Structure tensor
In mathematics, the structure tensor, also referred to as the second-moment matrix, is a matrix derived from the gradient of a function. It describes the distribution of the gradient in a specified neighborhood around a point and makes the information invariant respect the observing coordinates. The structure tensor is often used in image processing and computer vision.[1][2][3]
| Feature detection |
|---|
| Edge detection |
| Corner detection |
| Blob detection |
| Ridge detection |
| Hough transform |
| Structure tensor |
| Affine invariant feature detection |
| Feature description |
| Scale space |
The 2D structure tensor
Continuous version
For a function of two variables p = (x, y), the structure tensor is the 2×2 matrix

![{\displaystyle S_{w}(p)={\begin{bmatrix}\int w(r)(I_{x}(p-r))^{2}\,dr&\int w(r)I_{x}(p-r)I_{y}(p-r)\,dr\\[10pt]\int w(r)I_{x}(p-r)I_{y}(p-r)\,dr&\int w(r)(I_{y}(p-r))^{2}\,dr\end{bmatrix}}}](../I/4af7c33b21c4fba6e47efc8a61f629c31ffe217e.svg)
where and are the partial derivatives of with respect to x and y; the integrals range over the plane ; and w is some fixed "window function" (such as a Gaussian blur), a distribution on two variables. Note that the matrix is itself a function of p = (x, y).




The formula above can be written also as , where is the matrix-valued function defined by


![{\displaystyle S_{0}(p)={\begin{bmatrix}(I_{x}(p))^{2}&I_{x}(p)I_{y}(p)\\[10pt]I_{x}(p)I_{y}(p)&(I_{y}(p))^{2}\end{bmatrix}}}](../I/387eb7dbc94385850a34c57d6e0d498a9cfef95e.svg)
If the gradient of is viewed as a 2×1 (single-column) matrix, where denotes transpose operation, turning a row vector to a column vector, the matrix can be written as the matrix product or tensor or outer product . Note however that the structure tensor cannot be factored in this way in general except if is a Dirac delta function.






Discrete version
In image processing and other similar applications, the function is usually given as a discrete array of samples , where p is a pair of integer indices. The 2D structure tensor at a given pixel is usually taken to be the discrete sum
![I[p]](../I/478f11e7e26684f020400ab24f8b8fe5dfc874e7.svg)
![{\displaystyle S_{w}[p]={\begin{bmatrix}\sum _{r}w[r](I_{x}[p-r])^{2}&\sum _{r}w[r]I_{x}[p-r]I_{y}[p-r]\\[10pt]\sum _{r}w[r]I_{x}[p-r]I_{y}[p-r]&\sum _{r}w[r](I_{y}[p-r])^{2}\end{bmatrix}}}](../I/8dd130d3875ee06346d9a3202883a3e023ac015d.svg)
Here the summation index r ranges over a finite set of index pairs (the "window", typically for some m), and w[r] is a fixed "window weight" that depends on r, such that the sum of all weights is 1. The values are the partial derivatives sampled at pixel p; which, for instance, may be estimated from by by finite difference formulas.

![I_x[p],I_y[p]](../I/b7266c1487ef676312aaec7272197be698f960ea.svg)
The formula of the structure tensor can be written also as , where is the matrix-valued array such that
![{\textstyle S_{w}[p]=\sum _{r}w[r]S_{0}[p-r]}](../I/539fde77c097863fe44b1e85d11d24f654bdf576.svg)
![{\displaystyle S_{0}[p]={\begin{bmatrix}(I_{x}[p])^{2}&I_{x}[p]I_{y}[p]\\[10pt]I_{x}[p]I_{y}[p]&(I_{y}[p])^{2}\end{bmatrix}}}](../I/03dcd0147370f6bfc04b7cfdedb95bbc1aebdab6.svg)
Interpretation
The importance of the 2D structure tensor stems from the fact eigenvalues (which can be ordered so that ) and the corresponding eigenvectors summarize the distribution of the gradient of within the window defined by centered at .[1][2][3]





Namely, if , then (or ) is the direction that is maximally aligned with the gradient within the window.



In particular, if then the gradient is always a multiple of (positive, negative or zero); this is the case if and only if within the window varies along the direction but is constant along . This condition of eigenvalues is also called linear symmetry condition because then the iso-curves of consist in parallel lines, i.e there exists a one dimensional function which can generate the two dimensional function as for some constant vector and the coordinates .






If , on the other hand, the gradient in the window has no predominant direction; which happens, for instance, when the image has rotational symmetry within that window. This condition of eigenvalues is also called balanced body, or directional equilibrium condition because it holds when all gradient directions in the window are equally frequent/probable.

Furthermore, the condition happens if and only if the function is constant () within .



More generally, the value of , for k=1 or k=2, is the -weighted average, in the neighborhood of p, of the square of the directional derivative of along . The relative discrepancy between the two eigenvalues of is an indicator of the degree of anisotropy of the gradient in the window, namely how strongly is it biased towards a particular direction (and its opposite).[4][5] This attribute can be quantified by the coherence, defined as



if . This quantity is 1 when the gradient is totally aligned, and 0 when it has no preferred direction. The formula is undefined, even in the limit, when the image is constant in the window (). Some authors define it as 0 in that case.

Note that the average of the gradient inside the window is not a good indicator of anisotropy. Aligned but oppositely oriented gradient vectors would cancel out in this average, whereas in the structure tensor they are properly added together.[6] This is a reason for why is used in the averaging of the structure tensor to optimize the direction instead of .

By expanding the effective radius of the window function (that is, increasing its variance), one can make the structure tensor more robust in the face of noise, at the cost of diminished spatial resolution.[5][7] The formal basis for this property is described in more detail below, where it is shown that a multi-scale formulation of the structure tensor, referred to as the multi-scale structure tensor, constitutes a true multi-scale representation of directional data under variations of the spatial extent of the window function.
Complex version
The interpretation and implementation of the 2D structure tensor becomes particularly accessible using complex numbers.[2] The structure tensor consists in 3 real numbers
![{\displaystyle S_{w}(p)={\begin{bmatrix}\mu _{20}&\mu _{11}\\[10pt]\mu _{11}&\mu _{02}\end{bmatrix}}}](../I/dd464eb73b6be5b48ac165e822910f694f24e103.svg)
where , and in which integrals can be replaced by summations for discrete representation. Using Parseval's identity it is clear that the three real numbers are the second order moments of the power spectrum of . The following second order complex moment of the power spectrum of can then be written as




where and is the direction angle of the most significant eigenvector of the structure tensor whereas and are the most and the least significant eigenvalues. From, this it follows that contains both a certainty and the optimal direction in double angle representation since it is a complex number consisting of two real numbers. It follows also that if the gradient is represented as a complex number, and is remapped by squaring (i.e. the argument angles of the complex gradient is doubled), then averaging acts as an optimizer in the mapped domain, since it directly delivers both the optimal direction (in double angle representation) and the associated certainty. The complex number represents thus how much linear structure (linear symmetry) there is in image , and the complex number is obtained directly by averaging the gradient in its (complex) double angle representation without computing the eigenvalues and the eigenvectors explicitly.







Likewise the following second order complex moment of the power spectrum of , which happens to be always real because is real,

can be obtained, with and being the eigenvalues as before. Notice that this time the magnitude of the complex gradient is squared (which is always real).
However, decomposing the structure tensor in its eigenvectors yields its tensor components as

where is the identity matrix in 2D because the two eigenvectors are always orthogonal (and sum to unity). The first term in the last expression of the decomposition, , represents the linear symmetry component of the structure tensor containing all directional information (as a rank-1 matrix), whereas the second term represents the balanced body component of the tensor, which lacks any directional information (containing an identity matrix ). To know how much directional information there is in is then the same as checking how large is compared to .



Evidently, is the complex equivalent of the first term in the tensor decomposition, whereas

is the equivalent of the second term. Thus the two scalars, comprising three real numbers,

where is the (complex) gradient filter, and is convolution, constitute a complex representation of the 2D Structure Tensor. As discussed here and elsewhere defines the local image which is usually a Gaussian (with a certain variance defining the outer scale), and is the (inner scale) parameter determining the effective frequency range in which the orientation is to be estimated.




The elegance of the complex representation stems from that the two components of the structure tensor can be obtained as averages and independently. In turn, this means that and can be used in a scale space representation to describe the evidence for presence of unique orientation and the evidence for the alternative hypothesis, the presence of multiple balanced orientations, without computing the eigenvectors and eigenvalues. A functional, such as squaring the complex numbers have to this date not been shown to exist for structure tensors with dimensions higher than two. In Bigun 91, it has been put forward with due argument that this is because complex numbers are commutative algebras whereas quaternions, the possible candidate to construct such a functional by, constitute a non-commutative algebra.[8]

The complex representation of the structure tensor is frequently used in fingerprint analysis to obtain direction maps containing certainties which in turn are used to enhance them, to find the locations of the global (cores and deltas) and local (minutia) singularities, as well as automatically evaluate the quality of the fingerprints.
The 3D structure tensor
Definition
The structure tensor can be defined also for a function of three variables p=(x,y,z) in an entirely analogous way. Namely, in the continuous version we have , where
![{\displaystyle S_{0}(p)={\begin{bmatrix}(I_{x}(p))^{2}&I_{x}(p)I_{y}(p)&I_{x}(p)I_{z}(p)\\[10pt]I_{x}(p)I_{y}(p)&(I_{y}(p))^{2}&I_{y}(p)I_{z}(p)\\[10pt]I_{x}(p)I_{z}(p)&I_{y}(p)I_{z}(p)&(I_{z}(p))^{2}\end{bmatrix}}}](../I/d63e3ea8444fb74c450d58b861e4b6ce4cf67edc.svg)
where are the three partial derivatives of , and the integral ranges over .


In the discrete version,, where
![{\displaystyle S_{0}[p]={\begin{bmatrix}(I_{x}[p])^{2}&I_{x}[p]I_{y}[p]&I_{x}[p]I_{z}[p]\\[10pt]I_{x}[p]I_{y}[p]&(I_{y}[p])^{2}&I_{y}[p]I_{z}[p]\\[10pt]I_{x}[p]I_{z}[p]&I_{y}[p]I_{z}[p]&(I_{z}[p])^{2}\end{bmatrix}}}](../I/676e2043d06d76fc2f470e41f4d372ad8d89ac99.svg)
and the sum ranges over a finite set of 3D indices, usually for some m.

Interpretation
As in the two-dimensional case, the eigenvalues of , and the corresponding eigenvectors , summarize the distribution of gradient directions within the neighborhood of p defined by the window . This information can be visualized as an ellipsoid whose semi-axes are equal to the eigenvalues and directed along their corresponding eigenvectors.[9][10]

![S_{w}[p]](../I/def9457fa249ca80b6ae40c6ade8972b530970b7.svg)

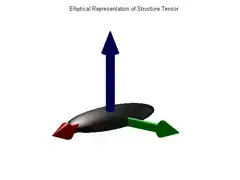
In particular, if the ellipsoid is stretched along one axis only, like a cigar (that is, if is much larger than both and ), it means that the gradient in the window is predominantly aligned with the direction , so that the isosurfaces of tend to be flat and perpendicular to that vector. This situation occurs, for instance, when p lies on a thin plate-like feature, or on the smooth boundary between two regions with contrasting values.

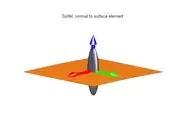 The structure tensor ellipsoid of a surface-like neighborhood ("surfel"), where . |  A 3D window straddling a smooth boundary surface between two uniform regions of a 3D image. |  The corresponding structure tensor ellipsoid. |

If the ellipsoid is flattened in one direction only, like a pancake (that is, if is much smaller than both and ), it means that the gradient directions are spread out but perpendicular to ; so that the isosurfaces tend to be like tubes parallel to that vector. This situation occurs, for instance, when p lies on a thin line-like feature, or on a sharp corner of the boundary between two regions with contrasting values.

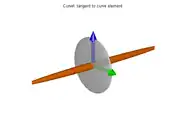 The structure tensor of a line-like neighborhood ("curvel"), where . |  A 3D window straddling a line-like feature of a 3D image. | 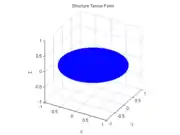 The corresponding structure tensor ellipsoid. |

Finally, if the ellipsoid is roughly spherical (that is, if ), it means that the gradient directions in the window are more or less evenly distributed, with no marked preference; so that the function is mostly isotropic in that neighborhood. This happens, for instance, when the function has spherical symmetry in the neighborhood of p. In particular, if the ellipsoid degenerates to a point (that is, if the three eigenvalues are zero), it means that is constant (has zero gradient) within the window.

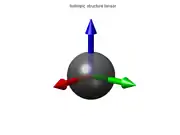 The structure tensor in an isotropic neighborhood, where . |  A 3D window containing a spherical feature of a 3D image. | 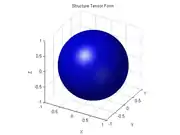 The corresponding structure tensor ellipsoid. |
The multi-scale structure tensor
The structure tensor is an important tool in scale space analysis. The multi-scale structure tensor (or multi-scale second moment matrix) of a function is in contrast to other one-parameter scale-space features an image descriptor that is defined over two scale parameters. One scale parameter, referred to as local scale , is needed for determining the amount of pre-smoothing when computing the image gradient . Another scale parameter, referred to as integration scale , is needed for specifying the spatial extent of the window function that determines the weights for the region in space over which the components of the outer product of the gradient by itself are accumulated.




More precisely, suppose that is a real-valued signal defined over . For any local scale , let a multi-scale representation of this signal be given by where represents a pre-smoothing kernel. Furthermore, let denote the gradient of the scale space representation. Then, the multi-scale structure tensor/second-moment matrix is defined by[7][11][12]






Conceptually, one may ask if it would be sufficient to use any self-similar families of smoothing functions and . If one naively would apply, for example, a box filter, however, then non-desirable artifacts could easily occur. If one wants the multi-scale structure tensor to be well-behaved over both increasing local scales and increasing integration scales , then it can be shown that both the smoothing function and the window function have to be Gaussian.[7] The conditions that specify this uniqueness are similar to the scale-space axioms that are used for deriving the uniqueness of the Gaussian kernel for a regular Gaussian scale space of image intensities.
There are different ways of handling the two-parameter scale variations in this family of image descriptors. If we keep the local scale parameter fixed and apply increasingly broadened versions of the window function by increasing the integration scale parameter only, then we obtain a true formal scale space representation of the directional data computed at the given local scale .[7] If we couple the local scale and integration scale by a relative integration scale , such that then for any fixed value of , we obtain a reduced self-similar one-parameter variation, which is frequently used to simplify computational algorithms, for example in corner detection, interest point detection, texture analysis and image matching. By varying the relative integration scale in such a self-similar scale variation, we obtain another alternative way of parameterizing the multi-scale nature of directional data obtained by increasing the integration scale.



A conceptually similar construction can be performed for discrete signals, with the convolution integral replaced by a convolution sum and with the continuous Gaussian kernel replaced by the discrete Gaussian kernel :



When quantizing the scale parameters and in an actual implementation, a finite geometric progression is usually used, with i ranging from 0 to some maximum scale index m. Thus, the discrete scale levels will bear certain similarities to image pyramid, although spatial subsampling may not necessarily be used in order to preserve more accurate data for subsequent processing stages.

Applications
The eigenvalues of the structure tensor play a significant role in many image processing algorithms, for problems like corner detection, interest point detection, and feature tracking.[9][13][14][15][16][17][18] The structure tensor also plays a central role in the Lucas-Kanade optical flow algorithm, and in its extensions to estimate affine shape adaptation;[11] where the magnitude of is an indicator of the reliability of the computed result. The tensor has been used for scale space analysis,[7] estimation of local surface orientation from monocular or binocular cues,[12] non-linear fingerprint enhancement,[19] diffusion-based image processing,[20][21][22][23] and several other image processing problems. The structure tensor can be also applied in geology to filter seismic data.[24]
Processing spatio-temporal video data with the structure tensor
The three-dimensional structure tensor has been used to analyze three-dimensional video data (viewed as a function of x, y, and time t).[4] If one in this context aims at image descriptors that are invariant under Galilean transformations, to make it possible to compare image measurements that have been obtained under variations of a priori unknown image velocities


it is, however, from a computational viewpoint preferable to parameterize the components in the structure tensor/second-moment matrix using the notion of Galilean diagonalization[25]


where denotes a Galilean transformation of spacetime and a two-dimensional rotation over the spatial domain, compared to the abovementioned use of eigenvalues of a 3-D structure tensor, which corresponds to an eigenvalue decomposition and a (non-physical) three-dimensional rotation of spacetime



To obtain true Galilean invariance, however, also the shape of the spatio-temporal window function needs to be adapted,[25][26] corresponding to the transfer of affine shape adaptation[11] from spatial to spatio-temporal image data. In combination with local spatio-temporal histogram descriptors,[27] these concepts together allow for Galilean invariant recognition of spatio-temporal events.[28]
See also
References
- J. Bigun and G. Granlund (1986), Optimal Orientation Detection of Linear Symmetry. Tech. Report LiTH-ISY-I-0828, Computer Vision Laboratory, Linkoping University, Sweden 1986; Thesis Report, Linkoping studies in science and technology No. 85, 1986.
- J. Bigun & G. Granlund (1987). "Optimal Orientation Detection of Linear Symmetry". First int. Conf. on Computer Vision, ICCV, (London). Piscataway: IEEE Computer Society Press, Piscataway. pp. 433–438.
- H. Knutsson (1989). "Representing local structure using tensors". Proceedings 6th Scandinavian Conf. on Image Analysis. Oulu: Oulu University. pp. 244–251.
- B. Jahne (1993). Spatio-Temporal Image Processing: Theory and Scientific Applications. Vol. 751. Berlin: Springer-Verlag.
- G. Medioni, M. Lee & C. Tang (March 2000). A Computational Framework for Feature Extraction and Segmentation. Elsevier Science.
- T. Brox; J. Weickert; B. Burgeth & P. Mrazek (2004). Nonlinear Structure Tensors (Technical report). Universität des Saarlandes. 113.
- T. Lindeberg (1993), Scale-Space Theory in Computer Vision. Kluwer Academic Publishers, (see sections 14.4.1 and 14.2.3 on pages 359–360 and 355–356 for detailed statements about how the multi-scale second-moment matrix/structure tensor defines a true and uniquely determined multi-scale representation of directional data).
- J. Bigun; G. Granlund & J. Wiklund (1991). "Multidimensional Orientation Estimation with Applications to Texture Analysis and Optical Flow". IEEE Transactions on Pattern Analysis and Machine Intelligence. 13 (8): 775–790. doi:10.1109/34.85668.
- M. Nicolescu & G. Medioni (2003). "Motion Segmentation with Accurate Boundaries – A Tensor Voting Approach". Proc. IEEE Computer Vision and Pattern Recognition. Vol. 1. pp. 382–389.
- Westin, C.-F.; Maier, S.E.; Mamata, H.; Nabavi, A.; Jolesz, F.A.; Kikinis, R. (June 2002). "Processing and visualization for diffusion tensor MRI". Medical Image Analysis. 6 (2): 93–108. doi:10.1016/S1361-8415(02)00053-1. PMID 12044998.
- T. Lindeberg & J. Garding (1997). "Shape-adapted smoothing in estimation of 3-D depth cues from affine distortions of local 2-D structure". Image and Vision Computing. 15 (6): 415–434. doi:10.1016/S0262-8856(97)01144-X.
- J. Garding and T. Lindeberg (1996). "Direct computation of shape cues using scale-adapted spatial derivative operators, International Journal of Computer Vision, volume 17, issue 2, pages 163–191.
- W. Förstner (1986). "A Feature Based Correspondence Algorithm for Image Processing". International Archives of Photogrammetry and Remote Sensing. 26: 150–166.
- C. Harris & M. Stephens (1988). "A Combined Corner and Edge Detector". Proc. of the 4th ALVEY Vision Conference. pp. 147–151.
- K. Rohr (1997). "On 3D Differential Operators for Detecting Point Landmarks". Image and Vision Computing. 15 (3): 219–233. doi:10.1016/S0262-8856(96)01127-4.
- I. Laptev & T. Lindeberg (2003). "Space–time interest points". International Conference on Computer Vision ICCV'03. Vol. I. pp. 432–439. doi:10.1109/ICCV.2003.1238378.
- B. Triggs (2004). "Detecting Keypoints with Stable Position, Orientation, and Scale under Illumination Changes". Proc. European Conference on Computer Vision. Vol. 4. pp. 100–113.
- C. Kenney, M. Zuliani & B. Manjunath (2005). "An Axiomatic Approach to Corner Detection". Proc. IEEE Computer Vision and Pattern Recognition. pp. 191–197.
- A. Almansa and T. Lindeberg (2000), Enhancement of fingerprint images using shape-adaptated scale-space operators. IEEE Transactions on Image Processing, volume 9, number 12, pages 2027–2042.
- J. Weickert (1998), Anisotropic diffusion in image processing, Teuber Verlag, Stuttgart.
- D. Tschumperle & R. Deriche (September 2002). "Diffusion PDEs on Vector-Valued Images". IEEE Signal Processing Magazine. 19 (5): 16–25. Bibcode:2002ISPM...19...16T. doi:10.1109/MSP.2002.1028349.
- S. Arseneau & J. Cooperstock (September 2006). "An Asymmetrical Diffusion Framework for Junction Analysis". British Machine Vision Conference. Vol. 2. pp. 689–698.
- S. Arseneau & J. Cooperstock (November 2006). "An Improved Representation of Junctions through Asymmetric Tensor Diffusion". International Symposium on Visual Computing.
- Yang, Shuai; Chen, Anqing; Chen, Hongde (2017-05-25). "Seismic data filtering using non-local means algorithm based on structure tensor". Open Geosciences. 9 (1): 151–160. Bibcode:2017OGeo....9...13Y. doi:10.1515/geo-2017-0013. ISSN 2391-5447. S2CID 134392619.
- T. Lindeberg; A. Akbarzadeh & I. Laptev (August 2004). "Galilean-corrected spatio-temporal interest operators". International Conference on Pattern Recognition ICPR'04. Vol. I. pp. 57–62. doi:10.1109/ICPR.2004.1334004.
- I. Laptev & T. Lindeberg (August 2004). Velocity adaptation of space–time interest points. International Conference on Pattern Recognition ICPR'04. Vol. I. pp. 52–56. doi:10.1109/ICPR.2004.971.
- I. Laptev & T. Lindeberg (May 2004). Local descriptors for spatio-temporal recognition. ECCV'04 Workshop on Spatial Coherence for Visual Motion Analysis (Prague, Czech Republic) Springer Lecture Notes in Computer Science. Vol. 3667. pp. 91–103. doi:10.1007/11676959.
- I. Laptev; B. Caputo; C. Schuldt & T. Lindeberg (2007). "Local velocity-adapted motion events for spatio-temporal recognition". Computer Vision and Image Understanding. Vol. 108. pp. 207–229. doi:10.1016/j.cviu.2006.11.023.