Content similarity detection
Plagiarism detection or content similarity detection is the process of locating instances of plagiarism or copyright infringement within a work or document. The widespread use of computers and the advent of the Internet have made it easier to plagiarize the work of others.[1][2]
Detection of plagiarism can be undertaken in a variety of ways. Human detection is the most traditional form of identifying plagiarism from written work. This can be a lengthy and time-consuming task for the reader[2] and can also result in inconsistencies in how plagiarism is identified within an organization.[3] Text-matching software (TMS), which is also referred to as "plagiarism detection software" or "anti-plagiarism" software, has become widely available, in the form of both commercially available products as well as open-source software. TMS does not actually detect plagiarism per se, but instead finds specific passages of text in one document that match text in another document.
Software-assisted plagiarism detection
Computer-assisted plagiarism detection (CaPD) is an Information retrieval (IR) task supported by specialized IR systems, which is referred to as a plagiarism detection system (PDS) or document similarity detection system. A 2019 systematic literature review[4] presents an overview of state-of-the-art plagiarism detection methods.
In text documents
Systems for text similarity detection implement one of two generic detection approaches, one being external, the other being intrinsic.[5] External detection systems compare a suspicious document with a reference collection, which is a set of documents assumed to be genuine.[6] Based on a chosen document model and predefined similarity criteria, the detection task is to retrieve all documents that contain text that is similar to a degree above a chosen threshold to text in the suspicious document.[7] Intrinsic PDSes solely analyze the text to be evaluated without performing comparisons to external documents. This approach aims to recognize changes in the unique writing style of an author as an indicator for potential plagiarism.[8][9] PDSes are not capable of reliably identifying plagiarism without human judgment. Similarities and writing style features are computed with the help of predefined document models and might represent false positives.[10][11][12][13][14]
Effectiveness of those tools in higher education settings
A study was conducted to test the effectiveness of similarity detection software in a higher education setting. One part of the study assigned one group of students to write a paper. These students were first educated about plagiarism and informed that their work was to be run through a content similarity detection system. A second group of students was assigned to write a paper without any information about plagiarism. The researchers expected to find lower rates in group one but found roughly the same rates of plagiarism in both groups.[15]
Approaches
The figure below represents a classification of all detection approaches currently in use for computer-assisted content similarity detection. The approaches are characterized by the type of similarity assessment they undertake: global or local. Global similarity assessment approaches use the characteristics taken from larger parts of the text or the document as a whole to compute similarity, while local methods only examine pre-selected text segments as input.
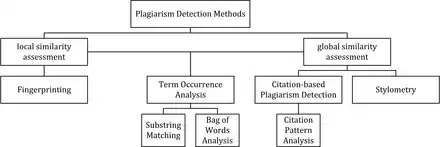
Fingerprinting
Fingerprinting is currently the most widely applied approach to content similarity detection. This method forms representative digests of documents by selecting a set of multiple substrings (n-grams) from them. The sets represent the fingerprints and their elements are called minutiae.[16][17] A suspicious document is checked for plagiarism by computing its fingerprint and querying minutiae with a precomputed index of fingerprints for all documents of a reference collection. Minutiae matching with those of other documents indicate shared text segments and suggest potential plagiarism if they exceed a chosen similarity threshold.[18] Computational resources and time are limiting factors to fingerprinting, which is why this method typically only compares a subset of minutiae to speed up the computation and allow for checks in very large collection, such as the Internet.[16]
String matching
String matching is a prevalent approach used in computer science. When applied to the problem of plagiarism detection, documents are compared for verbatim text overlaps. Numerous methods have been proposed to tackle this task, of which some have been adapted to external plagiarism detection. Checking a suspicious document in this setting requires the computation and storage of efficiently comparable representations for all documents in the reference collection to compare them pairwise. Generally, suffix document models, such as suffix trees or suffix vectors, have been used for this task. Nonetheless, substring matching remains computationally expensive, which makes it a non-viable solution for checking large collections of documents.[19][20][21]
Bag of words
Bag of words analysis represents the adoption of vector space retrieval, a traditional IR concept, to the domain of content similarity detection. Documents are represented as one or multiple vectors, e.g. for different document parts, which are used for pair wise similarity computations. Similarity computation may then rely on the traditional cosine similarity measure, or on more sophisticated similarity measures.[22][23][24]
Citation analysis
Citation-based plagiarism detection (CbPD)[25] relies on citation analysis, and is the only approach to plagiarism detection that does not rely on the textual similarity.[26] CbPD examines the citation and reference information in texts to identify similar patterns in the citation sequences. As such, this approach is suitable for scientific texts, or other academic documents that contain citations. Citation analysis to detect plagiarism is a relatively young concept. It has not been adopted by commercial software, but a first prototype of a citation-based plagiarism detection system exists.[27] Similar order and proximity of citations in the examined documents are the main criteria used to compute citation pattern similarities. Citation patterns represent subsequences non-exclusively containing citations shared by the documents compared.[26][28] Factors, including the absolute number or relative fraction of shared citations in the pattern, as well as the probability that citations co-occur in a document are also considered to quantify the patterns' degree of similarity.[26][28][29][30]
Stylometry
Stylometry subsumes statistical methods for quantifying an author's unique writing style[31][32] and is mainly used for authorship attribution or intrinsic plagiarism detection.[33] Detecting plagiarism by authorship attribution requires checking whether the writing style of the suspicious document, which is written supposedly by a certain author, matches with that of a corpus of documents written by the same author. Intrinsic plagiarism detection, on the other hand, uncover plagiarism based on internal evidences in the suspicious document without comparing it with other documents. This is performed by constructing and comparing stylometric models for different text segments of the suspicious document, and passages that are stylistically different from others are marked as potentially plagiarized/infringed.[8] Although they are simple to extract, character n-grams are proven to be among the best stylometric features for intrinsic plagiarism detection.[34]
Neural networks
More recent approaches to assess content similarity using neural networks have achieved significantly greater accuracy, but come at great computational cost.[35] Traditional neural network approaches embed both pieces of content into semantic vector embeddings to calculate their similarity, which is often their cosine similarity. More advanced methods perform end-to-end prediction of similarity or classifications using the Transformer architecture.[36][37] Particularly paraphrase detection benefits from highly parameterized pre-trained models.
Performance
Comparative evaluations of content similarity detection systems[6][38][39][40][41][42] indicate that their performance depends on the type of plagiarism present (see figure). Except for citation pattern analysis, all detection approaches rely on textual similarity. It is therefore symptomatic that detection accuracy decreases the more plagiarism cases are obfuscated.
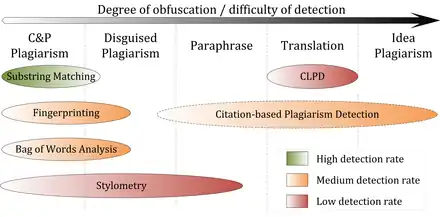
Literal copies, aka copy and paste (c&p) plagiarism or blatant copyright infringement, or modestly disguised plagiarism cases can be detected with high accuracy by current external PDS if the source is accessible to the software. Especially substring matching procedures achieve a good performance for c&p plagiarism, since they commonly use lossless document models, such as suffix trees. The performance of systems using fingerprinting or bag of words analysis in detecting copies depends on the information loss incurred by the document model used. By applying flexible chunking and selection strategies, they are better capable of detecting moderate forms of disguised plagiarism when compared to substring matching procedures.
Intrinsic plagiarism detection using stylometry can overcome the boundaries of textual similarity to some extent by comparing linguistic similarity. Given that the stylistic differences between plagiarized and original segments are significant and can be identified reliably, stylometry can help in identifying disguised and paraphrased plagiarism. Stylometric comparisons are likely to fail in cases where segments are strongly paraphrased to the point where they more closely resemble the personal writing style of the plagiarist or if a text was compiled by multiple authors. The results of the International Competitions on Plagiarism Detection held in 2009, 2010 and 2011,[6][41][42] as well as experiments performed by Stein,[33] indicate that stylometric analysis seems to work reliably only for document lengths of several thousand or tens of thousands of words, which limits the applicability of the method to CaPD settings.
An increasing amount of research is performed on methods and systems capable of detecting translated plagiarism. Currently, cross-language plagiarism detection (CLPD) is not viewed as a mature technology[43] and respective systems have not been able to achieve satisfying detection results in practice.[40]
Citation-based plagiarism detection using citation pattern analysis is capable of identifying stronger paraphrases and translations with higher success rates when compared to other detection approaches, because it is independent of textual characteristics.[26][29] However, since citation-pattern analysis depends on the availability of sufficient citation information, it is limited to academic texts. It remains inferior to text-based approaches in detecting shorter plagiarized passages, which are typical for cases of copy-and-paste or shake-and-paste plagiarism; the latter refers to mixing slightly altered fragments from different sources.[44]
Software
The design of content similarity detection software for use with text documents is characterized by a number of factors:[45]
| Factor | Description and alternatives |
|---|---|
| Scope of search | In the public internet, using search engines / Institutional databases / Local, system-specific database. |
| Analysis time | Delay between the time a document is submitted and the time when results are made available. |
| Document capacity / Batch processing | Number of documents the system can process per unit of time. |
| Check intensity | How often and for which types of document fragments (paragraphs, sentences, fixed-length word sequences) does the system query external resources, such as search engines. |
| Comparison algorithm type | The algorithms that define the way the system uses to compare documents against each other. |
| Precision and recall | Number of documents correctly flagged as plagiarized compared to the total number of flagged documents, and to the total number of documents that were actually plagiarized. High precision means that few false positives were found, and high recall means that few false negatives were left undetected. |
Most large-scale plagiarism detection systems use large, internal databases (in addition to other resources) that grow with each additional document submitted for analysis. However, this feature is considered by some as a violation of student copyright.
In source code
Plagiarism in computer source code is also frequent, and requires different tools than those used for text comparisons in document. Significant research has been dedicated to academic source-code plagiarism.[46]
A distinctive aspect of source-code plagiarism is that there are no essay mills, such as can be found in traditional plagiarism. Since most programming assignments expect students to write programs with very specific requirements, it is very difficult to find existing programs that already meet them. Since integrating external code is often harder than writing it from scratch, most plagiarizing students choose to do so from their peers.
According to Roy and Cordy,[47] source-code similarity detection algorithms can be classified as based on either
- Strings – look for exact textual matches of segments, for instance five-word runs. Fast, but can be confused by renaming identifiers.
- Tokens – as with strings, but using a lexer to convert the program into tokens first. This discards whitespace, comments, and identifier names, making the system more robust to simple text replacements. Most academic plagiarism detection systems work at this level, using different algorithms to measure the similarity between token sequences.
- Parse Trees – build and compare parse trees. This allows higher-level similarities to be detected. For instance, tree comparison can normalize conditional statements, and detect equivalent constructs as similar to each other.
- Program Dependency Graphs (PDGs) – a PDG captures the actual flow of control in a program, and allows much higher-level equivalences to be located, at a greater expense in complexity and calculation time.
- Metrics – metrics capture 'scores' of code segments according to certain criteria; for instance, "the number of loops and conditionals", or "the number of different variables used". Metrics are simple to calculate and can be compared quickly, but can also lead to false positives: two fragments with the same scores on a set of metrics may do entirely different things.
- Hybrid approaches – for instance, parse trees + suffix trees can combine the detection capability of parse trees with the speed afforded by suffix trees, a type of string-matching data structure.
The previous classification was developed for code refactoring, and not for academic plagiarism detection (an important goal of refactoring is to avoid duplicate code, referred to as code clones in the literature). The above approaches are effective against different levels of similarity; low-level similarity refers to identical text, while high-level similarity can be due to similar specifications. In an academic setting, when all students are expected to code to the same specifications, functionally equivalent code (with high-level similarity) is entirely expected, and only low-level similarity is considered as proof of cheating.
Complications with the use of text-matching software for plagiarism detection
Various complications have been documented with the use of text-matching software when used for plagiarism detection. One of the more prevalent concerns documented centers on the issue of intellectual property rights. The basic argument is that materials must be added to a database in order for the TMS to effectively determine a match, but adding users' materials to such a database may infringe on their intellectual property rights. The issue has been raised in a number of court cases.
An additional complication with the use of TMS is that the software finds only precise matches to other text. It does not pick up poorly paraphrased work, for example, or the practice of plagiarizing by use of sufficient word substitutions to elude detection software, which is known as rogeting.
See also
- Artificial intelligence detection software
- Category:Plagiarism detectors
- Comparison of anti-plagiarism software
- Locality-sensitive hashing
- Nearest neighbor search
- Paraphrase detection
- Kolmogorov complexity#Compression – used to estimate similarity between token sequences in several systems
- Video copy detection
References
- Culwin, Fintan; Lancaster, Thomas (2001). "Plagiarism, prevention, deterrence and detection". CiteSeerX 10.1.1.107.178. Archived from the original on 18 April 2021. Retrieved 11 November 2022 – via The Higher Education Academy.
- Bretag, T., & Mahmud, S. (2009). A model for determining student plagiarism: Electronic detection and academic judgement. Journal of University Teaching & Learning Practice, 6(1). Retrieved from http://ro.uow.edu.au/jutlp/vol6/iss1/6
- Macdonald, R., & Carroll, J. (2006). Plagiarism—a complex issue requiring a holistic institutional approach. Assessment & Evaluation in Higher Education, 31(2), 233–245. doi:10.1080/02602930500262536
- Foltýnek, Tomáš; Meuschke, Norman; Gipp, Bela (16 October 2019). "Academic Plagiarism Detection: A Systematic Literature Review". ACM Computing Surveys. 52 (6): 1–42. doi:10.1145/3345317.
- Stein, Benno; Koppel, Moshe; Stamatatos, Efstathios (December 2007), "Plagiarism Analysis, Authorship Identification, and Near-Duplicate Detection PAN'07" (PDF), SIGIR Forum, 41 (2): 68, doi:10.1145/1328964.1328976, S2CID 6379659, archived from the original (PDF) on 2 April 2012, retrieved 7 October 2011
- Potthast, Martin; Stein, Benno; Eiselt, Andreas; Barrón-Cedeño, Alberto; Rosso, Paolo (2009), "Overview of the 1st International Competition on Plagiarism Detection", PAN09 - 3rd Workshop on Uncovering Plagiarism, Authorship and Social Software Misuse and 1st International Competition on Plagiarism Detection (PDF), CEUR Workshop Proceedings, vol. 502, pp. 1–9, ISSN 1613-0073, archived from the original (PDF) on 2 April 2012
- Stein, Benno; Meyer zu Eissen, Sven; Potthast, Martin (2007), "Strategies for Retrieving Plagiarized Documents", Proceedings 30th Annual International ACM SIGIR Conference (PDF), ACM, pp. 825–826, doi:10.1145/1277741.1277928, ISBN 978-1-59593-597-7, S2CID 3898511, archived from the original (PDF) on 2 April 2012, retrieved 7 October 2011
- Meyer zu Eissen, Sven; Stein, Benno (2006), "Intrinsic Plagiarism Detection", Advances in Information Retrieval 28th European Conference on IR Research, ECIR 2006, London, UK, April 10–12, 2006 Proceedings (PDF), Lecture Notes in Computer Science, vol. 3936, Springer, pp. 565–569, CiteSeerX 10.1.1.110.5366, doi:10.1007/11735106_66, ISBN 978-3-540-33347-0, archived from the original (PDF) on 2 April 2012, retrieved 7 October 2011
- Bensalem, Imene (2020). "Intrinsic Plagiarism Detection: a Survey". Plagiarism Detection: A focus on the Intrinsic Approach and the Evaluation in the Arabic Language (PhD thesis). Constantine 2 University. doi:10.13140/RG.2.2.25727.84641.
- Bao, Jun-Peng; Malcolm, James A. (2006), "Text similarity in academic conference papers", 2nd International Plagiarism Conference Proceedings (PDF), Northumbria University Press, archived from the original (PDF) on 16 September 2018, retrieved 7 October 2011
- Clough, Paul (2000), Plagiarism in natural and programming languages an overview of current tools and technologies (PDF) (Technical Report), Department of Computer Science, University of Sheffield, archived from the original (PDF) on 18 August 2011
- Culwin, Fintan; Lancaster, Thomas (2001), "Plagiarism issues for higher education" (PDF), Vine, 31 (2): 36–41, doi:10.1108/03055720010804005, archived from the original (PDF) on 5 April 2012
- Lancaster, Thomas (2003), Effective and Efficient Plagiarism Detection (PhD Thesis), School of Computing, Information Systems and Mathematics South Bank University
- Maurer, Hermann; Zaka, Bilal (2007), "Plagiarism - A Problem And How To Fight It", Proceedings of World Conference on Educational Multimedia, Hypermedia and Telecommunications 2007, AACE, pp. 4451–4458, ISBN 9781880094624
- Youmans, Robert J. (November 2011). "Does the adoption of plagiarism-detection software in higher education reduce plagiarism?". Studies in Higher Education. 36 (7): 749–761. doi:10.1080/03075079.2010.523457. S2CID 144143548.
- Hoad, Timothy; Zobel, Justin (2003), "Methods for Identifying Versioned and Plagiarised Documents" (PDF), Journal of the American Society for Information Science and Technology, 54 (3): 203–215, CiteSeerX 10.1.1.18.2680, doi:10.1002/asi.10170, archived from the original (PDF) on 30 April 2015, retrieved 14 October 2014
- Stein, Benno (July 2005), "Fuzzy-Fingerprints for Text-Based Information Retrieval", Proceedings of the I-KNOW '05, 5th International Conference on Knowledge Management, Graz, Austria (PDF), Springer, Know-Center, pp. 572–579, archived from the original (PDF) on 2 April 2012, retrieved 7 October 2011
- Brin, Sergey; Davis, James; Garcia-Molina, Hector (1995), "Copy Detection Mechanisms for Digital Documents", Proceedings of the 1995 ACM SIGMOD International Conference on Management of Data (PDF), ACM, pp. 398–409, CiteSeerX 10.1.1.49.1567, doi:10.1145/223784.223855, ISBN 978-1-59593-060-6, S2CID 8652205, archived from the original (PDF) on 18 August 2016, retrieved 7 October 2011
- Monostori, Krisztián; Zaslavsky, Arkady; Schmidt, Heinz (2000), "Document Overlap Detection System for Distributed Digital Libraries", Proceedings of the fifth ACM conference on Digital libraries (PDF), ACM, pp. 226–227, doi:10.1145/336597.336667, ISBN 978-1-58113-231-1, S2CID 5796686, archived from the original (PDF) on 15 April 2012, retrieved 7 October 2011
- Baker, Brenda S. (February 1993), On Finding Duplication in Strings and Software (Technical Report), AT&T Bell Laboratories, NJ, archived from the original (gs) on 30 October 2007
- Khmelev, Dmitry V.; Teahan, William J. (2003), "A Repetition Based Measure for Verification of Text Collections and for Text Categorization", SIGIR'03: Proceedings of the 26th annual international ACM SIGIR conference on Research and development in information retrieval, ACM, pp. 104–110, CiteSeerX 10.1.1.9.6155, doi:10.1145/860435.860456, ISBN 978-1581136463, S2CID 7316639
- Si, Antonio; Leong, Hong Va; Lau, Rynson W. H. (1997), "CHECK: A Document Plagiarism Detection System", SAC '97: Proceedings of the 1997 ACM symposium on Applied computing (PDF), ACM, pp. 70–77, doi:10.1145/331697.335176, ISBN 978-0-89791-850-3, S2CID 15273799
- Dreher, Heinz (2007), "Automatic Conceptual Analysis for Plagiarism Detection" (PDF), Information and Beyond: The Journal of Issues in Informing Science and Information Technology, 4: 601–614, doi:10.28945/974
- Muhr, Markus; Zechner, Mario; Kern, Roman; Granitzer, Michael (2009), "External and Intrinsic Plagiarism Detection Using Vector Space Models", PAN09 - 3rd Workshop on Uncovering Plagiarism, Authorship and Social Software Misuse and 1st International Competition on Plagiarism Detection (PDF), CEUR Workshop Proceedings, vol. 502, pp. 47–55, ISSN 1613-0073, archived from the original (PDF) on 2 April 2012
- Gipp, Bela (2014), Citation-based Plagiarism Detection, Springer Vieweg Research, ISBN 978-3-658-06393-1
- Gipp, Bela; Beel, Jöran (June 2010), "Citation Based Plagiarism Detection - A New Approach to Identifying Plagiarized Work Language Independently", Proceedings of the 21st ACM Conference on Hypertext and Hypermedia (HT'10) (PDF), ACM, pp. 273–274, doi:10.1145/1810617.1810671, ISBN 978-1-4503-0041-4, S2CID 2668037, archived from the original (PDF) on 25 April 2012, retrieved 21 October 2011
- Gipp, Bela; Meuschke, Norman; Breitinger, Corinna; Lipinski, Mario; Nürnberger, Andreas (28 July 2013), "Demonstration of Citation Pattern Analysis for Plagiarism Detection", Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval (PDF), ACM, p. 1119, doi:10.1145/2484028.2484214, ISBN 9781450320344, S2CID 2106222
- Gipp, Bela; Meuschke, Norman (September 2011), "Citation Pattern Matching Algorithms for Citation-based Plagiarism Detection: Greedy Citation Tiling, Citation Chunking and Longest Common Citation Sequence", Proceedings of the 11th ACM Symposium on Document Engineering (DocEng2011) (PDF), ACM, pp. 249–258, doi:10.1145/2034691.2034741, ISBN 978-1-4503-0863-2, S2CID 207190305, archived from the original (PDF) on 25 April 2012, retrieved 7 October 2011
- Gipp, Bela; Meuschke, Norman; Beel, Jöran (June 2011), "Comparative Evaluation of Text- and Citation-based Plagiarism Detection Approaches using GuttenPlag", Proceedings of 11th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL'11) (PDF), ACM, pp. 255–258, CiteSeerX 10.1.1.736.4865, doi:10.1145/1998076.1998124, ISBN 978-1-4503-0744-4, S2CID 3683238, archived from the original (PDF) on 25 April 2012, retrieved 7 October 2011
- Gipp, Bela; Beel, Jöran (July 2009), "Citation Proximity Analysis (CPA) - A new approach for identifying related work based on Co-Citation Analysis", Proceedings of the 12th International Conference on Scientometrics and Informetrics (ISSI'09) (PDF), International Society for Scientometrics and Informetrics, pp. 571–575, ISSN 2175-1935, archived from the original (PDF) on 13 September 2012, retrieved 7 October 2011
- Holmes, David I. (1998), "The Evolution of Stylometry in Humanities Scholarship", Literary and Linguistic Computing, 13 (3): 111–117, doi:10.1093/llc/13.3.111
- Juola, Patrick (2006), "Authorship Attribution" (PDF), Foundations and Trends in Information Retrieval, 1 (3): 233–334, CiteSeerX 10.1.1.219.1605, doi:10.1561/1500000005, ISSN 1554-0669
- Stein, Benno; Lipka, Nedim; Prettenhofer, Peter (2011), "Intrinsic Plagiarism Analysis" (PDF), Language Resources and Evaluation, 45 (1): 63–82, doi:10.1007/s10579-010-9115-y, ISSN 1574-020X, S2CID 13426762, archived from the original (PDF) on 2 April 2012, retrieved 7 October 2011
- Bensalem, Imene; Rosso, Paolo; Chikhi, Salim (2019). "On the use of character n-grams as the only intrinsic evidence of plagiarism". Language Resources and Evaluation. 53 (3): 363–396. doi:10.1007/s10579-019-09444-w. hdl:10251/159151. S2CID 86630897.
- Reimers, Nils; Gurevych, Iryna (2019). "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks". arXiv:1908.10084 [cs.CL].
- Lan, Wuwei; Xu, Wei (2018). "Neural Network Models for Paraphrase Identification, Semantic Textual Similarity, Natural Language Inference, and Question Answering". Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe, New Mexico, USA: Association for Computational Linguistics: 3890–3902. arXiv:1806.04330.
- Wahle, Jan Philip; Ruas, Terry; Foltýnek, Tomáš; Meuschke, Norman; Gipp, Bela (2022), Smits, Malte (ed.), "Identifying Machine-Paraphrased Plagiarism", Information for a Better World: Shaping the Global Future, Cham: Springer International Publishing, vol. 13192, pp. 393–413, arXiv:2103.11909, doi:10.1007/978-3-030-96957-8_34, ISBN 978-3-030-96956-1, S2CID 232307572, retrieved 6 October 2022
- Portal Plagiat - Softwaretest 2004 (in German), HTW University of Applied Sciences Berlin, archived from the original on 25 October 2011, retrieved 6 October 2011
- Portal Plagiat - Softwaretest 2008 (in German), HTW University of Applied Sciences Berlin, retrieved 6 October 2011
- Portal Plagiat - Softwaretest 2010 (in German), HTW University of Applied Sciences Berlin, retrieved 6 October 2011
- Potthast, Martin; Barrón-Cedeño, Alberto; Eiselt, Andreas; Stein, Benno; Rosso, Paolo (2010), "Overview of the 2nd International Competition on Plagiarism Detection", Notebook Papers of CLEF 2010 LABs and Workshops, 22–23 September, Padua, Italy (PDF), archived from the original (PDF) on 3 April 2012, retrieved 7 October 2011
- Potthast, Martin; Eiselt, Andreas; Barrón-Cedeño, Alberto; Stein, Benno; Rosso, Paolo (2011), "Overview of the 3rd International Competition on Plagiarism Detection", Notebook Papers of CLEF 2011 LABs and Workshops, 19–22 September, Amsterdam, Netherlands (PDF), archived from the original (PDF) on 2 April 2012, retrieved 7 October 2011
- Potthast, Martin; Barrón-Cedeño, Alberto; Stein, Benno; Rosso, Paolo (2011), "Cross-Language Plagiarism Detection" (PDF), Language Resources and Evaluation, 45 (1): 45–62, doi:10.1007/s10579-009-9114-z, hdl:10251/37479, ISSN 1574-020X, S2CID 14942239, archived from the original (PDF) on 26 November 2013, retrieved 7 October 2011
- Weber-Wulff, Debora (June 2008), "On the Utility of Plagiarism Detection Software", In Proceedings of the 3rd International Plagiarism Conference, Newcastle Upon Tyne (PDF), archived from the original (PDF) on 1 October 2013, retrieved 29 September 2013
- How to check the text for plagiarism
- "Plagiarism Prevention and Detection - On-line Resources on Source Code Plagiarism" Archived 15 November 2012 at the Wayback Machine. Higher Education Academy, University of Ulster.
- Roy, Chanchal Kumar;Cordy, James R. (26 September 2007)."A Survey on Software Clone Detection Research". School of Computing, Queen's University, Canada.