Priority queue
In computer science, a priority queue is an abstract data-type similar to a regular queue or stack data structure. Each element in a priority queue has an associated priority. In a priority queue, elements with high priority are served before elements with low priority. In some implementations, if two elements have the same priority, they are served in the same order in which they were enqueued. In other implementations, the order of elements with the same priority is undefined.
While priority queues are often implemented using heaps, they are conceptually distinct from heaps. A priority queue is an abstract data structure like a list or a map; just as a list can be implemented with a linked list or with an array, a priority queue can be implemented with a heap or another method such as an unordered array.
Operations
A priority queue must at least support the following operations:
- is_empty: check whether the queue has no elements.
- insert_with_priority: add an element to the queue with an associated priority.
- pull_highest_priority_element: remove the element from the queue that has the highest priority, and return it.
- This is also known as "pop_element(Off)", "get_maximum_element" or "get_front(most)_element".
- Some conventions reverse the order of priorities, considering lower values to be higher priority, so this may also be known as "get_minimum_element", and is often referred to as "get-min" in the literature.
- This may instead be specified as separate "peek_at_highest_priority_element" and "delete_element" functions, which can be combined to produce "pull_highest_priority_element".
In addition, peek (in this context often called find-max or find-min), which returns the highest-priority element but does not modify the queue, is very frequently implemented, and nearly always executes in O(1) time. This operation and its O(1) performance is crucial to many applications of priority queues.
More advanced implementations may support more complicated operations, such as pull_lowest_priority_element, inspecting the first few highest- or lowest-priority elements, clearing the queue, clearing subsets of the queue, performing a batch insert, merging two or more queues into one, incrementing priority of any element, etc.
Stacks and queues can be implemented as particular kinds of priority queues, with the priority determined by the order in which the elements are inserted. In a stack, the priority of each inserted element is monotonically increasing; thus, the last element inserted is always the first retrieved. In a queue, the priority of each inserted element is monotonically decreasing; thus, the first element inserted is always the first retrieved.
Implementation
Naive implementations
There are a variety of simple, usually inefficient, ways to implement a priority queue. They provide an analogy to help one understand what a priority queue is.
For instance, one can keep all the elements in an unsorted list (O(1) insertion time). Whenever the highest-priority element is requested, search through all elements for the one with the highest priority. (O(n) pull time),
insert(node)
{
list.append(node)
}
pull()
{
highest = list.get_first_element()
foreach node in list
{
if highest.priority < node.priority
{
highest = node
}
}
list.remove(highest)
return highest
}
In another case, one can keep all the elements in a priority sorted list (O(n) insertion sort time), whenever the highest-priority element is requested, the first one in the list can be returned. (O(1) pull time)
insert(node)
{
foreach (index, element) in list
{
if node.priority < element.priority
{
list.insert_at_index(node,index)
break
}
}
}
pull()
{
highest = list.get_at_index(list.length-1)
list.remove(highest)
return highest
}
Usual implementation
To improve performance, priority queues are typically based on a heap, giving O(log n) performance for inserts and removals, and O(n) to build the heap initially from a set of n elements. Variants of the basic heap data structure such as pairing heaps or Fibonacci heaps can provide better bounds for some operations.[1]
Alternatively, when a self-balancing binary search tree is used, insertion and removal also take O(log n) time, although building trees from existing sequences of elements takes O(n log n) time; this is typical where one might already have access to these data structures, such as with third-party or standard libraries. From a space-complexity standpoint, using self-balancing binary search tree with linked list takes more storage, since it requires to store extra references to other nodes.
From a computational-complexity standpoint, priority queues are congruent to sorting algorithms. The section on the equivalence of priority queues and sorting algorithms, below, describes how efficient sorting algorithms can create efficient priority queues.
Specialized heaps
There are several specialized heap data structures that either supply additional operations or outperform heap-based implementations for specific types of keys, specifically integer keys. Suppose the set of possible keys is {1, 2, ..., C}.
- When only insert, find-min and extract-min are needed and in case of integer priorities, a bucket queue can be constructed as an array of C linked lists plus a pointer top, initially C. Inserting an item with key k appends the item to the k'th list, and updates top ← min(top, k), both in constant time. Extract-min deletes and returns one item from the list with index top, then increments top if needed until it again points to a non-empty list; this takes O(C) time in the worst case. These queues are useful for sorting the vertices of a graph by their degree.[2]: 374
- A van Emde Boas tree supports the minimum, maximum, insert, delete, search, extract-min, extract-max, predecessor and successor] operations in O(log log C) time, but has a space cost for small queues of about O(2m/2), where m is the number of bits in the priority value.[3] The space can be reduced significantly with hashing.
- The Fusion tree by Fredman and Willard implements the minimum operation in O(1) time and insert and extract-min operations in time. However it is stated by the author that, "Our algorithms have theoretical interest only; The constant factors involved in the execution times preclude practicality."[4]

For applications that do many "peek" operations for every "extract-min" operation, the time complexity for peek actions can be reduced to O(1) in all tree and heap implementations by caching the highest priority element after every insertion and removal. For insertion, this adds at most a constant cost, since the newly inserted element is compared only to the previously cached minimum element. For deletion, this at most adds an additional "peek" cost, which is typically cheaper than the deletion cost, so overall time complexity is not significantly impacted.
Monotone priority queues are specialized queues that are optimized for the case where no item is ever inserted that has a lower priority (in the case of min-heap) than any item previously extracted. This restriction is met by several practical applications of priority queues.
Summary of running times
Here are time complexities[5] of various heap data structures. Function names assume a min-heap. For the meaning of "O(f)" and "Θ(f)" see Big O notation.
| Operation | find-min | delete-min | insert | decrease-key | meld |
|---|---|---|---|---|---|
| Binary[5] | Θ(1) | Θ(log n) | O(log n) | O(log n) | Θ(n) |
| Leftist | Θ(1) | Θ(log n) | Θ(log n) | O(log n) | Θ(log n) |
| Binomial[5][6] | Θ(1) | Θ(log n) | Θ(1)[lower-alpha 1] | Θ(log n) | O(log n) |
| Skew binomial[7] | Θ(1) | Θ(log n) | Θ(1) | Θ(log n) | O(log n)[lower-alpha 2] |
| Pairing[8] | Θ(1) | O(log n)[lower-alpha 1] | Θ(1) | o(log n)[lower-alpha 1][lower-alpha 3] | Θ(1) |
| Rank-pairing[11] | Θ(1) | O(log n)[lower-alpha 1] | Θ(1) | Θ(1)[lower-alpha 1] | Θ(1) |
| Fibonacci[5][12] | Θ(1) | O(log n)[lower-alpha 1] | Θ(1) | Θ(1)[lower-alpha 1] | Θ(1) |
| Strict Fibonacci[13] | Θ(1) | O(log n) | Θ(1) | Θ(1) | Θ(1) |
| Brodal[14][lower-alpha 4] | Θ(1) | O(log n) | Θ(1) | Θ(1) | Θ(1) |
| 2–3 heap[16] | O(log n) | O(log n)[lower-alpha 1] | O(log n)[lower-alpha 1] | Θ(1) | ? |
- Amortized time.
- Brodal and Okasaki describe a technique to reduce the worst-case complexity of meld to Θ(1); this technique applies to any heap datastructure that has insert in Θ(1) and find-min, delete-min, meld in O(log n).
- Lower bound of [9] upper bound of [10]
- Brodal and Okasaki later describe a persistent variant with the same bounds except for decrease-key, which is not supported. Heaps with n elements can be constructed bottom-up in O(n).[15]


Equivalence of priority queues and sorting algorithms
Using a priority queue to sort
The semantics of priority queues naturally suggest a sorting method: insert all the elements to be sorted into a priority queue, and sequentially remove them; they will come out in sorted order. This is actually the procedure used by several sorting algorithms, once the layer of abstraction provided by the priority queue is removed. This sorting method is equivalent to the following sorting algorithms:
| Name | Priority Queue Implementation | Best | Average | Worst |
|---|---|---|---|---|
| Heapsort | Heap | |||
| Smoothsort | Leonardo Heap | |||
| Selection sort | Unordered Array | |||
| Insertion sort | Ordered Array | |||
| Tree sort | Self-balancing binary search tree |



Using a sorting algorithm to make a priority queue
A sorting algorithm can also be used to implement a priority queue. Specifically, Thorup says:[17]
We present a general deterministic linear space reduction from priority queues to sorting implying that if we can sort up to n keys in S(n) time per key, then there is a priority queue supporting delete and insert in O(S(n)) time and find-min in constant time.
That is, if there is a sorting algorithm which can sort in O(S) time per key, where S is some function of n and word size,[18] then one can use the given procedure to create a priority queue where pulling the highest-priority element is O(1) time, and inserting new elements (and deleting elements) is O(S) time. For example, if one has an O(n log n) sort algorithm, one can create a priority queue with O(1) pulling and O( log n) insertion.
Libraries
A priority queue is often considered to be a "container data structure".
The Standard Template Library (STL), and the C++ 1998 standard, specifies std::priority_queue as one of the STL container adaptor class templates. However, it does not specify how two elements with same priority should be served, and indeed, common implementations will not return them according to their order in the queue. It implements a max-priority-queue, and has three parameters: a comparison object for sorting such as a function object (defaults to less<T> if unspecified), the underlying container for storing the data structures (defaults to std::vector<T>), and two iterators to the beginning and end of a sequence. Unlike actual STL containers, it does not allow iteration of its elements (it strictly adheres to its abstract data type definition). STL also has utility functions for manipulating another random-access container as a binary max-heap. The Boost libraries also have an implementation in the library heap.
Python's heapq module implements a binary min-heap on top of a list.
Java's library contains a PriorityQueue class, which implements a min-priority-queue.
.NET's library contains a PriorityQueue class, which implements an array-backed, quaternary min-heap.
Scala's library contains a PriorityQueue class, which implements a max-priority-queue.
Go's library contains a container/heap module, which implements a min-heap on top of any compatible data structure.
The Standard PHP Library extension contains the class SplPriorityQueue.
Apple's Core Foundation framework contains a CFBinaryHeap structure, which implements a min-heap.
Applications
Bandwidth management
Priority queuing can be used to manage limited resources such as bandwidth on a transmission line from a network router. In the event of outgoing traffic queuing due to insufficient bandwidth, all other queues can be halted to send the traffic from the highest priority queue upon arrival. This ensures that the prioritized traffic (such as real-time traffic, e.g. an RTP stream of a VoIP connection) is forwarded with the least delay and the least likelihood of being rejected due to a queue reaching its maximum capacity. All other traffic can be handled when the highest priority queue is empty. Another approach used is to send disproportionately more traffic from higher priority queues.
Many modern protocols for local area networks also include the concept of priority queues at the media access control (MAC) sub-layer to ensure that high-priority applications (such as VoIP or IPTV) experience lower latency than other applications which can be served with best-effort service. Examples include IEEE 802.11e (an amendment to IEEE 802.11 which provides quality of service) and ITU-T G.hn (a standard for high-speed local area network using existing home wiring (power lines, phone lines and coaxial cables).
Usually a limitation (policer) is set to limit the bandwidth that traffic from the highest priority queue can take, in order to prevent high priority packets from choking off all other traffic. This limit is usually never reached due to high level control instances such as the Cisco Callmanager, which can be programmed to inhibit calls which would exceed the programmed bandwidth limit.
Discrete event simulation
Another use of a priority queue is to manage the events in a discrete event simulation. The events are added to the queue with their simulation time used as the priority. The execution of the simulation proceeds by repeatedly pulling the top of the queue and executing the event thereon.
See also: Scheduling (computing), queueing theory
Dijkstra's algorithm
When the graph is stored in the form of adjacency list or matrix, priority queue can be used to extract minimum efficiently when implementing Dijkstra's algorithm, although one also needs the ability to alter the priority of a particular vertex in the priority queue efficiently.
If instead, a graph is stored as node objects, and priority-node pairs are inserted into a heap, altering the priority of a particular vertex is not necessary if one tracks visited nodes. Once a node is visited, if it comes up in the heap again (having had a lower priority number associated with it earlier), it is popped-off and ignored.
Huffman coding
Huffman coding requires one to repeatedly obtain the two lowest-frequency trees. A priority queue is one method of doing this.
Best-first search algorithms
Best-first search algorithms, like the A* search algorithm, find the shortest path between two vertices or nodes of a weighted graph, trying out the most promising routes first. A priority queue (also known as the fringe) is used to keep track of unexplored routes; the one for which the estimate (a lower bound in the case of A*) of the total path length is smallest is given highest priority. If memory limitations make best-first search impractical, variants like the SMA* algorithm can be used instead, with a double-ended priority queue to allow removal of low-priority items.
ROAM triangulation algorithm
The Real-time Optimally Adapting Meshes (ROAM) algorithm computes a dynamically changing triangulation of a terrain. It works by splitting triangles where more detail is needed and merging them where less detail is needed. The algorithm assigns each triangle in the terrain a priority, usually related to the error decrease if that triangle would be split. The algorithm uses two priority queues, one for triangles that can be split and another for triangles that can be merged. In each step the triangle from the split queue with the highest priority is split, or the triangle from the merge queue with the lowest priority is merged with its neighbours.
Prim's algorithm for minimum spanning tree
Using min heap priority queue in Prim's algorithm to find the minimum spanning tree of a connected and undirected graph, one can achieve a good running time. This min heap priority queue uses the min heap data structure which supports operations such as insert, minimum, extract-min, decrease-key.[19] In this implementation, the weight of the edges is used to decide the priority of the vertices. Lower the weight, higher the priority and higher the weight, lower the priority.[20]
Parallel priority queue
Parallelization can be used to speed up priority queues, but requires some changes to the priority queue interface. The reason for such changes is that a sequential update usually only has or cost, and there is no practical gain to parallelize such an operation. One possible change is to allow the concurrent access of multiple processors to the same priority queue. The second possible change is to allow batch operations that work on elements, instead of just one element. For example, extractMin will remove the first elements with the highest priority.



Concurrent parallel access
If the priority queue allows concurrent access, multiple processes can perform operations concurrently on that priority queue. However, this raises two issues. First of all, the definition of the semantics of the individual operations is no longer obvious. For example, if two processes want to extract the element with the highest priority, should they get the same element or different ones? This restricts parallelism on the level of the program using the priority queue. In addition, because multiple processes have access to the same element, this leads to contention.

The concurrent access to a priority queue can be implemented on a Concurrent Read, Concurrent Write (CRCW) PRAM model. In the following the priority queue is implemented as a skip list.[21][22] In addition, an atomic synchronization primitive, CAS, is used to make the skip list lock-free. The nodes of the skip list consists of a unique key, a priority, an array of pointers, for each level, to the next nodes and a delete mark. The delete mark marks if the node is about to be deleted by a process. This ensures that other processes can react to the deletion appropriately.
- insert(e): First, a new node with a key and a priority is created. In addition, the node is assigned a number of levels, which dictates the size of the array of pointers. Then a search is performed to find the correct position where to insert the new node. The search starts from the first node and from the highest level. Then the skip list is traversed down to the lowest level until the correct position is found. During the search, for every level the last traversed node will be saved as parent node for the new node at that level. In addition, the node to which the pointer, at that level, of the parent node points towards, will be saved as the successor node of the new node at that level. Afterwards, for every level of the new node, the pointers of the parent node will be set to the new node. Finally, the pointers, for every level, of the new node will be set to the corresponding successor nodes.
- extract-min: First, the skip list is traversed until a node is reached whose delete mark is not set. This delete mark is than set to true for that node. Finally the pointers of the parent nodes of the deleted node are updated.
If the concurrent access to a priority queue is allowed, conflicts may arise between two processes. For example, a conflict arises if one process is trying to insert a new node, but at the same time another process is about to delete the predecessor of that node.[21] There is a risk that the new node is added to the skip list, yet it is not longer reachable. (See image)
K-element operations
In this setting, operations on a priority queue is generalized to a batch of elements. For instance, k_extract-min deletes the smallest elements of the priority queue and returns those.
In a shared-memory setting, the parallel priority queue can be easily implemented using parallel binary search trees and join-based tree algorithms. In particular, k_extract-min corresponds to a split on the binary search tree that has cost and yields a tree that contains the smallest elements. k_insert can be applied by a union of the original priority queue and the batch of insertions. If the batch is already sorted by the key, k_insert has cost. Otherwise, we need to first sort the batch, so the cost will be . Other operations for priority queue can be applied similarly. For instance, k_decrease-key can be done by first applying difference and then union, which first deletes the elements and then inserts them back with the updated keys. All these operations are highly parallel, and the theoretical and practical efficiency can be found in related research papers.[23][24]


The rest of this section discusses a queue-based algorithm on distributed memory. We assume each processor has its own local memory and a local (sequential) priority queue. The elements of the global (parallel) priority queue are distributed across all processors.
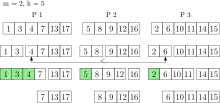
A k_insert operation assigns the elements uniformly random to the processors which insert the elements into their local queues. Note that single elements can still be inserted into the queue. Using this strategy the global smallest elements are in the union of the local smallest elements of every processor with high probability. Thus each processor holds a representative part of the global priority queue.
This property is used when k_extract-min is executed, as the smallest elements of each local queue are removed and collected in a result set. The elements in the result set are still associated with their original processor. The number of elements that is removed from each local queue depends on and the number of processors . [25] By parallel selection the smallest elements of the result set are determined. With high probability these are the global smallest elements. If not, elements are again removed from each local queue and put into the result set. This is done until the global smallest elements are in the result set. Now these elements can be returned. All other elements of the result set are inserted back into their local queues. The running time of k_extract-min is expected , where and is the size of the priority queue.[25]





The priority queue can be further improved by not moving the remaining elements of the result set directly back into the local queues after a k_extract-min operation. This saves moving elements back and forth all the time between the result set and the local queues.
By removing several elements at once a considerable speedup can be reached. But not all algorithms can use this kind of priority queue. Dijkstra's algorithm for example can not work on several nodes at once. The algorithm takes the node with the smallest distance from the priority queue and calculates new distances for all its neighbor nodes. If you would take out nodes, working at one node could change the distance of another one of the nodes. So using k-element operations destroys the label setting property of Dijkstra's algorithm.
See also
References
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001) [1990]. "Chapter 20: Fibonacci Heaps". Introduction to Algorithms (2nd ed.). MIT Press and McGraw-Hill. pp. 476–497. ISBN 0-262-03293-7. Third edition, p. 518.
- Skiena, Steven (2010). The Algorithm Design Manual (2nd ed.). Springer Science+Business Media. ISBN 978-1-849-96720-4.
- P. van Emde Boas. Preserving order in a forest in less than logarithmic time. In Proceedings of the 16th Annual Symposium on Foundations of Computer Science, pages 75-84. IEEE Computer Society, 1975.
- Michael L. Fredman and Dan E. Willard. Surpassing the information theoretic bound with fusion trees. Journal of Computer and System Sciences, 48(3):533-551, 1994
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L. (1990). Introduction to Algorithms (1st ed.). MIT Press and McGraw-Hill. ISBN 0-262-03141-8.
- "Binomial Heap | Brilliant Math & Science Wiki". brilliant.org. Retrieved 2019-09-30.
- Brodal, Gerth Stølting; Okasaki, Chris (November 1996), "Optimal purely functional priority queues", Journal of Functional Programming, 6 (6): 839–857, doi:10.1017/s095679680000201x
- Iacono, John (2000), "Improved upper bounds for pairing heaps", Proc. 7th Scandinavian Workshop on Algorithm Theory (PDF), Lecture Notes in Computer Science, vol. 1851, Springer-Verlag, pp. 63–77, arXiv:1110.4428, CiteSeerX 10.1.1.748.7812, doi:10.1007/3-540-44985-X_5, ISBN 3-540-67690-2
- Fredman, Michael Lawrence (July 1999). "On the Efficiency of Pairing Heaps and Related Data Structures" (PDF). Journal of the Association for Computing Machinery. 46 (4): 473–501. doi:10.1145/320211.320214.
- Pettie, Seth (2005). Towards a Final Analysis of Pairing Heaps (PDF). FOCS '05 Proceedings of the 46th Annual IEEE Symposium on Foundations of Computer Science. pp. 174–183. CiteSeerX 10.1.1.549.471. doi:10.1109/SFCS.2005.75. ISBN 0-7695-2468-0.
- Haeupler, Bernhard; Sen, Siddhartha; Tarjan, Robert E. (November 2011). "Rank-pairing heaps" (PDF). SIAM J. Computing. 40 (6): 1463–1485. doi:10.1137/100785351.
- Fredman, Michael Lawrence; Tarjan, Robert E. (July 1987). "Fibonacci heaps and their uses in improved network optimization algorithms" (PDF). Journal of the Association for Computing Machinery. 34 (3): 596–615. CiteSeerX 10.1.1.309.8927. doi:10.1145/28869.28874.
- Brodal, Gerth Stølting; Lagogiannis, George; Tarjan, Robert E. (2012). Strict Fibonacci heaps (PDF). Proceedings of the 44th symposium on Theory of Computing - STOC '12. pp. 1177–1184. CiteSeerX 10.1.1.233.1740. doi:10.1145/2213977.2214082. ISBN 978-1-4503-1245-5.
- Brodal, Gerth S. (1996), "Worst-Case Efficient Priority Queues" (PDF), Proc. 7th Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 52–58
- Goodrich, Michael T.; Tamassia, Roberto (2004). "7.3.6. Bottom-Up Heap Construction". Data Structures and Algorithms in Java (3rd ed.). pp. 338–341. ISBN 0-471-46983-1.
- Takaoka, Tadao (1999), Theory of 2–3 Heaps (PDF), p. 12
- Thorup, Mikkel (2007). "Equivalence between priority queues and sorting". Journal of the ACM. 54 (6): 28. doi:10.1145/1314690.1314692. S2CID 11494634.
- "Archived copy" (PDF). Archived (PDF) from the original on 2011-07-20. Retrieved 2011-02-10.
{{cite web}}: CS1 maint: archived copy as title (link) - Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009) [1990]. Introduction to Algorithms (3rd ed.). MIT Press and McGraw-Hill. p. 634. ISBN 0-262-03384-4. "In order to implement Prim's algorithm efficiently, we need a fast way to select a new edge to add to the tree formed by the edges in A."
- "Prim's Algorithm". Geek for Geeks. 18 November 2012. Archived from the original on 9 September 2014. Retrieved 12 September 2014.
- Sundell, Håkan; Tsigas, Philippas (2005). "Fast and lock-free concurrent priority queues for multi-thread systems". Journal of Parallel and Distributed Computing. 65 (5): 609–627. doi:10.1109/IPDPS.2003.1213189. S2CID 20995116.
- Lindén, Jonsson (2013), "A Skiplist-Based Concurrent Priority Queue with Minimal Memory Contention", Technical Report 2018-003 (in German)
- Blelloch, Guy E.; Ferizovic, Daniel; Sun, Yihan (2016), "Just Join for Parallel Ordered Sets", Symposium on Parallel Algorithms and Architectures, Proc. of 28th ACM Symp. Parallel Algorithms and Architectures (SPAA 2016), ACM, pp. 253–264, arXiv:1602.02120, doi:10.1145/2935764.2935768, ISBN 978-1-4503-4210-0, S2CID 2897793
- Blelloch, Guy E.; Ferizovic, Daniel; Sun, Yihan (2018), "PAM: parallel augmented maps", Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, ACM, pp. 290–304
- Sanders, Peter; Mehlhorn, Kurt; Dietzfelbinger, Martin; Dementiev, Roman (2019). Sequential and Parallel Algorithms and Data Structures - The Basic Toolbox. Springer International Publishing. pp. 226–229. doi:10.1007/978-3-030-25209-0. ISBN 978-3-030-25208-3. S2CID 201692657.
Further reading
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001) [1990]. "Section 6.5: Priority queues". Introduction to Algorithms (2nd ed.). MIT Press and McGraw-Hill. pp. 138–142. ISBN 0-262-03293-7.
External links
- C++ reference for
std::priority_queue - Descriptions by Lee Killough
- libpqueue is a generic priority queue (heap) implementation (in C) used by the Apache HTTP Server project.
- Survey of known priority queue structures by Stefan Xenos
- UC Berkeley - Computer Science 61B - Lecture 24: Priority Queues (video) - introduction to priority queues using binary heap