Binary heap
A binary heap is a heap data structure that takes the form of a binary tree. Binary heaps are a common way of implementing priority queues.[1]: 162–163 The binary heap was introduced by J. W. J. Williams in 1964, as a data structure for heapsort.[2]
| Binary (min) heap | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Type | binary tree/heap | ||||||||||||||||||
| Invented | 1964 | ||||||||||||||||||
| Invented by | J. W. J. Williams | ||||||||||||||||||
| Time complexity in big O notation | |||||||||||||||||||
| |||||||||||||||||||


A binary heap is defined as a binary tree with two additional constraints:[3]
- Shape property: a binary heap is a complete binary tree; that is, all levels of the tree, except possibly the last one (deepest) are fully filled, and, if the last level of the tree is not complete, the nodes of that level are filled from left to right.
- Heap property: the key stored in each node is either greater than or equal to (≥) or less than or equal to (≤) the keys in the node's children, according to some total order.
Heaps where the parent key is greater than or equal to (≥) the child keys are called max-heaps; those where it is less than or equal to (≤) are called min-heaps. Efficient (logarithmic time) algorithms are known for the two operations needed to implement a priority queue on a binary heap: inserting an element, and removing the smallest or largest element from a min-heap or max-heap, respectively. Binary heaps are also commonly employed in the heapsort sorting algorithm, which is an in-place algorithm because binary heaps can be implemented as an implicit data structure, storing keys in an array and using their relative positions within that array to represent child–parent relationships.
Heap operations
Both the insert and remove operations modify the heap to conform to the shape property first, by adding or removing from the end of the heap. Then the heap property is restored by traversing up or down the heap. Both operations take O(log n) time.
Insert
To add an element to a heap, we can perform this algorithm:
- Add the element to the bottom level of the heap at the leftmost open space.
- Compare the added element with its parent; if they are in the correct order, stop.
- If not, swap the element with its parent and return to the previous step.
Steps 2 and 3, which restore the heap property by comparing and possibly swapping a node with its parent, are called the up-heap operation (also known as bubble-up, percolate-up, sift-up, trickle-up, swim-up, heapify-up, or cascade-up).
The number of operations required depends only on the number of levels the new element must rise to satisfy the heap property. Thus, the insertion operation has a worst-case time complexity of O(log n). For a random heap, and for repeated insertions, the insertion operation has an average-case complexity of O(1).[4][5]
As an example of binary heap insertion, say we have a max-heap

and we want to add the number 15 to the heap. We first place the 15 in the position marked by the X. However, the heap property is violated since 15 > 8, so we need to swap the 15 and the 8. So, we have the heap looking as follows after the first swap:

However the heap property is still violated since 15 > 11, so we need to swap again:

which is a valid max-heap. There is no need to check the left child after this final step: at the start, the max-heap was valid, meaning the root was already greater than its left child, so replacing the root with an even greater value will maintain the property that each node is greater than its children (11 > 5; if 15 > 11, and 11 > 5, then 15 > 5, because of the transitive relation).
Extract
The procedure for deleting the root from the heap (effectively extracting the maximum element in a max-heap or the minimum element in a min-heap) while retaining the heap property is as follows:
- Replace the root of the heap with the last element on the last level.
- Compare the new root with its children; if they are in the correct order, stop.
- If not, swap the element with one of its children and return to the previous step. (Swap with its smaller child in a min-heap and its larger child in a max-heap.)
Steps 2 and 3, which restore the heap property by comparing and possibly swapping a node with one of its children, are called the down-heap (also known as bubble-down, percolate-down, sift-down, sink-down, trickle down, heapify-down, cascade-down, extract-min or extract-max, or simply heapify) operation.
So, if we have the same max-heap as before
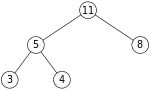
We remove the 11 and replace it with the 4.
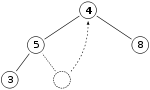
Now the heap property is violated since 8 is greater than 4. In this case, swapping the two elements, 4 and 8, is enough to restore the heap property and we need not swap elements further:

The downward-moving node is swapped with the larger of its children in a max-heap (in a min-heap it would be swapped with its smaller child), until it satisfies the heap property in its new position. This functionality is achieved by the Max-Heapify function as defined below in pseudocode for an array-backed heap A of length length(A). A is indexed starting at 1.
// Perform a down-heap or heapify-down operation for a max-heap
// A: an array representing the heap, indexed starting at 1
// i: the index to start at when heapifying down
Max-Heapify(A, i):
left ← 2×i
right ← 2×i + 1
largest ← i
if left ≤ length(A) and A[left] > A[largest] then:
largest ← left
if right ≤ length(A) and A[right] > A[largest] then:
largest ← right
if largest ≠ i then:
swap A[i] and A[largest]
Max-Heapify(A, largest)
For the above algorithm to correctly re-heapify the array, no nodes besides the node at index i and its two direct children can violate the heap property. The down-heap operation (without the preceding swap) can also be used to modify the value of the root, even when an element is not being deleted.
In the worst case, the new root has to be swapped with its child on each level until it reaches the bottom level of the heap, meaning that the delete operation has a time complexity relative to the height of the tree, or O(log n).
Insert then extract
Inserting an element then extracting from the heap can be done more efficiently than simply calling the insert and extract functions defined above, which would involve both an upheap and downheap operation. Instead, we can do just a downheap operation, as follows:
- Compare whether the item we're pushing or the peeked top of the heap is greater (assuming a max heap)
- If the root of the heap is greater:
- Replace the root with the new item
- Down-heapify starting from the root
- Else, return the item we're pushing
Python provides such a function for insertion then extraction called "heappushpop", which is paraphrased below.[6][7] The heap array is assumed to have its first element at index 1.
// Push a new item to a (max) heap and then extract the root of the resulting heap.
// heap: an array representing the heap, indexed at 1
// item: an element to insert
// Returns the greater of the two between item and the root of heap.
Push-Pop(heap: List<T>, item: T) -> T:
if heap is not empty and heap[1] > item then: // < if min heap
swap heap[1] and item
_downheap(heap starting from index 1)
return item
A similar function can be defined for popping and then inserting, which in Python is called "heapreplace":
// Extract the root of the heap, and push a new item
// heap: an array representing the heap, indexed at 1
// item: an element to insert
// Returns the current root of heap
Replace(heap: List<T>, item: T) -> T:
swap heap[1] and item
_downheap(heap starting from index 1)
return item
Search
Finding an arbitrary element takes O(n) time.
Delete
Deleting an arbitrary element can be done as follows:
- Find the index of the element we want to delete
- Swap this element with the last element
- Down-heapify or up-heapify to restore the heap property. In a max-heap (min-heap), up-heapify is only required when the new key of element is greater (smaller) than the previous one because only the heap-property of the parent element might be violated. Assuming that the heap-property was valid between element and its children before the element swap, it can't be violated by a now larger (smaller) key value. When the new key is less (greater) than the previous one then only a down-heapify is required because the heap-property might only be violated in the child elements.

Decrease or increase key
The decrease key operation replaces the value of a node with a given value with a lower value, and the increase key operation does the same but with a higher value. This involves finding the node with the given value, changing the value, and then down-heapifying or up-heapifying to restore the heap property.
Decrease key can be done as follows:
- Find the index of the element we want to modify
- Decrease the value of the node
- Down-heapify (assuming a max heap) to restore the heap property
Increase key can be done as follows:
- Find the index of the element we want to modify
- Increase the value of the node
- Up-heapify (assuming a max heap) to restore the heap property
Building a heap
Building a heap from an array of n input elements can be done by starting with an empty heap, then successively inserting each element. This approach, called Williams' method after the inventor of binary heaps, is easily seen to run in O(n log n) time: it performs n insertions at O(log n) cost each.[lower-alpha 1]
However, Williams' method is suboptimal. A faster method (due to Floyd[8]) starts by arbitrarily putting the elements on a binary tree, respecting the shape property (the tree could be represented by an array, see below). Then starting from the lowest level and moving upwards, sift the root of each subtree downward as in the deletion algorithm until the heap property is restored. More specifically if all the subtrees starting at some height have already been "heapified" (the bottommost level corresponding to ), the trees at height can be heapified by sending their root down along the path of maximum valued children when building a max-heap, or minimum valued children when building a min-heap. This process takes operations (swaps) per node. In this method most of the heapification takes place in the lower levels. Since the height of the heap is , the number of nodes at height is . Therefore, the cost of heapifying all subtrees is:







This uses the fact that the given infinite series converges.

The exact value of the above (the worst-case number of comparisons during the heap construction) is known to be equal to:

where s2(n) is the sum of all digits of the binary representation of n and e2(n) is the exponent of 2 in the prime factorization of n.
The average case is more complex to analyze, but it can be shown to asymptotically approach 1.8814 n − 2 log2n + O(1) comparisons.[10][11]
The Build-Max-Heap function that follows, converts an array A which stores a complete binary tree with n nodes to a max-heap by repeatedly using Max-Heapify (down-heapify for a max-heap) in a bottom-up manner. The array elements indexed by floor(n/2) + 1, floor(n/2) + 2, ..., n are all leaves for the tree (assuming that indices start at 1)—thus each is a one-element heap, and does not need to be down-heapified. Build-Max-Heap runs Max-Heapify on each of the remaining tree nodes.
Build-Max-Heap (A):
for each index i from floor(length(A)/2) downto 1 do:
Max-Heapify(A, i)
Heap implementation
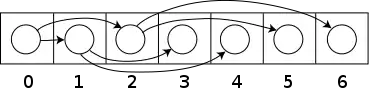

Heaps are commonly implemented with an array. Any binary tree can be stored in an array, but because a binary heap is always a complete binary tree, it can be stored compactly. No space is required for pointers; instead, the parent and children of each node can be found by arithmetic on array indices. These properties make this heap implementation a simple example of an implicit data structure or Ahnentafel list. Details depend on the root position, which in turn may depend on constraints of a programming language used for implementation, or programmer preference. Specifically, sometimes the root is placed at index 1, in order to simplify arithmetic.
Let n be the number of elements in the heap and i be an arbitrary valid index of the array storing the heap. If the tree root is at index 0, with valid indices 0 through n − 1, then each element a at index i has
- children at indices 2i + 1 and 2i + 2
- its parent at index floor((i − 1) / 2).
Alternatively, if the tree root is at index 1, with valid indices 1 through n, then each element a at index i has
- children at indices 2i and 2i +1
- its parent at index floor(i / 2).
This implementation is used in the heapsort algorithm which reuses the space allocated to the input array to store the heap (i.e. the algorithm is done in-place). This implementation is also useful as a Priority queue. When a dynamic array is used, insertion of an unbounded number of items is possible.
The upheap/downheap operations can then be stated in terms of an array as follows: suppose that the heap property holds for the indices b, b+1, ..., e. The sift-down function extends the heap property to b−1, b, b+1, ..., e. Only index i = b−1 can violate the heap property. Let j be the index of the largest child of a[i] (for a max-heap, or the smallest child for a min-heap) within the range b, ..., e. (If no such index exists because 2i > e then the heap property holds for the newly extended range and nothing needs to be done.) By swapping the values a[i] and a[j] the heap property for position i is established. At this point, the only problem is that the heap property might not hold for index j. The sift-down function is applied tail-recursively to index j until the heap property is established for all elements.
The sift-down function is fast. In each step it only needs two comparisons and one swap. The index value where it is working doubles in each iteration, so that at most log2 e steps are required.
For big heaps and using virtual memory, storing elements in an array according to the above scheme is inefficient: (almost) every level is in a different page. B-heaps are binary heaps that keep subtrees in a single page, reducing the number of pages accessed by up to a factor of ten.[12]
The operation of merging two binary heaps takes Θ(n) for equal-sized heaps. The best you can do is (in case of array implementation) simply concatenating the two heap arrays and build a heap of the result.[13] A heap on n elements can be merged with a heap on k elements using O(log n log k) key comparisons, or, in case of a pointer-based implementation, in O(log n log k) time.[14] An algorithm for splitting a heap on n elements into two heaps on k and n-k elements, respectively, based on a new view of heaps as an ordered collections of subheaps was presented in.[15] The algorithm requires O(log n * log n) comparisons. The view also presents a new and conceptually simple algorithm for merging heaps. When merging is a common task, a different heap implementation is recommended, such as binomial heaps, which can be merged in O(log n).
Additionally, a binary heap can be implemented with a traditional binary tree data structure, but there is an issue with finding the adjacent element on the last level on the binary heap when adding an element. This element can be determined algorithmically or by adding extra data to the nodes, called "threading" the tree—instead of merely storing references to the children, we store the inorder successor of the node as well.
It is possible to modify the heap structure to make the extraction of both the smallest and largest element possible in time.[16] To do this, the rows alternate between min heap and max-heap. The algorithms are roughly the same, but, in each step, one must consider the alternating rows with alternating comparisons. The performance is roughly the same as a normal single direction heap. This idea can be generalized to a min-max-median heap.


Derivation of index equations
In an array-based heap, the children and parent of a node can be located via simple arithmetic on the node's index. This section derives the relevant equations for heaps with their root at index 0, with additional notes on heaps with their root at index 1.
To avoid confusion, we'll define the level of a node as its distance from the root, such that the root itself occupies level 0.
Child nodes
For a general node located at index i (beginning from 0), we will first derive the index of its right child, .

Let node i be located in level L, and note that any level l contains exactly nodes. Furthermore, there are exactly nodes contained in the layers up to and including layer l (think of binary arithmetic; 0111...111 = 1000...000 - 1). Because the root is stored at 0, the kth node will be stored at index . Putting these observations together yields the following expression for the index of the last node in layer l.




Let there be j nodes after node i in layer L, such that

Each of these j nodes must have exactly 2 children, so there must be nodes separating i's right child from the end of its layer ().



As required.
Noting that the left child of any node is always 1 place before its right child, we get .

If the root is located at index 1 instead of 0, the last node in each level is instead at index . Using this throughout yields and for heaps with their root at 1.


Parent node
Every node is either the left or right child of its parent, so we know that either of the following is true.


Hence,

Now consider the expression .

If node is a left child, this gives the result immediately, however, it also gives the correct result if node is a right child. In this case, must be even, and hence must be odd.



Therefore, irrespective of whether a node is a left or right child, its parent can be found by the expression:

Related structures
Since the ordering of siblings in a heap is not specified by the heap property, a single node's two children can be freely interchanged unless doing so violates the shape property (compare with treap). Note, however, that in the common array-based heap, simply swapping the children might also necessitate moving the children's sub-tree nodes to retain the heap property.
The binary heap is a special case of the d-ary heap in which d = 2.
Summary of running times
Here are time complexities[17] of various heap data structures. Function names assume a min-heap. For the meaning of "O(f)" and "Θ(f)" see Big O notation.
| Operation | find-min | delete-min | insert | decrease-key | meld |
|---|---|---|---|---|---|
| Binary[17] | Θ(1) | Θ(log n) | O(log n) | O(log n) | Θ(n) |
| Leftist | Θ(1) | Θ(log n) | Θ(log n) | O(log n) | Θ(log n) |
| Binomial[17][18] | Θ(1) | Θ(log n) | Θ(1)[lower-alpha 3] | Θ(log n) | O(log n)[lower-alpha 4] |
| Fibonacci[17][19] | Θ(1) | O(log n)[lower-alpha 3] | Θ(1) | Θ(1)[lower-alpha 3] | Θ(1) |
| Pairing[20] | Θ(1) | O(log n)[lower-alpha 3] | Θ(1) | o(log n)[lower-alpha 3][lower-alpha 5] | Θ(1) |
| Brodal[23][lower-alpha 6] | Θ(1) | O(log n) | Θ(1) | Θ(1) | Θ(1) |
| Rank-pairing[25] | Θ(1) | O(log n)[lower-alpha 3] | Θ(1) | Θ(1)[lower-alpha 3] | Θ(1) |
| Strict Fibonacci[26] | Θ(1) | O(log n) | Θ(1) | Θ(1) | Θ(1) |
| 2–3 heap[27] | O(log n) | O(log n)[lower-alpha 3] | O(log n)[lower-alpha 3] | Θ(1) | ? |
- In fact, this procedure can be shown to take Θ(n log n) time in the worst case, meaning that n log n is also an asymptotic lower bound on the complexity.[1]: 167 In the average case (averaging over all permutations of n inputs), though, the method takes linear time.[8]
- This does not mean that sorting can be done in linear time since building a heap is only the first step of the heapsort algorithm.
- Amortized time.
- n is the size of the larger heap.
- Lower bound of [21] upper bound of [22]
- Brodal and Okasaki later describe a persistent variant with the same bounds except for decrease-key, which is not supported. Heaps with n elements can be constructed bottom-up in O(n).[24]


References
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009) [1990]. Introduction to Algorithms (3rd ed.). MIT Press and McGraw-Hill. ISBN 0-262-03384-4.
- Williams, J. W. J. (1964), "Algorithm 232 - Heapsort", Communications of the ACM, 7 (6): 347–348, doi:10.1145/512274.512284
- eEL,CSA_Dept,IISc,Bangalore, "Binary Heaps", Data Structures and Algorithms
{{citation}}: CS1 maint: uses authors parameter (link) - Porter, Thomas; Simon, Istvan (Sep 1975). "Random insertion into a priority queue structure". IEEE Transactions on Software Engineering. SE-1 (3): 292–298. doi:10.1109/TSE.1975.6312854. ISSN 1939-3520. S2CID 18907513.
- Mehlhorn, Kurt; Tsakalidis, A. (Feb 1989). "Data structures". Universität des Saarlandes: 27. doi:10.22028/D291-26123.
Porter and Simon [171] analyzed the average cost of inserting a random element into a random heap in terms of exchanges. They proved that this average is bounded by the constant 1.61. Their proof docs not generalize to sequences of insertions since random insertions into random heaps do not create random heaps. The repeated insertion problem was solved by Bollobas and Simon [27]; they show that the expected number of exchanges is bounded by 1.7645. The worst-case cost of inserts and deletemins was studied by Gonnet and Munro [84]; they give log log n + O(1) and log n + log n* + O(1) bounds for the number of comparisons respectively.
{{cite journal}}: Cite journal requires|journal=(help) - "python/cpython/heapq.py". GitHub. Retrieved 2020-08-07.
- "heapq — Heap queue algorithm — Python 3.8.5 documentation". docs.python.org. Retrieved 2020-08-07.
heapq.heappushpop(heap, item): Push item on the heap, then pop and return the smallest item from the heap. The combined action runs more efficiently than heappush() followed by a separate call to heappop().
- Hayward, Ryan; McDiarmid, Colin (1991). "Average Case Analysis of Heap Building by Repeated Insertion" (PDF). J. Algorithms. 12: 126–153. CiteSeerX 10.1.1.353.7888. doi:10.1016/0196-6774(91)90027-v. Archived from the original (PDF) on 2016-02-05. Retrieved 2016-01-28.
- Suchenek, Marek A. (2012), "Elementary Yet Precise Worst-Case Analysis of Floyd's Heap-Construction Program", Fundamenta Informaticae, 120 (1): 75–92, doi:10.3233/FI-2012-751.
- Doberkat, Ernst E. (May 1984). "An Average Case Analysis of Floyd's Algorithm to Construct Heaps" (PDF). Information and Control. 6 (2): 114–131. doi:10.1016/S0019-9958(84)80053-4.
- Pasanen, Tomi (November 1996). Elementary Average Case Analysis of Floyd's Algorithm to Construct Heaps (Technical report). Turku Centre for Computer Science. CiteSeerX 10.1.1.15.9526. ISBN 951-650-888-X. TUCS Technical Report No. 64. Note that this paper uses Floyd's original terminology "siftup" for what is now called sifting down.
- Kamp, Poul-Henning (June 11, 2010). "You're Doing It Wrong". ACM Queue. Vol. 8, no. 6.
- Chris L. Kuszmaul. "binary heap" Archived 2008-08-08 at the Wayback Machine. Dictionary of Algorithms and Data Structures, Paul E. Black, ed., U.S. National Institute of Standards and Technology. 16 November 2009.
- J.-R. Sack and T. Strothotte "An Algorithm for Merging Heaps", Acta Informatica 22, 171-186 (1985).
- Sack, Jörg-Rüdiger; Strothotte, Thomas (1990). "A characterization of heaps and its applications". Information and Computation. 86: 69–86. doi:10.1016/0890-5401(90)90026-E.
- Atkinson, M.D.; J.-R. Sack; N. Santoro & T. Strothotte (1 October 1986). "Min-max heaps and generalized priority queues" (PDF). Programming techniques and Data structures. Comm. ACM, 29(10): 996–1000.
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L. (1990). Introduction to Algorithms (1st ed.). MIT Press and McGraw-Hill. ISBN 0-262-03141-8.
- "Binomial Heap | Brilliant Math & Science Wiki". brilliant.org. Retrieved 2019-09-30.
- Fredman, Michael Lawrence; Tarjan, Robert E. (July 1987). "Fibonacci heaps and their uses in improved network optimization algorithms" (PDF). Journal of the Association for Computing Machinery. 34 (3): 596–615. CiteSeerX 10.1.1.309.8927. doi:10.1145/28869.28874.
- Iacono, John (2000), "Improved upper bounds for pairing heaps", Proc. 7th Scandinavian Workshop on Algorithm Theory (PDF), Lecture Notes in Computer Science, vol. 1851, Springer-Verlag, pp. 63–77, arXiv:1110.4428, CiteSeerX 10.1.1.748.7812, doi:10.1007/3-540-44985-X_5, ISBN 3-540-67690-2
- Fredman, Michael Lawrence (July 1999). "On the Efficiency of Pairing Heaps and Related Data Structures" (PDF). Journal of the Association for Computing Machinery. 46 (4): 473–501. doi:10.1145/320211.320214.
- Pettie, Seth (2005). Towards a Final Analysis of Pairing Heaps (PDF). FOCS '05 Proceedings of the 46th Annual IEEE Symposium on Foundations of Computer Science. pp. 174–183. CiteSeerX 10.1.1.549.471. doi:10.1109/SFCS.2005.75. ISBN 0-7695-2468-0.
- Brodal, Gerth S. (1996), "Worst-Case Efficient Priority Queues" (PDF), Proc. 7th Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 52–58
- Goodrich, Michael T.; Tamassia, Roberto (2004). "7.3.6. Bottom-Up Heap Construction". Data Structures and Algorithms in Java (3rd ed.). pp. 338–341. ISBN 0-471-46983-1.
- Haeupler, Bernhard; Sen, Siddhartha; Tarjan, Robert E. (November 2011). "Rank-pairing heaps" (PDF). SIAM J. Computing. 40 (6): 1463–1485. doi:10.1137/100785351.
- Brodal, Gerth Stølting; Lagogiannis, George; Tarjan, Robert E. (2012). Strict Fibonacci heaps (PDF). Proceedings of the 44th symposium on Theory of Computing - STOC '12. pp. 1177–1184. CiteSeerX 10.1.1.233.1740. doi:10.1145/2213977.2214082. ISBN 978-1-4503-1245-5.
- Takaoka, Tadao (1999), Theory of 2–3 Heaps (PDF), p. 12
External links
- Open Data Structures - Section 10.1 - BinaryHeap: An Implicit Binary Tree, Pat Morin
- Implementation of binary max heap in C by Robin Thomas
- Implementation of binary min heap in C by Robin Thomas