Dimension (data warehouse)
A dimension is a structure that categorizes facts and measures in order to enable users to answer business questions. Commonly used dimensions are people, products, place and time.[1][2] (Note: People and time sometimes are not modeled as dimensions.)
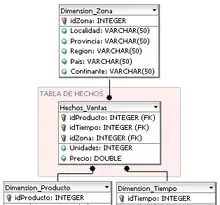
In a data warehouse, dimensions provide structured labeling information to otherwise unordered numeric measures. The dimension is a data set composed of individual, non-overlapping data elements. The primary functions of dimensions are threefold: to provide filtering, grouping and labelling.
These functions are often described as "slice and dice". A common data warehouse example involves sales as the measure, with customer and product as dimensions. In each sale a customer buys a product. The data can be sliced by removing all customers except for a group under study, and then diced by grouping by product.
A dimensional data element is similar to a categorical variable in statistics.
Typically dimensions in a data warehouse are organized internally into one or more hierarchies. "Date" is a common dimension, with several possible hierarchies:
- "Days (are grouped into) Months (which are grouped into) Years",
- "Days (are grouped into) Weeks (which are grouped into) Years"
- "Days (are grouped into) Months (which are grouped into) Quarters (which are grouped into) Years"
- etc.
Types
Slowly changing dimensions
A slowly changing dimension is a set of data attributes that change slowly over a period of time rather than changing regularly e.g. address or name. These attributes can change over a period of time and that will get combined as a slowly changing dimension. These dimension can be classified in types:[3]
- Type 0 (Retain original): Attributes never change. No history.
- Type 1 (Overwrite): Old values are overwritten with new values for attribute. No history.
- Type 2 (Add new row): A new row is created with either a start date / end date or a version for a new value. This creates history.
- Type 3 (Add new attribute): A new column is created for a new value. History is limited to the number of columns designated for storing historical data.
- Type 4 (Add history table): One table keeps the current value, while the history is saved in a second table.
- Type 5 (Combined Approach 1 + 4): Combination of type 1 and type 4. History is created through a second history table.
- Type 6 (Combined Approach 1 + 2 + 3): Combination of type 1, type 2 and type 3. History is created through separate row and attributes.
- Type 7 (Hybrid Approach): Both surrogate and natural key are used.[4]
Conformed dimension
A conformed dimension is a set of data attributes that have been physically referenced in multiple database tables using the same key value to refer to the same structure, attributes, domain values, definitions and concepts. A conformed dimension cuts across many facts.
Dimensions are conformed when they are either exactly the same (including keys) or one is a proper subset of the other. Most important, the row headers produced in two different answer sets from the same conformed dimension(s) must be able to match perfectly.'
Conformed dimensions are either identical or strict mathematical subsets of the most granular, detailed dimension. Dimension tables are not conformed if the attributes are labeled differently or contain different values. Conformed dimensions come in several different flavors. At the most basic level, conformed dimensions mean exactly the same thing with every possible fact table to which they are joined. The date dimension table connected to the sales facts is identical to the date dimension connected to the inventory facts.[5]
Junk dimension
A junk dimension is a convenient grouping of typically low-cardinality flags and indicators. By creating an abstract dimension, these flags and indicators are removed from the fact table while placing them into a useful dimensional framework.[6] A junk dimension is a dimension table consisting of attributes that do not belong in the fact table or in any of the existing dimension tables. The nature of these attributes is usually text or various flags, e.g. non-generic comments or just simple yes/no or true/false indicators. These kinds of attributes are typically remaining when all the obvious dimensions in the business process have been identified and thus the designer is faced with the challenge of where to put these attributes that do not belong in the other dimensions.
One solution is to create a new dimension for each of the remaining attributes, but due to their nature, it could be necessary to create a vast number of new dimensions resulting in a fact table with a very large number of foreign keys. The designer could also decide to leave the remaining attributes in the fact table but this could make the row length of the table unnecessarily large if, for example, the attribute is a long text string.
The solution to this challenge is to identify all the attributes and then put them into one or several junk dimensions. One junk dimension can hold several true/false or yes/no indicators that have no correlation with each other, so it would be convenient to convert the indicators into a more describing attribute. An example would be an indicator about whether a package had arrived: instead of indicating this as “yes” or “no”, it would be converted into "arrived" or "pending" in the junk dimension. The designer can choose to build the dimension table so it ends up holding all the indicators occurring with every other indicator so that all combinations are covered. This sets up a fixed size for the table itself which would be 2x rows, where x is the number of indicators. This solution is appropriate in situations where the designer would expect to encounter a lot of different combinations and where the possible combinations are limited to an acceptable level. In a situation where the number of indicators are large, thus creating a very big table or where the designer only expects to encounter a few of the possible combinations, it would be more appropriate to build each row in the junk dimension as new combinations are encountered. To limit the size of the tables, multiple junk dimensions might be appropriate in other situations depending on the correlation between various indicators.
Junk dimensions are also appropriate for placing attributes like non-generic comments from the fact table. Such attributes might consist of data from an optional comment field when a customer places an order and as a result will probably be blank in many cases. Therefore, the junk dimension should contain a single row representing the blanks as a surrogate key that will be used in the fact table for every row returned with a blank comment field.[7]
Degenerate dimension
A degenerate dimension is a key, such as a transaction number, invoice number, ticket number, or bill-of-lading number, that has no attributes and hence does not join to an actual dimension table. Degenerate dimensions are very common when the grain of a fact table represents a single transaction item or line item because the degenerate dimension represents the unique identifier of the parent. Degenerate dimensions often play an integral role in the fact table's primary key.[8]
Role-playing dimension
Dimensions are often recycled for multiple applications within the same database. For instance, a "Date" dimension can be used for "Date of Sale", as well as "Date of Delivery", or "Date of Hire". This is often referred to as a "role-playing dimension". This can be implemented using a view over the same dimension table.
Outrigger dimension
Usually dimension tables do not reference other dimensions via foreign keys. When this happens, the referenced dimension is called an outrigger dimension. Outrigger dimensions should be considered a data warehouse anti-pattern: it is considered a better practice to use some fact tables that relate the two dimensions. [9]
Shrunken dimension
A conformed dimensions is said to be a shrunken dimension when it includes a subset of the rows and/or columns of the original dimension.[10]
Calendar date dimension
A special type of dimension can be used to represent dates with a granularity of a day. Dates would be referenced in a fact table as foreign keys to a date dimension. The date dimension primary key could be a surrogate key or a number using the format YYYYMMDD.
The date dimension can include other attributes like the week of the year, or flags representing work days, holidays, etc. It could also include special rows representing: not known dates, or yet to be defined dates. The date dimension should be initialized with all the required dates, say the next 10 years of dates, or more if required, or past dates if events in the past are handled.
Time instead is usually best represented as a timestamp in the fact table. [11]
Use of ISO representation terms
When referencing data from a metadata registry such as ISO/IEC 11179, representation terms such as "Indicator" (a boolean true/false value), "Code" (a set of non-overlapping enumerated values) are typically used as dimensions. For example, using the National Information Exchange Model (NIEM) the data element name would be "PersonGenderCode" and the enumerated values might be "male", "female" and "unknown".
Dimension table
In data warehousing, a dimension table is one of the set of companion tables to a fact table.
The fact table contains business facts (or measures), and foreign keys which refer to candidate keys (normally primary keys) in the dimension tables.
Contrary to fact tables, dimension tables contain descriptive attributes (or fields) that are typically textual fields (or discrete numbers that behave like text). These attributes are designed to serve two critical purposes: query constraining and/or filtering, and query result set labeling.
Dimension attributes should be:
- Verbose (labels consisting of full words)
- Descriptive
- Complete (having no missing values)
- Discretely valued (having only one value per dimension table row)
- Quality assured (having no misspellings or impossible values)
Dimension table rows are uniquely identified by a single key field. It is recommended that the key field be a simple integer because a key value is meaningless, used only for joining fields between the fact and dimension tables. Dimension tables often use primary keys that are also surrogate keys. Surrogate keys are often auto-generated (e.g. a Sybase or SQL Server "identity column", a PostgreSQL or Informix serial, an Oracle SEQUENCE or a column defined with AUTO_INCREMENT in MySQL).
The use of surrogate dimension keys brings several advantages, including:
- Performance. Join processing is made much more efficient by using a single field (the surrogate key)
- Buffering from operational key management practices. This prevents situations where removed data rows might reappear when their natural keys get reused or reassigned after a long period of dormancy
- Mapping to integrate disparate sources
- Handling unknown or not-applicable connections
- Tracking changes in dimension attribute values
Although surrogate key use places a burden on the ETL system, pipeline processing can be improved, and ETL tools have built-in improved surrogate key processing.
The goal of a dimension table is to create standardized, conformed dimensions that can be shared across the enterprise's data warehouse environment, and enable joining to multiple fact tables representing various business processes.
Conformed dimensions are important to the enterprise nature of DW/BI systems because they promote:
- Consistency. Every fact table is filtered consistently, so that query answers are labeled consistently.
- Integration. Queries can drill into different process fact tables separately, then join the results on common dimension attributes.
- Reduced development time to market. The common dimensions are available without recreating them.
Over time, the attributes of a given row in a dimension table may change. For example, the shipping address for a company may change. Kimball refers to this phenomenon as slowly changing dimension. Strategies for dealing with this kind of change are divided into three categories:
- Type one: Simply overwrite the old value(s).
- Type two: Add a new row containing the new value(s), and distinguish between the rows using Tuple-versioning techniques.
- Type three: Add a new attribute to the existing row.
Common patterns
Date and time[12]
Since many fact tables in a data warehouse are time series of observations, one or more date dimensions are often needed. One of the reasons to have date dimensions is to place calendar knowledge in the data warehouse instead of hard-coded in an application. While a simple SQL date/timestamp is useful for providing accurate information about the time a fact was recorded, it can not give information about holidays, fiscal periods, etc. An SQL date/timestamp can still be useful to store in the fact table, as it allows for precise calculations.
Having both the date and time of day in the same dimension, may easily result in a huge dimension with millions of rows. If a high amount of detail is needed it is usually a good idea to split date and time into two or more separate dimensions. A time dimension with a grain of seconds in a day will only have 86400 rows. A more or less detailed grain for date/time dimensions can be chosen depending on needs. As examples, date dimensions can be accurate to year, quarter, month or day and time dimensions can be accurate to hours, minutes or seconds.
As a rule of thumb, time of day dimension should only be created if hierarchical groupings are needed or if there are meaningful textual descriptions for periods of time within the day (ex. “evening rush” or “first shift”).
If the rows in a fact table are coming from several time zones, it might be useful to store date and time in both local time and a standard time. This can be done by having two dimensions for each date/time dimension needed – one for local time, and one for standard time. Storing date/time in both local and standard time, will allow for analysis on when facts are created in a local setting and in a global setting as well. The standard time chosen can be a global standard time (ex. UTC), it can be the local time of the business’ headquarters (ex. CET), or any other time zone that would make sense to use.
See also
References
- "Oracle Data Warehousing Guide", Oracle Corporation, retrieved 9 June 2014
- Definition: Dimension" Search Data Management, TechTarget, retrieved 9 June 2014
- Says, Kalyn (9 October 2014). "Types Of Dimension Table | Data Warehousing Training". Edureka. Retrieved 12 January 2022.
- Ross, Margy (5 February 2013). "Design Tip #152 Slowly Changing Dimension Types 0, 4, 5, 6 and 7". Kimball Group. Retrieved 12 January 2022.
- Ralph Kimball, Margy Ross, The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling, Second Edition, Wiley Computer Publishing, 2002. ISBN 0471-20024-7, Pages 82-87, 394
- Ralph Kimball, Margy Ross, The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling, Second Edition, Wiley Computer Publishing, 2002. ISBN 0471-20024-7, Pages 202, 405
- Kimball, Ralph, et al. (2008): The Data Warehouse Lifecycle Toolkit, Second Edition, Wiley Publishing Inc., Indianapolis, IN. Pages 263-265
- Ralph Kimball, Margy Ross, The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling, Second Edition, Wiley Computer Publishing, 2002. ISBN 0471-20024-7, Pages 50, 398
- Ralph Kimball; Margy Ross (2013). The Data Wharehouse Toolkit 3rd edition. Wiley. p. 50. ISBN 978-1-118-53080-1.
- Ralph Kimball; Margy Ross (2013). The Data Wharehouse Toolkit 3rd edition. Wiley. p. 51. ISBN 978-1-118-53080-1.
- Ralph Kimball; Margy Ross (2013). The Data Wharehouse Toolkit 3rd edition. Wiley. p. 48. ISBN 978-1-118-53080-1.
- Ralph Kimball, The Data Warehouse Toolkit, Second Edition, Wiley Publishing, Inc., 2008. ISBN 978-0-470-14977-5, Pages 253-256