Cristopher Moore; M. E. J. Newman (2008-05-01). "Hierarchical structure and the prediction of missing links in networks". Nature. 453 (7191): 98–101. arXiv:0811.0484. Bibcode:2008Natur.453...98C. doi:10.1038/nature06830. ISSN 0028-0836. PMID 18451861. S2CID 278058.
- M.G. Everett; S.P. Borgatti (1998). "Analyzing Clique Overlap Connections". Connections. 21: 49.
- T.S. Evans (2010). "Clique Graphs and Overlapping Communities". J. Stat. Mech. 2010 (12): P12037. arXiv:1009.0638. Bibcode:2010JSMTE..12..037E. doi:10.1088/1742-5468/2010/12/P12037. S2CID 2783670.
- G. Palla; I. Derényi; I. Farkas; T. Vicsek (2005). "Uncovering the overlapping community structure of complex networks in nature and society". Nature. 435 (7043): 814–818. arXiv:physics/0506133. Bibcode:2005Natur.435..814P. doi:10.1038/nature03607. PMID 15944704. S2CID 3250746.
- Škrlj, Blaž; Kralj, Jan; Lavrač, Nada (2020-11-01). "Embedding-based Silhouette community detection". Machine Learning. 109 (11): 2161–2193. doi:10.1007/s10994-020-05882-8. ISSN 1573-0565. PMC 7652809. PMID 33191975.
- Bruno, Matteo (21 Jun 2019). "Community Detection in the Hyperbolic Space". arXiv:1906.09082 [physics.soc-ph].
- Condon, A.; Karp, R. M. (2001). "Algorithms for graph partitioning on the planted partition model". Random Struct. Algor. 18 (2): 116–140. CiteSeerX 10.1.1.22.4340. doi:10.1002/1098-2418(200103)18:2<116::AID-RSA1001>3.0.CO;2-2.
- A. Lancichinetti; S. Fortunato; F. Radicchi (2008). "Benchmark graphs for testing community detection algorithms". Phys. Rev. E. 78 (4): 046110. arXiv:0805.4770. Bibcode:2008PhRvE..78d6110L. doi:10.1103/PhysRevE.78.046110. PMID 18999496. S2CID 18481617.
- Fathi, Reza (April 2019). "Efficient Distributed Community Detection in the Stochastic Block Model". arXiv:1904.07494 [cs.DC].
- M. Q. Pasta; F. Zaidi (2017). "Leveraging Evolution Dynamics to Generate Benchmark Complex Networks with Community Structures". arXiv:1606.01169 [cs.SI].
- Pasta, M. Q.; Zaidi, F. (2017). "Topology of Complex Networks and Performance Limitations of Community Detection Algorithms". IEEE Access. 5: 10901–10914. doi:10.1109/ACCESS.2017.2714018.
- Reichardt, J.; Leone, M. (2008). "(Un)detectable Cluster Structure in Sparse Networks". Phys. Rev. Lett. 101 (78701): 1–4. arXiv:0711.1452. Bibcode:2008PhRvL.101g8701R. doi:10.1103/PhysRevLett.101.078701. PMID 18764586. S2CID 41197281.
- Decelle, A.; Krzakala, F.; Moore, C.; Zdeborová, L. (2011). "Inference and Phase Transitions in the Detection of Modules in Sparse Networks". Phys. Rev. Lett. 107 (65701): 1–5. arXiv:1102.1182. Bibcode:2011PhRvL.107f5701D. doi:10.1103/PhysRevLett.107.065701. PMID 21902340. S2CID 18399723.
- Nadakuditi, R.R; Newman, M.E.J. (2012). "Graph Spectra and the Detectability of Community Structure in Networks". Phys. Rev. Lett. 108 (188701): 1–5. arXiv:1205.1813. Bibcode:2012PhRvL.108r8701N. doi:10.1103/PhysRevLett.108.188701. PMID 22681123. S2CID 11820036.