Control character
In computing and telecommunication, a control character or non-printing character (NPC) is a code point in a character set that does not represent a written character or symbol. They are used as in-band signaling to cause effects other than the addition of a symbol to the text. All other characters are mainly graphic characters, also known as printing characters (or printable characters), except perhaps for "space" characters. In the ASCII standard there are 33 control characters, such as code 7, BEL, which rings a terminal bell.
History
Procedural signs in Morse code are a form of control character.
A form of control characters were introduced in the 1870 Baudot code: NUL and DEL. The 1901 Murray code added the carriage return (CR) and line feed (LF), and other versions of the Baudot code included other control characters.
The bell character (BEL), which rang a bell to alert operators, was also an early teletype control character.
Some control characters have also been called "format effectors".
In ASCII
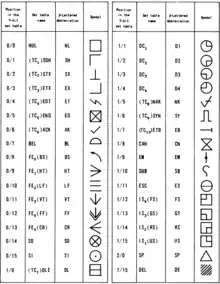
There were quite a few control characters defined (33 in ASCII, and the ECMA-48 standard adds 32 more). This was because early terminals had very primitive mechanical or electrical controls that made any kind of state-remembering API quite expensive to implement, thus a different code for each and every function looked like a requirement. It quickly became possible and inexpensive to interpret sequences of codes to perform a function, and device makers found a way to send hundreds of device instructions. Specifically, they used ASCII code 2710 (escape), followed by a series of characters called a "control sequence" or "escape sequence". The mechanism was invented by Bob Bemer, the father of ASCII. For example, the sequence of code 2710, followed by the printable characters "[2;10H", would cause a Digital Equipment Corporation VT100 terminal to move its cursor to the 10th cell of the 2nd line of the screen. Several standards exist for these sequences, notably ANSI X3.64. But the number of non-standard variations in use is large, especially among printers, where technology has advanced far faster than any standards body can possibly keep up with.
All entries in the ASCII table below code 3210 (technically the C0 control code set) are of this kind, including CR and LF used to separate lines of text. The code 12710 (DEL) is also a control character.[1][2] Extended ASCII sets defined by ISO 8859 added the codes 12810 through 15910 as control characters. This was primarily done so that if the high bit was stripped, it would not change a printing character to a C0 control code. This second set is called the C1 set.
These 65 control codes were carried over to Unicode. Unicode added more characters that could be considered controls, but it makes a distinction between these "Formatting characters" (such as the zero-width non-joiner) and the 65 control characters.
The Extended Binary Coded Decimal Interchange Code (EBCDIC) character set contains 65 control codes, including all of the ASCII control codes plus additional codes which are mostly used to control IBM peripherals.
| 0x00 | 0x10 | |
|---|---|---|
| 0x00 | NUL | DLE |
| 0x01 | SOH | DC1 |
| 0x02 | STX | DC2 |
| 0x03 | ETX | DC3 |
| 0x04 | EOT | DC4 |
| 0x05 | ENQ | NAK |
| 0x06 | ACK | SYN |
| 0x07 | BEL | ETB |
| 0x08 | BS | CAN |
| 0x09 | HT | EM |
| 0x0A | LF | SUB |
| 0x0B | VT | ESC |
| 0x0C | FF | FS |
| 0x0D | CR | GS |
| 0x0E | SO | RS |
| 0x0F | SI | US |
| 0x7F | DEL |
The control characters in ASCII still in common use include:
- 0x00 (null, NUL, \0, ^@), originally intended to be an ignored character, but now used by many programming languages including C to mark the end of a string.
- 0x07 (bell, BEL, \a, ^G), which may cause the device to emit a warning such as a bell or beep sound or the screen flashing.
- 0x08 (backspace, BS, \b, ^H), may overprint the previous character.
- 0x09 (horizontal tab, HT, \t, ^I), moves the printing position right to the next tab stop.
- 0x0A (line feed, LF, \n, ^J), moves the print head down one line, or to the left edge and down. Used as the end of line marker in most UNIX systems and variants.
- 0x0B (vertical tab, VT, \v, ^K), vertical tabulation.
- 0x0C (form feed, FF, \f, ^L), to cause a printer to eject paper to the top of the next page, or a video terminal to clear the screen.
- 0x0D (carriage return, CR, \r, ^M), moves the printing position to the start of the line, allowing overprinting. Used as the end of line marker in Classic Mac OS, OS-9, FLEX (and variants). A CR+LF pair is used by CP/M-80 and its derivatives including DOS and Windows, and by Application Layer protocols such as FTP, SMTP, and HTTP.
- 0x1A (Control-Z, SUB, ^Z). Acts as an end-of-file for the Windows text-mode file i/o.
- 0x1B (escape, ESC, \e (GCC only), ^[). Introduces an escape sequence.
Control characters may be described as doing something when the user inputs them, such as code 3 (End-of-Text character, ETX, ^C) to interrupt the running process, or code 4 (End-of-Transmission character, EOT, ^D), used to end text input on Unix or to exit a Unix shell. These uses usually have little to do with their use when they are in text being output.
In Unicode
In Unicode, "Control-characters" are U+0000—U+001F (C0 controls), U+007F (delete), and U+0080—U+009F (C1 controls). Their General Category is "Cc". Formatting codes are distinct, in General Category "Cf". The Cc control characters have no Name in Unicode, but are given labels such as "<control-001A>" instead.[4]
Display
There are a number of techniques to display non-printing characters, which may be illustrated with the bell character in ASCII encoding:
- Code point: decimal 7, hexadecimal 0x07
- An abbreviation, often three capital letters: BEL
- A special character condensing the abbreviation: Unicode U+2407 (␇), "symbol for bell"
- An ISO 2047 graphical representation: Unicode U+237E (⍾), "graphic for bell"
- Caret notation in ASCII, where code point 00xxxxx is represented as a caret followed by the capital letter at code point 10xxxxx: ^G
- An escape sequence, as in C/C++ character string codes: \a, \007, \x07, etc.
How control characters map to keyboards
ASCII-based keyboards have a key labelled "Control", "Ctrl", or (rarely) "Cntl" which is used much like a shift key, being pressed in combination with another letter or symbol key. In one implementation, the control key generates the code 64 places below the code for the (generally) uppercase letter it is pressed in combination with (i.e., subtract 0x40 from ASCII code value of the (generally) uppercase letter). The other implementation is to take the ASCII code produced by the key and bitwise AND it with 0x1F, forcing bits 5 to 7 to zero. For example, pressing "control" and the letter "g" (which is 0110 0111 in binary), produces the code 7 (BELL, 7 in base ten, or 0000 0111 in binary). The NULL character (code 0) is represented by Ctrl-@, "@" being the code immediately before "A" in the ASCII character set. For convenience, some terminals accept Ctrl-Space as an alias for Ctrl-@. In either case, this produces one of the 32 ASCII control codes between 0 and 31. Neither approach works to produce the DEL character because of its special location in the table and its value (code 12710), Ctrl-? is sometimes used for this character.[5]
When the control key is held down, letter keys produce the same control characters regardless of the state of the shift or caps lock keys. In other words, it does not matter whether the key would have produced an upper-case or a lower-case letter. The interpretation of the control key with the space, graphics character, and digit keys (ASCII codes 32 to 63) vary between systems. Some will produce the same character code as if the control key were not held down. Other systems translate these keys into control characters when the control key is held down. The interpretation of the control key with non-ASCII ("foreign") keys also varies between systems.
Control characters are often rendered into a printable form known as caret notation by printing a caret (^) and then the ASCII character that has a value of the control character plus 64. Control characters generated using letter keys are thus displayed with the upper-case form of the letter. For example, ^G represents code 7, which is generated by pressing the G key when the control key is held down.
Keyboards also typically have a few single keys which produce control character codes. For example, the key labelled "Backspace" typically produces code 8, "Tab" code 9, "Enter" or "Return" code 13 (though some keyboards might produce code 10 for "Enter").
Many keyboards include keys that do not correspond to any ASCII printable or control character, for example cursor control arrows and word processing functions. The associated keypresses are communicated to computer programs by one of four methods: appropriating otherwise unused control characters; using some encoding other than ASCII; using multi-character control sequences; or using an additional mechanism outside of generating characters. "Dumb" computer terminals typically use control sequences. Keyboards attached to stand-alone personal computers made in the 1980s typically use one (or both) of the first two methods. Modern computer keyboards generate scancodes that identify the specific physical keys that are pressed; computer software then determines how to handle the keys that are pressed, including any of the four methods described above.
The design purpose
The control characters were designed to fall into a few groups: printing and display control, data structuring, transmission control, and miscellaneous.
Printing and display control
Printing control characters were first used to control the physical mechanism of printers, the earliest output device. An early example of this idea was the use of Figures (FIGS) and Letters (LTRS) in Baudot code to shift between two code pages. A later, but still early, example was the out-of-band ASA carriage control characters. Later, control characters were integrated into the stream of data to be printed. The carriage return character (CR), when sent to such a device, causes it to put the character at the edge of the paper at which writing begins (it may, or may not, also move the printing position to the next line). The line feed character (LF/NL) causes the device to put the printing position on the next line. It may (or may not), depending on the device and its configuration, also move the printing position to the start of the next line (which would be the leftmost position for left-to-right scripts, such as the alphabets used for Western languages, and the rightmost position for right-to-left scripts such as the Hebrew and Arabic alphabets). The vertical and horizontal tab characters (VT and HT/TAB) cause the output device to move the printing position to the next tab stop in the direction of reading. The form feed character (FF/NP) starts a new sheet of paper, and may or may not move to the start of the first line. The backspace character (BS) moves the printing position one character space backwards. On printers, including hard-copy terminals, this is most often used so the printer can overprint characters to make other, not normally available, characters. On video terminals and other electronic output devices, there are often software (or hardware) configuration choices that allow a destructive backspace (e.g., a BS, SP, BS sequence), which erases, or a non-destructive one, which does not. The shift in and shift out characters (SI and SO) selected alternate character sets, fonts, underlining, or other printing modes. Escape sequences were often used to do the same thing.
With the advent of computer terminals that did not physically print on paper and so offered more flexibility regarding screen placement, erasure, and so forth, printing control codes were adapted. Form feeds, for example, usually cleared the screen, there being no new paper page to move to. More complex escape sequences were developed to take advantage of the flexibility of the new terminals, and indeed of newer printers. The concept of a control character had always been somewhat limiting, and was extremely so when used with new, much more flexible, hardware. Control sequences (sometimes implemented as escape sequences) could match the new flexibility and power and became the standard method. However, there were, and remain, a large variety of standard sequences to choose from.
Data structuring
The separators (File, Group, Record, and Unit: FS, GS, RS and US) were made to structure data, usually on a tape, in order to simulate punched cards. End of medium (EM) warns that the tape (or other recording medium) is ending. While many systems use CR/LF and TAB for structuring data, it is possible to encounter the separator control characters in data that needs to be structured. The separator control characters are not overloaded; there is no general use of them except to separate data into structured groupings. Their numeric values are contiguous with the space character, which can be considered a member of the group, as a word separator.
For example, the RS separator is used by RFC 7464 (JSON Text Sequences) to encode a sequence of JSON elements. Each sequence item starts with a RS character and ends with a line feed. This allows to serialize open-ended JSON sequences. It is one of the JSON streaming protocols.
Transmission control
The transmission control characters were intended to structure a data stream, and to manage re-transmission or graceful failure, as needed, in the face of transmission errors.
The start of heading (SOH) character was to mark a non-data section of a data stream—the part of a stream containing addresses and other housekeeping data. The start of text character (STX) marked the end of the header, and the start of the textual part of a stream. The end of text character (ETX) marked the end of the data of a message. A widely used convention is to make the two characters preceding ETX a checksum or CRC for error-detection purposes. The end of transmission block character (ETB) was used to indicate the end of a block of data, where data was divided into such blocks for transmission purposes.
The escape character (ESC) was intended to "quote" the next character, if it was another control character it would print it instead of performing the control function. It is almost never used for this purpose today. Various printable characters are used as visible "escape characters", depending on context.
The substitute character (SUB) was intended to request a translation of the next character from a printable character to another value, usually by setting bit 5 to zero. This is handy because some media (such as sheets of paper produced by typewriters) can transmit only printable characters. However, on MS-DOS systems with files opened in text mode, "end of text" or "end of file" is marked by this Ctrl-Z character, instead of the Ctrl-C or Ctrl-D, which are common on other operating systems.
The cancel character (CAN) signaled that the previous element should be discarded. The negative acknowledge character (NAK) is a definite flag for, usually, noting that reception was a problem, and, often, that the current element should be sent again. The acknowledge character (ACK) is normally used as a flag to indicate no problem detected with current element.
When a transmission medium is half duplex (that is, it can transmit in only one direction at a time), there is usually a master station that can transmit at any time, and one or more slave stations that transmit when they have permission. The enquire character (ENQ) is generally used by a master station to ask a slave station to send its next message. A slave station indicates that it has completed its transmission by sending the end of transmission character (EOT).
The device control codes (DC1 to DC4) were originally generic, to be implemented as necessary by each device. However, a universal need in data transmission is to request the sender to stop transmitting when a receiver is temporarily unable to accept any more data. Digital Equipment Corporation invented a convention which used 19 (the device control 3 character (DC3), also known as control-S, or XOFF) to "S"top transmission, and 17 (the device control 1 character (DC1), a.k.a. control-Q, or XON) to start transmission. It has become so widely used that most don't realize it is not part of official ASCII. This technique, however implemented, avoids additional wires in the data cable devoted only to transmission management, which saves money. A sensible protocol for the use of such transmission flow control signals must be used, to avoid potential deadlock conditions, however.
The data link escape character (DLE) was intended to be a signal to the other end of a data link that the following character is a control character such as STX or ETX. For example a packet may be structured in the following way (DLE) <STX> <PAYLOAD> (DLE) <ETX>.
Miscellaneous codes
Code 7 (BEL) is intended to cause an audible signal in the receiving terminal.[6]
Many of the ASCII control characters were designed for devices of the time that are not often seen today. For example, code 22, "synchronous idle" (SYN), was originally sent by synchronous modems (which have to send data constantly) when there was no actual data to send. (Modern systems typically use a start bit to announce the beginning of a transmitted word— this is a feature of asynchronous communication. Synchronous communication links were more often seen with mainframes, where they were typically run over corporate leased lines to connect a mainframe to another mainframe or perhaps a minicomputer.)
Code 0 (ASCII code name NUL) is a special case. In paper tape, it is the case when there are no holes. It is convenient to treat this as a fill character with no meaning otherwise. Since the position of a NUL character has no holes punched, it can be replaced with any other character at a later time, so it was typically used to reserve space, either for correcting errors or for inserting information that would be available at a later time or in another place. In computing it is often used for padding in fixed length records and more commonly, to mark the end of a string.
Code 127 (DEL, a.k.a. "rubout") is likewise a special case. Its 7-bit code is all-bits-on in binary, which essentially erased a character cell on a paper tape when overpunched. Paper tape was a common storage medium when ASCII was developed, with a computing history dating back to WWII code breaking equipment at Biuro Szyfrów. Paper tape became obsolete in the 1970s, so this clever aspect of ASCII rarely saw any use after that. Some systems (such as the original Apples) converted it to a backspace. But because its code is in the range occupied by other printable characters, and because it had no official assigned glyph, many computer equipment vendors used it as an additional printable character (often an all-black "box" character useful for erasing text by overprinting with ink).
Non-erasable programmable ROMs are typically implemented as arrays of fusible elements, each representing a bit, which can only be switched one way, usually from one to zero. In such PROMs, the DEL and NUL characters can be used in the same way that they were used on punched tape: one to reserve meaningless fill bytes that can be written later, and the other to convert written bytes to meaningless fill bytes. For PROMs that switch one to zero, the roles of NUL and DEL are reversed; also, DEL will only work with 7-bit characters, which are rarely used today; for 8-bit content, the character code 255, commonly defined as a nonbreaking space character, can be used instead of DEL.
Many file systems do not allow control characters in filenames, as they may have reserved functions.
See also
- Arrow keys § HJKL keys, HJKL as arrow keys, used on ADM-3A terminal
- C0 and C1 control codes
- Escape sequence
- In-band signaling
- Whitespace character
Notes and references
- ASCII format for network interchange. 1969-10-01. doi:10.17487/RFC0020. RFC 20. Retrieved 2023-04-05.
- "5.2 Control Characters". American National Standard Code for Information Interchange | ANSI X3.4-1977 (PDF). National Institute for Standards. 1977. Archived (PDF) from the original on 2022-10-09.
- MS-DOS QBasic v1.1 Documentation. Microsoft 1987-1991.
- "4.8 Name". The Unicode Standard Version 13.0 – Core Specification (PDF). Unicode, Inc. Archived (PDF) from the original on 2022-10-09.
- "ASCII Characters". Archived from the original on October 28, 2009. Retrieved 2010-10-08.
- ASCII format for Network Interchange. October 1969. doi:10.17487/RFC0020. RFC 20. Retrieved 2013-11-03. An old RFC, which explains the structure and meaning of the control characters in chapters 4.1 and 5.2
External links
- ISO IR 1 C0 Set of ISO 646 (PDF)
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |