Quantities of information
The mathematical theory of information is based on probability theory and statistics, and measures information with several quantities of information. The choice of logarithmic base in the following formulae determines the unit of information entropy that is used. The most common unit of information is the bit, or more correctly the shannon, based on the binary logarithm. Although "bit" is more frequently used in place of "shannon", its name is not distinguished from the bit as used in data-processing to refer to a binary value or stream regardless of its entropy (information content) Other units include the nat, based on the natural logarithm, and the hartley, based on the base 10 or common logarithm.








In what follows, an expression of the form is considered by convention to be equal to zero whenever is zero. This is justified because for any logarithmic base.



Self-information
Shannon derived a measure of information content called the self-information or "surprisal" of a message :


where is the probability that message is chosen from all possible choices in the message space . The base of the logarithm only affects a scaling factor and, consequently, the units in which the measured information content is expressed. If the logarithm is base 2, the measure of information is expressed in units of shannons or more often simply "bits" (a bit in other contexts is rather defined as a "binary digit", whose average information content is at most 1 shannon).


Information from a source is gained by a recipient only if the recipient did not already have that information to begin with. Messages that convey information over a certain (P=1) event (or one which is known with certainty, for instance, through a back-channel) provide no information, as the above equation indicates. Infrequently occurring messages contain more information than more frequently occurring messages.
It can also be shown that a compound message of two (or more) unrelated messages would have a quantity of information that is the sum of the measures of information of each message individually. That can be derived using this definition by considering a compound message providing information regarding the values of two random variables M and N using a message which is the concatenation of the elementary messages m and n, each of whose information content are given by and respectively. If the messages m and n each depend only on M and N, and the processes M and N are independent, then since (the definition of statistical independence) it is clear from the above definition that .





An example: The weather forecast broadcast is: "Tonight's forecast: Dark. Continued darkness until widely scattered light in the morning." This message contains almost no information. However, a forecast of a snowstorm would certainly contain information since such does not happen every evening. There would be an even greater amount of information in an accurate forecast of snow for a warm location, such as Miami. The amount of information in a forecast of snow for a location where it never snows (impossible event) is the highest (infinity).
Entropy
The entropy of a discrete message space is a measure of the amount of uncertainty one has about which message will be chosen. It is defined as the average self-information of a message from that message space:
![{\displaystyle \mathrm {H} (M)=\mathbb {E} \left[\operatorname {I} (M)\right]=\sum _{m\in M}p(m)\operatorname {I} (m)=-\sum _{m\in M}p(m)\log p(m).}](../I/480e910ca466230575a15288a1b27dcc65328820.svg)
where
- denotes the expected value operation.
![{\displaystyle \mathbb {E} [-]}](../I/529848bb3e817d4f2e052400e086eb58a08a9dfa.svg)
An important property of entropy is that it is maximized when all the messages in the message space are equiprobable (e.g. ). In this case .


Sometimes the function is expressed in terms of the probabilities of the distribution:

- where each and



An important special case of this is the binary entropy function:

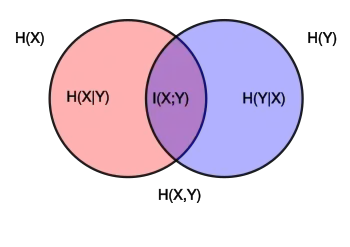
Joint entropy
The joint entropy of two discrete random variables and is defined as the entropy of the joint distribution of and :
![{\displaystyle \mathrm {H} (X,Y)=\mathbb {E} _{X,Y}\left[-\log p(x,y)\right]=-\sum _{x,y}p(x,y)\log p(x,y)\,}](../I/766168a01d7bc92684bd1e010171907054542373.svg)
If and are independent, then the joint entropy is simply the sum of their individual entropies.
(Note: The joint entropy should not be confused with the cross entropy, despite similar notations.)
Conditional entropy (equivocation)
Given a particular value of a random variable , the conditional entropy of given is defined as:

![{\displaystyle \mathrm {H} (X|y)=\mathbb {E} _{\left[X|Y\right]}[-\log p(x|y)]=-\sum _{x\in X}p(x|y)\log p(x|y)}](../I/c2898107d213fa8759148865e354ebc4b9b3beee.svg)
where is the conditional probability of given .



The conditional entropy of given , also called the equivocation of about is then given by:
![{\displaystyle \mathrm {H} (X|Y)=\mathbb {E} _{Y}\left[\mathrm {H} \left(X|y\right)\right]=-\sum _{y\in Y}p(y)\sum _{x\in X}p(x|y)\log p(x|y)=\sum _{x,y}p(x,y)\log {\frac {p(y)}{p(x,y)}}.}](../I/691d036d7aef46395cb1ced6a9cec4f17fe3713a.svg)
This uses the conditional expectation from probability theory.
A basic property of the conditional entropy is that:

Kullback–Leibler divergence (information gain)
The Kullback–Leibler divergence (or information divergence, information gain, or relative entropy) is a way of comparing two distributions, a "true" probability distribution , and an arbitrary probability distribution . If we compress data in a manner that assumes is the distribution underlying some data, when, in reality, is the correct distribution, Kullback–Leibler divergence is the number of average additional bits per datum necessary for compression, or, mathematically,


It is in some sense the "distance" from to , although it is not a true metric due to its not being symmetric.
Mutual information (transinformation)
It turns out that one of the most useful and important measures of information is the mutual information, or transinformation. This is a measure of how much information can be obtained about one random variable by observing another. The mutual information of relative to (which represents conceptually the average amount of information about that can be gained by observing ) is given by:

A basic property of the mutual information is that:

That is, knowing , we can save an average of bits in encoding compared to not knowing . Mutual information is symmetric:

Mutual information can be expressed as the average Kullback–Leibler divergence (information gain) of the posterior probability distribution of given the value of to the prior distribution on :
![{\displaystyle \operatorname {I} (X;Y)=\mathbb {E} _{p(y)}\left[D_{\mathrm {KL} }{\bigl (}p(X|Y=y)\|p(X){\bigr )}\right].}](../I/4dfda3399c19ec513883faf25ee4def8b9707e43.svg)
In other words, this is a measure of how much, on the average, the probability distribution on will change if we are given the value of . This is often recalculated as the divergence from the product of the marginal distributions to the actual joint distribution:

Mutual information is closely related to the log-likelihood ratio test in the context of contingency tables and the multinomial distribution and to Pearson's χ2 test: mutual information can be considered a statistic for assessing independence between a pair of variables, and has a well-specified asymptotic distribution.
Differential entropy
The basic measures of discrete entropy have been extended by analogy to continuous spaces by replacing sums with integrals and probability mass functions with probability density functions. Although, in both cases, mutual information expresses the number of bits of information common to the two sources in question, the analogy does not imply identical properties; for example, differential entropy may be negative.
The differential analogies of entropy, joint entropy, conditional entropy, and mutual information are defined as follows:





where is the joint density function, and are the marginal distributions, and is the conditional distribution.




See also
References
- D.J.C. Mackay. Information theory, inferences, and learning algorithms.: 141