Microarchitecture
In electronics, computer science and computer engineering, microarchitecture, also called computer organization and sometimes abbreviated as µarch or uarch, is the way a given instruction set architecture (ISA) is implemented in a particular processor.[1] A given ISA may be implemented with different microarchitectures;[2][3] implementations may vary due to different goals of a given design or due to shifts in technology.[4]
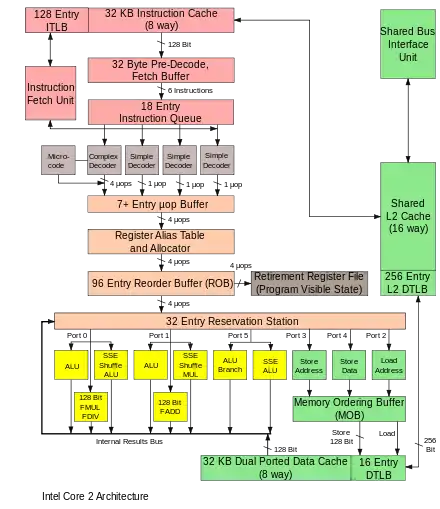
Computer architecture is the combination of microarchitecture and instruction set architecture.
Relation to instruction set architecture
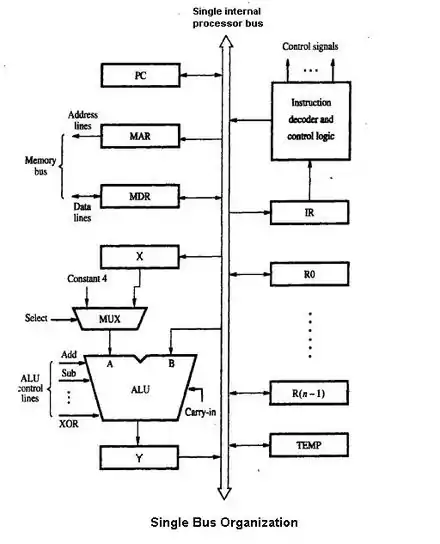
The ISA is roughly the same as the programming model of a processor as seen by an assembly language programmer or compiler writer. The ISA includes the instructions, execution model, processor registers, address and data formats among other things. The microarchitecture includes the constituent parts of the processor and how these interconnect and interoperate to implement the ISA.
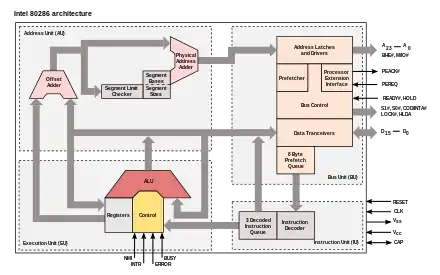
The microarchitecture of a machine is usually represented as (more or less detailed) diagrams that describe the interconnections of the various microarchitectural elements of the machine, which may be anything from single gates and registers, to complete arithmetic logic units (ALUs) and even larger elements. These diagrams generally separate the datapath (where data is placed) and the control path (which can be said to steer the data).[5]
The person designing a system usually draws the specific microarchitecture as a kind of data flow diagram. Like a block diagram, the microarchitecture diagram shows microarchitectural elements such as the arithmetic and logic unit and the register file as a single schematic symbol. Typically, the diagram connects those elements with arrows, thick lines and thin lines to distinguish between three-state buses (which require a three-state buffer for each device that drives the bus), unidirectional buses (always driven by a single source, such as the way the address bus on simpler computers is always driven by the memory address register), and individual control lines. Very simple computers have a single data bus organization – they have a single three-state bus. The diagram of more complex computers usually shows multiple three-state buses, which help the machine do more operations simultaneously.
Each microarchitectural element is in turn represented by a schematic describing the interconnections of logic gates used to implement it. Each logic gate is in turn represented by a circuit diagram describing the connections of the transistors used to implement it in some particular logic family. Machines with different microarchitectures may have the same instruction set architecture, and thus be capable of executing the same programs. New microarchitectures and/or circuitry solutions, along with advances in semiconductor manufacturing, are what allows newer generations of processors to achieve higher performance while using the same ISA.
In principle, a single microarchitecture could execute several different ISAs with only minor changes to the microcode.
Aspects
The pipelined datapath is the most commonly used datapath design in microarchitecture today. This technique is used in most modern microprocessors, microcontrollers, and DSPs. The pipelined architecture allows multiple instructions to overlap in execution, much like an assembly line. The pipeline includes several different stages which are fundamental in microarchitecture designs.[5] Some of these stages include instruction fetch, instruction decode, execute, and write back. Some architectures include other stages such as memory access. The design of pipelines is one of the central microarchitectural tasks.
Execution units are also essential to microarchitecture. Execution units include arithmetic logic units (ALU), floating point units (FPU), load/store units, branch prediction, and SIMD. These units perform the operations or calculations of the processor. The choice of the number of execution units, their latency and throughput is a central microarchitectural design task. The size, latency, throughput and connectivity of memories within the system are also microarchitectural decisions.
System-level design decisions such as whether or not to include peripherals, such as memory controllers, can be considered part of the microarchitectural design process. This includes decisions on the performance-level and connectivity of these peripherals.
Unlike architectural design, where achieving a specific performance level is the main goal, microarchitectural design pays closer attention to other constraints. Since microarchitecture design decisions directly affect what goes into a system, attention must be paid to issues such as chip area/cost, power consumption, logic complexity, ease of connectivity, manufacturability, ease of debugging, and testability.
Microarchitectural concepts
Instruction cycles
To run programs, all single- or multi-chip CPUs:
- Read an instruction and decode it
- Find any associated data that is needed to process the instruction
- Process the instruction
- Write the results out
The instruction cycle is repeated continuously until the power is turned off.
Multicycle microarchitecture
Historically, the earliest computers were multicycle designs. The smallest, least-expensive computers often still use this technique. Multicycle architectures often use the least total number of logic elements and reasonable amounts of power. They can be designed to have deterministic timing and high reliability. In particular, they have no pipeline to stall when taking conditional branches or interrupts. However, other microarchitectures often perform more instructions per unit time, using the same logic family. When discussing "improved performance," an improvement is often relative to a multicycle design.
In a multicycle computer, the computer does the four steps in sequence, over several cycles of the clock. Some designs can perform the sequence in two clock cycles by completing successive stages on alternate clock edges, possibly with longer operations occurring outside the main cycle. For example, stage one on the rising edge of the first cycle, stage two on the falling edge of the first cycle, etc.
In the control logic, the combination of cycle counter, cycle state (high or low) and the bits of the instruction decode register determine exactly what each part of the computer should be doing. To design the control logic, one can create a table of bits describing the control signals to each part of the computer in each cycle of each instruction. Then, this logic table can be tested in a software simulation running test code. If the logic table is placed in a memory and used to actually run a real computer, it is called a microprogram. In some computer designs, the logic table is optimized into the form of combinational logic made from logic gates, usually using a computer program that optimizes logic. Early computers used ad-hoc logic design for control until Maurice Wilkes invented this tabular approach and called it microprogramming.[6]
Increasing execution speed
Complicating this simple-looking series of steps is the fact that the memory hierarchy, which includes caching, main memory and non-volatile storage like hard disks (where the program instructions and data reside), has always been slower than the processor itself. Step (2) often introduces a lengthy (in CPU terms) delay while the data arrives over the computer bus. A considerable amount of research has been put into designs that avoid these delays as much as possible. Over the years, a central goal was to execute more instructions in parallel, thus increasing the effective execution speed of a program. These efforts introduced complicated logic and circuit structures. Initially, these techniques could only be implemented on expensive mainframes or supercomputers due to the amount of circuitry needed for these techniques. As semiconductor manufacturing progressed, more and more of these techniques could be implemented on a single semiconductor chip. See Moore's law.
Instruction set choice
Instruction sets have shifted over the years, from originally very simple to sometimes very complex (in various respects). In recent years, load–store architectures, VLIW and EPIC types have been in fashion. Architectures that are dealing with data parallelism include SIMD and Vectors. Some labels used to denote classes of CPU architectures are not particularly descriptive, especially so the CISC label; many early designs retroactively denoted "CISC" are in fact significantly simpler than modern RISC processors (in several respects).
However, the choice of instruction set architecture may greatly affect the complexity of implementing high-performance devices. The prominent strategy, used to develop the first RISC processors, was to simplify instructions to a minimum of individual semantic complexity combined with high encoding regularity and simplicity. Such uniform instructions were easily fetched, decoded and executed in a pipelined fashion and a simple strategy to reduce the number of logic levels in order to reach high operating frequencies; instruction cache-memories compensated for the higher operating frequency and inherently low code density while large register sets were used to factor out as much of the (slow) memory accesses as possible.
Instruction pipelining
One of the first, and most powerful, techniques to improve performance is the use of instruction pipelining. Early processor designs would carry out all of the steps above for one instruction before moving onto the next. Large portions of the circuitry were left idle at any one step; for instance, the instruction decoding circuitry would be idle during execution and so on.
Pipelining improves performance by allowing a number of instructions to work their way through the processor at the same time. In the same basic example, the processor would start to decode (step 1) a new instruction while the last one was waiting for results. This would allow up to four instructions to be "in flight" at one time, making the processor look four times as fast. Although any one instruction takes just as long to complete (there are still four steps) the CPU as a whole "retires" instructions much faster.
RISC makes pipelines smaller and much easier to construct by cleanly separating each stage of the instruction process and making them take the same amount of time—one cycle. The processor as a whole operates in an assembly line fashion, with instructions coming in one side and results out the other. Due to the reduced complexity of the classic RISC pipeline, the pipelined core and an instruction cache could be placed on the same size die that would otherwise fit the core alone on a CISC design. This was the real reason that RISC was faster. Early designs like the SPARC and MIPS often ran over 10 times as fast as Intel and Motorola CISC solutions at the same clock speed and price.
Pipelines are by no means limited to RISC designs. By 1986 the top-of-the-line VAX implementation (VAX 8800) was a heavily pipelined design, slightly predating the first commercial MIPS and SPARC designs. Most modern CPUs (even embedded CPUs) are now pipelined, and microcoded CPUs with no pipelining are seen only in the most area-constrained embedded processors. Large CISC machines, from the VAX 8800 to the modern Pentium 4 and Athlon, are implemented with both microcode and pipelines. Improvements in pipelining and caching are the two major microarchitectural advances that have enabled processor performance to keep pace with the circuit technology on which they are based.
Cache
It was not long before improvements in chip manufacturing allowed for even more circuitry to be placed on the die, and designers started looking for ways to use it. One of the most common was to add an ever-increasing amount of cache memory on-die. Cache is very fast and expensive memory. It can be accessed in a few cycles as opposed to many needed to "talk" to main memory. The CPU includes a cache controller which automates reading and writing from the cache. If the data is already in the cache it is accessed from there – at considerable time savings, whereas if it is not the processor is "stalled" while the cache controller reads it in.
RISC designs started adding cache in the mid-to-late 1980s, often only 4 KB in total. This number grew over time, and typical CPUs now have at least 2 MB, while more powerful CPUs come with 4 or 6 or 12MB or even 32MB or more, with the most being 768MB in the newly released EPYC Milan-X line, organized in multiple levels of a memory hierarchy. Generally speaking, more cache means more performance, due to reduced stalling.
Caches and pipelines were a perfect match for each other. Previously, it didn't make much sense to build a pipeline that could run faster than the access latency of off-chip memory. Using on-chip cache memory instead, meant that a pipeline could run at the speed of the cache access latency, a much smaller length of time. This allowed the operating frequencies of processors to increase at a much faster rate than that of off-chip memory.
Branch prediction
One barrier to achieving higher performance through instruction-level parallelism stems from pipeline stalls and flushes due to branches. Normally, whether a conditional branch will be taken isn't known until late in the pipeline as conditional branches depend on results coming from a register. From the time that the processor's instruction decoder has figured out that it has encountered a conditional branch instruction to the time that the deciding register value can be read out, the pipeline needs to be stalled for several cycles, or if it's not and the branch is taken, the pipeline needs to be flushed. As clock speeds increase the depth of the pipeline increases with it, and some modern processors may have 20 stages or more. On average, every fifth instruction executed is a branch, so without any intervention, that's a high amount of stalling.
Techniques such as branch prediction and speculative execution are used to lessen these branch penalties. Branch prediction is where the hardware makes educated guesses on whether a particular branch will be taken. In reality one side or the other of the branch will be called much more often than the other. Modern designs have rather complex statistical prediction systems, which watch the results of past branches to predict the future with greater accuracy. The guess allows the hardware to prefetch instructions without waiting for the register read. Speculative execution is a further enhancement in which the code along the predicted path is not just prefetched but also executed before it is known whether the branch should be taken or not. This can yield better performance when the guess is good, with the risk of a huge penalty when the guess is bad because instructions need to be undone.
Superscalar
Even with all of the added complexity and gates needed to support the concepts outlined above, improvements in semiconductor manufacturing soon allowed even more logic gates to be used.
In the outline above the processor processes parts of a single instruction at a time. Computer programs could be executed faster if multiple instructions were processed simultaneously. This is what superscalar processors achieve, by replicating functional units such as ALUs. The replication of functional units was only made possible when the die area of a single-issue processor no longer stretched the limits of what could be reliably manufactured. By the late 1980s, superscalar designs started to enter the market place.
In modern designs it is common to find two load units, one store (many instructions have no results to store), two or more integer math units, two or more floating point units, and often a SIMD unit of some sort. The instruction issue logic grows in complexity by reading in a huge list of instructions from memory and handing them off to the different execution units that are idle at that point. The results are then collected and re-ordered at the end.
Out-of-order execution
The addition of caches reduces the frequency or duration of stalls due to waiting for data to be fetched from the memory hierarchy, but does not get rid of these stalls entirely. In early designs a cache miss would force the cache controller to stall the processor and wait. Of course there may be some other instruction in the program whose data is available in the cache at that point. Out-of-order execution allows that ready instruction to be processed while an older instruction waits on the cache, then re-orders the results to make it appear that everything happened in the programmed order. This technique is also used to avoid other operand dependency stalls, such as an instruction awaiting a result from a long latency floating-point operation or other multi-cycle operations.
Register renaming
Register renaming refers to a technique used to avoid unnecessary serialized execution of program instructions because of the reuse of the same registers by those instructions. Suppose we have two groups of instruction that will use the same register. One set of instructions is executed first to leave the register to the other set, but if the other set is assigned to a different similar register, both sets of instructions can be executed in parallel (or) in series.
Multiprocessing and multithreading
Computer architects have become stymied by the growing mismatch in CPU operating frequencies and DRAM access times. None of the techniques that exploited instruction-level parallelism (ILP) within one program could make up for the long stalls that occurred when data had to be fetched from main memory. Additionally, the large transistor counts and high operating frequencies needed for the more advanced ILP techniques required power dissipation levels that could no longer be cheaply cooled. For these reasons, newer generations of computers have started to exploit higher levels of parallelism that exist outside of a single program or program thread.
This trend is sometimes known as throughput computing. This idea originated in the mainframe market where online transaction processing emphasized not just the execution speed of one transaction, but the capacity to deal with massive numbers of transactions. With transaction-based applications such as network routing and web-site serving greatly increasing in the last decade, the computer industry has re-emphasized capacity and throughput issues.
One technique of how this parallelism is achieved is through multiprocessing systems, computer systems with multiple CPUs. Once reserved for high-end mainframes and supercomputers, small-scale (2–8) multiprocessors servers have become commonplace for the small business market. For large corporations, large scale (16–256) multiprocessors are common. Even personal computers with multiple CPUs have appeared since the 1990s.
With further transistor size reductions made available with semiconductor technology advances, multi-core CPUs have appeared where multiple CPUs are implemented on the same silicon chip. Initially used in chips targeting embedded markets, where simpler and smaller CPUs would allow multiple instantiations to fit on one piece of silicon. By 2005, semiconductor technology allowed dual high-end desktop CPUs CMP chips to be manufactured in volume. Some designs, such as Sun Microsystems' UltraSPARC T1 have reverted to simpler (scalar, in-order) designs in order to fit more processors on one piece of silicon.
Another technique that has become more popular recently is multithreading. In multithreading, when the processor has to fetch data from slow system memory, instead of stalling for the data to arrive, the processor switches to another program or program thread which is ready to execute. Though this does not speed up a particular program/thread, it increases the overall system throughput by reducing the time the CPU is idle.
Conceptually, multithreading is equivalent to a context switch at the operating system level. The difference is that a multithreaded CPU can do a thread switch in one CPU cycle instead of the hundreds or thousands of CPU cycles a context switch normally requires. This is achieved by replicating the state hardware (such as the register file and program counter) for each active thread.
A further enhancement is simultaneous multithreading. This technique allows superscalar CPUs to execute instructions from different programs/threads simultaneously in the same cycle.
See also
References
- Curriculum Guidelines for Undergraduate Degree Programs in Computer Engineering (PDF). Association for Computing Machinery. 2004. p. 60. Archived from the original (PDF) on 2017-07-03.
Comments on Computer Architecture and Organization: Computer architecture is a key component of computer engineering and the practicing computer engineer should have a practical understanding of this topic...
- Murdocca, Miles; Heuring, Vincent (2007). Computer Architecture and Organization, An Integrated Approach. Wiley. p. 151. ISBN 9780471733881.
- Clements, Alan. Principles of Computer Hardware (4th ed.). pp. 1–2.
- Flynn, Michael J. (2007). "An Introduction to Architecture and Machines". Computer Architecture Pipelined and Parallel Processor Design. Jones and Bartlett. pp. 1–3. ISBN 9780867202045.
- Hennessy, John L.; Patterson, David A. (2006). Computer Architecture: A Quantitative Approach (4th ed.). Morgan Kaufmann. ISBN 0-12-370490-1.
- Wilkes, M. V. (1969). "The Growth of Interest in Microprogramming: A Literature Survey". ACM Computing Surveys. 1 (3): 139–145. doi:10.1145/356551.356553. S2CID 10673679.
Further reading
- Patterson, D.; Hennessy, J. (2004). Computer Organization and Design: The Hardware/Software Interface. Morgan Kaufmann. ISBN 1-55860-604-1.
- Hamacher, V. C.; Vrasenic, Z. G.; Zaky, S. G. (2001). Computer Organization. McGraw-Hill. ISBN 0-07-232086-9.
- Stallings, William (2002). Computer Organization and Architecture. Prentice Hall. ISBN 0-13-035119-9.
- Hayes, J. P. (2002). Computer Architecture and Organization. McGraw-Hill. ISBN 0-07-286198-3.
- Schneider, Gary Michael (1985). The Principles of Computer Organization. Wiley. pp. 6–7. ISBN 0-471-88552-5.
- Mano, M. Morris (1992). Computer System Architecture. Prentice Hall. p. 3. ISBN 0-13-175563-3.
- Abd-El-Barr, Mostafa; El-Rewini, Hesham (2004). Fundamentals of Computer Organization and Architecture. Wiley. p. 1. ISBN 0-471-46741-3.
- Gardner, J (2001). "PC Processor Microarchitecture". ExtremeTech.
- Gilreath, William F.; Laplante, Phillip A. (2012) [2003]. Computer Architecture: A Minimalist Perspective. Springer. ISBN 978-1-4615-0237-1.
- Patterson, David A. (10 October 2018). A New Golden Age for Computer Architecture. US Berkeley ACM A.M. Turing Laureate Colloquium. ctwj53r07yI.