PADICAT
El PADICAT (acrónimo de Patrimonio Digital de Cataluña) es el archivo web de Cataluña.[1]

Creado el 2005[2] por la Biblioteca de Cataluña, la institución pública responsable de compilar, conservar y difundir el patrimonio bibliográfico de Cataluña, y por extensión el patrimonio digital. Cuenta con la colaboración tecnológica del Centro de Servicios Científicos y Académicos de Cataluña (CESCA) para preservar y dar acceso a versiones antiguas de páginas web publicadas en Internet. La Biblioteca de Cataluña, como responsable del PADICAT, está asociada al International Internet Preservation Consortium (IIPC).[3]
Historia
El PADICAT nació el 2005 siguiendo la tendencia de otras bibliotecas nacionales en la creación de archivos web, y como respuesta a la publicación por parte de la UNESCO de las Directrices para la preservación del patrimonio digital.[4]
Hay numerosos archivos web en funcionamiento.[5] Los más conocidos son también los que hicieron los primeros pasos el año 1996: el sueco Kulturarw3;[6] el australiano Pandora,[7] y el conocido repositorio web de alcance internacional, Internet Archive.[8]
El análisis de estas experiencias pioneras y de posteriores, dan paso a la planificación del proyecto PADICAT siguiendo la tendencia generalizada en todo el mundo de un modelo híbrido de funcionamiento, complementando la captura periódica de un dominio geográfico entero (en este caso el .cat), con acciones selectivas, y ampliando esta cobertura a diversos acontecimientos de interés social que generan una actividad intensa en la red (procesos electorales, por ejemplo) o con paquetes web agrupados por una misma temática (museos de Cataluña, música folk rock catalana en la red, etc.). En el caso de PADICAT, esto se complementa con las aportaciones ciudadanas a través de las páginas web recomendadas.
En junio de 2005 la Biblioteca de Catalunya inició la fase preliminar, de planificación, en la cual se realizó el análisis de los proyectos y recursos existentes, los agentes implicados en la producción de páginas web en Cataluña y los aspectos legales que condicionan las prácticas que se quieren llevar a cabo.
Sobre la base de unos parámetros definidos por la Biblioteca de Catalunya, el 21 de julio de 2006 se empezaron a recopilar de manera automatizada las webs susceptibles de formar parte del patrimonio digital de Cataluña. El 11 de septiembre de 2006, coincidiendo con la celebración de la Diada Nacional de Catalunya, el portal web de PADICAT se abrió al público, con una treintena de webs almacenadas.
El período 2006-08 representa la fase de producción, del plan piloto del proyecto, la fase de explotación de PADICAT: la captura sistemática de las páginas web de Cataluña.
El período 2009-2011 ha permitido a la BC contar con un escenario óptimo en el cual este sistema, que es pionero en España y de referencia en Europa, funciona a pleno rendimiento. Paralelamente, se han cerrado acuerdos de cooperación con más de 450 instituciones de todo tipo, y se ha garantizado el acceso en abierto, en línea, a toda la colección.
El 11 de septiembre de 2011, coincidiendo de nuevo con la Diada Nacional de Catalunya y con el quinto aniversario de la puesta en funcionamiento de su web, se ha inaugurado una nueva versión del portal web de acceso a los contenidos depositados en PADICAT.
En fecha de noviembre de 2012, PADICAT ya tiene conservadas 58.122 webs, 249.609 capturas, 349 millones de ficheros y 13 TB de espacio que son consultables de forma libre y gratuita.[9]
Misión y funcionamiento
Misión y objetivos
La misión de PADICAT es capturar, conservar y difundir el patrimonio digital de Cataluña nacido en Internet. Sus objetivos son:
- Compilar masivamente el dominio .cat, gracias al convenio firmado con la Fundació puntCAT.[10]
- Impulsar el depósito sistemático de la producción web de las entidades y las empresas de Cataluña.
- Promover líneas de investigación procesando de manera monográfica los recursos de eventos de la vida pública catalana, como campañes electorales en Internet,[11] el fenómeno de la música en línea, o los museos en Internet.
Después de unas etapas de nacimiento (2005-2006), crecimiento (2007-2008) y consolidación (2009-2011), a partir del 2012 se persigue sistematizar la capacidad de crecimiento con la meta de incorporar anualmente unas 75.700 versiones de aproximadamente 32.000 páginas web, procedentes de:
- Compilación semestral de 30.000 recursos del dominio.cat.
- Compilación semestral de 550 recursos de las más de 450 entidades con las que se ha llegado a un convenio de cooperación.
- Compilación semestral de los recursos procedentes de las recomendaciones de los usuarios.
- Compilación diaria de una parte sustancial de 30 publicaciones seriadas en línea.
A estas metas concretas se añaden cuatro ejes permanentes de trabajo:
- Definición de las estrategias de preservación digital para el patrimonio nacido en Internet. PADICAT proporciona radiografías periódicas de la web catalana; detecta los formatos que experimentan a corto plazo problemas de ilegibilidad; identifica los lenguajes más usados, etc.
- Impulso a líneas de investigación a partir de la creación de colecciones monográficas que cuentan con la implicación de expertos de cada materia.
- Creación y mantenimiento de la hemeroteca digital en Internet, con la captura sistematizada de publicaciones digitales en serie. Actualmente, con una muestra representativa en cuanto a tipos y contenidos, seleccionando las nacidas digitales, sin equivalente analógico.
- Cooperación con otros archivos web y depósitos de preservación digital, de bibliotecas, archivos y museos, para dar una respuesta eficiente a los retos de preservación digital y acceso a los recursos depositados.
Software
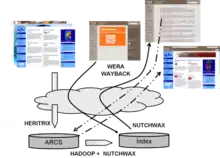
El sistema se basa en la aplicación de una serie de programas informáticos que permiten la captura, el almacenamiento, la organización y el acceso permanente a las páginas web publicadas en Internet. Posteriormente a la fase de análisis y test de software se determinó que se utilizaría el programa informático Heritrix,[12] empleado en la mayor parte de proyectos de captura de recursos digitales. Este es el programa encargado de compilar las páginas web tal y como las ve el usuario que navega por Internet y almacenarlas en archivos comprimidos en formato .arc o WARC.[13] A continuación, el programa Heritrix se complementa con NutchWax,[14] o bien la combinación de Haddoop[15] y Wayback,[16] que llevan a cabo unos procesos de indexación de la información compilada que permiten, ulteriormente, utilizar estos índices para localizar los recursos dentro de la colección mediante sus respectivas interfaces de consulta: Wera,[17] que permite la búsqueda por palabras clave a través de los índices generados por NutchWax; y Wayback, que permite la consulta directa por URL en los índices generados por Hadoop y el mismo Wayback.
Se ha aprovechado el programa Web Curator Tool,[18] desarrollado por la National Library of New Zealand[19] y la Biblioteca Británica, como sistema de gestión documental que permite la asignación de metadatos a una parte significativa de la colección, con la intención de poder integrar, en el futuro, el fondo del depósito a la búsqueda en otros catálogos, tanto de la Biblioteca de Cataluña, como de otras instituciones. Actualmente, ya se realiza la catalogación de las páginas web utilizando el software CAT[20] realizado por los técnicos del CESCA expresamente para el proyecto.

Hardware
Respecto al hardware que sostiene el sistema, se cuenta con seis nodos HP ProLiant DL360 G4p, encargados de las tareas de recolección e indexación de las páginas web. De la búsqueda y la visualización de resultados en la interface web, se encarga de ello un clúster Linux de alta disponibilidad con características de equilibrado de carga de peticiones y de tolerancia de errores en caso de desastre técnico de nódulos que integran la plataforma. Una cabina NetApp FAS3170 presenta un espacio de 19TB de disco vía NFS a estos nodos.
Los nodos están conectados mediante fibra a una Storage Area Network (SAN) y el sistema se completa con un robot donde se guardan, en cinta, copias de seguridad de los datos.
Está prevista la inclusión paralela de los contenidos depositados en PADICAT al sistema COFRE[21] (COnservem per al Futur Recursos Electrònics), un instrumento de preservación en alta seguridad creado a partir de la propia experiencia de la Biblioteca de Catalunya.
Referencias
- Web oficial
- Biblioteca de Catalunya, ed. (diciembre de 2005). «Memòria del plantejament del projecte PADICAT (Patrimoni Digital de Catalunya)». Consultado el 20 de noviembre de 2012.
- International Internet Preservation Consortium
- Biblioteca Nacional de Australia (2003). Unesco, ed. «Directrices para la preservación del patrimonio digital». Camberra. Consultado el 20 de noviembre de 2012.
- Llueca Fonollosa, Ciro (diciembre de 2005). BiD: textos universitaris de biblioteconomia i documentació, ed. «Webs sempre accessibles : les biblioteques nacionals i els dipòsits digitals nacionals». Archivado desde el original el 2 de febrero de 2014. Consultado el 20 de noviembre de 2012.
- «Kulturarw3». Archivado desde el original el 2 de octubre de 2013. Consultado el 20 de noviembre de 2012.
- Pandora
- Internet Archive
- PADICAT
- Signat el conveni de cooperació entre la Biblioteca de Catalunya i la fundació puntCAT per la preservació de les pàgines web.
- Llueca, Ciro; Daniel Cócera; Natalia Torres et al. (junio de 2011). El profesional de la información, ed. «A ritmo de tweet: archivando elecciones 2.0» (PDF). Consultado el 21 de noviembre de 2012.
- Heritrix
- WARC File Format specifications
- NutchWax
- Hadoop
- Wayback
- Wera
- «Web Curator Tool». Archivado desde el original el 19 de febrero de 2015. Consultado el 20 de noviembre de 2012.
- National Library of New Zealand
- Llueca, Ciro; Daniel Cócera; Natalia Torres et al. (septiembre de 2010). «CAT (Curator Archiving Tool): improving access to web archives = CAT (Curator Archiving Tool): millorant l'accés als arxius web = CAT (Curator Archiving Tool): mejorando el acceso a los archivos web» (PDF). Consultado el 21 de noviembre de 2012.
- Serra, Eugènia; Karibel Pérez; Ciro Llueca (2011). MEI, ed. «La Biblioteca de Catalunya i l'accés al patrimoni digital». Consultado el 21 de noviembre de 2012.