Data vault modeling
Data vault modeling is a database modeling method that is designed to provide long-term historical storage of data coming in from multiple operational systems. It is also a method of looking at historical data that deals with issues such as auditing, tracing of data, loading speed and resilience to change as well as emphasizing the need to trace where all the data in the database came from. This means that every row in a data vault must be accompanied by record source and load date attributes, enabling an auditor to trace values back to the source. The concept was published in 2000 by Dan Linstedt.
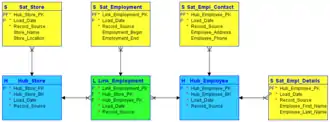
Data vault modeling makes no distinction between good and bad data ("bad" meaning not conforming to business rules).[1] This is summarized in the statement that a data vault stores "a single version of the facts" (also expressed by Dan Linstedt as "all the data, all of the time") as opposed to the practice in other data warehouse methods of storing "a single version of the truth"[2] where data that does not conform to the definitions is removed or "cleansed". A data vault enterprise data warehouse provides both; a single version of facts and a single source of truth.[3]
The modeling method is designed to be resilient to change in the business environment where the data being stored is coming from, by explicitly separating structural information from descriptive attributes.[4] Data vault is designed to enable parallel loading as much as possible,[5] so that very large implementations can scale out without the need for major redesign.
Unlike the star schema (dimensional modelling) and the classical relational model (3NF), data vault and anchor modeling are well-suited for capturing changes that occur when a source system is changed or added, but are considered advanced techniques which require experienced data architects.[6] Both data vaults and anchor models are entity-based models,[7] but anchor models have a more normalized approach.
History and philosophy
In its early days, Dan Linstedt referred to the modeling technique which was to become data vault as common foundational warehouse architecture[8] or common foundational modeling architecture.[9] In data warehouse modeling there are two well-known competing options for modeling the layer where the data are stored. Either you model according to Ralph Kimball, with conformed dimensions and an enterprise data bus, or you model according to Bill Inmon with the database normalized. Both techniques have issues when dealing with changes in the systems feeding the data warehouse. For conformed dimensions you also have to cleanse data (to conform it) and this is undesirable in a number of cases since this inevitably will lose information. Data vault is designed to avoid or minimize the impact of those issues, by moving them to areas of the data warehouse that are outside the historical storage area (cleansing is done in the data marts) and by separating the structural items (business keys and the associations between the business keys) from the descriptive attributes.
Dan Linstedt, the creator of the method, describes the resulting database as follows:
"The Data Vault Model is a detail oriented, historical tracking and uniquely linked set of normalized tables that support one or more functional areas of business. It is a hybrid approach encompassing the best of breed between 3rd normal form (3NF) and star schema. The design is flexible, scalable, consistent and adaptable to the needs of the enterprise"[10]
Data vault's philosophy is that all data is relevant data, even if it is not in line with established definitions and business rules. If data are not conforming to these definitions and rules then that is a problem for the business, not the data warehouse. The determination of data being "wrong" is an interpretation of the data that stems from a particular point of view that may not be valid for everyone, or at every point in time. Therefore the data vault must capture all data and only when reporting or extracting data from the data vault is the data being interpreted.
Another issue to which data vault is a response is that more and more there is a need for complete auditability and traceability of all the data in the data warehouse. Due to Sarbanes-Oxley requirements in the USA and similar measures in Europe this is a relevant topic for many business intelligence implementations, hence the focus of any data vault implementation is complete traceability and auditability of all information.
Data Vault 2.0 is the new specification. It is an open standard.[11] The new specification consists of three pillars: methodology (SEI/CMMI, Six Sigma, SDLC, etc..), the architecture (amongst others an input layer (data stage, called persistent staging area in Data Vault 2.0) and a presentation layer (data mart), and handling of data quality services and master data services), and the model. Within the methodology, the implementation of best practices is defined. Data Vault 2.0 has a focus on including new components such as big data, NoSQL - and also focuses on the performance of the existing model. The old specification (documented here for the most part) is highly focused on data vault modeling. It is documented in the book: Building a Scalable Data Warehouse with Data Vault 2.0.
It is necessary to evolve the specification to include the new components, along with the best practices in order to keep the EDW and BI systems current with the needs and desires of today's businesses.
History
Data vault modeling was originally conceived by Dan Linstedt in the 1990s and was released in 2000 as a public domain modeling method. In a series of five articles in The Data Administration Newsletter the basic rules of the Data Vault method are expanded and explained. These contain a general overview,[12] an overview of the components,[13] a discussion about end dates and joins,[14] link tables,[15] and an article on loading practices.[16]
An alternative (and seldom used) name for the method is "Common Foundational Integration Modelling Architecture."[17]
Data Vault 2.0[18][19] has arrived on the scene as of 2013 and brings to the table Big Data, NoSQL, unstructured, semi-structured seamless integration, along with methodology, architecture, and implementation best practices.
Alternative interpretations
According to Dan Linstedt, the Data Model is inspired by (or patterned off) a simplistic view of neurons, dendrites, and synapses – where neurons are associated with Hubs and Hub Satellites, Links are dendrites (vectors of information), and other Links are synapses (vectors in the opposite direction). By using a data mining set of algorithms, links can be scored with confidence and strength ratings. They can be created and dropped on the fly in accordance with learning about relationships that currently don't exist. The model can be automatically morphed, adapted, and adjusted as it is used and fed new structures.[20]
Another view is that a data vault model provides an ontology of the Enterprise in the sense that it describes the terms in the domain of the enterprise (Hubs) and the relationships among them (Links), adding descriptive attributes (Satellites) where necessary.
Another way to think of a data vault model is as a graphical model. The data vault model actually provides a "graph based" model with hubs and relationships in a relational database world. In this manner, the developer can use SQL to get at graph-based relationships with sub-second responses.
Basic notions
Data vault attempts to solve the problem of dealing with change in the environment by separating the business keys (that do not mutate as often, because they uniquely identify a business entity) and the associations between those business keys, from the descriptive attributes of those keys.
The business keys and their associations are structural attributes, forming the skeleton of the data model. The data vault method has as one of its main axioms that real business keys only change when the business changes and are therefore the most stable elements from which to derive the structure of a historical database. If you use these keys as the backbone of a data warehouse, you can organize the rest of the data around them. This means that choosing the correct keys for the hubs is of prime importance for the stability of your model.[21] The keys are stored in tables with a few constraints on the structure. These key-tables are called hubs.
Hubs
Hubs contain a list of unique business keys with low propensity to change. Hubs also contain a surrogate key for each Hub item and metadata describing the origin of the business key. The descriptive attributes for the information on the Hub (such as the description for the key, possibly in multiple languages) are stored in structures called Satellite tables which will be discussed below.
The Hub contains at least the following fields:[22]
- a surrogate key, used to connect the other structures to this table.
- a business key, the driver for this hub. The business key can consist of multiple fields.
- the record source, which can be used to see what system loaded each business key first.
- optionally, you can also have metadata fields with information about manual updates (user/time) and the extraction date.
A hub is not allowed to contain multiple business keys, except when two systems deliver the same business key but with collisions that have different meanings.
Hubs should normally have at least one satellite.[22]
Hub example
This is an example for a hub-table containing cars, called "Car" (H_CAR). The driving key is vehicle identification number.
| Fieldname | Description | Mandatory? | Comment |
|---|---|---|---|
| H_CAR_ID | Sequence ID and surrogate key for the hub | No | Recommended but optional[23] |
| VEHICLE_ID_NR | The business key that drives this hub. Can be more than one field for a composite business key | Yes | |
| H_RSRC | The record source of this key when first loaded | Yes | |
| LOAD_AUDIT_ID | An ID into a table with audit information, such as load time, duration of load, number of lines, etc. | No |
Links
Associations or transactions between business keys (relating for instance the hubs for customer and product with each other through the purchase transaction) are modeled using link tables. These tables are basically many-to-many join tables, with some metadata.
Links can link to other links, to deal with changes in granularity (for instance, adding a new key to a database table would change the grain of the database table). For instance, if you have an association between customer and address, you could add a reference to a link between the hubs for product and transport company. This could be a link called "Delivery". Referencing a link in another link is considered a bad practice, because it introduces dependencies between links that make parallel loading more difficult. Since a link to another link is the same as a new link with the hubs from the other link, in these cases creating the links without referencing other links is the preferred solution (see the section on loading practices for more information).
Links sometimes link hubs to information that is not by itself enough to construct a hub. This occurs when one of the business keys associated by the link is not a real business key. As an example, take an order form with "order number" as key, and order lines that are keyed with a semi-random number to make them unique. Let's say, "unique number". The latter key is not a real business key, so it is no hub. However, we do need to use it in order to guarantee the correct granularity for the link. In this case, we do not use a hub with surrogate key, but add the business key "unique number" itself to the link. This is done only when there is no possibility of ever using the business key for another link or as key for attributes in a satellite. This construct has been called a 'peg-legged link' by Dan Linstedt on his (now defunct) forum.
Links contain the surrogate keys for the hubs that are linked, their own surrogate key for the link and metadata describing the origin of the association. The descriptive attributes for the information on the association (such as the time, price or amount) are stored in structures called satellite tables which are discussed below.
Link example
This is an example for a link-table between two hubs for cars (H_CAR) and persons (H_PERSON). The link is called "Driver" (L_DRIVER).
| Fieldname | Description | Mandatory? | Comment |
|---|---|---|---|
| L_DRIVER_ID | Sequence ID and surrogate key for the Link | No | Recommended but optional[23] |
| H_CAR_ID | surrogate key for the car hub, the first anchor of the link | Yes | |
| H_PERSON_ID | surrogate key for the person hub, the second anchor of the link | Yes | |
| L_RSRC | The recordsource of this association when first loaded | Yes | |
| LOAD_AUDIT_ID | An ID into a table with audit information, such as load time, duration of load, number of lines, etc. | No |
Satellites
The hubs and links form the structure of the model, but have no temporal attributes and hold no descriptive attributes. These are stored in separate tables called satellites. These consist of metadata linking them to their parent hub or link, metadata describing the origin of the association and attributes, as well as a timeline with start and end dates for the attribute. Where the hubs and links provide the structure of the model, the satellites provide the "meat" of the model, the context for the business processes that are captured in hubs and links. These attributes are stored both with regards to the details of the matter as well as the timeline and can range from quite complex (all of the fields describing a client's complete profile) to quite simple (a satellite on a link with only a valid-indicator and a timeline).
Usually the attributes are grouped in satellites by source system. However, descriptive attributes such as size, cost, speed, amount or color can change at different rates, so you can also split these attributes up in different satellites based on their rate of change.
All the tables contain metadata, minimally describing at least the source system and the date on which this entry became valid, giving a complete historical view of the data as it enters the data warehouse.
An effectivity satellite is a satellite built on a link, "and record[s] the time period when the corresponding link records start and end effectivity".[24]
Satellite example
This is an example for a satellite on the drivers-link between the hubs for cars and persons, called "Driver insurance" (S_DRIVER_INSURANCE). This satellite contains attributes that are specific to the insurance of the relationship between the car and the person driving it, for instance an indicator whether this is the primary driver, the name of the insurance company for this car and person (could also be a separate hub) and a summary of the number of accidents involving this combination of vehicle and driver. Also included is a reference to a lookup- or reference table called R_RISK_CATEGORY containing the codes for the risk category in which this relationship is deemed to fall.
| Fieldname | Description | Mandatory? | Comment |
|---|---|---|---|
| S_DRIVER_INSURANCE_ID | Sequence ID and surrogate key for the satellite on the link | No | Recommended but optional[23] |
| L_DRIVER_ID | (surrogate) primary key for the driver link, the parent of the satellite | Yes | |
| S_SEQ_NR | Ordering or sequence number, to enforce uniqueness if there are several valid satellites for one parent key | No(**) | This can happen if, for instance, you have a hub COURSE and the name of the course is an attribute but in several different languages. |
| S_LDTS | Load Date (startdate) for the validity of this combination of attribute values for parent key L_DRIVER_ID | Yes | |
| S_LEDTS | Load End Date (enddate) for the validity of this combination of attribute values for parent key L_DRIVER_ID | No | |
| IND_PRIMARY_DRIVER | Indicator whether the driver is the primary driver for this car | No (*) | |
| INSURANCE_COMPANY | The name of the insurance company for this vehicle and this driver | No (*) | |
| NR_OF_ACCIDENTS | The number of accidents by this driver in this vehicle | No (*) | |
| R_RISK_CATEGORY_CD | The risk category for the driver. This is a reference to R_RISK_CATEGORY | No (*) | |
| S_RSRC | The recordsource of the information in this satellite when first loaded | Yes | |
| LOAD_AUDIT_ID | An ID into a table with audit information, such as load time, duration of load, number of lines, etc. | No |
(*) at least one attribute is mandatory. (**) sequence number becomes mandatory if it is needed to enforce uniqueness for multiple valid satellites on the same hub or link.
Reference tables
Reference tables are a normal part of a healthy data vault model. They are there to prevent redundant storage of simple reference data that is referenced a lot. More formally, Dan Linstedt defines reference data as follows:
Any information deemed necessary to resolve descriptions from codes, or to translate keys in to (sic) a consistent manner. Many of these fields are "descriptive" in nature and describe a specific state of the other more important information. As such, reference data lives in separate tables from the raw Data Vault tables.[25]
Reference tables are referenced from Satellites, but never bound with physical foreign keys. There is no prescribed structure for reference tables: use what works best in your specific case, ranging from simple lookup tables to small data vaults or even stars. They can be historical or have no history, but it is recommended that you stick to the natural keys and not create surrogate keys in that case.[26] Normally, data vaults have a lot of reference tables, just like any other Data Warehouse.
Reference example
This is an example of a reference table with risk categories for drivers of vehicles. It can be referenced from any satellite in the data vault. For now we reference it from satellite S_DRIVER_INSURANCE. The reference table is R_RISK_CATEGORY.
| Fieldname | Description | Mandatory? |
|---|---|---|
| R_RISK_CATEGORY_CD | The code for the risk category | Yes |
| RISK_CATEGORY_DESC | A description of the risk category | No (*) |
(*) at least one attribute is mandatory.
Loading practices
The ETL for updating a data vault model is fairly straightforward (see Data Vault Series 5 – Loading Practices). First you have to load all the hubs, creating surrogate IDs for any new business keys. Having done that, you can now resolve all business keys to surrogate ID's if you query the hub. The second step is to resolve the links between hubs and create surrogate IDs for any new associations. At the same time, you can also create all satellites that are attached to hubs, since you can resolve the key to a surrogate ID. Once you have created all the new links with their surrogate keys, you can add the satellites to all the links.
Since the hubs are not joined to each other except through links, you can load all the hubs in parallel. Since links are not attached directly to each other, you can load all the links in parallel as well. Since satellites can be attached only to hubs and links, you can also load these in parallel.
The ETL is quite straightforward and lends itself to easy automation or templating. Problems occur only with links relating to other links, because resolving the business keys in the link only leads to another link that has to be resolved as well. Due to the equivalence of this situation with a link to multiple hubs, this difficulty can be avoided by remodeling such cases and this is in fact the recommended practice.[16]
Data is never deleted from the data vault, unless you have a technical error while loading data.
Data vault and dimensional modelling
The data vault modelled layer is normally used to store data. It is not optimised for query performance, nor is it easy to query by the well-known query-tools such as Cognos, Oracle Business Intelligence Suite Enterprise Edition, SAP Business Objects, Pentaho et al. Since these end-user computing tools expect or prefer their data to be contained in a dimensional model, a conversion is usually necessary.
For this purpose, the hubs and related satellites on those hubs can be considered as dimensions and the links and related satellites on those links can be viewed as fact tables in a dimensional model. This enables you to quickly prototype a dimensional model out of a data vault model using views.
Note that while it is relatively straightforward to move data from a data vault model to a (cleansed) dimensional model, the reverse is not as easy, given the denormalized nature of the dimensional model's fact tables, fundamentally different to the third normal form of the data vault.[27]
Data vault methodology
The data vault methodology is based on SEI/CMMI Level 5 best practices. It includes multiple components of CMMI Level 5, and combines them with best practices from Six Sigma, TQM, and SDLC. Particularly, it is focused on Scott Ambler's agile methodology for build out and deployment. Data vault projects have a short, scope-controlled release cycle and should consist of a production release every 2 to 3 weeks.
Teams using the data vault methodology should readily adapt to the repeatable, consistent, and measurable projects that are expected at CMMI Level 5. Data that flow through the EDW data vault system will begin to follow the TQM (total quality management) life-cycle that has long been missing from BI (business intelligence) projects.
Tools
Some examples of tools are:
See also
- Bill Inmon
- Data warehouse
- The Kimball lifecycle, developed by Ralph Kimball
- Persistent staging area
References
Citations
- Super Charge your data warehouse, page 74
- The next generation EDW
- Building a scalable datawarehouse with data vault 2.0, p. 6
- Super Charge your data warehouse, page 21
- Super Charge your data warehouse, page 76
- Porsby, Johan. "Rålager istället för ett strukturerat datalager". www.agero.se (in Swedish). Retrieved 2023-02-22.
- Porsby, Johan. "Datamodeller för data warehouse". www.agero.se (in Swedish). Retrieved 2023-02-22.
- Building a scalable datawarehouse with data vault 2.0, p. 11
- Building a scalable datawarehouse with data vault 2.0, p. xv
- The New Business Supermodel, glossary, page 75
- A short intro to#datavault 2.0
- Data Vault Series 1 – Data Vault Overview
- Data Vault Series 2 – Data Vault Components
- Data Vault Series 3 – End Dates and Basic Joins
- Data Vault Series 4 – Link tables, paragraph 2.3
- Data Vault Series 5 – Loading Practices
- Data Warehousing for Dummies, page 83
- A short intro to #datavault 2.0
- Data Vault 2.0 Being Announced
- Super Charge your Data Warehouse, paragraph 5.20, page 110
- Super Charge your data warehouse, page 61, why are business keys important
- Data Vault Forum, Standards section, section 3.0 Hub Rules
- Data Vault Modeling Specification v1.0.9
- Effectivity Satellites - dbtvault
- Super Charge your Data Warehouse, paragraph 8.0, page 146
- Super Charge your Data Warehouse, paragraph 8.0, page 149
- Melbournevault, 16 May 2023
Sources
- Linstedt, Dan (December 2010). Super Charge your Data Warehouse. Dan Linstedt. ISBN 978-0-9866757-1-3.
- Thomas C. Hammergren; Alan R. Simon (February 2009). Data Warehousing for Dummies, 2nd edition. John Wiley & Sons. ISBN 978-0-470-40747-9.
- Ronald Damhof; Lidwine van As (August 25, 2008). "The next generation EDW – Letting go of the idea of a single version of the truth" (PDF). Database Magazine (DB/M). Array Publications B.V.
- Linstedt, Dan. "Data Vault Series 1 – Data Vault Overview". Data Vault Series. The Data Administration Newsletter. Retrieved 12 September 2011.
- Linstedt, Dan. "Data Vault Series 2 – Data Vault Components". Data Vault Series. The Data Administration Newsletter. Retrieved 12 September 2011.
- Linstedt, Dan. "Data Vault Series 3 – End Dates and Basic Joins". Data Vault Series. The Data Administration Newsletter. Retrieved 12 September 2011.
- Linstedt, Dan. "Data Vault Series 4 – Link Tables". Data Vault Series. The Data Administration Newsletter. Retrieved 12 September 2011.
- Linstedt, Dan. "Data Vault Series 5 – Loading Practices". Data Vault Series. The Data Administration Newsletter. Retrieved 12 September 2011.
- Kunenborg, Ronald. "Data Vault Rules v1.0.8 Cheat Sheet" (PDF). Data Vault Rules. Grundsätzlich IT. Retrieved 26 September 2012. Cheat sheet reflecting the rules in v1.0.8 and additional clarification from the forums on the rules in v1.0.8.
- Linstedt, Dan. "Data Vault Modeling Specification v1.0.9". Data Vault Forum. Dan Linstedt. Retrieved 26 September 2012.
- Linstedt, Dan. "Data Vault Loading Specification v1.2". DanLinstedt.com. Dan Linstedt. Retrieved 2014-01-03.
- Linstedt, Dan. "A short intro to #datavault 2.0". DanLinstedt.com. Dan Linstedt. Retrieved 2014-01-03.
- Linstedt, Dan. "Data Vault 2.0 Being Announced". DanLinstedt.com. Dan Linstedt. Retrieved 2014-01-03.
- Dutch language sources
- Ketelaars, M.W.A.M. (2005-11-25). "Datawarehouse-modelleren met Data Vault". Database Magazine (DB/M). Array Publications B.V. (7): 36–40.
- Verhagen, K.; Vrijkorte, B. (June 10, 2008). "Relationeel versus Data Vault". Database Magazine (DB/M). Array Publications B.V. (4): 6–9.
Literature
- Patrick Cuba: The Data Vault Guru. A Pragmatic Guide on Building a Data Vault. Selbstverlag, ohne Ort 2020, ISBN 979-86-9130808-6.
- John Giles: The Elephant in the Fridge. Guided Steps to Data Vault Success through Building Business-Centered Models. Technics, Basking Ridge 2019, ISBN 978-1-63462-489-3.
- Kent Graziano: Better Data Modeling. An Introduction to Agile Data Engineering Using Data Vault 2.0. Data Warrior, Houston 2015.
- Hans Hultgren: Modeling the Agile Data Warehouse with Data Vault. Brighton Hamilton, Denver u. a. 2012, ISBN 978-0-615-72308-2.
- Dirk Lerner: Data Vault für agile Data-Warehouse-Architekturen. In: Stephan Trahasch, Michael Zimmer (Hrsg.): Agile Business Intelligence. Theorie und Praxis. dpunkt.verlag, Heidelberg 2016, ISBN 978-3-86490-312-0, S. 83–98.
- Daniel Linstedt: Super Charge Your Data Warehouse. Invaluable Data Modeling Rules to Implement Your Data Vault. Linstedt, Saint Albans, Vermont 2011, ISBN 978-1-4637-7868-2.
- Daniel Linstedt, Michael Olschimke: Building a Scalable Data Warehouse with Data Vault 2.0. Morgan Kaufmann, Waltham, Massachusetts 2016, ISBN 978-0-12-802510-9.
- Dani Schnider, Claus Jordan u. a.: Data Warehouse Blueprints. Business Intelligence in der Praxis. Hanser, München 2016, ISBN 978-3-446-45075-2, S. 35–37, 161–173.
External links
- The home for the Data Vault community users
- The path to Certification
- The homepage of Dan Linstedt, the inventor of Data Vault modeling
- A website dedicated to Data Vault, maintained by Dan Linstedt
- Youtube videos on Data Vault Modeling Approach and Methodology
- Dan Linstedt's Slide Share Site
- Data Vault Certification Site
- Agile Data Site
- Disciplined Agile Delivery (DAD) Site