Reachability
In graph theory, reachability refers to the ability to get from one vertex to another within a graph. A vertex can reach a vertex (and is reachable from ) if there exists a sequence of adjacent vertices (i.e. a walk) which starts with and ends with .


In an undirected graph, reachability between all pairs of vertices can be determined by identifying the connected components of the graph. Any pair of vertices in such a graph can reach each other if and only if they belong to the same connected component; therefore, in such a graph, reachability is symmetric ( reaches iff reaches ). The connected components of an undirected graph can be identified in linear time. The remainder of this article focuses on the more difficult problem of determining pairwise reachability in a directed graph (which, incidentally, need not be symmetric).
Definition
For a directed graph , with vertex set and edge set , the reachability relation of is the transitive closure of , which is to say the set of all ordered pairs of vertices in for which there exists a sequence of vertices such that the edge is in for all .[1]








If is acyclic, then its reachability relation is a partial order; any partial order may be defined in this way, for instance as the reachability relation of its transitive reduction.[2] A noteworthy consequence of this is that since partial orders are anti-symmetric, if can reach , then we know that cannot reach . Intuitively, if we could travel from to and back to , then would contain a cycle, contradicting that it is acyclic. If is directed but not acyclic (i.e. it contains at least one cycle), then its reachability relation will correspond to a preorder instead of a partial order.[3]
Algorithms
Algorithms for determining reachability fall into two classes: those that require preprocessing and those that do not.
If you have only one (or a few) queries to make, it may be more efficient to forgo the use of more complex data structures and compute the reachability of the desired pair directly. This can be accomplished in linear time using algorithms such as breadth first search or iterative deepening depth-first search.[4]
If you will be making many queries, then a more sophisticated method may be used; the exact choice of method depends on the nature of the graph being analysed. In exchange for preprocessing time and some extra storage space, we can create a data structure which can then answer reachability queries on any pair of vertices in as low as time. Three different algorithms and data structures for three different, increasingly specialized situations are outlined below.

Floyd–Warshall Algorithm
The Floyd–Warshall algorithm[5] can be used to compute the transitive closure of any directed graph, which gives rise to the reachability relation as in the definition, above.
The algorithm requires time and space in the worst case. This algorithm is not solely interested in reachability as it also computes the shortest path distance between all pairs of vertices. For graphs containing negative cycles, shortest paths may be undefined, but reachability between pairs can still be noted.


Thorup's Algorithm
For planar digraphs, a much faster method is available, as described by Mikkel Thorup in 2004.[6] This method can answer reachability queries on a planar graph in time after spending preprocessing time to create a data structure of size. This algorithm can also supply approximate shortest path distances, as well as route information.

The overall approach is to associate with each vertex a relatively small set of so-called separator paths such that any path from a vertex to any other vertex must go through at least one of the separators associated with or . An outline of the reachability related sections follows.


Given a graph , the algorithm begins by organizing the vertices into layers starting from an arbitrary vertex . The layers are built in alternating steps by first considering all vertices reachable from the previous step (starting with just ) and then all vertices which reach to the previous step until all vertices have been assigned to a layer. By construction of the layers, every vertex appears at most two layers, and every directed path, or dipath, in is contained within two adjacent layers and . Let be the last layer created, that is, the lowest value for such that .





The graph is then re-expressed as a series of digraphs where each and where is the contraction of all previous levels into a single vertex. Because every dipath appears in at most two consecutive layers, and because each is formed by two consecutive layers, every dipath in appears in its entirety in at least one (and no more than 2 consecutive such graphs)





For each , three separators are identified which, when removed, break the graph into three components which each contain at most the vertices of the original. As is built from two layers of opposed dipaths, each separator may consist of up to 2 dipaths, for a total of up to 6 dipaths over all of the separators. Let be this set of dipaths. The proof that such separators can always be found is related to the Planar Separator Theorem of Lipton and Tarjan, and these separators can be located in linear time.


For each , the directed nature of provides for a natural indexing of its vertices from the start to the end of the path. For each vertex in , we locate the first vertex in reachable by , and the last vertex in that reaches to . That is, we are looking at how early into we can get from , and how far we can stay in and still get back to . This information is stored with each . Then for any pair of vertices and , can reach via if connects to earlier than connects from .



Every vertex is labelled as above for each step of the recursion which builds . As this recursion has logarithmic depth, a total of extra information is stored per vertex. From this point, a logarithmic time query for reachability is as simple as looking over each pair of labels for a common, suitable . The original paper then works to tune the query time down to .


In summarizing the analysis of this method, first consider that the layering approach partitions the vertices so that each vertex is considered only times. The separator phase of the algorithm breaks the graph into components which are at most the size of the original graph, resulting in a logarithmic recursion depth. At each level of the recursion, only linear work is needed to identify the separators as well as the connections possible between vertices. The overall result is preprocessing time with only additional information stored for each vertex.

Kameda's Algorithm
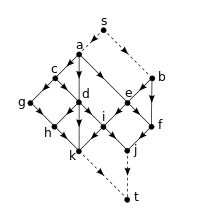
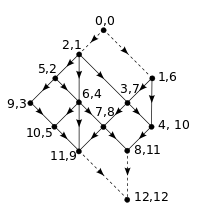
An even faster method for pre-processing, due to T. Kameda in 1975,[7] can be used if the graph is planar, acyclic, and also exhibits the following additional properties: all 0-indegree and all 0-outdegree vertices appear on the same face (often assumed to be the outer face), and it is possible to partition the boundary of that face into two parts such that all 0-indegree vertices appear on one part, and all 0-outdegree vertices appear on the other (i.e. the two types of vertices do not alternate).
If exhibits these properties, then we can preprocess the graph in only time, and store only extra bits per vertex, answering reachability queries for any pair of vertices in time with a simple comparison.

Preprocessing performs the following steps. We add a new vertex which has an edge to each 0-indegree vertex, and another new vertex with edges from each 0-outdegree vertex. Note that the properties of allow us to do so while maintaining planarity, that is, there will still be no edge crossings after these additions. For each vertex we store the list of adjacencies (out-edges) in order of the planarity of the graph (for example, clockwise with respect to the graph's embedding). We then initialize a counter and begin a Depth-First Traversal from . During this traversal, the adjacency list of each vertex is visited from left-to-right as needed. As vertices are popped from the traversal's stack, they are labelled with the value , and is then decremented. Note that is always labelled with the value and is always labelled with . The depth-first traversal is then repeated, but this time the adjacency list of each vertex is visited from right-to-left.




When completed, and , and their incident edges, are removed. Each remaining vertex stores a 2-dimensional label with values from to . Given two vertices and , and their labels and , we say that if and only if , , and there exists at least one component or which is strictly less than or , respectively.











The main result of this method then states that is reachable from if and only if , which is easily calculated in time.
Related problems
A related problem is to solve reachability queries with some number of vertex failures. For example: "Can vertex still reach vertex even though vertices have failed and can no longer be used?" A similar problem may consider edge failures rather than vertex failures, or a mix of the two. The breadth-first search technique works just as well on such queries, but constructing an efficient oracle is more challenging.[8][9]

Another problem related to reachability queries is in quickly recalculating changes to reachability relationships when some portion of the graph is changed. For example, this is a relevant concern to garbage collection which needs to balance the reclamation of memory (so that it may be reallocated) with the performance concerns of the running application.
See also
References
- Skiena, Steven S. (2011), "15.5 Transitive Closure and Reduction", The Algorithm Design Manual (2nd ed.), Springer, pp. 495–497, ISBN 9781848000698.
- Cohn, Paul Moritz (2003), Basic Algebra: Groups, Rings, and Fields, Springer, p. 17, ISBN 9781852335878.
- Schmidt, Gunther (2010), Relational Mathematics, Encyclopedia of Mathematics and Its Applications, vol. 132, Cambridge University Press, p. 77, ISBN 9780521762687.
- Gersting, Judith L. (2006), Mathematical Structures for Computer Science (6th ed.), Macmillan, p. 519, ISBN 9780716768647.
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001), "Transitive closure of a directed graph", Introduction to Algorithms (2nd ed.), MIT Press and McGraw-Hill, pp. 632–634, ISBN 0-262-03293-7.
- Thorup, Mikkel (2004), "Compact oracles for reachability and approximate distances in planar digraphs", Journal of the ACM, 51 (6): 993–1024, doi:10.1145/1039488.1039493, MR 2145261, S2CID 18864647.
- Kameda, T (1975), "On the vector representation of the reachability in planar directed graphs", Information Processing Letters, 3 (3): 75–77, doi:10.1016/0020-0190(75)90019-8.
- Demetrescu, Camil; Thorup, Mikkel; Chowdhury, Rezaul Alam; Ramachandran, Vijaya (2008), "Oracles for distances avoiding a failed node or link", SIAM Journal on Computing, 37 (5): 1299–1318, CiteSeerX 10.1.1.329.5435, doi:10.1137/S0097539705429847, MR 2386269.
- Halftermeyer, Pierre, Connectivity in Networks and Compact Labeling Schemes for Emergency Planning, Universite de Bordeaux.