Segmentación de cauce
La segmentación de cauce, también denominada pipeline, es una técnica empleada en el diseño de procesadores, basada en la división de la ejecución de las instrucciones en etapas, consiguiendo así que una instrucción empiece a ejecutarse antes de que hayan terminado las anteriores y, por tanto, que haya varias instrucciones procesándose simultáneamente.

Cada una de las etapas debe completar sus acciones en un ciclo de reloj, pasando sus resultados a la etapa siguiente y recibiéndolos de la anterior. Para eso es necesario almacenar los datos en registros intermedios. Cualquier valor que pueda ser necesario en una etapa posterior debe irse propagando a través de esos registros intermedios hasta que ya no sea necesario.
Para conseguir la segmentación es necesario que una instrucción utilice solamente una etapa en cada ciclo de ejecución.
Ya que todas las etapas deben de tardar lo mismo en su ejecución, el tiempo de ciclo será el de la etapa más lenta, más el del retardo provocado por la utilización de los registros intermedios. Comparando este esquema con el multiciclo, el tiempo de ciclo será más lento, pero el CPI (ciclos por instrucción) será menor, lo que provoca un aumento del rendimiento. Ya que si no tenemos en cuenta los riesgos estructurales (que pueden provocar paradas en el pipeline), tendríamos que en cada ciclo de reloj, termina de ejecutarse una instrucción (CPI=1).
Riesgos de Datos y de Control
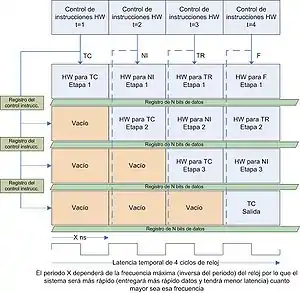
El empleo de esta técnica conlleva diversos riesgos de datos, ya que al empezar a ejecutar instrucciones antes de terminar las anteriores puede provocar que se necesite leer/escribir un registro antes de que este haya sido escrito/leído por la instrucción anterior/siguiente. Esos riesgos de datos se pueden clasificar como:
- RAW (Read After Write): una instrucción trata de leer un operando antes de que lo escriba una instrucción anterior.
- WAR (Write After Read): una instrucción trata de escribir su resultado en un destino (sobreescribiendo su valor previo) antes de que una instrucción anterior haya leído el valor anterior de éste.
- WAW (Write After Write): una instrucción trata de escribir antes que otra instrucción anterior escriba en el mismo destino.
La técnica más sencilla para evitar estos riesgos sería, cuando se detecte un riesgo, parar la ejecución de la instrucción que vaya a causar el riesgo, (insertando instrucciones NOP, o burbujas), hasta que hayan terminado de ejecutarse todas las instrucciones anteriores. Esta técnica supone demasiadas paradas en la ejecución, lo que supone una caída considerable del rendimiento.
Otra técnica para solucionar los riesgos RAW es la del adelantamiento, consistente en copiar un valor de un registro intermedio posterior en uno anterior, para que la instrucción que venga detrás pueda utilizar los valores, sin tener que esperar a que termine del todo la instrucción anterior.
Para intentar solucionar los demás riesgos se emplean técnicas más avanzadas como el algoritmo de Tomasulo o la de Scoreboard (ambas de predicción dinámica).
De una manera u otra, lo que se pretende con cualquiera de estas técnicas es reducir lo máximo posible los ciclos de parada, ya que incrementan el CPI, el cual idealmente es de 1. El compilador también influye notablemente en la búsqueda del CPI ideal, puesto que otra manera de evitar riesgos y, por lo tanto, posibles ciclos de parada, podría ser cambiar el orden de ejecución de las instrucciones, evitando siempre, por supuesto, que no cambie el resultado del programa.
Aparte de los riesgos de datos, también existen los riesgos de control, provocados por los saltos condicionales. Estos procesadores empiezan a mandar instrucciones a ejecutar antes de saber si esas instrucciones deben de ejecutarse(ya que hasta que no se procesa la condición de salto, no se sabe si será o no tomado), por lo que deben de tener maneras de deshacer cambios, o de poder descartarlos, si han empezado a ejecutar instrucciones que no corresponden, además del desperdicio de ciclos que supone el haber empezado a ejecutar instrucciones inútiles.
Por esto, se emplean técnicas para intentar predecir si un salto condicional será tomado o no, y en caso de equivocarse, que la penalización sea la mínima posible.
Para ello, existen técnicas de predicción estática (en caso de un salto, siempre se actuará de la misma manera), o técnicas de predicción dinámica (añadiendo hardware adicional, que intenta "aprender" el comportamiento del programa para saber que ha de hacer en el próximo salto). Ejemplos de estos últimos son el predictor de 1 o 2 bits, predictores con correlación, predictores de contienda y el BTB (Branch Target Buffer, Buffer de destino de saltos).
Véase también
Enlaces externos
 Wikimedia Commons alberga una galería multimedia sobre Segmentación de cauce.
Wikimedia Commons alberga una galería multimedia sobre Segmentación de cauce.
| Control de autoridades |
|
|---|
 Datos: Q7197282
Datos: Q7197282