Modelo de independencia binaria
El modelo de independencia binaria es una técnica de recuperación de información probabilística que hace algunas suposiciones para hacer más fácil la determinación de la similitud documento / consulta. Este modelo fue propuesto por primera vez por Yu y Salton,[1] pero su nombre lo debe a Robertson y Sparck.[2]
Definiciones
La suposición de independencia binaria es considerar a los documentos vectores binarios, es decir solo se tiene constancia de la existencia o no de los términos. Los términos están distribuidos independientemente en el conjunto de documentos al igual que en el conjunto de documentos irrelevantes. Los documentos y las consultas se representan a partir de un vector con un elemento booleano para cada término tomado en consideración, es decir un documento es representado por un vectoe d = (x1, x2,..., xm) donde xt = 1 si el término t está presente en el documento d y xt = 0 en caso contrario. Con esta simplificación muchos documentos pueden tener al mismo vector como representación. Las consultas son representadas de forma similar. La independencia entre términos quiere decir que los términos en un documento son considerados independientes uno de otros y que no es modelada ninguna asociación entre los mismos. Esta suposición es muy limitante pero ha sido probado que provee resultados lo suficientemente buenos para muchas situaciones. Además permite que la representación de los documentos sea tratada como una instancia de un modelo vectorial espacial al consideraer cada término como 0 o 1.
La probabilidad P(R|d,q) de que un documento sea relevante se deriva de la probabilidad de relevancia del vector de términos de dicho documento P(R|x,q). Usando el Teorema de Bayes obtenemos la siguiente función de similitud:
donde P(x|R=1,q) y P(x|R=0,q) son las probabilidades de recuperar un documento relevnte o irrelevante respectivamente, y la representación del documento es x. Como las probabilidades exactas no se conocen de antemano es necesario usar datos estadísticos sobre la colección de documentos.
P(R=1|q) y P(R=0|q) indican las probabilidades anteriores de recuperar un documento relevante o irrelevante dada una consulta q. Si por ejemplo conocieramos el porcentaje de documentos relevantes de la colección pudiéramos usar dicho dato para estimar dichas probabilidades. Como n documento es relevante o irrelevante dada una consulta tenemos:
Pesos de los términos de la consulta
Dada una consulta binaria y la función de similitud, definida anteriormente, entre un documento y una consulta, el problema es asignar pesos a los términos de la consulta para obtener una efectividad alta en el recobrado. Sean pi y qi las probabilidades de que un documento relevante y uno irrelevante contengan al i-ésimo término respectivamente. Yu y Salton propusieron que el peso del i-ésimo término fuera una función creciente definida como sigue:[1]
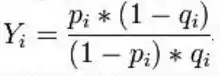
Entonces si Yi es mayor que Yj, el peso del término i-ésimo será mayor que el peso del j-ésimo. Yu y Salton mostraron que esa asignación de pesos arroja mejores resultados que en el caso donde los términos de la consulta poseen el mismo peso. Robertson y Sparck posteriormente mostraron que si al término i-ésimo se le asigna el peso de log(Yi) se obtiene la efectividad óptima bajo este modelo.[2]
Trabajos recientes
Wu y al.[3] propusieron un nuevo modelo probabilístico donde los pesos de los términos dependen del contexto dentro del documento. La función de peso usada por ellos es similar al modelo de independencia binaria.
Roelleke y al. investigan la implementación probabilística reñacional del modelo de independencia binaria bajo el uso del álgebra relacional para la integración de la recuperación de información en bases de datos. Esta investigación surge como resultado del interés de Surajit y otros en aplicar conocimientos de los modelos probabilísticos en la recuperación de información en datos estructurados, para a su vez investigar el problema del ranking de las respuestas a una consulta sobre una base de datos cuando más de una tupla es retornada.
Referencias
- Clement T. Yu, Gerard Salton: Precision Weighting - An Effective Automatic Indexing Method. J. ACM 23(1): 76-88 (1976)
- S.E. Robertson and Sparck Jones, K.: Relevance weighting of search terms. journal of the American Society for Information Science, 27: 129-146(1976)
- H. C. Wu: R. W. P. Luk, K. F. Wong, K.L. Kwok, A retrospective study of probabilistic contex-based retrieval
| Control de autoridades |
|
|---|
 Datos: Q3531721
Datos: Q3531721