Semantic Web
The Semantic Web, sometimes known as Web 3.0 (not to be confused with Web3), is an extension of the World Wide Web through standards[1] set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
| Semantics | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
|
Semantics of programming languages | ||||||||
|
||||||||
To enable the encoding of semantics with the data, technologies such as Resource Description Framework (RDF)[2] and Web Ontology Language (OWL)[3] are used. These technologies are used to formally represent metadata. For example, ontology can describe concepts, relationships between entities, and categories of things. These embedded semantics offer significant advantages such as reasoning over data and operating with heterogeneous data sources.[4]
These standards promote common data formats and exchange protocols on the Web, fundamentally the RDF. According to the W3C, "The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries."[5] The Semantic Web is therefore regarded as an integrator across different content and information applications and systems.
The term was coined by Tim Berners-Lee for a web of data (or data web)[6] that can be processed by machines[7]—that is, one in which much of the meaning is machine-readable. While its critics have questioned its feasibility, proponents argue that applications in library and information science, industry, biology and human sciences research have already proven the validity of the original concept.[8]
Berners-Lee originally expressed his vision of the Semantic Web in 1999 as follows:
I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A "Semantic Web", which makes this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The "intelligent agents" people have touted for ages will finally materialize.[9]
The 2001 Scientific American article by Berners-Lee, Hendler, and Lassila described an expected evolution of the existing Web to a Semantic Web.[10] In 2006, Berners-Lee and colleagues stated that: "This simple idea…remains largely unrealized".[11] In 2013, more than four million Web domains (out of roughly 250 million total) contained Semantic Web markup.[12]
Example
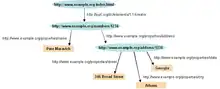
In the following example, the text "Paul Schuster was born in Dresden" on a website will be annotated, connecting a person with their place of birth. The following HTML fragment shows how a small graph is being described, in RDFa-syntax using a schema.org vocabulary and a Wikidata ID:
<div vocab="https://schema.org/" typeof="Person">
<span property="name">Paul Schuster</span> was born in
<span property="birthPlace" typeof="Place" href="https://www.wikidata.org/entity/Q1731">
<span property="name">Dresden</span>.
</span>
</div>

The example defines the following five triples (shown in Turtle syntax). Each triple represents one edge in the resulting graph: the first element of the triple (the subject) is the name of the node where the edge starts, the second element (the predicate) the type of the edge, and the last and third element (the object) either the name of the node where the edge ends or a literal value (e.g. a text, a number, etc.).
_:a <https://www.w3.org/1999/02/22-rdf-syntax-ns#type> <https://schema.org/Person> .
_:a <https://schema.org/name> "Paul Schuster" .
_:a <https://schema.org/birthPlace> <https://www.wikidata.org/entity/Q1731> .
<https://www.wikidata.org/entity/Q1731> <https://schema.org/itemtype> <https://schema.org/Place> .
<https://www.wikidata.org/entity/Q1731> <https://schema.org/name> "Dresden" .
The triples result in the graph shown in the given figure.

One of the advantages of using Uniform Resource Identifiers (URIs) is that they can be dereferenced using the HTTP protocol. According to the so-called Linked Open Data principles, such a dereferenced URI should result in a document that offers further data about the given URI. In this example, all URIs, both for edges and nodes (e.g. http://schema.org/Person, http://schema.org/birthPlace, http://www.wikidata.org/entity/Q1731) can be dereferenced and will result in further RDF graphs, describing the URI, e.g. that Dresden is a city in Germany, or that a person, in the sense of that URI, can be fictional.
The second graph shows the previous example, but now enriched with a few of the triples from the documents that result from dereferencing https://schema.org/Person (green edge) and https://www.wikidata.org/entity/Q1731 (blue edges).
Additionally to the edges given in the involved documents explicitly, edges can be automatically inferred: the triple
_:a <https://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://schema.org/Person> .
from the original RDFa fragment and the triple
<https://schema.org/Person> <http://www.w3.org/2002/07/owl#equivalentClass> <http://xmlns.com/foaf/0.1/Person> .
from the document at https://schema.org/Person (green edge in the figure) allow to infer the following triple, given OWL semantics (red dashed line in the second Figure):
_:a <https://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> .
Background
The concept of the semantic network model was formed in the early 1960s by researchers such as the cognitive scientist Allan M. Collins, linguist M. Ross Quillian and psychologist Elizabeth F. Loftus as a form to represent semantically structured knowledge. When applied in the context of the modern internet, it extends the network of hyperlinked human-readable web pages by inserting machine-readable metadata about pages and how they are related to each other. This enables automated agents to access the Web more intelligently and perform more tasks on behalf of users. The term "Semantic Web" was coined by Tim Berners-Lee,[7] the inventor of the World Wide Web and director of the World Wide Web Consortium ("W3C"), which oversees the development of proposed Semantic Web standards. He defines the Semantic Web as "a web of data that can be processed directly and indirectly by machines".
Many of the technologies proposed by the W3C already existed before they were positioned under the W3C umbrella. These are used in various contexts, particularly those dealing with information that encompasses a limited and defined domain, and where sharing data is a common necessity, such as scientific research or data exchange among businesses. In addition, other technologies with similar goals have emerged, such as microformats.
Limitations of HTML
Many files on a typical computer can also be loosely divided into human-readable documents and machine-readable data. Documents like mail messages, reports, and brochures are read by humans. Data, such as calendars, address books, playlists, and spreadsheets are presented using an application program that lets them be viewed, searched, and combined.
Currently, the World Wide Web is based mainly on documents written in Hypertext Markup Language (HTML), a markup convention that is used for coding a body of text interspersed with multimedia objects such as images and interactive forms. Metadata tags provide a method by which computers can categorize the content of web pages. In the examples below, the field names "keywords", "description" and "author" are assigned values such as "computing", and "cheap widgets for sale" and "John Doe".
<meta name="keywords" content="computing, computer studies, computer" />
<meta name="description" content="Cheap widgets for sale" />
<meta name="author" content="John Doe" />
Because of this metadata tagging and categorization, other computer systems that want to access and share this data can easily identify the relevant values.
With HTML and a tool to render it (perhaps web browser software, perhaps another user agent), one can create and present a page that lists items for sale. The HTML of this catalog page can make simple, document-level assertions such as "this document's title is 'Widget Superstore'", but there is no capability within the HTML itself to assert unambiguously that, for example, item number X586172 is an Acme Gizmo with a retail price of €199, or that it is a consumer product. Rather, HTML can only say that the span of text "X586172" is something that should be positioned near "Acme Gizmo" and "€199", etc. There is no way to say "this is a catalog" or even to establish that "Acme Gizmo" is a kind of title or that "€199" is a price. There is also no way to express that these pieces of information are bound together in describing a discrete item, distinct from other items perhaps listed on the page.
Semantic HTML refers to the traditional HTML practice of markup following intention, rather than specifying layout details directly. For example, the use of <em> denoting "emphasis" rather than <i>, which specifies italics. Layout details are left up to the browser, in combination with Cascading Style Sheets. But this practice falls short of specifying the semantics of objects such as items for sale or prices.
Microformats extend HTML syntax to create machine-readable semantic markup about objects including people, organizations, events and products.[13] Similar initiatives include RDFa, Microdata and Schema.org.
Semantic Web solutions
The Semantic Web takes the solution further. It involves publishing in languages specifically designed for data: Resource Description Framework (RDF), Web Ontology Language (OWL), and Extensible Markup Language (XML). HTML describes documents and the links between them. RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts.
These technologies are combined in order to provide descriptions that supplement or replace the content of Web documents. Thus, content may manifest itself as descriptive data stored in Web-accessible databases,[14] or as markup within documents (particularly, in Extensible HTML (XHTML) interspersed with XML, or, more often, purely in XML, with layout or rendering cues stored separately). The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content. In this way, a machine can process knowledge itself, instead of text, using processes similar to human deductive reasoning and inference, thereby obtaining more meaningful results and helping computers to perform automated information gathering and research.
An example of a tag that would be used in a non-semantic web page:
<item>blog</item>
Encoding similar information in a semantic web page might look like this:
<item rdf:about="https://example.org/semantic-web/">Semantic Web</item>
Tim Berners-Lee calls the resulting network of Linked Data the Giant Global Graph, in contrast to the HTML-based World Wide Web. Berners-Lee posits that if the past was document sharing, the future is data sharing. His answer to the question of "how" provides three points of instruction. One, a URL should point to the data. Two, anyone accessing the URL should get data back. Three, relationships in the data should point to additional URLs with data.
Tags and identifiers
Tags, including hierarchical categories and tags that are collaboratively added and maintained (e.g. with folksonomies) can be considered part of, of potential use to or a step towards the semantic Web vision.[15][16][17]
Unique identifiers, including hierarchical categories and collaboratively added ones, analysis tools (e.g. scite.ai algorithms)[18] and metadata, including tags, can be used to create forms of semantic webs – webs that are to a certain degree semantic. In particular, such has been used for structuring scientific research i.a. by research topics and scientific fields by the projects OpenAlex,[19][20][21] Wikidata and Scholia which are under development and provide APIs, Web-pages, feeds and graphs for various semantic queries.
Web 3.0
Tim Berners-Lee has described the Semantic Web as a component of Web 3.0.[22]
People keep asking what Web 3.0 is. I think maybe when you've got an overlay of scalable vector graphics – everything rippling and folding and looking misty – on Web 2.0 and access to a semantic Web integrated across a huge space of data, you'll have access to an unbelievable data resource …
— Tim Berners-Lee, 2006
"Semantic Web" is sometimes used as a synonym for "Web 3.0",[23] though the definition of each term varies.
Challenges
Some of the challenges for the Semantic Web include vastness, vagueness, uncertainty, inconsistency, and deceit. Automated reasoning systems will have to deal with all of these issues in order to deliver on the promise of the Semantic Web.
- Vastness: The World Wide Web contains many billions of pages. The SNOMED CT medical terminology ontology alone contains 370,000 class names, and existing technology has not yet been able to eliminate all semantically duplicated terms. Any automated reasoning system will have to deal with truly huge inputs.
- Vagueness: These are imprecise concepts like "young" or "tall". This arises from the vagueness of user queries, of concepts represented by content providers, of matching query terms to provider terms and of trying to combine different knowledge bases with overlapping but subtly different concepts. Fuzzy logic is the most common technique for dealing with vagueness.
- Uncertainty: These are precise concepts with uncertain values. For example, a patient might present a set of symptoms that correspond to a number of different distinct diagnoses each with a different probability. Probabilistic reasoning techniques are generally employed to address uncertainty.
- Inconsistency: These are logical contradictions that will inevitably arise during the development of large ontologies, and when ontologies from separate sources are combined. Deductive reasoning fails catastrophically when faced with inconsistency, because "anything follows from a contradiction". Defeasible reasoning and paraconsistent reasoning are two techniques that can be employed to deal with inconsistency.
- Deceit: This is when the producer of the information is intentionally misleading the consumer of the information. Cryptography techniques are currently utilized to alleviate this threat. By providing a means to determine the information's integrity, including that which relates to the identity of the entity that produced or published the information, however credibility issues still have to be addressed in cases of potential deceit.
This list of challenges is illustrative rather than exhaustive, and it focuses on the challenges to the "unifying logic" and "proof" layers of the Semantic Web. The World Wide Web Consortium (W3C) Incubator Group for Uncertainty Reasoning for the World Wide Web[24] (URW3-XG) final report lumps these problems together under the single heading of "uncertainty".[25] Many of the techniques mentioned here will require extensions to the Web Ontology Language (OWL) for example to annotate conditional probabilities. This is an area of active research.[26]
Standards
Standardization for Semantic Web in the context of Web 3.0 is under the care of W3C.[27]
Components
The term "Semantic Web" is often used more specifically to refer to the formats and technologies that enable it.[5] The collection, structuring and recovery of linked data are enabled by technologies that provide a formal description of concepts, terms, and relationships within a given knowledge domain. These technologies are specified as W3C standards and include:
- Resource Description Framework (RDF), a general method for describing information
- RDF Schema (RDFS)
- Simple Knowledge Organization System (SKOS)
- SPARQL, an RDF query language
- Notation3 (N3), designed with human readability in mind
- N-Triples, a format for storing and transmitting data
- Turtle (Terse RDF Triple Language)
- Web Ontology Language (OWL), a family of knowledge representation languages
- Rule Interchange Format (RIF), a framework of web rule language dialects supporting rule interchange on the Web
- JavaScript Object Notation for Linked Data (JSON-LD), a JSON-based method to describe data
- ActivityPub, a generic way for client and server to communicate with each other. This is used by the popular decentralized social network Mastodon.
The Semantic Web Stack illustrates the architecture of the Semantic Web. The functions and relationships of the components can be summarized as follows:[28]
- XML provides an elemental syntax for content structure within documents, yet associates no semantics with the meaning of the content contained within. XML is not at present a necessary component of Semantic Web technologies in most cases, as alternative syntaxes exist, such as Turtle. Turtle is a de facto standard, but has not been through a formal standardization process.
- XML Schema is a language for providing and restricting the structure and content of elements contained within XML documents.
- RDF is a simple language for expressing data models, which refer to objects ("web resources") and their relationships. An RDF-based model can be represented in a variety of syntaxes, e.g., RDF/XML, N3, Turtle, and RDFa. RDF is a fundamental standard of the Semantic Web.[29][30]
- RDF Schema extends RDF and is a vocabulary for describing properties and classes of RDF-based resources, with semantics for generalized-hierarchies of such properties and classes.
- OWL adds more vocabulary for describing properties and classes: among others, relations between classes (e.g. disjointness), cardinality (e.g. "exactly one"), equality, richer typing of properties, characteristics of properties (e.g. symmetry), and enumerated classes.
- SPARQL is a protocol and query language for semantic web data sources.
- RIF is the W3C Rule Interchange Format. It's an XML language for expressing Web rules that computers can execute. RIF provides multiple versions, called dialects. It includes a RIF Basic Logic Dialect (RIF-BLD) and RIF Production Rules Dialect (RIF PRD).
Current state of standardization
Well-established standards:
- RDF
- RDFS
- Rule Interchange Format (RIF)
- SPARQL
- Unicode
- Uniform Resource Identifier
- Web Ontology Language (OWL)
- XML
Not yet fully realized:
- Unifying Logic and Proof layers
- Semantic Web Rule Language (SWRL)
Applications
The intent is to enhance the usability and usefulness of the Web and its interconnected resources by creating semantic web services, such as:
- Servers that expose existing data systems using the RDF and SPARQL standards. Many converters to RDF exist from different applications.[31] Relational databases are an important source. The semantic web server attaches to the existing system without affecting its operation.
- Documents "marked up" with semantic information (an extension of the HTML
<meta>tags used in today's Web pages to supply information for Web search engines using web crawlers). This could be machine-understandable information about the human-understandable content of the document (such as the creator, title, description, etc.) or it could be purely metadata representing a set of facts (such as resources and services elsewhere on the site). Note that anything that can be identified with a Uniform Resource Identifier (URI) can be described, so the semantic web can reason about animals, people, places, ideas, etc. There are four semantic annotation formats that can be used in HTML documents; Microformat, RDFa, Microdata and JSON-LD.[32] Semantic markup is often generated automatically, rather than manually.
.png.webp)
- Common metadata vocabularies (ontologies) and maps between vocabularies that allow document creators to know how to mark up their documents so that agents can use the information in the supplied metadata (so that Author in the sense of 'the Author of the page' will not be confused with Author in the sense of a book that is the subject of a book review).
- Automated agents to perform tasks for users of the semantic web using this data.
- Semantic translation. An alternative or complementary approach are improvements to contextual and semantic understanding of texts – these could be aided via Semantic Web methods so that only increasingly small numbers of mistranslations need to be corrected in manual or semi-automated post-editing.
- Web-based services (often with agents of their own) to supply information specifically to agents, for example, a Trust service that an agent could ask if some online store has a history of poor service or spamming.
- Semantic Web ideas are implemented in collaborative structured argument mapping sites where their relations are organized semantically, arguments can be mirrored (linked) to multiple places, reused (copied), rated, and changed as semantic distinct units. Ideas for such, or a more widely adopted "World Wide Argument Web", go back to at least 2007[33] and have been implemented to some degree in Argüman[34] and Kialo. Further steps towards semantic web services may include enabling "Querying", argument search engines,[35] and "summarizing the contentious and agreed-upon points of a discussion".[36]
Such services could be useful to public search engines, or could be used for knowledge management within an organization. Business applications include:
- Facilitating the integration of information from mixed sources[37]
- Dissolving ambiguities in corporate terminology
- Improving information retrieval thereby reducing information overload and increasing the refinement and precision of the data retrieved[38][39][40][41]
- Identifying relevant information with respect to a given domain[42]
- Providing decision making support
In a corporation, there is a closed group of users and the management is able to enforce company guidelines like the adoption of specific ontologies and use of semantic annotation. Compared to the public Semantic Web there are lesser requirements on scalability and the information circulating within a company can be more trusted in general; privacy is less of an issue outside of handling of customer data.
Skeptical reactions
Practical feasibility
Critics question the basic feasibility of a complete or even partial fulfillment of the Semantic Web, pointing out both difficulties in setting it up and a lack of general-purpose usefulness that prevents the required effort from being invested. In a 2003 paper, Marshall and Shipman point out the cognitive overhead inherent in formalizing knowledge, compared to the authoring of traditional web hypertext:[43]
While learning the basics of HTML is relatively straightforward, learning a knowledge representation language or tool requires the author to learn about the representation's methods of abstraction and their effect on reasoning. For example, understanding the class-instance relationship, or the superclass-subclass relationship, is more than understanding that one concept is a "type of" another concept. [...] These abstractions are taught to computer scientists generally and knowledge engineers specifically but do not match the similar natural language meaning of being a "type of" something. Effective use of such a formal representation requires the author to become a skilled knowledge engineer in addition to any other skills required by the domain. [...] Once one has learned a formal representation language, it is still often much more effort to express ideas in that representation than in a less formal representation [...]. Indeed, this is a form of programming based on the declaration of semantic data and requires an understanding of how reasoning algorithms will interpret the authored structures.
According to Marshall and Shipman, the tacit and changing nature of much knowledge adds to the knowledge engineering problem, and limits the Semantic Web's applicability to specific domains. A further issue that they point out are domain- or organization-specific ways to express knowledge, which must be solved through community agreement rather than only technical means.[43] As it turns out, specialized communities and organizations for intra-company projects have tended to adopt semantic web technologies greater than peripheral and less-specialized communities.[44] The practical constraints toward adoption have appeared less challenging where domain and scope is more limited than that of the general public and the World-Wide Web.[44]
Finally, Marshall and Shipman see pragmatic problems in the idea of (Knowledge Navigator-style) intelligent agents working in the largely manually curated Semantic Web:[43]
In situations in which user needs are known and distributed information resources are well described, this approach can be highly effective; in situations that are not foreseen and that bring together an unanticipated array of information resources, the Google approach is more robust. Furthermore, the Semantic Web relies on inference chains that are more brittle; a missing element of the chain results in a failure to perform the desired action, while the human can supply missing pieces in a more Google-like approach. [...] cost-benefit tradeoffs can work in favor of specially-created Semantic Web metadata directed at weaving together sensible well-structured domain-specific information resources; close attention to user/customer needs will drive these federations if they are to be successful.
Cory Doctorow's critique ("metacrap")[45] is from the perspective of human behavior and personal preferences. For example, people may include spurious metadata into Web pages in an attempt to mislead Semantic Web engines that naively assume the metadata's veracity. This phenomenon was well known with metatags that fooled the Altavista ranking algorithm into elevating the ranking of certain Web pages: the Google indexing engine specifically looks for such attempts at manipulation. Peter Gärdenfors and Timo Honkela point out that logic-based semantic web technologies cover only a fraction of the relevant phenomena related to semantics.[46][47]
Censorship and privacy
Enthusiasm about the semantic web could be tempered by concerns regarding censorship and privacy. For instance, text-analyzing techniques can now be easily bypassed by using other words, metaphors for instance, or by using images in place of words. An advanced implementation of the semantic web would make it much easier for governments to control the viewing and creation of online information, as this information would be much easier for an automated content-blocking machine to understand. In addition, the issue has also been raised that, with the use of FOAF files and geolocation meta-data, there would be very little anonymity associated with the authorship of articles on things such as a personal blog. Some of these concerns were addressed in the "Policy Aware Web" project[48] and is an active research and development topic.
Doubling output formats
Another criticism of the semantic web is that it would be much more time-consuming to create and publish content because there would need to be two formats for one piece of data: one for human viewing and one for machines. However, many web applications in development are addressing this issue by creating a machine-readable format upon the publishing of data or the request of a machine for such data. The development of microformats has been one reaction to this kind of criticism. Another argument in defense of the feasibility of semantic web is the likely falling price of human intelligence tasks in digital labor markets, such as Amazon's Mechanical Turk.
Specifications such as eRDF and RDFa allow arbitrary RDF data to be embedded in HTML pages. The GRDDL (Gleaning Resource Descriptions from Dialects of Language) mechanism allows existing material (including microformats) to be automatically interpreted as RDF, so publishers only need to use a single format, such as HTML.
Research activities on corporate applications
The first research group explicitly focusing on the Corporate Semantic Web was the ACACIA team at INRIA-Sophia-Antipolis, founded in 2002. Results of their work include the RDF(S) based Corese[49] search engine, and the application of semantic web technology in the realm of distributed artificial intelligence for knowledge management (e.g. ontologies and multi-agent systems for corporate semantic Web) [50] and E-learning.[51]
Since 2008, the Corporate Semantic Web research group, located at the Free University of Berlin, focuses on building blocks: Corporate Semantic Search, Corporate Semantic Collaboration, and Corporate Ontology Engineering.[52]
Ontology engineering research includes the question of how to involve non-expert users in creating ontologies and semantically annotated content[53] and for extracting explicit knowledge from the interaction of users within enterprises.
Future of applications
Tim O'Reilly, who coined the term Web 2.0, proposed a long-term vision of the Semantic Web as a web of data, where sophisticated applications are navigating and manipulating it.[54] The data web transforms the World Wide Web from a distributed file system into a distributed database.[55]
See also
- AGRIS
- Business semantics management
- Computational semantics
- Calais (Reuters product)
- DBpedia
- Entity–attribute–value model
- EU Open Data Portal
- Hyperdata
- Internet of things
- Linked data
- List of emerging technologies
- Nextbio
- Ontology alignment
- Ontology learning
- RDF and OWL
- Semantic computing
- Semantic Geospatial Web
- Semantic heterogeneity
- Semantic integration
- Semantic matching
- Semantic MediaWiki
- Semantic Sensor Web
- Semantic social network
- Semantic technology
- Semantic Web
- Semantically-Interlinked Online Communities
- Smart-M3
- Social Semantic Web
- Web engineering
- Web resource
- Web science
References
- Semantic Web at W3C: https://www.w3.org/standards/semanticweb/
- "World Wide Web Consortium (W3C), "RDF/XML Syntax Specification (Revised)", 25 Feb. 2014".
- "World Wide Web Consortium (W3C), "OWL Web Ontology Language Overview", W3C Recommendation, 10 Feb. 2004".
- Chung, Seung-Hwa (2018). "The MOUSE approach: Mapping Ontologies using UML for System Engineers". Computer Reviews Journal: 8–29. ISSN 2581-6640.
- "W3C Semantic Web Activity". World Wide Web Consortium (W3C). November 7, 2011. Retrieved November 26, 2011.
- "Q&A with Tim Berners-Lee, Special Report". Bloomberg. Retrieved 14 April 2018.
- Berners-Lee, Tim; James Hendler; Ora Lassila (May 17, 2001). "The Semantic Web". Scientific American. Retrieved July 2, 2019.
- Lee Feigenbaum (May 1, 2007). "The Semantic Web in Action". Scientific American. Retrieved February 24, 2010.
- Berners-Lee, Tim; Fischetti, Mark (1999). Weaving the Web. HarperSanFrancisco. chapter 12. ISBN 978-0-06-251587-2.
- Berners-Lee, Tim; Hendler, James; Lassila, Ora (May 17, 2001). "The Semantic Web" (PDF). Scientific American. Vol. 284, no. 5. pp. 34–43. JSTOR 26059207. S2CID 56818714. Archived from the original (PDF) on October 10, 2017. Retrieved March 13, 2008.
- Nigel Shadbolt; Wendy Hall; Tim Berners-Lee (2006). "The Semantic Web Revisited" (PDF). IEEE Intelligent Systems. Archived from the original (PDF) on March 20, 2013. Retrieved April 13, 2007.
- Ramanathan V. Guha (2013). "Light at the End of the Tunnel". International Semantic Web Conference 2013 Keynote. Retrieved March 8, 2015.
- Allsopp, John (March 2007). Microformats: Empowering Your Markup for Web 2.0. Friends of ED. p. 368. ISBN 978-1-59059-814-6.
- Artem Chebotko and Shiyong Lu, "Querying the Semantic Web: An Efficient Approach Using Relational Databases", LAP Lambert Academic Publishing, ISBN 978-3-8383-0264-5, 2009.
- "Towards the Semantic Web: Collaborative Tag Suggestions" (PDF).
- Specia, Lucia; Motta, Enrico (2007). "Integrating Folksonomies with the Semantic Web". The Semantic Web: Research and Applications. Lecture Notes in Computer Science. Vol. 4519. Springer. pp. 624–639. doi:10.1007/978-3-540-72667-8_44. ISBN 978-3-540-72666-1.
- "Bridging the gap between folksonomies and the semantic web: an experience report" (PDF).
- Nicholson, Josh M.; Mordaunt, Milo; Lopez, Patrice; Uppala, Ashish; Rosati, Domenic; Rodrigues, Neves P.; Grabitz, Peter; Rife, Sean C. (5 November 2021). "scite: A smart citation index that displays the context of citations and classifies their intent using deep learning". Quantitative Science Studies. 2 (3): 882–898. doi:10.1162/qss_a_00146.
- Singh Chawla, Dalmeet (24 January 2022). "Massive open index of scholarly papers launches". Nature. doi:10.1038/d41586-022-00138-y. Retrieved 14 February 2022.
- "OpenAlex: The Promising Alternative to Microsoft Academic Graph". Singapore Management University (SMU). Retrieved 14 February 2022.
- "OpenAlex Documentation". Retrieved 18 February 2022.
- Shannon, Victoria (23 May 2006). "A 'more revolutionary' Web". International Herald Tribune. Retrieved 26 June 2006.
- "Web 3.0 Explained, Plus the History of Web 1.0 and 2.0". Investopedia. Retrieved 2022-10-21.
- "W3C Uncertainty Reasoning for the World Wide Web". www.w3.org. Retrieved 2021-05-14.
- "Uncertainty Reasoning for the World Wide Web". W3.org. Retrieved 20 December 2018.
- Lukasiewicz, Thomas; Umberto Straccia (2008). "Managing uncertainty and vagueness in description logics for the Semantic Web" (PDF). Web Semantics: Science, Services and Agents on the World Wide Web. 6 (4): 291–308. doi:10.1016/j.websem.2008.04.001.
- "Semantic Web Standards". W3.org. Retrieved 14 April 2018.
- "OWL Web Ontology Language Overview". World Wide Web Consortium (W3C). February 10, 2004. Retrieved November 26, 2011.
- "Resource Description Framework (RDF)". World Wide Web Consortium.
- Allemang, Dean; Hendler, James; Gandon, Fabien (August 3, 2020). Semantic Web for the Working Ontologist : Effective Modeling for Linked Data, RDFS, and OWL (Third ed.). [New York, NY, USA]: ACM Books; 3rd edition. ISBN 978-1450376143.
- "ConverterToRdf - W3C Wiki". W3.org. Retrieved 20 December 2018.
- Sikos, Leslie F. (2015). Mastering Structured Data on the Semantic Web: From HTML5 Microdata to Linked Open Data. Apress. p. 23. ISBN 978-1-4842-1049-9.
- Kiesel, Johannes; Lang, Kevin; Wachsmuth, Henning; Hornecker, Eva; Stein, Benno (14 March 2020). "Investigating Expectations for Voice-based and Conversational Argument Search on the Web". Proceedings of the 2020 Conference on Human Information Interaction and Retrieval. ACM. pp. 53–62. doi:10.1145/3343413.3377978. ISBN 9781450368926. S2CID 212676751.
- Vetere, Guido (30 June 2018). "L'impossibile necessità delle piattaforme sociali decentralizzate". DigitCult - Scientific Journal on Digital Cultures. 3 (1): 41–50. doi:10.4399/97888255159096.
- Bikakis, Antonis; Flouris, Giorgos; Patkos, Theodore; Plexousakis, Dimitris (2023). "Sketching the vision of the Web of Debates". Frontiers in Artificial Intelligence. 6. doi:10.3389/frai.2023.1124045. ISSN 2624-8212. PMC 10313200. PMID 37396970.
- Schneider, Jodi; Groza, Tudor; Passant, Alexandre. "A Review of Argumentation for the Social Semantic Web" (PDF).
{{cite journal}}: Cite journal requires|journal=(help) - Zhang, Chuanrong; Zhao, Tian; Li, Weidong (2015). Geospatial Semantic Web. Springer International Publishing : Imprint: Springer. ISBN 978-3-319-17801-1.
- Omar Alonso and Hugo Zaragoza. 2008. Exploiting semantic annotations in information retrieval: ESAIR '08. SIGIR Forum 42, 1 (June 2008), 55–58. doi:10.1145/1394251.1394262
- Jaap Kamps, Jussi Karlgren, and Ralf Schenkel. 2011. Report on the third workshop on exploiting semantic annotations in information retrieval (ESAIR). SIGIR Forum 45, 1 (May 2011), 33–41. doi:10.1145/1988852.1988858
- Jaap Kamps, Jussi Karlgren, Peter Mika, and Vanessa Murdock. 2012. Fifth workshop on exploiting semantic annotations in information retrieval: ESAIR '12). In Proceedings of the 21st ACM international conference on information and knowledge management (CIKM '12). ACM, New York, NY, USA, 2772–2773. doi:10.1145/2396761.2398761
- Omar Alonso, Jaap Kamps, and Jussi Karlgren. 2015. Report on the Seventh Workshop on Exploiting Semantic Annotations in Information Retrieval (ESAIR '14). SIGIR Forum 49, 1 (June 2015), 27–34. doi:10.1145/2795403.2795412
- Kuriakose, John (September 2009). "Understanding and Adopting Semantic Web Technology". Cutter IT Journal. CUTTER INFORMATION CORP. 22 (9): 10–18.
- Marshall, Catherine C.; Shipman, Frank M. (2003). Which semantic web? (PDF). Proc. ACM Conf. on Hypertext and Hypermedia. pp. 57–66. Archived from the original (PDF) on 2015-09-23. Retrieved 2015-04-17.
- Ivan Herman (2007). State of the Semantic Web (PDF). Semantic Days 2007. Retrieved July 26, 2007.
- Doctorow, Cory. "Metacrap: Putting the torch to seven straw-men of the meta-utopia". www.well.com/. Retrieved 11 September 2023.
- Gärdenfors, Peter (2004). How to make the Semantic Web more semantic. pp. 17–34.
{{cite book}}:|work=ignored (help) - Honkela, Timo; Könönen, Ville; Lindh-Knuutila, Tiina; Paukkeri, Mari-Sanna (2008). "Simulating processes of concept formation and communication". Journal of Economic Methodology. 15 (3): 245–259. doi:10.1080/13501780802321350. S2CID 16994027.
- "Policy Aware Web Project". Policyawareweb.org. Retrieved 2013-06-14.
- Corby, Olivier; Dieng-Kuntz, Rose; Zucker, Catherine Faron; Gandon, Fabien (2006). "Searching the Semantic Web: Approximate Query Processing based on Ontologies". IEEE Intelligent Systems. 21: 20–27. doi:10.1109/MIS.2006.16. S2CID 11488848.
- Gandon, Fabien (7 November 2002). Distributed Artificial Intelligence And Knowledge Management: Ontologies And Multi-Agent Systems For A Corporate Semantic Web (phdthesis). Université Nice Sophia Antipolis.
- Buffa, Michel; Dehors, Sylvain; Faron-Zucker, Catherine; Sander, Peter (2005). "Towards a Corporate Semantic Web Approach in Designing Learning Systems: Review of the Trial Solutioins Project" (PDF). International Workshop on Applications of Semantic Web Technologies for E-Learning. Amsterdam, Holland. pp. 73–76.
- "Corporate Semantic Web - Home". Corporate-semantic-web.de. Retrieved 14 April 2018.
- Hinze, Annika; Heese, Ralf; Luczak-Rösch, Markus; Paschke, Adrian (2012). "Semantic Enrichment by Non-Experts: Usability of Manual Annotation Tools" (PDF). ISWC'12 - Proceedings of the 11th international conference on The Semantic Web. Boston, USA. pp. 165–181.
- Mathieson, S. A. (6 April 2006). "Spread the word, and join it up". The Guardian. Retrieved 14 April 2018.
- Spivack, Nova (18 September 2007). "The Semantic Web, Collective Intelligence and Hyperdata". novaspivack.typepad.com/nova_spivacks_weblog [This Blog has Moved to NovaSpivack.com]. Retrieved 14 April 2018.
Further reading
- Liyang Yu (December 14, 2014). A Developer's Guide to the Semantic Web,2nd ed. Springer. ISBN 978-3-662-43796-4.
- Aaron Swartz's A Programmable Web: An unfinished Work donated by Morgan & Claypool Publishers after Aaron Swartz's death in January 2013.
- Grigoris Antoniou, Frank van Harmelen (March 31, 2008). A Semantic Web Primer, 2nd Edition. The MIT Press. ISBN 978-0-262-01242-3.
- Allemang, Dean; Hendler, James; Gandon, Fabien (August 3, 2020). Semantic Web for the Working Ontologist : Effective Modeling for Linked Data, RDFS, and OWL (Third ed.). [New York, NY, USA]: ACM Books; 3rd edition. ISBN 978-1450376143.
- Pascal Hitzler; Markus Krötzsch; Sebastian Rudolph (August 25, 2009). Foundations of Semantic Web Technologies. CRCPress. ISBN 978-1-4200-9050-5.
- Thomas B. Passin (March 1, 2004). Explorer's Guide to the Semantic Web. Manning Publications. ISBN 978-1-932394-20-7.
- Jeffrey T. Pollock (March 23, 2009). Semantic Web For Dummies. For Dummies. ISBN 978-0-470-39679-7.
- Hitzler, Pascal (February 2021). "A Review of the Semantic Web Field". Communications of the ACM. 64 (2): 76–83. doi:10.1145/3397512.
- Unni, Deepak (March 2023). "FAIRification of health-related data using semantic web technologies in the Swiss Personalized Health Network". Nature Scientific Data. 10 (1): 127. Bibcode:2023NatSD..10..127T. doi:10.1038/s41597-023-02028-y. PMC 10006404. PMID 36899064.