Reference genome
A reference genome (also known as a reference assembly) is a digital nucleic acid sequence database, assembled by scientists as a representative example of the set of genes in one idealized individual organism of a species. As they are assembled from the sequencing of DNA from a number of individual donors, reference genomes do not accurately represent the set of genes of any single individual organism. Instead a reference provides a haploid mosaic of different DNA sequences from each donor. For example, one the most recent human reference genomes, assembly GRCh38/hg38, is derived from >60 genomic clone libraries.[1] There are reference genomes for multiple species of viruses, bacteria, fungus, plants, and animals. Reference genomes are typically used as a guide on which new genomes are built, enabling them to be assembled much more quickly and cheaply than the initial Human Genome Project. Reference genomes can be accessed online at several locations, using dedicated browsers such as Ensembl or UCSC Genome Browser.[2]

Properties of reference genomes
Measures of length
The length of a genome can be measured in multiple different ways.
A simple way to measure genome length is to count the number of base pairs in the assembly.[3]
The golden path is an alternative measure of length that omits redundant regions such as haplotypes and pseudoautosomal regions.[4][5] It is usually constructed by layering sequencing information over a physical map to combine scaffold information. It is a 'best estimate' of what the genome will look like and typically includes gaps, making it longer than the typical base pair assembly.[6]
Contigs and scaffolds
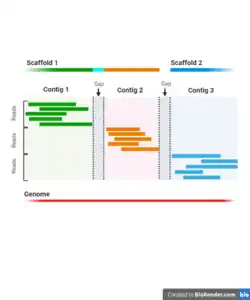
Reference genomes assembly requires reads overlapping, creating contigs, which are contiguous DNA regions of consensus sequences.[7] If there are gaps between contigs, these can be filled by scaffolding, either by contigs amplification with PCR and sequencing or by Bacterial Artificial Chromosome (BAC) cloning.[8][7] Filling these gaps is not always possible, in this case multiple scaffolds are created in a reference assembly.[9] Scaffolds are classified in 3 types: 1) Placed, whose chromosome, genomic coordinates and orientations are known; 2) Unlocalised, when only the chromosome is known but not the coordinates or orientation; 3) Unplaced, whose chromosome is not known.[10]
The number of contigs and scaffolds, as well as their average lengths are relevant parameters, among many others, for a reference genome assembly quality assessment since they provide information about the continuity of the final mapping from the original genome. The smaller the number of scaffolds per chromosome, until a single scaffold occupies an entire chromosome, the greater the continuity of the genome assembly.[11][12][13] Other related parameters are N50 and L50. N50 is the length of the contigs/scaffolds in which the 50% of the assembly is found in fragments of this length or greater, while L50 is the number of contigs/scaffolds whose length is N50. The higher the value of N50, the lower the value of L50, and vice versa, indicating high continuity in the assembly.[14][15][16]
Mammalian genomes
The human and mouse reference genomes are maintained and improved by the Genome Reference Consortium (GRC), a group of fewer than 20 scientists from a number of genome research institutes, including the European Bioinformatics Institute, the National Center for Biotechnology Information, the Sanger Institute and McDonnell Genome Institute at Washington University in St. Louis. GRC continues to improve reference genomes by building new alignments that contain fewer gaps, and fixing misrepresentations in the sequence.
Human reference genome
The original human reference genome was derived from thirteen anonymous volunteers from Buffalo, New York. Donors were recruited by advertisement in The Buffalo News, on Sunday, March 23, 1997. The first ten male and ten female volunteers were invited to make an appointment with the project's genetic counselors and donate blood from which DNA was extracted. As a result of how the DNA samples were processed, about 80 percent of the reference genome came from eight people and one male, designated RP11, accounts for 66 percent of the total. The ABO blood group system differs among humans, but the human reference genome contains only an O allele, although the others are annotated.[17][18][19][20][21]
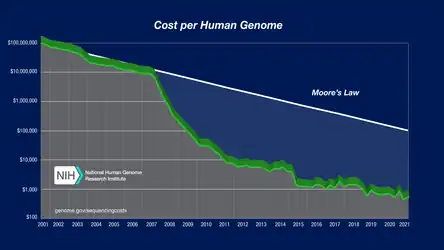
As the cost of DNA sequencing falls, and new full genome sequencing technologies emerge, more genome sequences continue to be generated. In several cases people such as James D. Watson had their genome assembled using massive parallel DNA sequencing.[22][23] Comparison between the reference (assembly NCBI36/hg18) and Watson's genome revealed 3.3 million single nucleotide polymorphism differences, while about 1.4 percent of his DNA could not be matched to the reference genome at all.[21][22] For regions where there is known to be large-scale variation, sets of alternate loci are assembled alongside the reference locus.
The latest human reference genome assembly, released by the Genome Reference Consortium, was GRCh38 in 2017.[25] Several patches were added to update it, the latest patch being GRCh38.p14, published in March 2022.[26][27] This build only has 349 gaps across the entire assembly, which implies a great improvement in comparison with the first version, which had roughly 150,000 gaps.[18] The gaps are mostly in areas such as telomeres, centromeres, and long repetitive sequences, with the biggest gap along the long arm of the Y chromosome, a region of ~30 Mb in length (~52% of the Y chromosome's length).[28] The number of genomic clone libraries contributing to the reference has increased steadily to >60 over the years, although individual RP11 still accounts for 70% of the reference genome.[1] Genomic analysis of this anonymous male suggests that he is of African-European ancestry.[1]
In 2022, the Telomere-to-Telomere (T2T) Consortium[29] published the first completely assembled reference genome (version T2T-CHM13), without any gaps in the assembly.[30][31] The Telomere-to-Telomere (T2T) consortium not only is an open, community-based effort to generate the first complete assembly of a human genome, but also provides an opportunity to examine how centromeric and pericentromeric (near the centromere) sequences evolve. This effort relied on careful measures in order to assemble, polish, and validate entire centromeric and pericentromeric repeat arrays. By deeply characterizing these recently assembled sequences, the consortium presented a high-resolution, genome-wide atlas of the sequence content and organization of human centromeric and pericentromeric regions.[32] On the other hand, according to the GRC website, their next assembly release for the human genome (version GRCh39) is currently "indefinitely postponed".[33]
Recent genome assemblies are as follows:[34]
| Release name | Date of release | Equivalent UCSC version |
|---|---|---|
| GRCh39 | Indefinitely postponed[33] | - |
| T2T-CHM13 | January 2022 | - |
| GRCh38 | Dec 2013 | hg38 |
| GRCh37 | Feb 2009 | hg19 |
| NCBI Build 36.1 | Mar 2006 | hg18 |
| NCBI Build 35 | May 2004 | hg17 |
| NCBI Build 34 | Jul 2003 | hg16 |
Limitations
For much of a genome, the reference provides a good approximation of the DNA of any single individual. But in regions with high allelic diversity, such as the major histocompatibility complex in humans and the major urinary proteins of mice, the reference genome may differ significantly from other individuals.[35][36][37] Due to the fact that the reference genome is a "single" distinct sequence, which gives its utility as an index or locator of genomic features, there are limitations in terms of how faithfully it represents the human genome and its variability. Most of the initial samples used for reference genome sequencing came from people of European ancestry. In 2010, it was found that, by de novo assembling genomes from African and Asian populations with the NCBI reference genome (version NCBI36), these genomes had ~5Mb sequences that did not align against any region of the reference genome.[38]
Following projects to the Human Genome Project seek to address a deeper and more diverse characerization of the human genetic variability, which the reference genome is not able to represent. The HapMap Project, active during the period 2002 -2010, with the purpose of creating a haplotypes map and their most common variations among different human populations. Up to 11 populations of different ancestry were studied, such as individuals of the Han ethnic group from China, Gujaratis from India, the Yoruba people from Nigeria or Japanese people, among others.[39][40][41][42] The 1000 Genomes Project, carried out between 2008 and 2015, with the aim of creating a database that includes more than 95% of the variations present in the human genome and whose results can be used in studies of association with diseases (GWAS) such as diabetes, cardiovascular or autoimmune diseases. A total of 26 ethnic groups were studied in this project, expanding the scope of the HapMap project to new ethnic groups such as the Mende people of Sierra Leone, the Vietnamese people or the Bengali people.[43][44][45][46] The Human Pangenome Project, which started its initial phase in 2019 with the creation of the Human Pangenome Reference Consortium, seeks to create the largest map of human genetic variability taking the results of previous studies as a starting point.[47][48]
Mouse reference genome
Recent mouse genome assemblies are as follows:[34]
| Release name | Date of release | Equivalent UCSC version |
|---|---|---|
| GRCm39 | June 2020 | mm39 |
| GRCm38 | Dec 2011 | mm10 |
| NCBI Build 37 | Jul 2007 | mm9 |
| NCBI Build 36 | Feb 2006 | mm8 |
| NCBI Build 35 | Aug 2005 | mm7 |
| NCBI Build 34 | Mar 2005 | mm6 |
Other genomes
Since the Human Genome Project was finished, multiple international projects have started, focused on assembling reference genomes for many organisms. Model organisms (e.g., zebrafish (Danio rerio), chicken (Gallus gallus), Escherichia coli etc.) are of special interest to the scientific community, as well as, for example, endangered species (e.g., Asian arowana (Scleropages formosus) or the American bison (Bison bison)). As of August 2022, the NCBI database supports 71 886 partially or completely sequenced and assembled genomes from different species, such as 676 mammals, 590 birds and 865 fishes. Also noteworthy are the numbers of 1796 insects genomes, 3747 fungi, 1025 plants, 33 724 bacteria, 26 004 virus and 2040 archaea.[49] A lot of these species have annotation data associated with their reference genomes that can be publicly accessed and visualized in genome browsers such as Ensembl and UCSC Genome Browser.[50][51]
Some examples of these international projects are: the Chimpanzee Genome Project, carried out between 2005 and 2013 jointly by the Broad Institute and the McDonnell Genome Institute of Washington University in St. Louis, which generated the first reference genomes for 4 subspecies of Pan troglodytes;[52][53] the 100K Pathogen Genome Project, which started in 2012 with the main goal of creating a database of reference genomes for 100 000 pathogen microorganisms to use in public health, outbreaks detection, agriculture and environment;[54] the Earth BioGenome Project, which started in 2018 and aims to sequence and catalog the genomes of all the eukaryotic organisms on Earth to promote biodiversity conservation projects. Inside this big-science project there are up to 50 smaller-scale affiliated projects such as the Africa BioGenome Project or the 1000 Fungal Genomes Project.[55][56][57]
References
- "How many individuals were sequenced for the human reference genome assembly?". Genome Reference Consortium. Retrieved 7 April 2022.
- Flicek P, Aken BL, Beal K, Ballester B, Caccamo M, Chen Y, et al. (January 2008). "Ensembl 2008". Nucleic Acids Research. 36 (Database issue): D707–D714. doi:10.1093/nar/gkm988. PMC 2238821. PMID 18000006.
- "Help - Glossary - Homo sapiens - Ensembl genome browser 87". www.ensembl.org.
- "Golden path length | VectorBase". www.vectorbase.org. Archived from the original on 2020-08-07. Retrieved 2016-12-12.
- "Help - Glossary - Homo sapiens - Ensembl genome browser 87". www.ensembl.org.
- "Whole assembly vs Golden path length in Ensembl? - SEQanswers". seqanswers.com. Retrieved 2016-12-12.
- Gibson, Greg; Muse, Spencer V. (2009). A Primer of Genome Science (3rd ed.). Sinauer Associates. p. 84. ISBN 978-0-878-93236-8.
- "Help - Glossary - Homo_sapiens - Ensembl genome browser 107". www.ensembl.org. Retrieved 2022-09-26.
- Luo, Junwei; Wei, Yawei; Lyu, Mengna; Wu, Zhengjiang; Liu, Xiaoyan; Luo, Huimin; Yan, Chaokun (2021-09-02). "A comprehensive review of scaffolding methods in genome assembly". Briefings in Bioinformatics. 22 (5): bbab033. doi:10.1093/bib/bbab033. ISSN 1477-4054. PMID 33634311.
- "Chromosomes, scaffolds and contigs". www.ensembl.org. Retrieved 2022-09-26.
- Meader, Stephen; Hillier, LaDeana W.; Locke, Devin; Ponting, Chris P.; Lunter, Gerton (May 2010). "Genome assembly quality: Assessment and improvement using the neutral indel model". Genome Research. 20 (5): 675–684. doi:10.1101/gr.096966.109. ISSN 1088-9051. PMC 2860169. PMID 20305016.
- Rice, Edward S.; Green, Richard E. (2019-02-15). "New Approaches for Genome Assembly and Scaffolding". Annual Review of Animal Biosciences. 7 (1): 17–40. doi:10.1146/annurev-animal-020518-115344. ISSN 2165-8102. PMID 30485757. S2CID 54121772.
- Cao, Minh Duc; Nguyen, Son Hoang; Ganesamoorthy, Devika; Elliott, Alysha G.; Cooper, Matthew A.; Coin, Lachlan J. M. (2017-02-20). "Scaffolding and completing genome assemblies in real-time with nanopore sequencing". Nature Communications. 8 (1): 14515. Bibcode:2017NatCo...814515C. doi:10.1038/ncomms14515. ISSN 2041-1723. PMC 5321748. PMID 28218240.
- Mende, Daniel R.; Waller, Alison S.; Sunagawa, Shinichi; Järvelin, Aino I.; Chan, Michelle M.; Arumugam, Manimozhiyan; Raes, Jeroen; Bork, Peer (2012-02-23). "Assessment of Metagenomic Assembly Using Simulated Next Generation Sequencing Data". PLOS ONE. 7 (2): e31386. Bibcode:2012PLoSO...731386M. doi:10.1371/journal.pone.0031386. ISSN 1932-6203. PMC 3285633. PMID 22384016.
- Alhakami, Hind; Mirebrahim, Hamid; Lonardi, Stefano (2017-05-18). "A comparative evaluation of genome assembly reconciliation tools". Genome Biology. 18 (1): 93. doi:10.1186/s13059-017-1213-3. ISSN 1474-7596. PMC 5436433. PMID 28521789.
- Castro, Christina J.; Ng, Terry Fei Fan (2017-11-01). "U50: A New Metric for Measuring Assembly Output Based on Non-Overlapping, Target-Specific Contigs". Journal of Computational Biology. 24 (11): 1071–1080. doi:10.1089/cmb.2017.0013. PMC 5783553. PMID 28418726.
- Scherer S (2008). A short guide to the human genome. CSHL Press. p. 135. ISBN 978-0-87969-791-4.
- "E pluribus unum". Nature Methods. 7 (5): 331. May 2010. doi:10.1038/nmeth0510-331. PMID 20440876.
- Ballouz S, Dobin A, Gillis JA (August 2019). "Is it time to change the reference genome?". Genome Biology. 20 (1): 159. doi:10.1186/s13059-019-1774-4. PMC 6688217. PMID 31399121.
- Rosenfeld JA, Mason CE, Smith TM (11 July 2012). "Limitations of the human reference genome for personalized genomics". PLOS ONE. 7 (7): e40294. Bibcode:2012PLoSO...740294R. doi:10.1371/journal.pone.0040294. PMC 3394790. PMID 22811759.
- Wade N (May 31, 2007). "Genome of DNA Pioneer Is Deciphered". New York Times. Retrieved February 21, 2009.
- Wheeler DA, Srinivasan M, Egholm M, Shen Y, Chen L, McGuire A, et al. (April 2008). "The complete genome of an individual by massively parallel DNA sequencing". Nature. 452 (7189): 872–876. Bibcode:2008Natur.452..872W. doi:10.1038/nature06884. PMID 18421352.
- The exception to this is J. Craig Venter whose DNA was sequenced and assembled using shotgun sequencing methods.
- "Genome Data Viewer - NCBI". www.ncbi.nlm.nih.gov. Retrieved 2022-08-18.
- Schneider VA, Graves-Lindsay T, Howe K, Bouk N, Chen HC, Kitts PA, et al. (May 2017). "Evaluation of GRCh38 and de novo haploid genome assemblies demonstrates the enduring quality of the reference assembly". Genome Research. 27 (5): 849–864. doi:10.1101/gr.213611.116. PMC 5411779. PMID 28396521.
- "GRCh38.p14 - hg38 - Genome - Assembly - NCBI". www.ncbi.nlm.nih.gov. Retrieved 2022-08-19.
- Genome Reference Consortium (2022-05-09). "GenomeRef: GRCh38.p14 is now released!". GRC Blog (GenomeRef). Retrieved 2022-08-19.
- "GRCh38.p14 - hg38 - Genome - Assembly - NCBI - Statistics Report". www.ncbi.nlm.nih.gov. Retrieved 2022-08-18.
- "Telomere-to-Telomere". NHGRI. Retrieved 2022-08-16.
- Nurk S, Koren S, Rhie A, Rautiainen M, Bzikadze AV, Mikheenko A, et al. (April 2022). "The complete sequence of a human genome". Science. 376 (6588): 44–53. Bibcode:2022Sci...376...44N. doi:10.1126/science.abj6987. PMC 9186530. PMID 35357919. S2CID 247854936.
- "T2T-CHM13v2.0 - Genome - Assembly - NCBI". www.ncbi.nlm.nih.gov. Retrieved 2022-08-16.
- Altemose, Nicolas; Logsdon, Glennis A.; Bzikadze, Andrey V.; Sidhwani, Pragya; Langley, Sasha A.; Caldas, Gina V.; Hoyt, Savannah J.; Uralsky, Lev; Ryabov, Fedor D.; Shew, Colin J.; Sauria, Michael E. G.; Borchers, Matthew; Gershman, Ariel; Mikheenko, Alla; Shepelev, Valery A. (April 2022). "Complete genomic and epigenetic maps of human centromeres". Science. 376 (6588): eabl4178. doi:10.1126/science.abl4178. ISSN 0036-8075. PMC 9233505. PMID 35357911.
- "Genome Reference Consortium". www.ncbi.nlm.nih.gov. Retrieved 2022-08-18.
- "UCSC Genome Bioinformatics: FAQ". genome.ucsc.edu. Retrieved 2016-08-18.
- MHC Sequencing Consortium (October 1999). "Complete sequence and gene map of a human major histocompatibility complex. The MHC sequencing consortium". Nature. 401 (6756): 921–923. Bibcode:1999Natur.401..921T. doi:10.1038/44853. PMID 10553908. S2CID 186243515.
- Logan DW, Marton TF, Stowers L (September 2008). Vosshall LB (ed.). "Species specificity in major urinary proteins by parallel evolution". PLOS ONE. 3 (9): e3280. Bibcode:2008PLoSO...3.3280L. doi:10.1371/journal.pone.0003280. PMC 2533699. PMID 18815613.
- Hurst J, Beynon RJ, Roberts SC, Wyatt TD (October 2007). Urinary Lipocalins in Rodenta:is there a Generic Model?. Chemical Signals in Vertebrates 11. Springer New York. ISBN 978-0-387-73944-1.
- Li R, Li Y, Zheng H, Luo R, Zhu H, Li Q, et al. (January 2010). "Building the sequence map of the human pan-genome". Nature Biotechnology. 28 (1): 57–63. doi:10.1038/nbt.1596. PMID 19997067. S2CID 205274447.
- The International HapMap Consortium (October 2005). "A haplotype map of the human genome". Nature. 437 (7063): 1299–1320. Bibcode:2005Natur.437.1299T. doi:10.1038/nature04226. PMC 1880871. PMID 16255080.
- Frazer KA, Ballinger DG, Cox DR, Hinds DA, Stuve LL, Gibbs RA, et al. (October 2007). "A second generation human haplotype map of over 3.1 million SNPs". Nature. 449 (7164): 851–861. Bibcode:2007Natur.449..851F. doi:10.1038/nature06258. PMC 2689609. PMID 17943122.
- Altshuler DM, Gibbs RA, Peltonen L, Altshuler DM, Gibbs RA, Peltonen L, et al. (September 2010). "Integrating common and rare genetic variation in diverse human populations". Nature. 467 (7311): 52–58. Bibcode:2010Natur.467...52T. doi:10.1038/nature09298. PMC 3173859. PMID 20811451.
- "International HapMap Project". Genome.gov. Retrieved 2022-08-18.
- Abecasis GR, Altshuler D, Auton A, Brooks LD, Durbin RM, Gibbs RA, et al. (October 2010). "A map of human genome variation from population-scale sequencing". Nature. 467 (7319): 1061–1073. Bibcode:2010Natur.467.1061T. doi:10.1038/nature09534. PMC 3042601. PMID 20981092.
- Abecasis GR, Auton A, Brooks LD, DePristo MA, Durbin RM, Handsaker RE, et al. (November 2012). "An integrated map of genetic variation from 1,092 human genomes". Nature. 491 (7422): 56–65. Bibcode:2012Natur.491...56T. doi:10.1038/nature11632. PMC 3498066. PMID 23128226.
- Auton A, Brooks LD, Durbin RM, Garrison EP, Kang HM, Korbel JO, et al. (October 2015). "A global reference for human genetic variation". Nature. 526 (7571): 68–74. Bibcode:2015Natur.526...68T. doi:10.1038/nature15393. PMC 4750478. PMID 26432245.
- Sudmant PH, Rausch T, Gardner EJ, Handsaker RE, Abyzov A, Huddleston J, et al. (October 2015). "An integrated map of structural variation in 2,504 human genomes". Nature. 526 (7571): 75–81. Bibcode:2015Natur.526...75.. doi:10.1038/nature15394. PMC 4617611. PMID 26432246.
- Miga KH, Wang T (August 2021). "The Need for a Human Pangenome Reference Sequence". Annual Review of Genomics and Human Genetics. 22 (1): 81–102. doi:10.1146/annurev-genom-120120-081921. PMC 8410644. PMID 33929893.
- Wang T, Antonacci-Fulton L, Howe K, Lawson HA, Lucas JK, Phillippy AM, et al. (April 2022). "The Human Pangenome Project: a global resource to map genomic diversity". Nature. 604 (7906): 437–446. Bibcode:2022Natur.604..437W. doi:10.1038/s41586-022-04601-8. PMC 9402379. PMID 35444317. S2CID 248297723.
- "Genome List - Genome - NCBI". www.ncbi.nlm.nih.gov. Retrieved 2022-08-18.
- "Species List". uswest.ensembl.org. Retrieved 2022-08-18.
- "GenArk: UCSC Genome Archive". hgdownload.soe.ucsc.edu. Retrieved 2022-08-18.
- "Chimpanzee Genome Project". BCM-HGSC. 2016-03-04. Retrieved 2022-08-18.
- Prado-Martinez J, Sudmant PH, Kidd JM, Li H, Kelley JL, Lorente-Galdos B, et al. (July 2013). "Great ape genetic diversity and population history". Nature. 499 (7459): 471–475. Bibcode:2013Natur.499..471P. doi:10.1038/nature12228. PMC 3822165. PMID 23823723.
- "100K Pathogen Genome Project – Genomes for Public Health & Food Safety". Retrieved 2022-08-18.
- Lewin HA, Robinson GE, Kress WJ, Baker WJ, Coddington J, Crandall KA, et al. (April 2018). "Earth BioGenome Project: Sequencing life for the future of life". Proceedings of the National Academy of Sciences of the United States of America. 115 (17): 4325–4333. Bibcode:2018PNAS..115.4325L. doi:10.1073/pnas.1720115115. PMC 5924910. PMID 29686065.
- "African BioGenome Project – Genomics in the service of conservation and improvement of African biological diversity". Retrieved 2022-08-18.
- "1000 Fungal Genomes Project". mycocosm.jgi.doe.gov. Retrieved 2022-08-18.