Video Coding Layer
La capa de codificación de vídeo, o en inglés Video Coding Layer (VCL) es parte del estándar de video H.264/AVC y similar a MPEG-2 en lo que a su filosofía se refiere. Mezcla predicción temporal (se refiere al conjunto de frames que se suceden) y espacial (píxels dentro de la imagen).
Dentro del estándar H.264/AVC podemos encontrar también la Capa de abstracción de red (en inglés Network Abstraction Layer), la cual trata de facilitar una representación del contenido según el soporte de almacenamiento o transmisión.
En la siguiente imagen se puede observar la estructura de actuación de VCL para un macrobloque.
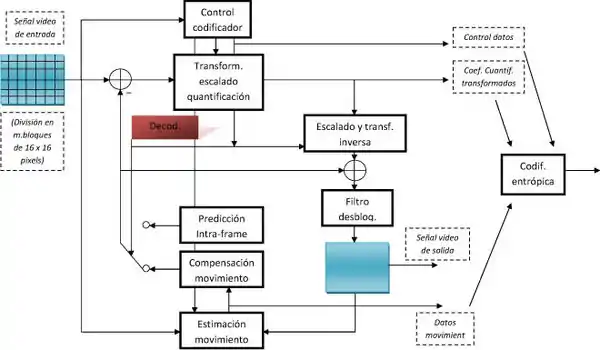
A continuación, se comentarán algunos de los bloques más significativos.
Subdivisión de una imagen en macrobloques
Procesar una imagen como tal presenta muchos problemas debido a que la imagen no es estacionaria. Esto es debido a que las características de la misma varían mucho (a no ser que sea un fondo de un único color). Así pues, se procede al proceso de dividirla en pequeños bloques que se pueden considerar estacionarios. En este caso, los macrobloques tienen una dimensión de 16x16 muestras de luminancia y 8x8 componentes de cada una de las dos componentes de crominancia. Los macrobloques a su vez, son la base a la hora de decidir de qué forma se codifica cada imagen antes de ser transmitida. Existen cinco tipos de codificación:
- Intra-frame: los macrobloques se codifican tal cual, sin referencias a anteriores imágenes.
- Predictive-frame: los macrobloques se predicen a partir de imágenes anteriores y Compensación de movimiento.
- Bi-predictive-frame: los macrobloques se predicen a partir de imágenes anteriores, posteriores y Compensación de movimiento.
- Switching P-frame: facilita alternancia entre streams codificados. Contiene macrobloque I y/o P.
- Switching I-frame: también facilita alternancia entre streams codificados. Contiene macrobloques SI.
Una vez los macrobloques han sido codificados, lo único que falta es transmitirlos. Con el fin de combatir los errores que puedan surgir en el canal de transmisión, el Grupo de Expertos en Codificación de Vídeo (VCEG) de la UIT-T y el Grupo de Expertos en Imágenes en Movimiento (MPEG) de la ISO/IEC desarrollaron la Ordenación flexible de los macrobloques (FMO, Flexible Macroblock Ordering), que asigna a cada macrobloque de la imagen un grupo de imágenes, lo cual permite efectivamente reducir la tasa de error.
Predicción Inter-frame
La Predicción Inter-frame es una técnica que explota la correlación temporal entre frames consecutivos para poder codificar con el mínimo número de bits posibles. Para codificar, lo que se hace es predecir un frame a partir de frames anteriores y/o futuros, aplicando sobre éstos un movimiento obtenido a partir de unos vectores de movimiento. Esta técnica ya se utilizaba en anteriores estándares como el MPEG-2.
Compensación de movimiento en P-frames
Como se ha comentado anteriormente, de cara a realizar una aceptable compensación de movimiento, es necesario dividir la imagen en macrobloques. Las mejoras más significativas de H.264 respecto a otras técnicas son las siguientes:
- Particiones de bloques más flexibles.
- Resolución de hasta ¼ de píxel en la compensación de movimiento.
- Múltiples referencias.
- Direct/Skip Macroblock mejorado.
Las particiones de bloques pueden ser de luminancia de 16×16 (MPEG-2), 16×8, 8×16 u 8×8. En este último caso nos permitirá dividirlo en nuevos bloques de 4×8, 8×4 y 4×4.
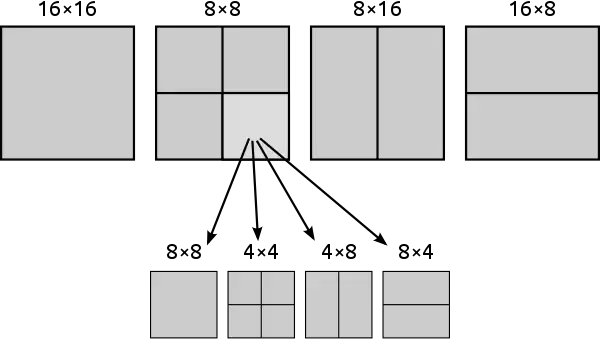
Así pues, un macrobloque podrá servir para predecir otro macrobloque de igual tamaño después de aplicarle el consiguiente desplazamiento.
Se consigue una resolución de hasta ¼ de píxel en la compensación de movimiento, ya que, además de poder replicar bloques, también se podrán interpolar píxeles que no existan.
El hecho de tener múltiples referencias significa que la predicción de un macrobloque podrá realizarse a partir de la combinación de diversos macrobloques. Esto es muy útil para escenas en movimiento, donde pueden aparece y/o desaparecer objetos, cuya referencia puede estar en frames anteriores y/o posteriores.
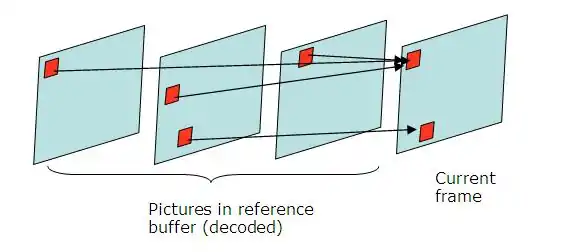
En el modo SKIP, no es necesario transmitir error de predicción, vector de movimiento ni tampoco ninguna referencia. El macrobloque reconstruido se obtiene de una forma similar a como se hace con las I-frames. Esta técnica se utiliza cuando, para un macrobloque, no existe ninguno que se asemeje lo suficiente, por lo que es mejor codificar el macrobloque entero tal cual.
Compensación de movimiento en B-frames
La teoría explicada para P-frames se puede generalizar para las B-frames. La diferencia entre ambas es que las B-frames se codifican de manera que un macrobloque se puede predecir a partir de información de compensación de movimiento proveniente de más de una estructura.
Las B-frames pueden tener 4 tipos de predicción:
- Lista 0
- indica que se utiliza compensación de movimiento a partir del primer buffer de referencia.
- Lista 1
- indica que se utiliza compensación de movimiento a partir del segundo buffer de referencia.
- Bi-predicción
- combinación de los dos anteriores.
- Predicción directa
- no se utiliza compensación de movimiento.
Transformación, escalado y cuantificación
A partir de bloques 4x4, se aplica una transformación con las mismas propiedades que la transformación DCT basada en una integral separable. Para los cuatro componentes de croma de cada componente también se aplica una transformación, en este caso 2x2.
Antes de transmitir la señal, también es importante realizar una cuantificación de la misma. En este caso se hace una cuantificación escalar que permite pasar de una señal (imagen) analógica a una digital. Para cada macrobloque se selecciona uno de los 52 cuantificadores a partir de lo que se conoce como parámetro de cuantificación (QP).
Codificación entrópica
El método de codificación entrópica que se utiliza por defecto en H.264/AVC se vale de un único conjunto de "codewords" (palabras código) para todos los elementos, exceptuando los coeficientes cuantificados. Así pues, no se necesita una tabla para cada elemento, sino que se utiliza este conjunto común.
En vistas a transmitir los coeficientes cuantificados, se utiliza una técnica denominada Context-Adaptative Variable Length Coding (CAVLC). El objetivo de esta codificación es procesar la información que se quiere transmitir o almacenar en un dispositivo de forma que ocupe el mínimo espacio posible. Esto permite que la imagen se pueda transmitir en menos tiempo o que ocupe un menor espacio en un dispositivo de almacenamiento.
Una técnica que permite aumentar la eficiencia de la codificación entrópica se denomina Context-Adaptative Binary Arithmetic Coding (CABAC). Como su propio nombre indica, se basa en el uso de codificación aritmética, lo cual permite el uso de números no necesariamente enteros que puedan hacer referencia a probabilidades.
Deblocking filter
La traducción de "deblocking filter" sería algo así como "filtro desbloqueante". La idea básica es que, debido a la partición de la imagen en bloques que se ha comentado anteriormente, en la imagen final puede aparecer lo que se denomina como efecto bloque. La consecuencia directa a efectos visuales es que la imagen pierde resolución debido a que los bloques se pueden apreciar.
La finalidad de este filtro adaptativo es la de reducir el denominado efecto bloque, controlando el ancho del filtro y sin afectar la nitidez de la imagen.
Bibliografía
- Ralf Schäfer, Thomas Wiegand, y Heiko Schwarz. "The emerging H.264/AVC standard"
- Thomas Wiegand, Gary J. Sullivan, Gisle Bjontegaard, and Ajay Luthra, "Overview of the H.264/AVC Video Coding Standard", IEEE Transactions on Circuits and Systems for Video Technology, Vol. 13, No. 7, pp. 560-576, July 2003.
| Control de autoridades |
|
|---|
 Datos: Q10523887
Datos: Q10523887