Markup language
A markup language is a text-encoding system consisting of a set of symbols inserted in a text document to control its structure, formatting, or the relationship between its parts.[1] Markup is often used to control the display of the document or to enrich its content to facilitate automated processing.
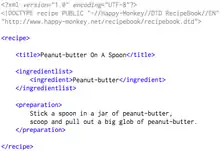
A markup language is a set of rules governing what markup information may be included in a document and how it is combined with the content of the document in a way to facilitate use by humans and computer programs. The idea and terminology evolved from the "marking up" of paper manuscripts (i.e., the revision instructions by editors), which is traditionally written with a red pen or blue pencil on authors' manuscripts.[2]
Older markup languages, which typically focus on typography and presentation, include Troff, TeX, and LaTeX. Scribe and most modern markup languages, such as XML, identify document components (for example headings, paragraphs, and tables), with the expectation that technology, such as stylesheets, will be used to apply formatting or other processing.
Some markup languages, such as the widely used HTML, have pre-defined presentation semantics, meaning that their specifications prescribe some aspects of how to present the structured data on particular media. HTML, like DocBook, Open eBook, JATS, and many others, is based on the markup meta-languages SGML and XML. That is, SGML and XML allow designers to specify particular schemas, which determine which elements, attributes, and other features are permitted, and where.
One extremely important characteristic of most markup languages is that they allow intermingling markup with document content such as text and pictures. For example, if a few words in a sentence need to be emphasized, or identified as a proper name, defined term, or another special item, the markup may be inserted between the characters of the sentence. This is quite different structurally from traditional databases, where it is by definition impossible to have data that is within a record but not within any field. Furthermore, markup for human-readable texts must maintain order: it would not suffice to make each paragraph of a book into a "paragraph" record, where those records do not maintain order.
Etymology
The noun markup is derived from the traditional publishing practice called "marking up" a manuscript,[3] which involves adding handwritten annotations in the form of conventional symbolic printer's instructions — in the margins and the text of a paper or a printed manuscript.
For centuries, this task was done primarily by skilled typographers known as "markup men"[4] or "d markers"[5] who marked up text to indicate what typeface, style, and size should be applied to each part, and then passed the manuscript to others for typesetting by hand or machine.
The markup was also commonly applied by editors, proofreaders, publishers, and graphic designers, and indeed by document authors, all of whom might also mark other things, such as corrections, changes, etc.
Types of markup language
There are three main general categories of electronic markup, articulated in Coombs, Renear, and DeRose (1987),[6] and Bray (2003).[7]
Presentational markup
- The kind of markup used by traditional word-processing systems: binary codes embedded within document text that produce the WYSIWYG ("what you see is what you get") effect. Such markup is usually hidden from human users, even authors and editors. Properly speaking, such systems use procedural and/or descriptive markup underneath but convert it to "present" to the user as geometric arrangements of type.
Procedural markup
- Markup is embedded in text which provides instructions for programs to process the text. Well-known examples include troff, TeX, and Markdown. It is assumed that software processes the text sequentially from beginning to end, following the instructions as encountered. Such text is often edited with the markup visible and directly manipulated by the author. Popular procedural markup systems usually include programming constructs, especially macros, allowing complex sets of instructions to be invoked by a simple name (and perhaps a few parameters). This is much faster, less error-prone, and more maintenance-friendly than re-stating the same or similar instructions in many places.
Descriptive markup
- Markup is specifically used to label parts of the document for what they are, rather than how they should be processed. Well-known systems that provide many such labels include LaTeX, HTML, and XML. The objective is to decouple the structure of the document from any particular treatment or rendition of it. Such markup is often described as "semantic". An example of a descriptive markup would be HTML's
<cite>tag, which is used to label a citation. Descriptive markup — sometimes called logical markup or conceptual markup — encourages authors to write in a way that describes the material conceptually, rather than visually.[8]
There is a considerable blurring of the lines between the types of markup. In modern word-processing systems, presentational markup is often saved in descriptive-markup-oriented systems such as XML, and then processed procedurally by implementations. The programming in procedural-markup systems, such as TeX, may be used to create higher-level markup systems that are more descriptive in nature, such as LaTeX.
In recent years, several markup languages have been developed with ease of use as a key goal, and without input from standards organizations, aimed at allowing authors to create formatted text via web browsers, for example in wikis and in web forums. These are sometimes called lightweight markup languages. Markdown, BBCode, and the markup language used by Wikipedia are examples of such languages.
History of markup languages
GenCode
The first well-known public presentation of markup languages in computer text processing was made by William W. Tunnicliffe at a conference in 1967, although he preferred to call it generic coding. It can be seen as a response to the emergence of programs such as RUNOFF that each used their own control notations, often specific to the target typesetting device. In the 1970s, Tunnicliffe led the development of a standard called GenCode for the publishing industry and later was the first chairman of the International Organization for Standardization committee that created SGML, the first standard descriptive markup language. Book designer Stanley Rice published speculation along similar lines in 1970.[9]
Brian Reid, in his 1980 dissertation at Carnegie Mellon University, developed the theory and a working implementation of descriptive markup in actual use. However, IBM researcher Charles Goldfarb is more commonly seen today as the "father" of markup languages. Goldfarb hit upon the basic idea while working on a primitive document management system intended for law firms in 1969, and helped invent IBM GML later that same year. GML was first publicly disclosed in 1973.
In 1975, Goldfarb moved from Cambridge, Massachusetts to Silicon Valley and became a product planner at the IBM Almaden Research Center. There, he convinced IBM's executives to deploy GML commercially in 1978 as part of IBM's Document Composition Facility product, and it was widely used in business within a few years.
SGML, which was based on both GML and GenCode, was an ISO project worked on by Goldfarb beginning in 1974.[10] Goldfarb eventually became chair of the SGML committee. SGML was first released by ISO as the ISO 8879 standard in October 1986.
troff and nroff
Some early examples of computer markup languages available outside the publishing industry can be found in typesetting tools on Unix systems such as troff and nroff. In these systems, formatting commands were inserted into the document text so that typesetting software could format the text according to the editor's specifications. It was a trial and error iterative process to get a document printed correctly.[11] Availability of WYSIWYG ("what you see is what you get") publishing software supplanted much use of these languages among casual users, though serious publishing work still uses markup to specify the non-visual structure of texts, and WYSIWYG editors now usually save documents in a markup-language-based format.
TeX
Another major publishing standard is TeX, created and refined by Donald Knuth in the 1970s and '80s. TeX concentrated on the detailed layout of text and font descriptions to typeset mathematical books. This required Knuth to spend considerable time investigating the art of typesetting. TeX is mainly used in academia, where it is a de facto standard in many scientific disciplines. A TeX macro package known as LaTeX provides a descriptive markup system on top of TeX, and is widely used both among the scientific community and the publishing industry.
Scribe, GML, and SGML
The first language to make a clean distinction between structure and presentation was Scribe, developed by Brian Reid and described in his doctoral thesis in 1980.[12] Scribe was revolutionary in a number of ways, introducing the idea of styles separated from the marked-up document, and a grammar that controlled the usage of descriptive elements. Scribe influenced the development of Generalized Markup Language (later SGML),[13] and is a direct ancestor to HTML and LaTeX.[14]
In the early 1980s, the idea that markup should focus on the structural aspects of a document and leave the visual presentation of that structure to the interpreter led to the creation of SGML. The language was developed by a committee chaired by Goldfarb. It incorporated ideas from many different sources, including Tunnicliffe's project, GenCode. Sharon Adler, Anders Berglund, and James A. Marke were also key members of the SGML committee.
SGML specified a syntax for including the markup in documents, as well as one for separately describing what tags were allowed, and where (the Document Type Definition (DTD), later known as a schema). This allowed authors to create and use any markup they wished, selecting tags that made the most sense to them and were named in their own natural languages, while also allowing automated verification. Thus, SGML is properly a meta-language, and many particular markup languages are derived from it. From the late '80s onward, most substantial new markup languages have been based on the SGML system, including for example TEI and DocBook. SGML was promulgated as an International Standard by International Organization for Standardization, ISO 8879, in 1986.[15]
SGML found wide acceptance and use in fields with very large-scale documentation requirements. However, many found it cumbersome and difficult to learn — a side effect of its design attempting to do too much and being too flexible. For example, SGML made end tags (or start-tags, or even both) optional in certain contexts, because its developers thought markup would be done manually by overworked support staff who would appreciate saving keystrokes.
HTML
In 1989, computer scientist Sir Tim Berners-Lee wrote a memo proposing an Internet-based hypertext system,[16] then specified HTML and wrote the browser and server software in the last part of 1990. The first publicly available description of HTML was a document called "HTML Tags", first mentioned on the Internet by Berners-Lee in late 1991.[17][18] It describes 18 elements comprising the initial, relatively simple design of HTML. Except for the hyperlink tag, these were strongly influenced by SGMLguid, an in-house SGML-based documentation format at CERN, and very similar to the sample schema in the SGML standard. Eleven of these elements still exist in HTML 4.[19]
Berners-Lee considered HTML an SGML application. The Internet Engineering Task Force (IETF) formally defined it as such with the mid-1993 publication of the first proposal for an HTML specification: "Hypertext Markup Language (HTML)" Internet-Draft by Berners-Lee and Dan Connolly, which included an SGML Document Type Definition to define the grammar.[20] Many of the HTML text elements are found in the 1988 ISO technical report TR 9537 Techniques for using SGML, which in turn covers the features of early text formatting languages such as that used by the RUNOFF command developed in the early 1960s for the CTSS (Compatible Time-Sharing System) operating system. These formatting commands were derived from those used by typesetters to manually format documents. Steven DeRose[21] argues that HTML's use of descriptive markup (and the influence of SGML in particular) was a major factor in the success of the Web, because of the flexibility and extensibility that it enabled. HTML became the main markup language for creating web pages and other information that can be displayed in a web browser and is quite likely the most used markup language in the world today.
XML
XML (Extensible Markup Language) is a meta markup language that is very widely used. XML was developed by the World Wide Web Consortium, in a committee created and chaired by Jon Bosak. The main purpose of XML was to simplify SGML by focusing on a particular problem — documents on the Internet.[22] XML remains a meta-language like SGML, allowing users to create any tags needed (hence "extensible") and then describing those tags and their permitted uses.
XML adoption was helped because every XML document can be written in such a way that it is also an SGML document, and existing SGML users and software could switch to XML fairly easily. However, XML eliminated many of the more complex features of SGML to simplify implementation environments such as documents and publications. It appeared to strike a happy medium between simplicity and flexibility, as well as supporting very robust schema definition and validation tools, and was rapidly adopted for many other uses. XML is now widely used for communicating data between applications, for serializing program data, for hardware communications protocols, vector graphics, and many other uses as well as documents.
XHTML
From January 2000 until HTML 5 was released, all W3C Recommendations for HTML have been based on XML, using the abbreviation XHTML (Extensible HyperText Markup Language). The language specification requires that XHTML Web documents be well-formed XML documents. This allows for more rigorous and robust documents, by avoiding many syntax errors which historically led to incompatible browser behaviors, while still using document components that are familiar with HTML.
One of the most noticeable differences between HTML and XHTML is the rule that all tags must be closed: empty HTML tags such as <br> must either be closed with a regular end-tag, or replaced by a special form: <br /> (the space before the '/' on the end tag is optional, but frequently used because it enables some pre-XML Web browsers, and SGML parsers, to accept the tag). Another difference is that all attribute values in tags must be quoted. Both these differences are commonly criticized as verbose but also praised because they make it far easier to detect, localize, and repair errors. Finally, all tag and attribute names within the XHTML namespace must be lowercase to be valid. HTML, on the other hand, was case-insensitive.
Other XML-based applications
Many XML-based applications now exist, including the Resource Description Framework as RDF/XML, XForms, DocBook, SOAP, and the Web Ontology Language (OWL). For a partial list of these, see List of XML markup languages.
Features of markup languages
A common feature of many markup languages is that they intermix the text of a document with markup instructions in the same data stream or file. This is not necessary; it is possible to isolate markup from text content, using pointers, offsets, IDs, or other methods to coordinate the two. Such "standoff markup" is typical for the internal representations that programs use to work with marked-up documents. However, embedded or "inline" markup is much more common elsewhere. Here, for example, is a small section of text marked up in HTML:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>My test page</title>
</head>
<body>
<h1>Mozilla is cool</h1>
<img src="images/firefox-icon.png" alt="The Firefox logo: a flaming fox surrounding the Earth.">
<p>At Mozilla, we’re a global community of</p>
<ul> <!-- changed to list in the tutorial -->
<li>technologists</li>
<li>thinkers</li>
<li>builders</li>
</ul>
<p>working together to keep the Internet alive and accessible, so people worldwide can be informed contributors and creators of the Web. We believe this act of human collaboration across an open platform is essential to individual growth and our collective future.</p>
<p>Read the <a href="https://www.mozilla.org/en-US/about/manifesto/">Mozilla Manifesto</a> to learn even more about the values and principles that guide the pursuit of our mission.</p>
</body>
</html>
The codes enclosed in angle-brackets < like this> are markup instructions (known as tags), while the text between these instructions is the actual text of the document. The codes h1, p, and em are examples of semantic markup, in that they describe the intended purpose or the meaning of the text they include. Specifically, h1 means "this is a first-level heading", p means "this is a paragraph", and em means "this is an emphasized word or phrase". A program interpreting such structural markup may apply its own rules or styles for presenting the various pieces of text, using different typefaces, boldness, font size, indentation, color, or other styles, as desired.
For example, a tag such as "h1" (header level 1) might be presented in a large bold sans-serif typeface in an article, or it might be underscored in a monospaced (typewriter-style) document – or it might simply not change the presentation at all.
In contrast, the i tag in HTML 4 is an example of presentational markup, which is generally used to specify a particular characteristic of the text without specifying the reason for that appearance. In this case, the i element dictates the use of an italic typeface. However, in HTML 5, this element has been repurposed with a more semantic usage: to denote a span of text in an alternate voice or mood, or otherwise offset from the normal prose in a manner indicating a different quality of text
. For example, it is appropriate to use the i element to indicate a taxonomic designation or a phrase in another language.[23] The change was made to ease the transition from HTML 4 to HTML 5 as smoothly as possible so that deprecated uses of presentational elements would preserve the most likely intended semantics.
The Text Encoding Initiative (TEI) has published extensive guidelines[24] for how to encode texts of interest in the humanities and social sciences, developed through years of international cooperative work. These guidelines are used by projects encoding historical documents, the works of particular scholars, periods, genres, and so on.
Language
While the idea of markup language originated with text documents, there is increasing use of markup languages in the presentation of other types of information, including playlists, vector graphics, web services, content syndication, and user interfaces. Most of these are XML applications because XML is a well-defined and extensible language.
The use of XML has also led to the possibility of combining multiple markup languages into a single profile, like XHTML+SMIL and XHTML+MathML+SVG.[25]
See also
References
- "markup language | Definition, Examples, & Facts". Encyclopedia Britannica. Archived from the original on 2020-10-26. Retrieved 2022-08-17.
- Siechert, Carl; Bott, Ed (2013). Microsoft Office Inside Out: 2013 Edition. Pearson Education. p. 305. ISBN 978-0735669062.
Some reviewers prefer going old school by using a red pen on printed output
- CHEN, XinYing (2011). "Central nodes of the Chinese syntactic networks". Chinese Science Bulletin. 56 (10): 735–740. doi:10.1360/972010-2369. ISSN 0023-074X.
- Allan Woods, Modern Newspaper Production (New York: Harper & Row, 1963), 85; Stewart Harral, Profitable Public Relations for Newspapers (Ann Arbor: J.W. Edwards, 1957), 76; and Chiarella v. United States, 445 U.S. 222 (1980).
- From the Notebooks of H.J.H & D.H.An on Composition, Kingsport Press Inc., undated (the 1960s).
- Coombs, James H.; Renear, Allen H.; DeRose, Steven J. (November 1987). "Markup systems and the future of scholarly text processing". Communications of the ACM. 30 (11): 933–947. CiteSeerX 10.1.1.515.5618. doi:10.1145/32206.32209. S2CID 59941802. Archived from the original on 2019-05-12. Retrieved 2005-04-19.
- Bray, Tim (9 April 2003). "On Semantics and Markup, Taxonomy of Markup". www.tbray.org. Archived from the original on 2021-02-27. Retrieved 2021-08-16.
- Michael Downes."TEX and LATEX 2e" Archived 2021-05-24 at the Wayback Machine
- Rice, Stanley. “Editorial Text Structures (with some relations to information structures and format controls in computerized composition).” American National Standards Institute, March 17, 1970.
- "2009 interview with SGML creator Charles F. Goldfarb". Dr. Dobb's Journal. Retrieved 2010-07-18.
- Daniel Gilly. Unix in a nutshell: Chapter 12. Groff and Troff Archived 2016-01-05 at the Wayback Machine. O'Reilly Books, 1992. ISBN 1-56592-001-5
- Reid, Brian. "Scribe: A Document Specification Language and its Compiler." Ph.D. thesis, Carnegie-Mellon University, Pittsburgh PA. Also available as Technical Report CMU-CS-81-100.
- Reid, Brian. "20 Years of Abstract Markup - Any Progress?". xml.coverpages.org. Archived from the original on 2019-05-01. Retrieved 2021-08-16.
- HTML is a particular instance of SGML, whereas LaTeX is designed with the separation-between-content-and-design philosophy of Scribe in mind.
- "ISO 8879:1986". ISO. Archived from the original on 2021-08-17. Retrieved 2021-08-15.
- Tim Berners-Lee, "Information Management: A Proposal." CERN (March 1989, May 1990). W3.org Archived 2010-04-01 at the Wayback Machine
- "First mention of HTML Tags on the www-talk mailing list". World Wide Web Consortium. October 29, 1991. Archived from the original on August 8, 2021. Retrieved August 16, 2021.
- "Index of elements in HTML 4". World Wide Web Consortium. December 24, 1999. Archived from the original on 2007-05-05. Retrieved 2021-08-16.
- Tim Berners-Lee (December 9, 1991). "Re: SGML/HTML docs, X Browser (archived www-talk mailing list post)". Archived from the original on July 3, 2021. Retrieved August 16, 2021.
SGML is very general. HTML is a specific application of the SGML basic syntax applied to hypertext documents with a simple structure.
- DeRose, Steven J. "The SGML FAQ Book." Boston: Kluwer Academic Publishers, 1997. ISBN 0-7923-9943-9
- "Extensible Markup Language (XML)". W3.org. Archived from the original on 2021-08-11. Retrieved 2021-08-16.
- Hickson, Ian. "HTML Living Standard". WHATWG — HTML. Archived from the original on 8 March 2018. Retrieved 13 September 2020.
- "TEI Guidelines for Electronic Text Encoding and Interchange". Tei-c.org. Archived from the original on 2014-07-03. Retrieved 2021-08-16.
- An XHTML + MathML + SVG Profile Archived 2021-07-19 at the Wayback Machine. W3C. August 9, 2002. Retrieved 2021-08-16.