Van Emde Boas tree
A van Emde Boas tree (Dutch pronunciation: [vɑn ˈɛmdə ˈboːɑs]), also known as a vEB tree or van Emde Boas priority queue, is a tree data structure which implements an associative array with m-bit integer keys. It was invented by a team led by Dutch computer scientist Peter van Emde Boas in 1975.[1] It performs all operations in O(log m) time (assuming that an m bit operation can be performed in constant time), or equivalently in O(log log M) time, where M = 2m is the largest element that can be stored in the tree. The parameter M is not to be confused with the actual number of elements stored in the tree, by which the performance of other tree data-structures is often measured.
| van Emde Boas tree | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Type | Non-binary tree | |||||||||||||||
| Invented | 1975 | |||||||||||||||
| Invented by | Peter van Emde Boas | |||||||||||||||
| Time complexity in big O notation | ||||||||||||||||
| ||||||||||||||||
The vEB tree has poor space efficiency. For example, for storing 32-bit integers (i.e., when m=32), it requires M=232 bits of storage. However, similar data structures with equally good time efficiency and space O(n) exist, where n is the number of stored elements.
Supported operations
A vEB supports the operations of an ordered associative array, which includes the usual associative array operations along with two more order operations, FindNext and FindPrevious:[2]
- Insert: insert a key/value pair with an m-bit key
- Delete: remove the key/value pair with a given key
- Lookup: find the value associated with a given key
- FindNext: find the key/value pair with the smallest key which is greater than a given k
- FindPrevious: find the key/value pair with the largest key which is smaller than a given k
A vEB tree also supports the operations Minimum and Maximum, which return the minimum and maximum element stored in the tree respectively.[3] These both run in O(1) time, since the minimum and maximum element are stored as attributes in each tree.
Function
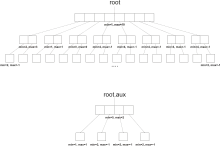
For the sake of simplicity, let log2 m = k for some integer k. Define M = 2m. A vEB tree T over the universe {0, ..., M−1} has a root node that stores an array T.children of length √M. T.children[i] is a pointer to a vEB tree that is responsible for the values {i√M, ..., (i+1)√M−1}. Additionally, T stores two values T.min and T.max as well as an auxiliary vEB tree T.aux.
Data is stored in a vEB tree as follows: The smallest value currently in the tree is stored in T.min and largest value is stored in T.max. Note that T.min is not stored anywhere else in the vEB tree, while T.max is. If T is empty then we use the convention that T.max=−1 and T.min=M. Any other value x is stored in the subtree T.children[i] where i = ⌊x/√M⌋. The auxiliary tree T.aux keeps track of which children are non-empty, so T.aux contains the value j if and only if T.children[j] is non-empty.
FindNext
The operation FindNext(T, x) that searches for the successor of an element x in a vEB tree proceeds as follows: If x<T.min then the search is complete, and the answer is T.min. If x≥T.max then the next element does not exist, return M. Otherwise, let i = ⌊x/√M⌋. If x<T.children[i].max then the value being searched for is contained in T.children[i] so the search proceeds recursively in T.children[i]. Otherwise, we search for the successor of the value i in T.aux. This gives us the index j of the first subtree that contains an element larger than x. The algorithm then returns T.children[j].min. The element found on the children level needs to be composed with the high bits to form a complete next element.
function FindNext(T, x)
if x < T.min then
return T.min
if x ≥ T.max then // no next element
return M
i = floor(x/√M)
lo = x mod √M
if lo < T.children[i].max then
return (√M i) + FindNext(T.children[i], lo)
j = FindNext(T.aux, i)
return (√M j) + T.children[j].min
end
Note that, in any case, the algorithm performs O(1) work and then possibly recurses on a subtree over a universe of size M1/2 (an m/2 bit universe). This gives a recurrence for the running time of , which resolves to O(log m) = O(log log M).

Insert
The call insert(T, x) that inserts a value x into a vEB tree T operates as follows:
- If T is empty then we set T.min = T.max = x and we are done.
- Otherwise, if x<T.min then we insert T.min into the subtree i responsible for T.min and then set T.min = x. If T.children[i] was previously empty, then we also insert i into T.aux
- Otherwise, if x>T.max then we insert x into the subtree i responsible for x and then set T.max = x. If T.children[i] was previously empty, then we also insert i into T.aux
- Otherwise, T.min< x < T.max so we insert x into the subtree i responsible for x. If T.children[i] was previously empty, then we also insert i into T.aux.
In code:
function Insert(T, x)
if T.min > T.max then // T is empty
T.min = T.max = x;
return
if x < T.min then
swap(x, T.min)
if x > T.max then
T.max = x
i = floor(x / √M)
lo = x mod √M
Insert(T.children[i], lo)
if T.children[i].min == T.children[i].max then
Insert(T.aux, i)
end
The key to the efficiency of this procedure is that inserting an element into an empty vEB tree takes O(1) time. So, even though the algorithm sometimes makes two recursive calls, this only occurs when the first recursive call was into an empty subtree. This gives the same running time recurrence of as before.
Delete
Deletion from vEB trees is the trickiest of the operations. The call Delete(T, x) that deletes a value x from a vEB tree T operates as follows:
- If T.min = T.max = x then x is the only element stored in the tree and we set T.min = M and T.max = −1 to indicate that the tree is empty.
- Otherwise, if x == T.min then we need to find the second-smallest value y in the vEB tree, delete it from its current location, and set T.min=y. The second-smallest value y is T.children[T.aux.min].min, so it can be found in O(1) time. We delete y from the subtree that contains it.
- If x≠T.min and x≠T.max then we delete x from the subtree T.children[i] that contains x.
- If x == T.max then we will need to find the second-largest value y in the vEB tree and set T.max=y. We start by deleting x as in previous case. Then value y is either T.min or T.children[T.aux.max].max, so it can be found in O(1) time.
- In any of the above cases, if we delete the last element x or y from any subtree T.children[i] then we also delete i from T.aux.
In code:
function Delete(T, x)
if T.min == T.max == x then
T.min = M
T.max = −1
return
if x == T.min then
hi = T.aux.min * √M
j = T.aux.min
T.min = x = hi + T.children[j].min
i = floor(x / √M)
lo = x mod √M
Delete(T.children[i], lo)
if T.children[i] is empty then
Delete(T.aux, i)
if x == T.max then
if T.aux is empty then
T.max = T.min
else
hi = T.aux.max * √M
j = T.aux.max
T.max = hi + T.children[j].max
end
Again, the efficiency of this procedure hinges on the fact that deleting from a vEB tree that contains only one element takes only constant time. In particular, the second Delete call only executes if x was the only element in T.children[i] prior to the deletion.
Discussion
The assumption that log m is an integer is unnecessary. The operations and can be replaced by taking only higher-order ⌈m/2⌉ and the lower-order ⌊m/2⌋ bits of x, respectively. On any existing machine, this is more efficient than division or remainder computations.


In practical implementations, especially on machines with shift-by-k and find first zero instructions, performance can further be improved by switching to a bit array once m equal to the word size (or a small multiple thereof) is reached. Since all operations on a single word are constant time, this does not affect the asymptotic performance, but it does avoid the majority of the pointer storage and several pointer dereferences, achieving a significant practical savings in time and space with this trick.
An obvious optimization of vEB trees is to discard empty subtrees. This makes vEB trees quite compact when they contain many elements, because no subtrees are created until something needs to be added to them. Initially, each element added creates about log(m) new trees containing about m/2 pointers all together. As the tree grows, more and more subtrees are reused, especially the larger ones. In a full tree of M elements, only O(M) space is used. Moreover, unlike a binary search tree, most of this space is being used to store data: even for billions of elements, the pointers in a full vEB tree number in the thousands.
The implementation described above uses pointers and occupies a total space of O(M) = O(2m), proportional to the size of the key universe. This can be seen as follows. The recurrence is . Resolving that would lead to . One can, fortunately, also show that S(M) = M−2 by induction.[4]


Similar structures
The O(M) space usage of vEB trees is an enormous overhead unless a large fraction of the universe of keys is being stored. This is one reason why vEB trees are not popular in practice. This limitation can be addressed by changing the array used to store children to another data structure. One possibility is to use only a fixed number of bits per level, which results in a trie. Alternatively, each array may be replaced by a hash table, reducing the space to O(n log log M) (where n is the number of elements stored in the data structure) at the expense of making the data structure randomized.
x-fast tries and the more complicated y-fast tries have comparable update and query times to vEB trees and use randomized hash tables to reduce the space used. x-fast tries use O(n log M) space while y-fast tries use O(n) space.
Fusion trees are another type of tree data structure that implements an associative array on w-bit integers on a finite universe. They use word-level parallelism and bit manipulation techniques to achieve O(logw n) time for predecessor/successor queries and updates, where w is the word size.[5] Fusion trees use O(n) space and can be made dynamic with hashing or exponential trees.
Implementations
There is a verified implementation in Isabelle (proof assistant).[6] Both functional correctness and time bounds are proved. Efficient imperative Standard ML code can be generated.
See also
References
- Peter van Emde Boas: Preserving order in a forest in less than logarithmic time (Proceedings of the 16th Annual Symposium on Foundations of Computer Science 10: 75-84, 1975)
- Gudmund Skovbjerg Frandsen: Dynamic algorithms: Course notes on van Emde Boas trees (PDF) (University of Aarhus, Department of Computer Science)
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Third Edition. MIT Press, 2009. ISBN 978-0-262-53305-8. Chapter 20: The van Emde Boas tree, pp. 531–560.
- Rex, A. "Determining the space complexity of van Emde Boas trees". Retrieved 2011-05-27.
- "Fusion Tree". OpenGenus IQ: Computing Expertise & Legacy. 2019-04-04. Retrieved 2023-08-30.
- Ammer, Thomas; Lammich, Peter. "van Emde Boas Trees". Archive of Formal Proofs. Retrieved 26 November 2021.
Further reading
- Erik Demaine, Sam Fingeret, Shravas Rao, Paul Christiano. Massachusetts Institute of Technology. 6.851: Advanced Data Structures (Spring 2012). Lecture 11 notes. March 22, 2012.
- van Emde Boas, P.; Kaas, R.; Zijlstra, E. (1976). "Design and implementation of an efficient priority queue". Mathematical Systems Theory. 10: 99–127. doi:10.1007/BF01683268.