Búsqueda binaria
En ciencias de la computación y matemáticas, la búsqueda binaria, también conocida, como búsqueda de intervalo medio[1] o búsqueda logarítmica,[2] es un algoritmo de búsqueda que encuentra la posición de un valor en un array ordenado.[3][4] Compara el valor con el elemento en el medio del array, si no son iguales, la mitad en la cual el valor no puede estar es eliminada y la búsqueda continúa en la mitad restante hasta que el valor se encuentre.
La búsqueda binaria es computada en el peor de los casos en un tiempo logarítmico, realizando comparaciones, donde n es el número de elementos del arreglo y log es el logaritmo. La búsqueda binaria requiere solamente O(1) en espacio, es decir, que el espacio requerido por el algoritmo es el mismo para cualquier cantidad de elementos en el array.[5] Aunque estructuras de datos especializadas en la búsqueda rápidas como las tablas hash pueden ser más eficientes, la búsqueda binaria se aplica a un amplio rango de problemas de búsqueda.

Aunque la idea es simple, implementar la búsqueda binaria correctamente requiere atención a algunos detalles como su condición de parada y el cálculo del punto medio de un intervalo.
Existen numerosas variaciones de la búsqueda binaria. Una variación particular (cascada fraccional) acelera la búsqueda binaria para un mismo valor en múltiples arreglos.
Algoritmo
La búsqueda binaria funciona en arreglos ordenados. La búsqueda binaria comienza por comparar el elemento del medio del arreglo con el valor buscado. Si el valor buscado es igual al elemento del medio, su posición en el arreglo es retornada. Si el valor buscado es menor o mayor que el elemento del medio, la búsqueda continua en la primera o segunda mitad, respectivamente, dejando la otra mitad fuera de consideración.
Procedimiento
Dado un vector A de n elementos con valores A0 ... An−1, ordenados tal que A0 ≤ ... ≤ An−1, y un valor buscado T, el siguiente procedimiento usa búsqueda binaria para encontrar el índice de T en A.
- Asignar 0 a L y a R (n − 1).
- Si L > R, la búsqueda termina sin encontrar el valor.
- Sea m (la posición del elemento del medio) igual a la parte entera de (L + R) / 2.
- Si Am < T, igualar L a m + 1 e ir al paso 2.
- Si Am > T, igualar R a m – 1 e ir al paso 2.
- Si Am = T, la búsqueda terminó, retornar m.
Este procedimiento iterativo mantiene los límites de la búsqueda mediante dos variables. Algunas implementaciones realizan la comparación de igualdad al final del algoritmo, como resultando se obtiene un ciclo más rápido de comparaciones pero se aumenta en uno la cantidad de iteraciones promedio.[6]
Coincidencias aproximadas
El procedimiento anterior solo realiza coincidencias exactas, encontrando la posición del valor buscado. Sin embargo, dado el orden natural de los arreglos ordenados, es trivial extender la búsqueda binaria para realizar coincidencias aproximadas. Por ejemplo, la búsqueda binaria puede ser usada para computar, para un valor dado, su rank(el número de elementos menores), antecesor(próximo elemento menor), sucesor(próximo elemento mayor), y vecinos cercanos. Las consultas en intervalos, como por ejemplo, buscar el número de elementos entre dos números pueden ser computadas con dos preguntas de rank.
- Las consultas de rank pueden ser realizadas usando una modificación de la búsqueda binaria, retornando m en las búsquedas donde se encuentre el elemento, y L en donde no se encuentre, correspondiendo este último al número de elementos menores que el valor buscado.
- Las consultas de antecesor y sucesor pueden ser computadas con preguntas de rank también. Una vez que el rank del valor buscado es conocido, su antecesor es el elemento en la posición dado por su rank(el elemento mayor que es menor que el valor buscado). Su sucesor es el elemento después del (si él está presente en el arreglo) o en la posición siguiente al antecesor (en otro caso). El vecino más cercano del valor buscado es su antecesor o su sucesor, de los dos el más cercano.
- Las consultas de rango son también fáciles de manipular. Una vez que los rank de ambos valores son conocidos, el número de elementos mayores o iguales al primer valor y menores que el segundo es la diferencia de los dos ranks. Esta cantidad puede disminuir o aumentar de acuerdo si los extremos del intervalo deben ser considerados parte de la pregunta en cuestión y cuando el arreglo contenga llaves que coincidan con los extremos.
Rendimiento

El rendimiento de la búsqueda binaria puede ser analizada reduciendo el algoritmo a un árbol binario de búsqueda, donde la raíz es el elemento en el medio del arreglo, el elemento en el medio de la primera parte del arreglo es el hijo izquierdo de la raíz y el elemento en el medio de la segunda parte es el hijo derecho de la raíz. El resto del árbol se construye de forma similar. Este modelo representa a la búsqueda binaria, comenzando desde la raíz, el subárbol izquierdo o derecho son recorridos de acuerdo a si el valor buscado es menor o mayor que el valor presente en el nodo actual, representando la eliminación sucesiva de los elementos.[7]
En el peor de los casos se realizan iteraciones (del ciclo de comparaciones), donde la notación denota la parte entera por debajo de la función. Esta cantidad de iteraciones es alcanzada cuando la búsqueda alcanza el nivel más profundo del árbol, equivalente a una búsqueda binaria que se reduce a un solo elemento, y en cada iteración, siempre elimina el arreglo más pequeño de los dos si no tienen la misma cantidad de elementos.


Como promedio, asumiendo que cada elemento es igualmente probable de ser buscado, después que la búsqueda termine, el valor buscado será más probable de ser encontrado en el segundo nivel del árbol. Esto es equivalente a una búsqueda binaria que completa una iteración antes del peor de los casos, alcanzándola después de iteraciones. Sin embargo, el árbol puede estar no balanceado, con el nivel más profundo parcialmente completo, y equivalentemente, el arreglo puede no estar dividido perfectamente por la búsqueda en algunas iteraciones, resultando que en la mitad de las veces el menor subarreglo es eliminado. El promedio actual del número de iteraciones es ligeramente mayor .[7] En el mejor de los casos, donde el elemento del medio del arreglo es igual al valor buscado, su posición es retornada después de una iteración. En términos de iteración, ningún algoritmo basado solamente en comparaciones puede exhibir mejores promedios en su número de iteraciones que la búsqueda binaria.


Cada iteración de la búsqueda binaria definida anteriormente realiza una o dos comparaciones, comprobando si el elemento en el medio es igual al valor buscado en cada iteración. Asumiendo nuevamente que cada elemento es igualmente probable de ser buscado, cada iteración realiza como promedio 1.5 de comparaciones. Una variación del algoritmo comprueba por la igualdad en el final de cada búsqueda, eliminando como promedio la mitad de las comparaciones en cada iteración. En la mayoría de las computadoras el procedimiento anterior reduce el tiempo de cada iteración muy poco, mientras que garantiza que la búsqueda realice el mayor número de iteraciones posibles y como promedio adiciona una iteración más a la búsqueda. Dado que el ciclo de comparaciones se realiza solamente veces en el peor de los casos, para un n suficientemente grande, el pequeño incremento de la eficiencia producto de las comparaciones en el ciclo no compensa la iteración extra. Knuth 1998 propuso un valor de (más de 76 trillones) elementos para que esta variación fuese más rápida.[8][9]

Cascada fraccional puede ser usada para acelerar la búsqueda del mismo valor en múltiples arreglos. Se requiere para buscar en cada arreglo el elemento seleccionado, cascada fraccional lo reduce a , donde k es el número de arreglos.[10]


Comparación de la búsqueda binaria con otros esquemas
La técnica de usar arreglos ordenados con búsqueda binaria es una solución muy ineficiente cuando la inserción y la eliminación son necesarias, tomando un tiempo de
Otros algoritmos soportan más eficientemente la inserción y la eliminación, y también un macheo más rápido y exacto.
Hashing
Para implementar arreglos asociativos, tablas hash, una estructura que mapea llaves contra valores usando una función de hash, son generalmente más rápidas que la búsqueda binaria en arreglos ordenados de valores; la mayoría de las implementaciones requiere como promedio un tiempo amortizado constante. Sin embargo, hashing no es muy útil para comparaciones aproximadas, tales como antecesor, sucesor, y vecino más cercano, dado que la información que nos presenta en la búsqueda es si el valor está presente o no. La búsqueda binaria es ideal para este tipo de comparaciones, realizándolas en tiempo logarítmico.[11]
Árboles
Un árbol binario de búsqueda es una estructura de datos que funciona basado en el principio de la búsqueda binaria: los valores del árbol están colocados en forma ordenada, y el recorrido del árbol es realizado usando un algoritmo muy parecido a la búsqueda binaria. La inserción y eliminación requieren al igual que el recorrido un tiempo logarítmico. Este costo es mucho mejor que el costo lineal de la inserción y eliminación en los arreglos ordenados, y los árboles de búsqueda binaria poseen la habilidad de realizar todas las operaciones posibles en los arreglos ordenados, incluyendo consultas en rangos y comparaciones aproximadas.
Sin embargo, la búsqueda binaria es usualmente más eficiente para realizar búsquedas puesto que los árboles binarios de búsqueda estarán probablemente desbalanceados, dando como consecuencia un costo computacional superior a la búsqueda binaria.
Los árboles binarios de búsqueda se utilizan para realizar búsquedas rápidas en dispositivos de almacenamientos externos, donde los datos necesitan ser buscados y colocados en la memoria principal. Dividiendo el árbol en páginas con una cantidad determinada de elementos resultado que la búsqueda en el árbol binario tenga un menor costo computacional que los buscadores convencionales de los discos. Note que este proceso crea un árbol multipropósito, puesto que cada página está conectada una con otra. El árbol-B generaliza este método de la organización en el árbol, los Arbol-B son frecuentemente utilizados para organizar largos conjuntos de datos como las bases de datos o los sistemas de ficheros.
Búsqueda lineal
La búsqueda lineal es un simple algoritmo de búsqueda que comprueba cada elemento hasta que encuentre el valor buscado. La búsqueda lineal puede ser implementada en una lista enlazada, que nos permite inserciones y eliminaciones más eficientes que un arreglo. La búsqueda binaria es más eficiente que la búsqueda lineal en los arreglos ordenados, exceptuando los arreglos que contenga pocos elementos. Si el arreglo debe ser ordenado primero, ese costo debe ser amortizado sobre cualquier búsqueda. Ordenar el arreglo también nos permite comparaciones aproximadas más eficientes, entre otras operaciones.
Aproximaciones mixtas
El arreglo de Judy usa un conjunto de ideas para lograr una solución más eficiente.
Algoritmos de clasificación
Un problema relacionado con la búsqueda es la clasificación. Cualquier algoritmo que realice búsquedas, como la búsqueda binaria, puede ser usado para clasificar también. Existen otros algoritmos más específicos para la clasificación, un arreglo de bit es el más simple, usado cuando el rango de los elementos es limitado, es muy rápido ya que requiere un tiempo constante.
Para resultados aproximados, los filtros de Bloom, otra estructura de dato probabilista basada en hashing, guarda un conjunto de valores codificando los valores con arreglos de bits y múltiples funciones de hash. Los filtros de Bloomson mucho más eficaces que los arreglos de bits en cuanto a espacio en la mayoría de los casos y mucho más lentos.[12]
Otras estructuras de datos
Existen estructuras de datos que pueden realizar búsqueda binaria en arreglos ordenados. Por ejemplo, las búsquedas, las comparaciones parciales y todas las operaciones permitidas en arreglos ordenados pueden ser realizadas de manera más eficiente que con la búsqueda binaria con estructuras como los árboles de van Emde Boas, árboles de fusión, tries, y arreglos de bits. Sin embargo, mientras que estas operaciones pueden ser realizadas eficientemente en los arreglos ordenados sin importancia de cual sea el tipo de los elementos, este tipo de estructura de datos son usualmente más eficientes porque explotan las propiedades del conjunto de elementos del arreglo.[11]
Variaciones
Búsqueda binaria uniforme
La búsqueda binaria uniforme guarda el índice del elemento del medio y el número de elementos alrededor del elemento del medio que no hemos eliminado todavía. Cada paso reduce el tamaño del arreglo aproximadamente en la mitad. Esta variación es uniforme porque la diferencia entre los índices de los elementos del medio y el elemento escogido en la iteración anterior permanece constante para arreglos del mismo tamaño.
Búsqueda Fibonacci
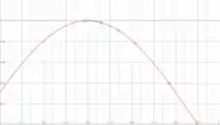

![{\displaystyle [0,1]}](../I/738f7d23bb2d9642bab520020873cccbef49768d.svg)


![{\displaystyle [{\frac {5}{13}},{\frac {6}{13}}]}](../I/f84907bd927345d114cc53fc283896a7d865e746.svg)

La búsqueda Fibonacci es un método similar a la búsqueda binaria que sucesivamente reduce el tamaño del intervalo al cual el máximo de una función unimodal pertenece. Dado un intervalo finito, una función unimodal, y la máxima longitud del intervalo resultante, la búsqueda Fibonacci encuentra un número de Fibonacci tal que si el intervalo se divide en esta cantidad de subintervalos de igual longitud, los subintervalos serán menores que la máxima longitud. Después de dividido el intervalo, elimina los subintervalos a los cuales el máximo no pertenece hasta que permanezcan uno o más subintervalos continuos.[13][14]
Búsqueda exponencial
La búsqueda exponencial es un algoritmo para buscar principalmente en listas infinitas, pero puede ser aplicada para seleccionar el límite superior de la búsqueda binaria. Comienza encontrando el primer elemento que cumple que es una potencia de dos y mayor que el valor buscado, después, fija este índice como el límite superior de la búsqueda binaria, y cambia hacia la búsqueda binaria. La búsqueda realiza iteraciones de la búsqueda exponencial y a lo sumo iteraciones de la búsqueda binaria, donde es la posición del valor buscado. Solamente si el valor buscado está cerca del principio del arreglo es que esta variación es más eficiente que seleccionar el mayor elemento como el límite superior.



Búsqueda de interpolación
Al contrario de la búsqueda binaria, la búsqueda de interpolación no calcula el punto medio sino que realiza varios intentos en busca del valor requerido, tomando en cuenta el menor y mayor elemento del arreglo así como su longitud. Este procedimiento es solamente posible si los elementos del arreglo son números. Se basa en la hipótesis de que el elemento del medio no es la mejor opción en muchos casos; por ejemplo, si el elemento buscado esta próximo al mayor elemento del arreglo, es muy probable que este ubicado en el final del arreglo. Cuando la distribución de los elementos en el arreglo es uniforme o cercanamente, se realizan comparaciones.[15]

En la práctica, la búsqueda de interpolación es más ineficiente que la búsqueda binaria para arreglos pequeños, dado que la búsqueda por interpolación requiere un conjunto de cómputos extras, y la tasa de crecimiento de su complejidad solo se compensa para arreglos grandes.
Cascada fraccional
Cascada fraccionaria es una técnica que acelera la búsqueda binaria del mismo elemento en arreglos ordenados. La búsqueda en cada arreglo toma , donde es el número de arreglos. Cascada fraccionaria reduce este costo a almacenando información específica en cada arreglo acerca de los otros arreglos.[10]



Cascada fraccionaria fue desarrollada originalmente para resolver eficientemente varios problemas de geometría computacional, pero también ha sido aplicada en dominios como el ruteo de los protocolos de internet.[10]
Historia
En 1946, John Mauchly mencionó por primera vez la búsqueda binaria como parte de Moore School Lectures, el primer conjunto de conferencias relacionado con las computadoras. Las siguientes publicaciones mencionaban que la búsqueda binaria solo funcionaba en arreglos cuya longitud fuese de uno menos que una potencia de dos hasta 1960, cuando Derrick Henry Lehmer público un algoritmo de búsqueda binaria que funcionaba en todos los arreglos ordenados. En 1962, Hermann Bottenbruch presentó en ALGOL 60 una implementación del algoritmo de búsqueda binaria en el cual colocaba la comparación de igualdad en el final del algoritmo, incrementando el número promedio de iteraciones por uno, pero reduciendo a uno el número de comparaciones por iteración. La búsqueda binaria uniforme fue presentada a Donald Knuth en 1971 por A. K. Chandra de la universidad de Stanford y publicado en el libro de Knuth: The Art of Computer Programming. En 1986, Bernard Chazelle y Leonidas J. Guibas introdujeron cascada fraccional, una técnica usada para acelerar la búsqueda binaria en múltiples arreglos.[10][16][17]
Problemas de implementación
A pesar de que la idea básica de búsqueda binaria es relativamente sencilla, los detalles pueden ser sorprendentemente complicados...—Donald Knuth [2]
Cuando Jon Bentley asignó la búsqueda binaria como un problema en un curso de programadores profesionales, se percató que el noventa por ciento fallo en desarrollar una solución correcta después de varias horas de trabajo y otro estudio publicado en 1988 muestra que el código correcto solo se encuentra en cinco de cada veinte muestras tomadas. Además la propia implementación de búsqueda binaria de Bentley, publicada en su libro de 1986 Programming Pearls, contenía un error de desbordamiento (overflow) que permaneció sin ser detectado por más de veinte años, además la implementación de la biblioteca del lenguaje de programación Java de la búsuqeda binaria tuvo el mismo error durante más de nueve años.[18]
En una implementación práctica, las variables utilizadas para representar los índices a menudo serán de tamaño fijo, y esto puede dar lugar a un desbordamiento aritmético para arreglos muy grandes. Si el punto medio del intervalo se calcula como (L + R) / 2, entonces el valor de L + R puede exceder el rango de enteros del tipo de datos usado para almacenar el punto medio, incluso si L y R están dentro del rango. Si L y R no son negativos, esto se puede evitar calculando el punto medio como L + (R - L) / 2.[19]
Si el valor buscado es mayor que el valor máximo del arreglo y el último índice del arreglo es el valor máximo representable de L, el valor de L eventualmente se convertirá en demasiado grande y ocurrirá un desbordamiento. Un problema similar ocurrirá si el valor buscado es menor que el menor valor en el arreglo y el primer índice del arreglo es el valor representable más pequeño de R. En particular, esto significa que R no debe ser un tipo sin signo si el arreglo empieza con índice 0..
Un bucle infinito puede ocurrir si las condiciones de salida para el bucle no están definidas correctamente. Una vez L supera R, la búsqueda ha fallado y debe transmitir el fracaso de la búsqueda. Además, el bucle debe salir cuando se encuentra el elemento de destino, o en el caso de una implementación donde este control se mueve al final, comprueba si la búsqueda tuvo éxito o falló al final debe estar en su lugar. Bentley encontró que, en su asignación de búsqueda binaria, este error fue realizado por la mayoría de los programadores que no implementaron correctamente una búsqueda binaria. [6]
Soporte de biblioteca
Las bibliotecas estándar de muchos lenguajes de programación incluyen implementaciones de la búsqueda binaria:
- C proporciona la función
bsearch() en su biblioteca estándar, la cual es típicamente implementada mediante búsqueda binaria (a pesar de que el estándar no lo requiere así).[20] - C++ STL proporciona las funciones binary_search()(), lower_bound(), upper_bound() y equal_range().[50]
- COBOL proporciona el verbo
SEARCH ALLpara realizar búsquedas binarias en tablas COBOL ordenadas.[21] - Java ofrece un conjunto de métodos estáticos de
binarySearh() en la clase Arrays yColeccionesen el paquete estándar java.util para realizar búsquedas binarias en los Arreglos y en lasListasde Java.[22][23] - Microsoft's .NET Franmework 2.0 ofrece versiones genéricas estáticas de la búsqueda binaria en su colección de clases. Un ejemplo sería
Sistema. Array'sBinarySearch<T>(T[]array, T valor).[24] - Python proporciona el módulo
bisect.[25] - La clase de Array de Ruby incluye un método bsearch con coincidencia aproximada incorporada.
- El paquete de biblioteca estándar: sort de Go contiene las funciones Search, SearchInts, SearchFloat64s y SearchStrings, que implementan la búsqueda binaria general, así como implementaciones específicas para buscar segmentos de números enteros, números de punto flotante y cadenas, respectivamente.
- Para Objective-C, el marco de Cacao proporciona el NSArray -indexOfObject:inSortedRange:opciones:usingComparator: método en Mac OS X 10.6+.[26] Apple's Core Foundation C framework también contiene un CFArrayBSearchValues() función.[27]
Véase también
Referencias
- Willams, Jr., Louis F. (1975). A modification to the half-interval search (binary search) method. Proceedings of the 14th ACM Southeast Conference. pp. 95-101. doi:10.1145/503561.503582.
- Knuth, 1998, §6.2.1 ("Searching an ordered table"), subsection "Binary search".
- Cormen et al., 2009, p. 39.
- Weisstein, Eric W. «Binary Search». En Weisstein, Eric W, ed. MathWorld (en inglés). Wolfram Research.
- Flores, Ivan; Madpis, George (1971). «Average binary search length for dense ordered lists». CACM 14 (9): 602-603. doi:10.1145/362663.362752.
- Bottenbruch, Hermann (1962).
- Flores, Ivan; Madpis, George (1971).
- Sloane, Neil.
- Rolfe, Timothy J. (1997).
- Chazelle, Bernard; Liu, Ding (2001).
- Beame, Paul; Fich, Faith E. (2001).
- Bloom, Burton H. (1970).
- Kiefer, J. (1953).
- Hassin, Refael (1981).
- Perl, Yehoshua; Itai, Alon; Avni, Haim (1978).
- Chazelle, Bernard; Guibas, Leonidas J. (1986).
- Chazelle, Bernard; Guibas, Leonidas J. (1986), "Fractional cascading: II".
- Bloch, Joshua (2 June 2006).
- Ruggieri, Salvatore (2003).
- "bsearch – binary search a sorted table".
- "The Binary Search in COBOL".
- "java.util.
- "java.util.
- "List<T>.
- "8.5. bisect — Array bisection algorithm".
- "NSArray".
- "CFArray".
Bibliografía
- Alexandrescu, Andrei (2010). The D Programming Language. Upper Saddle River, NJ: Addison-Wesley Professional. ISBN 0-321-63536-1.
- Bentley, Jon (2000) [1986]. Programming Pearls (2nd edición). Addison-Wesley. ISBN 0-201-65788-0.
- Chang, Shi-Kuo (2003). «Data Structures and Algorithms». Software Engineering and Knowledge Engineering 13 (Singapore: World Scientific). ISBN 978-981-238-348-8.
- Fitzgerald, Michael (2007). Ruby Pocket Reference. Sebastopol, CA: O'Reilly Media. ISBN 978-1-4919-2601-7.
- Goldman, Sally A.; Goldman, Kenneth J. (2008). A Practical Guide to Data Structures and Algorithms using Java. Boca Raton: CRC Press. ISBN 978-1-58488-455-2.
- Leiss, Ernst (2007). A Programmer's Companion to Algorithm Analysis. Boca Raton, FL: CRC Press. ISBN 1-58488-673-0.
- Moffat, Alistair; Turpin, Andrew (2002). Compression and Coding Algorithms. Hamburg, Germany: Kluwer Academic Publishers. ISBN 978-0-7923-7668-2. doi:10.1007/978-1-4615-0935-6.
- Sedgewick, Robert; Wayne, Kevin (2011). Algorithms (4th edición). Upper Saddle River, NJ: Addison-Wesley Professional. ISBN 978-0-321-57351-3. Condensed web version:; book version .
- Stroustrup, Bjarne (2013). The C++ Programming Language (4th edición). Upper Saddle River, NJ: Addison-Wesley Professional. ISBN 978-0-321-56384-2.
Enlaces externos
| Control de autoridades |
|
|---|
 Datos: Q243754
Datos: Q243754 Multimedia: Binary search algorithm / Q243754
Multimedia: Binary search algorithm / Q243754