Data Preprocessing
Data preprocessing can refer to manipulation or dropping of data before it is used in order to ensure or enhance performance,[1] and is an important step in the data mining process. The phrase "garbage in, garbage out" is particularly applicable to data mining and machine learning projects. Data collection methods are often loosely controlled, resulting in out-of-range values, impossible data combinations, and missing values, amongst other issues.
Analyzing data that has not been carefully screened for such problems can produce misleading results. Thus, representation and quality of data is necessary before running any analysis.[2] Often, data preprocessing is the most important phase of a machine learning project, especially in computational biology.[3] If there is a high proportion of irrelevant and redundant information present or noisy and unreliable data, then knowledge discovery during the training phase may be more difficult. Data preparation and filtering steps can take a considerable amount of processing time. Examples of methods used in data preprocessing include cleaning, instance selection, normalization, one-hot encoding, data transformation, feature extraction and feature selection.
Applications
Data mining
The origins of data preprocessing are located in data mining. The idea is to aggregate existing information and search in the content. Later it was recognized, that for machine learning and neural networks a data preprocessing step is needed too. So it has become to a universal technique which is used in computing in general.
Data preprocessing allows for the removal of unwanted data with the use of data cleaning, this allows the user to have a dataset to contain more valuable information after the preprocessing stage for data manipulation later in the data mining process. Editing such dataset to either correct data corruption or human error is a crucial step to get accurate quantifiers like true positives, true negatives, false positives and false negatives found in a confusion matrix that are commonly used for a medical diagnosis. Users are able to join data files together and use preprocessing to filter any unnecessary noise from the data which can allow for higher accuracy. Users use Python programming scripts accompanied by the pandas library which gives them the ability to import data from a comma-separated values as a data-frame. The data-frame is then used to manipulate data that can be challenging otherwise to do in Excel. pandas (software) which is a powerful tool that allows for data analysis and manipulation; which makes data visualizations, statistical operations and much more, a lot easier. Many also use the R programming language to do such tasks as well.
The reason why a user transforms existing files into a new one is because of many reasons. Data preprocessing has the objective to add missing values, aggregate information, label data with categories (data binning) and smooth a trajectory. More advanced techniques like principal component analysis and feature selection are working with statistical formulas and are applied to complex datasets which are recorded by GPS trackers and motion capture devices.
Semantic data preprocessing
Semantic data mining is a subset of data mining that specifically seeks to incorporate domain knowledge, such as formal semantics, into the data mining process. Domain knowledge is the knowledge of the environment the data was processed in. Domain knowledge can have a positive influence on many aspects of data mining, such as filtering out redundant or inconsistent data during the preprocessing phase.[4] Domain knowledge also works as constraint. It does this by using working as set of prior knowledge to reduce the space required for searching and acting as a guide to the data. Simply put, semantic preprocessing seeks to filter data using the original environment of said data more correctly and efficiently.
There are increasingly complex problems which are asking to be solved by more elaborate techniques to better analyze existing information. Instead of creating a simple script for aggregating different numerical values into a single value, it make sense to focus on semantic based data preprocessing.[5] The idea is to build a dedicated ontology, which explains on a higher level what the problem is about.[6] In regards to semantic data mining and semantic pre-processing, ontologies are a way to conceptualize and formally define semantic knowledge and data. The Protégé (software) is the standard tool for constructing an ontology. In general, the use of ontologies bridges the gaps between data, applications, algorithms, and results that occur from semantic mismatches. As a result, semantic data mining combined with ontology has many applications where semantic ambiguity can impact the usefulness and efficiency of data systems. Applications include the medical field, language processing, banking,[7] and even tutoring,[8] among many more.
There are various strengths to using a semantic data mining and ontological based approach. As previously mentioned, these tools can help during the per-processing phase by filtering out non-desirable data from the data set. Additionally, well-structured formal semantics integrated into well designed ontologies can return powerful data that can be easily read and processed by machines.[9] A specifically useful example of this exists in the medical use of semantic data processing. As an example, a patient is having a medical emergency and is being rushed to hospital. The emergency responders are trying to figure out the best medicine to administer to help the patient. Under normal data processing, scouring all the patient’s medical data to ensure they are getting the best treatment could take too long and risk the patients’ health or even life. However, using semantically processed ontologies, the first responders could save the patient’s life. Tools like a semantic reasoner can use ontology to infer the what best medicine to administer to the patient is based on their medical history, such as if they have a certain cancer or other conditions, simply by examining the natural language used in the patient's medical records.[10] This would allow the first responders to quickly and efficiently search for medicine without having worry about the patient’s medical history themselves, as the semantic reasoner would already have analyzed this data and found solutions. In general, this illustrates the incredible strength of using semantic data mining and ontologies. They allow for quicker and more efficient data extraction on the user side, as the user has fewer variables to account for, since the semantically pre-processed data and ontology built for the data have already accounted for many of these variables. However, there are some drawbacks to this approach. Namely, it requires a high amount of computational power and complexity, even with relatively small data sets.[11] This could result in higher costs and increased difficulties in building and maintaining semantic data processing systems. This can be mitigated somewhat if the data set is already well organized and formatted, but even then, the complexity is still higher when compared to standard data processing.
Below is a simple a diagram combining some of the processes, in particular semantic data mining and their use in ontology.
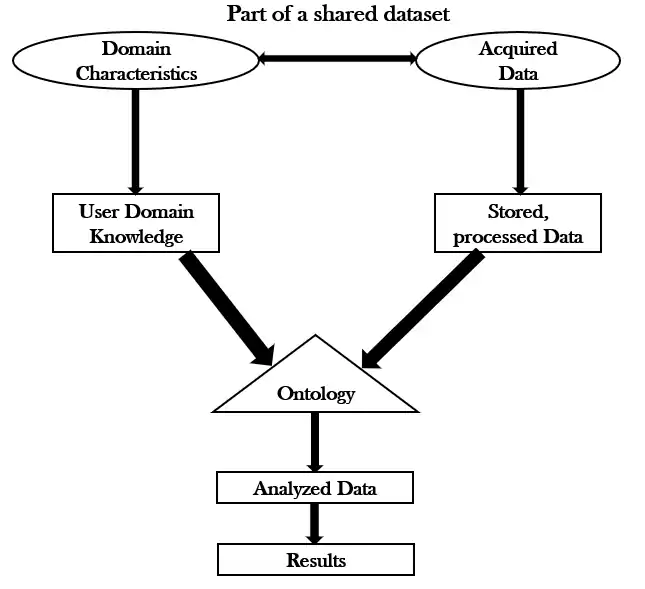
The diagram depicts a data set being broken up into two parts: the characteristics of its domain, or domain knowledge, and then the actual acquired data. The domain characteristics are then processed to become user understood domain knowledge that can be applied to the data. Meanwhile, the data set is processed and stored so that the domain knowledge can applied to it, so that the process may continue. This application forms the ontology. From there, the ontology can be used to analyze data and process results.
Fuzzy preprocessing is another, more advanced technique for solving complex problems. Fuzzy preprocessing and fuzzy data mining make use of fuzzy sets. These data sets are composed of two elements: a set and a membership function for the set which comprises 0 and 1. Fuzzy preprocessing uses this fuzzy data set to ground numerical values with linguistic information. Raw data is then transformed into natural language. Ultimately, fuzzy data mining's goal is to help deal with inexact information, such as an incomplete database. Currently fuzzy preprocessing, as well as other fuzzy based data mining techniques see frequent use with neural networks and artificial intelligence.[12]
References
- "Guide To Data Cleaning: Definition, Benefits, Components, And How To Clean Your Data". Tableau. Retrieved 2021-10-17.
- Pyle, D., 1999. Data Preparation for Data Mining. Morgan Kaufmann Publishers, Los Altos, California.
- Chicco D (December 2017). "Ten quick tips for machine learning in computational biology". BioData Mining. 10 (35): 35. doi:10.1186/s13040-017-0155-3. PMC 5721660. PMID 29234465.
- Dou, Deijing and Wang, Hao and Liu, Haishan. "Semantic Data Mining: A Survey of Ontology-based Approaches" (PDF). University of Oregon.
{{cite web}}: CS1 maint: multiple names: authors list (link) - Culmone, Rosario and Falcioni, Marco and Quadrini, Michela (2014). An ontology-based framework for semantic data preprocessing aimed at human activity recognition. SEMAPRO 2014: The Eighth International Conference on Advances in Semantic Processing. Alexey Cheptsov, High Performance Computing Center Stuttgart (HLRS). S2CID 196091422.
{{cite conference}}: CS1 maint: multiple names: authors list (link) - David Perez-Rey and Alberto Anguita and Jose Crespo (2006). OntoDataClean: Ontology-Based Integration and Preprocessing of Distributed Data. Biological and Medical Data Analysis. Springer Berlin Heidelberg. pp. 262–272. doi:10.1007/11946465_24.
- Yerashenia, Natalia and Bolotov, Alexander and Chan, David and Pierantoni, Gabriele (2020). "Semantic Data Pre-Processing for Machine Learning Based Bankruptcy Prediction Computational Model". 2020 IEEE 22nd Conference on Business Informatics (CBI) (PDF). IEEE. pp. 66–75. doi:10.1109/CBI49978.2020.00015. ISBN 978-1-7281-9926-9. S2CID 219499599.
{{cite book}}: CS1 maint: multiple names: authors list (link) - Chang, Maiga and D'Aniello, Giuseppe and Gaeta, Matteo and Orciuoli, Franceso and Sampson, Demetrois and Simonelli, Carmine (2020). "Building Ontology-Driven Tutoring Models for Intelligent Tutoring Systems Using Data Mining". IEEE Access. IEEE. 8: 48151–48162. doi:10.1109/ACCESS.2020.2979281. S2CID 214594754.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - Dou, Deijing and Wang, Hao and Liu, Haishan. "Semantic Data Mining: A Survey of Ontology-based Approaches" (PDF). University of Oregon.
{{cite web}}: CS1 maint: multiple names: authors list (link) - Kahn, Atif and Doucette, John A. and Jin, Changjiu and Fu Lijie and Cohen, Robin. "AN ONTOLOGICAL APPROACH TO DATA MINING FOR EMERGENCY MEDICINE" (PDF). University of Waterloo.
{{cite web}}: CS1 maint: multiple names: authors list (link) - Sirichanya, Chanmee and Kraisak Kesorn (2021). "Semantic data mining in the information age: A systematic review". International Journal of Intelligent Systems. 36 (8): 3880–3916. doi:10.1002/int.22443. S2CID 235506360.
- Wong, Kok Wai and Fung, Chun Che and Law, Kok Way (2000). "Fuzzy preprocessing rules for the improvement of an artificial neural network well log interpretation model". 2000 TENCON Proceedings. Intelligent Systems and Technologies for the New Millennium (Cat. No.00CH37119). Vol. 1. IEEE. pp. 400–405. doi:10.1109/TENCON.2000.893697. ISBN 0-7803-6355-8. S2CID 10384426.
{{cite book}}: CS1 maint: multiple names: authors list (link)