Red de inferencia
Las redes de inferencia constituyen una extensión del Modelo Probabilístico Clásico utilizado en problemas de recuperación de información. Estas resultan de gran interés porque permiten considerar varias fuentes de evidencia (consultas anteriores, distintas formulaciones de consultas, etc.) a la hora de determinar la relevancia de un documento dada una petición de información.
Las probabilidades, según el enfoque epistemológico, se determinan atendiendo a un grado de confianza de que ocurra un evento determinado, cuya especificación puede estar carente de experimentación estadística. Las Redes de Inferencia son un modelo de recuperación de información basado en las redes bayesianas y sigue el enfoque epistemológico de la teoría de las probabilidades.
Historia
En 1985 Judea Pearl propuso el término «red bayesiana» para representar e inferir en sistemas inteligentes,[1] esto lo hizo teniendo en cuenta las siguientes características:
- La naturaleza subjetiva de la información de entrada.
- La confianza en el condicionamiento de Bayes como la base para actualizar la información.
- La distinción entre los modos de razonamiento casual y evidencial.
A fines de la década de 1980 los textos “Probabilistic Reasoning in Intelligent Systems” y “Probabilistic Reasoning in Expert Systems” sintetizaron las propiedades de las Redes Bayesianas y ayudaron a su establecimiento como un campo de estudio.
Definiciones y conceptos
Las redes de inferencia son grafos cuyos nodos representan términos indexados, consultas y documentos. De cada documento sale un arco dirigido hacia cada uno de los términos indexados que aparecen en él.

Una variable aleatoria asociada con un documento di representa el evento de observar dicho documento. La observación de un documento es la causa por la que crece el grado de confianza en las variables asociadas con sus términos indexados kii.
La variable aleatoria asociada a una consulta del usuario q modela el evento de que la información requerida por la consulta haya sido obtenida. La confianza en esta consulta está en función de la confianza en los términos indexados que aparecen en la misma. En la red aparecen arcos dirigidos desde los términos indexados hasta las consultas en las cuales aparece (Figura 2).
Una simplificación de este modelo es cuando todas las variables de la red son binarias. En general esto facilita la tarea de modelación y mantiene todas las relaciones importantes en el problema de recuperación de información.
Sea el vector de los términos indexados, donde ki son variables aleatorias binarias, dj una variable aleatoria binaria asociada al documento y q una variable aleatoria binaria asociada a la consulta, en las Redes de Inferencia el valor de relevancia de un documento dj es calculado como , en general:



Este resultado se obtiene aplicando propiedades básicas de la probabilidad condicional y el Teorema de Bayes. En estas transformaciones se asume que los eventos de ocurrencia de un término en un documento son independientes. Por ese motivo se obtiene:

Debido al significado que tienen las probabilidades , se puede notar que las Redes de Inferencia recogen información muy útil para las estrategias de recuperación de información. Los nodos raíz de la red de inferencia no pueden derivar su probabilidad de ocurrencia de ningún otro. Como no hay ninguna evidencia para juzgar la probabilidad de ocurrencia de estos nodos, a ellos se debe asignar una distribución de probabilidad que normalmente se escoge uniforme. Por ejemplo, es usual la selección de la distribución donde N es la cantidad de documentos en el sistema.


Sin embargo una de las principales ventajas de las Redes de Inferencia es que las probabilidades de los nodos raíz se pueden asignar teniendo en cuenta evidencias previas sobre el sistema.
Representación del modelo
| Representación de los documentos | Vector binario que representa al conjunto de términos indexados |
| Representación de las consultas | Vector binario que representa al conjunto de términos que aparecen en la consulta |
| Pesos | Binarios |
| Framework | Teoría de Probabilidades y en particular las Redes Bayesianas |
| Función de similitud | |
| Dependencia entre términos | No |
Combinación de fuentes de evidencia
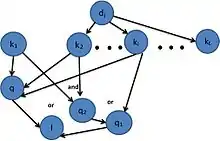
En la figura se muestra el nodo q como una consulta estándar que usa palabras claves, para la necesidad I de información del usuario. La consulta q1 es una consulta de tipo booleano para el mismo requerimiento de información. Si la red de inferencia está capacitada para modelar ambos tipos de consultas, entonces la información requerida puede ser modelada mediante un OR de q y q1. En este caso la función de ranking es calculada de la siguiente manera:


Lo cual puede representar un aumento de la eficiencia respecto al obtenido con cada uno de los nodos de la consulta por separado.
Costo computacional de las Redes de Inferencia
El costo de computar una red de inferencia es el mismo de computar el modelo vectorial. En general, los modelos basados en redes bayesianas no aportan un costo computacional significativo al cálculo de ranking, ya que los grafos subyacentes no tienen ciclos, lo que provoca que cualquier propagación en el grafo acíclico dirigido es proporcional a la cantidad de nodos.
Ventajas y desventajas del modelo de Redes de Inferencia
Ventajas:
- Permite realizar ranking a los documentos.
- Puede ser aplicado para representar el modelo booleano y el vectorial.
- Permite correspondencia parcial.
- Brinda poderosos mecanismos para la recuperación de información permitiendo utilizar varias fuentes de evidencia (consultas anteriores, distintas formulaciones de la consulta).
- Permite realizar consultas a consultas realizadas con anterioridad, elevando la calidad del conjunto de documentos recuperados.
Desventajas:
- Asume independencia entre los términos.
- Compleja implementación debido a que sus fundamentos teóricos son basados en las probabilidades y más específicamente en las redes bayesianas.
Bibliografía
- Information Retrieval Data Structures & Algorithms; William B. Frakes, Ricardo Baeza-Yates.
- Modern Information Retrieval I; Ricardo Baeza-Yates, Berthier Ribeiro-Neto.
- An Introduction to Information Retrieval; Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze.
Referencias
- Pearl, Judea (1985). Bayesian Networks: A Model of Self-Activated Memory for Evidential Reasoning. pp. 329-334.