Síntesis de habla
La síntesis de habla es la producción artificial del habla. El sistema computarizado que es usado con este propósito es llamado computadora de habla o sintetizador de voz y puede ser implementado en productos software o hardware. Un sistema text-to-speech (TTS) convierte el lenguaje de texto normal en habla; otros sistemas recrean la representación simbólica lingüística como transcripciones fonéticas en habla.[1]

El habla sintetizada puede ser creada a través de la concatenación de fragmentos de habla grabados que son almacenados en una base de datos. Los sistemas difieren en el tamaño de las unidades de habla almacenadas; un sistema que almacena fonos y difonos permite un mayor rango de sonidos pero carece de claridad. Para usos específicos, el tamaño del almacenamiento de palabras completas u oraciones permite una mayor calidad de audio. De manera alternativa, un sintetizador puede incorporar un modelo de tracto vocal u otras características de la voz humana para recrear completamente una voz "sintética".[2]
La calidad de un sintetizador de voz se juzga por la similitud que tenga con la voz humana y su habilidad para ser entendido con claridad. Un programa de conversión de texto en habla inteligible permite que las personas con discapacidades visuales o dificultades para leer puedan escuchar textos en una computadora. Muchos sistemas operativos tienen sintetizadores de voz integrados desde principios de los noventa.
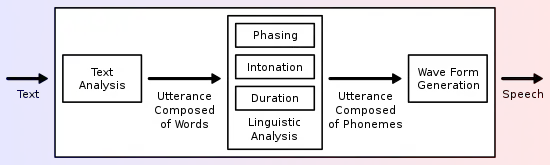
Un sistema o "motor" de texto a habla (TTS) está compuesto de dos partes:[3] un front-end y back-end. El front-end tiene dos tareas principales. Primero, convertir el texto con caracteres, números, símbolos y abreviaciones en su equivalente en palabras escritas. Este proceso es llamado como "normalización del texto", "pre-procesamiento" o "tokenización", posteriormente el front-end asigna una transcripción fonética a cada palabra, marca y divide el texto en unidades prosódicas, como frases, cláusulas y oraciones. El proceso de asignar transcripciones fonéticas a las palabras es llamado conversión "texto a fonema" o "grafema a fonema". La información de transcripciones fonéticas o prosódicas preparan la información de la representación simbólica lingüística que es el resultado del front-end. El back-end, comúnmente referido como el "sintetizador", convierte la representación simbólica lingüística en sonido. En algunos sistemas, esta parte incluye el cómputo de "intención prosódica" (tono del perfil, duración de los fonemas),[4] el cual es implementado en la voz de salida.
Historia
Antes de que el procesamiento de señal electrónico fuera inventado, hubo quienes intentaron construir máquinas para imitar el habla humana. Algunas de las primeras leyendas de la existencia de los "Brazen Heads" involucraron a Silvestre II (d. 1003 AD), Alberto Magno (1198–1280) y Roger Bacon (1214–1294).
En 1779 el científico danés Christian Kratzenstein, mientras trabajaba en la Academia de Ciencias de Rusia, construyó modelos del tracto vocal humano que podían reproducir los sonidos de las cinco vocales (en notación del Alfabeto Fonético Internacional para el inglés, son [aː], [eː], [iː], [oː] y [uː]).[5] Esto fue continuado por la "Wolfgang von Kempelen's Speaking Machine" operada por fuelles hecha por Wolfgang von Kempelen de Bratislava, Hungría, descrita en un texto en 1791.[6] Esta máquina integró modelos de labios y lengua, permitiendo producir consonantes, así como vocales. En 1837 Charles Wheatstone produjo un "máquina parlante" basada en el diseño de Von Kempelen, y en 1857, M. Faber construyó la máquina "Euphonia". El diseño de Wheatstone fue empleado por Paget en 1923.[7]
En la década de los treinta, los laboratorios Bell desarrollaron el vocoder, el cual automáticamente analizaba el habla a través de su nota fundamental y resonancias. De su trabajo con el vocoder, Homer Dudley desarrolló un sintetizador operado por un teclado llamado The Voder, el cual fue exhibido en la New York World's Fair de 1939.[8]
El "Pattern playback" fue construido por el Dr. Franklin S. Cooper y sus colegas en los laboratorios Haskins a finales de los cuarenta y finalizado en los cincuenta. Ha habido varias versiones de este dispositivo de hardware, pero solo una existe. La máquina convierte las imágenes de patrones acústicos del habla (espectrogramas) en sonido. Usando este dispositivo, Alvin Liberman y sus colegas lograron descubrir indicadores acústicos para la percepción de segmentos fonéticos (vocales y consonantes).[9]
Los sistemas dominantes en los ochenta y noventa eran el sistema DECtalk, basado en el trabajo de Dennis Klatt en MIT,[10] y el sistema de los laboratorios Bell;[11] que después se convertiría en un de los primeros sistemas multi-lenguajes independientes, haciendo un uso extensivo de los métodos de procesamiento de lenguajes naturales.
Los primeros sintetizadores de habla tenían un sonido robótico y poseían poca inteligibilidad. La calidad del habla sintetizada ha sido mejorada, pero el audio de salida de la síntesis de habla contemporánea aún es distinguible del habla humana.
Debido a la proporción de costo-rendimiento, los sintetizadores de habla se han convertido cada vez más baratos y accesibles para las personas, más gente será beneficiada por el uso de programas texto-habla.[12]
Dispositivos electrónicos
.jpg.webp)
Los primeros sistemas de computadora basados en la síntesis de voz fueron creados en los cincuenta. El primer sistema general de inglés de texto-habla fue desarrollado por Noriko Umeda et al. en 1968 en Laboratorio Electrotecnico en Japón.[13] En 1961, el físico John Larry Kelly, Jr y su colega Louis Gerstman[14] usaron una computadora IBM 704 para sintetizar la voz, un evento importante en la historia de los laboratorios Bell. El sintetizador de voz de Kelly (vocoder) reprodujo la canción "Daisy Bell" con el acompañamiento musical de Max Mathews. Casualmente, Arthur C. Clarke estaba visitando a su amigo y colega John Pierce en los laboratorios Bell en Murray Hill. Clarke estaba tan impresionado por la demostración que la usó en la escena clímax para su novela 2001: A Space Odyssey,[15] donde la computadora HAL 9000 canta la misma canción cuando pone a dormir al astronauta David Bowman.[16] Pese al éxito de la síntesis de voz electrónica pura, aún se continua investigando sobre los sintetizadores de voz mecánicos.[17]
Dispositivos móviles electrónicos incluyendo síntesis de voz comenzaron a aparecer en los setenta. Unos de los primeros fue la calculadora para ciegos Speech+ de Telesensory Systems Inc. (TSI) en 1976.[18][19] Otros dispositivos fueron producidos con fines educativos como el "Speak & Spell", creado por Texas Instruments en 1978.[20] Fidelity lanzó una versión parlante de su ajedrez electrónico en 1979.[21] El primer videojuego en incluir la síntesis de voz fue el arcade Matamarcianos, Stratovox, de Sunsoft.[22] Otro de los primeros ejemplos es la versión arcade de Berzerk del mismo año. El primer juego electrónico multijugador en usar la síntesis de voz fue "Milton" de Milton Bradley Company,[23] la cual produjo el dispositivo en 1980.
Tecnologías del sintetizador
Las cualidades más importantes de los sistemas de síntesis de voz son la "naturalidad" y la "inteligibilidad". La naturalidad describe qué tan cerca el audio de salida esta de la voz humana, mientras que la inteligibilidad es el grado de entendimiento que tiene el audio. El sintetizador de voz ideal es tanto natural como inteligible. Los sistemas de síntesis de voz usualmente tratan de maximizar estas características.[24]
Las dos tecnologías primarias que generan formas de ondas sintéticas de voz son la "síntesis concatenativa" y la "síntesis de formantes". Cada tecnología tiene sus fortalezas y debilidades, dependiendo de su uso se podrá determinar que acercamiento será usado.[25]
Síntesis concatenativa
La síntesis concatenativa está basada en la concatenación (o unión) de segmentos de una voz grabada. Generalmente, la síntesis concatenativa produce el sonido más natural de una voz sintetizada. Sin embargo, las diferencias entre las variaciones naturales en el habla y la naturaleza de las técnicas automatizadas para segmentación de formas de onda algunas veces resulta en glitches audibles en el audio de salida. Existen tres sub-tipos de síntesis concatenaitva.
Síntesis de selección de unidades
La síntesis de selección de unidades emplea bases de datos de voces grabadas. Durante la creación de la base de datos, cada enunciado grabado es segmentado en: fonos, difonos, medios fonos, sílabas, morfemas, palabras, frases y oraciones. Normalmente la división en segmentos es hecha con ayuda de un sistema de reconocimiento del habla modificado, usando representaciones visuales como la forma de onda y un espectrograma.[26] Un índice de las unidades de voz en la base de datos es creado basado en la segmentación y en parámetros acústicos como la frecuencia fundamental (tono), duración, posición de la sílaba y fonemas cercanos. Durante el tiempo de ejecución, el enunciado deseado es creado determinando la mayor cadena posible de unidades (selección de unidades). Este proceso es llevado a cabo usando un árbol de decisión.
La selección de unidades permite una naturalidad mayor debido a que emplea un menor procesamiento digital de señales (DSP) en el habla grabada. El procesamiento digital de señales usualmente ocasiona que el sonido de la voz no sea tan natural, aunque algunos sistemas emplean una pequeña cantidad de procesamiento de la señal en el punto de la concatenación para ajustar la forma de onda. El audio de salida de la mejor selección de unidades usualmente es indistinguible de las voces humanas reales, especialmente en contextos con sistemas TTS. Sin embargo, un mayor naturalidad requiere de bases de datos de selección de unidades muy grandes, en algunos sistemas llegando a ser de gigabytes de datos grabados, representando docenas de horas de voz.[27] También los algoritmos de selección de unidades son conocidos por seleccionar segmentos de un lugar menos ideal (ej. las palabras pequeñas no son claras) aun cuando una mejor opción existe en la base de datos.[28] Recientemente, los investigadores han propuestos varios métodos automatizados para detectar segmentos no naturales en los sistemas de síntesis de selección de unidades.[29]
Síntesis de difonos
La síntesis de difonos usa una base de datos de voz mínima que contiene todos los difonos (transiciones entre sonidos) que ocurren en el lenguaje. El número de difonos depende de la fonotáctica del lenguaje: por ejemplo, en el idioma español existen alrededor de 800 difonos y en el alemán 2500. En la síntesis de difonos, solo un ejemplo de cada difono es almacenado en la base de datos de voces. En el tiempo de ejecución, la prosodia objetivos de una oración es superpuesta en estas unidades mínimas a través de técnicas de procesamiento digital de señal como la codificación predictiva lineal, PSOLA[30] o MBROLA[31] o técnicas más recientes como la codificación del tono en el dominio de la fuente empleado la transformada de coseno discreta.[32] La síntesis de difonos sufre de glitches sonidos de la síntesis concatenativa y el sonido de naturaleza robótica de la síntesis de formantes y tiene pocas ventajas sobre cualquier otro acercamiento más que su tamaño. Su uso en aplicaciones comerciales ha disminuido, aunque sigue siendo investigada debido su número de aplicaciones en software gratuito.
Síntesis de dominio específico
La síntesis de dominio específico concatena palabras y frases pregrabadas para crear enunciados completos. Es usada en aplicaciones donde la variedad de los textos del sistemas esta limitada a una salida de audio en un dominio particular, como los anuncios en un calendario de tránsito o reportes del clima.[33] La tecnológica es muy simple de implementar y ha sido empleada de manera comercial por varios años en dispositivos como calculadoras o relojes parlantes. El nivel de naturalidad de estos sistemas puede ser muy alto debido a que la variedad los tipos de oraciones esta limitada y logran estar muy cerca de la prosodia y entonación de las grabaciones originales.
Debido a que estos sistemas están limitados por las palabras y frases en sus bases de datos, no son empleados para propósitos generales y solo pueden sintetizar combinaciones de palabras y frases a los que han sido programados. La adherencia de las palabras con la naturalidad del lenguaje puede causar problemas, a menos que las variaciones sean tomada en cuenta. Por ejemplo en los dialectos no róticos del inglés las palabras r como «clear» /ˈklɪə/ usualmente son pronunciadas cuando la siguiente palabra tiene un vocal en su primera letra (ej. «clear out» se pronuncia como /ˌklɪəɾˈʌʊt/). Como en el idioma francés, varias de las últimas consonantes no son silenciosas si son seguidas por una palabra que comience con una vocal, el efecto es llamado Liaison. Esta alternación no puede ser reproducida por sistema simple de concatenación, el cual requiere una compleja gramática sensible al contexto adicional.
Síntesis de formantes
La síntesis de formantes no utiliza muestras de voz humana durante el tiempo de ejecución. En su lugar, el audio de salida es creado a partir de la síntesis aditiva y un modelo acústico (síntesis mediante modelado físico).[34] Parámetros como la frecuencia fundamental, fonación y niveles de ruido son variados a través del tiempo para crear un forma de onda de una voz artificial. Este metido alguna veces es llamado síntesis basa en reglas; sin embargo, existen sistemas de concatenación que también tienen componentes basados en reglas.
Varios sistemas basados en la tecnología de síntesis de formantes generan una voz artificial con sonido robótico que no podría ser confundida con la voz humana. Sin embargo, la naturalidad máxima no es el objetivo de los sistemas de síntesis de voz, los sistemas de síntesis de formantes tienen ventajas sobre otros sistemas de concatenación. El habla a través de la síntesis de formantes puede ser inteligible, inclusive a grandes velocidades, evitando glitches acústicos comunes en los sistemas de concatenación. El habla sintetizada a grandes velocidades es usada por personas con dificultades visuales para navegar de manera más fluida en computadoras usando un lector de pantalla. Los sintetizadores de formantes son programas pequeños en comparación a los sistemas de concatenación debido a que no tienen un base de datos de muestras de voz. Pueden ser empleados en sistemas embebidos donde la memoria y el poder del microprocesador son limitados. Debido a que los sistemas basados en formantes tienen completo control sobre todos los aspectos del audio de salida, una amplia variedad de prosodias y entonaciones pueden ser generadas, para transmitir no solo preguntas o declaraciones, sino una variedad de emociones y entonaciones en la voz.
Algunos ejemplos de síntesis de formantes, no en tiempo real pero con gran precisión en el control de la entonación, se encuentran en trabajos de finales de los setenta por Texas Instruments con el juguete "Speak & Spell" y a finales de los ochenta en arcades de la compañía SEGA[35] y otros juegos de arcade de Atari[36] usando chips TMS5220 LPC de Texas Instrument. Crear la entonación apropiada era difícil y los resultados tenían que ser empatados en tiempo real con la interfaces texto-voz.[37]
Síntesis articulatoria
La síntesis articulatoria se refiere a las técnicas computacionales para síntesis del habla basadas en los modelos del tracto vocal humano y los procesos de articulación que ocurren. El primer sintetizador articulatorio frecuentemente usado en experimentos de laboratorio fue desarrollado en los laboratorios Haskins a mediados de los setenta por Philip Rubin, Tom Baer y Paul Mermelstein. Este sintetizador, conocido como ASY, estaba basado en modelos del tracto vocal desarrollado en los laboratorios Bell en los sesenta y setenta por Paul Mermelstein, Cecil Coker y sus colegas.
Recientemente, los modelos de síntesis articulatoria no habían sido incorporados en sistemas de síntesis de voz comerciales. Una excepción notable es el sistema basado en NeXT, originalmente desarrollado y puesto a la venta por Trillium Sound Research, una división de la compañía de la Universidad de Calgary, donde mucha de la investigación fue llevada a cabo. Siguiente a la desaparición de NeXT (iniciada por Steve Jobs a finales de la década de los ochenta y fusionara con Apple Computer en 1997), el software Trillium fue publicado bajo GNU General Public License, con su trabajo continuando como gnuspeech. El sistema, puesto a la venta en 1994, permite una conversión de texto-habla basada en una completa articulación usando una guía de ondas o una línea de transmisión análoga de la voz humana y conductos nasales controlados por el "modelo distintivo de región" de Carré.
Síntesis basada en modelos HMM
La síntesis basada en HMM es un método de síntesis basado en modelos ocultos de Márkov, también llamada síntesis estadística paramédica. En este sistema, el espectro de frecuencias (tracto vocal), la frecuencia fundamental (fuente de la voz) y la duración (prosodia) del habla son modelados de manera simultánea por HMM. Las formas de onda del habla son generada por los HMM basados en un criterio máxima verosimilitud.[38]
Síntesis de ondas sinusoidales
La síntesis de ondas sinusoidales es una técnica para síntesis de voz a través del reemplazo de formantes (principales bandas de energía) con tonos puros.[39]
Desafíos
Desafíos de la normalización de textos
El proceso de normalización de textos rara vez es directo. Los textos están llenos de heteronomías, números y abreviaciones que requieren de un expansión en una representación fonética. Hay muchas palabras en inglés que son pronunciadas de manera diferente basadas en su contexto. Por ejemplo, «My latest project is to learn how to better project my voice» en inglés la palabra project contiene dos pronunciaciones.
La mayoría de los sistemas de texto-habla (TTS) no generan representaciones semánticas de los textos de entrada, por lo que sus procesos pueden resultar erróneos, con poco entendimiento y computacionalmente inefectivos. Como resultado varias técnicas heurísticas son usadas para predecir la manera apropiada de desambiguar homografías como examinar las palabras cercanas usando estadísticas acerca de la frecuencia de uso.
Recientemente los sistemas TTS han comenzado a usar HMM para generar "etiquetados gramaticales" para ayudar a desambiguar las homografías. Esta técnica es hasta cierto punto efectiva para varios casos sobre como "read" debe ser pronunciado como "red" dando a entender una conjugación en pasado. Las tasas de errores típicos usando HMM de esta manera están por debajo del cinco por ciento. Estas técnicas también funcionan para la mayoría de los lenguajes europeos, aunque el entrenamiento en el corpus lingüístico es frecuentemente difícil en estos lenguajes.
Decidir como convertir números es otro problema que los sistemas TTS enfrentan. Es un desafío simple de programación convertir un número a palabras (por lo menos en el idioma inglés), como "1325" se convierte en "mil trescientos veinticinco". Sin embargo, los número ocurren en diferentes contextos; "1325" puede leerse como "uno tres dos cinco", "trece veinticinco" o "uno trescientos veinticinco". Un sistema TTS usualmente puede inferir como expandir un número basado en las palabras cercanos, número y la puntuación, algunas veces el sistema permite una manera de especificar el contexto si es ambiguo.[40] Los números romanos pueden ser leídos de diferentes maneras dependiendo el contexto.
De manera similar, las abreviaciones pueden resultar ambiguas. Por ejemplo, la abreviación "in" de "pulgas" puede ser diferenciada por la palabra "in" (en) o en la dirección en inglés "12 St John St." usa la misma abreviación para "street" (calle) y "saint" (San). Los sistemas TTS con front ends inteligentes pueden realizar predicciones correctas acerca de la ambigüedad de las abreviaciones, mientras que otros ofrecen el mismo resultado en todos los casos, dando resultados sin sentido (y a veces cómicos) como "co-operation" interpretado como "company operation".
Desafíos de texto a fonemas
Los sistemas de síntesis de voz emplean dos acercamientos básicos para determinar la pronunciación de una palabra basados en su escritura, un proceso el cual es comúnmente llamado texto-fonema o conversión de grafema a fonema (fonema es el término usado en la lingüística para describir los sonidos distintivos en el lenguaje). El acercamiento más simple de la conversión texto-fonema es a través de diccionarios, en donde un diccionario amplio que contiene todas las palabras de un lenguaje y su correcta pronunciación almacenada por el programa. Determinar la correcta pronunciación de cada palabra es cuestión de verificar cada palabra en el diccionario y remplazarla por la pronunciación especificado por el diccionario. Otro acercamiento es a través de las reglas, en donde las reglas de pronunciación son aplicadas a las palabras para determinar la correcta pronunciación basándose en su escritura.
Cada acercamiento tiene sus ventajas y desventajas. El acercamiento basado en un diccionario es rápido y preciso, pero falla completamente cuando una palabra no se encuentra en este. De manera que el diccionario crece, también lo hace el tamaño memoria que requiere la síntesis del sistema. Por otra parte, el acercamiento basado en reglas trabaja con cualquier tipo de texto de entrada, pero la complejidad de las reglas crece de manera sustancial cuando el sistema detecta pronunciaciones o escrituras irregulares. (Considere la palabra en inglés "of", la cual es la única en donde se pronuncia la "f"). Como resultado, casi todos los sistemas de síntesis de voz usan una combinación de estos acercamientos.
Lenguajes con ortografía fonética tienen un sistema de escritura regular y la predicción de la pronunciación de las palabras basada en su ortografía es exitosa. Los sistemas de síntesis para lenguajes donde es común el uso del método de reglas de manera extensiva, recurriendo a diccionarios para algunas palabras, como nombres extranjeros y préstamos lingüísticos, que sus traducciones no son obvias a partir de su escritura. Por otra parte, los sistemas de síntesis de voz para lenguajes como el idioma inglés, el cual tiene sistemas de escritura extremadamente irregulares, tienden a recurrir a diccionarios y usar métodos de reglas solo para palabras inusuales o que no están en sus diccionarios.
Evaluación de desafíos
La consistente evaluación de los sistemas de síntesis de voz puede resultar difícil debido a la falta de aceptación un criterio de evaluación universal. Diferentes organizaciones usan comúnmente diferentes datos de voz. La calidad de los sistemas de síntesis de voz también depende del grado de calidad en la técnica de producción (que puede involucrar grabaciones digitales u analógicas) y su facilidad para reproducir la voz. La evaluación de los sistemas de síntesis de voz ha estado comprometida por las diferencias entre las técnicas de producción y reproducción.
Desde 2005, sin embargo, algunos investigadores han comenzado ha evaluar la síntesis de voz usando una hoja de datos de voz en común.[41]
Prosodia y contenido emocional
Un estudio en la revista Speech Communication por Amy Drahota y sus colegas en la Universidad de Portsmouth en Reino Unido, reporta que las personas que escuchan las grabaciones de voz pueden determinar, en diferentes niveles, si el emisor estaba sonriendo o no.[42][43][44] Se ha sugerido que la identificación de las características vocales que muestran un contenido emocional pueden ayudar a hacer el sonido de la síntesis de voz más natural. Una de las cuestiones relacionadas es el tono de las oraciones, dependiendo de cuando es afirmativo, interrogativo o una oración de exclamación. Una de las técnicas para la modificación de tono[45] usa la transformada de coseno discreta en el dominio de la fuente (residuo de predicción lineal). Tales técnicas para la modificación sincronizada de tono requieren una señalización previa de los tonos en la base de datos de la síntesis de voz usando técnicas como la extracción de épocas usando un índice de consonantes oclusivas aplicado a la predicción lineal integrada residual de las regiones de voz.[46]
Hardware dedicado
Primeras tecnologías (no disponibles)
- Icofono
- Votrax
- SC-01A
- SC-02 / SSI-263 / "Artic 263"
- General Instrument SP0256-AL2 (CTS256A-AL2)
- National Semiconductor DT1050 Digitalker (Mozer - Forrest Mozer)
- Silicon Systems SSI 263
- Chips de voz Texas Instruments LPC
- TMS5110A
- TMS5200
- MSP50C6XX - Vendido a Sensory, Inc. en 2001[47]
Actuales (en 2013)
- Magnevation SpeakJet (www.speechchips.com) TTS256 Hobby and experimenter.
- Epson S1V30120F01A100 (www.epson.com) IC DECTalk Based voice, Robotic, Inglés y español.
- Textspeak TTS-EM (www.textspeak.com)
Mattel
La consola de videojuegos Intellivision de Mattel, la cual es una computadora que carece de teclado, permitía un módulos de síntesis de voz llamado Intellivoice en 1982. Incluía el chip de síntesis de voz SP0256 Narrator en un cartucho. El Narrator tenía 2KB de Read-Only Memory (ROM) y era utilizado para guardar un base de datos de palabras genéricas que podían ser combinadas para hacer frases en los juegos de Intellivision. Desde que el chip Orator puede aceptar datos de una memoria externa, cualquier palabra adicional o frase requerida puede ser almacenada dentro del cartucho. Los datos consisten en cadenas de texto de coeficiente de filtros analógicos para modificar el comportamiento del modelo de tracto vocal del chip, en lugar de muestras digitales.
SAM
También lanzado en 1982, Software Automatic Mouth fue el primer software sintetizador de voz comercial. Posteriormente fue usado para la base del Macintalk. El programa no se encontraba disponible para computadoras Macintosh Apple (incluyendo Apple II y Lisa), sino para modelos de Atari y Commodore 64. La versión de Apple requería de hardware adicional para la conversión digital analógico, aunque era posible utilizar la salida de audio de la computadora (con distorsión) si la tarjeta no estaba presente. El Atari hizo uso de un chip de audio POKEY. La reproducción de voz en el Atari normalmente deshabitaba las peticiones de interrupción y apagaba el chip ANTIC durante la salida de audio. La salida se encontraba sumamente distorsionada cuando la pantalla estaba prendida. El Commodore 64 usaba el chip de audio SID.
Atari
El primer sistema de síntesis de voz integrado en un sistema operativo fue para las computadoras 1400XL/1450XL diseñado por Atari usando el chip Votrax SC01 en 1983. Las computadoras 1400XL/1450XL usaban Finite State Machine para lleve a cabo la síntesis de voz en inglés.[48] Sin embargo, las computadoras 1400XL/1450XL eran raras.
Las computadoras Atari ST eran vendidas con el "stspeech.tos" en un disquete.
Apple
El primer sintetizador de voz integrado en un sistema operativo fue el MacInTalk de Apple. El software estaba licenciado por desarrolladores terceros como Joseph Katz y Mark Barton (posteriormente, SoftVoice, Inc.) y la primera versión fue presentada durante la introducción de la computadora Macintosh en 1984. La demostración presentada en enero, el cual empleaba de síntesis de voz basada en el software SAM, requería 512KB de memoria RAM. Como resultado, no podía correr en una memoria RAM de 128KB, presente en las primeras computadoras Mac.[49] La demostración fue llevada a cabo con un prototipo de 512KB, aunque esto no fue revelado a la audiencia lo que creó mayores expectativas para la Macintosh. A principios de los noventa, Apple expandió sus capacidades ofreciendo un sistema con un amplio soporte para la función texto-habla con la introducción de computadoras más veloces basadas en PowerPC, incluyó una mayor calidad de la voz reproducida. Apple también introdujo el reconocimiento del habla en sus sistemas los cuales permitían un set de comandos fluidos. Más recientemente, Apple ha incorporado muestras de voces. Comenzando como una curiosidad, el sistema de voz Macintosh de Apple ha evolucionado a un programa completo, PlainTalk, para personas con problemas relacionados con la vista. VoiceOver fue introducido en Mac OS X Tiger (10.4). Durante 10.4 (Tiger) y los primeros lanzamientos de 10.5 (Leopard) solo existía una voz en las Mac OS X. Desde 10.6 (Snow Leopard), el usuario puede escoger entre un amplio rango de múltiples voces. VoiceOver posee características como sonidos de inhalación entre oración, así como claridad en velocidades mayores en comparación al PlainTalk. Mac OS X también incluye el software "say", una aplicación de línea de comandos que convierte el texto en voz. Las adiciones estándar de AppleScript incluyen el software "say" que permite que un script utilice las voces instaladas y controle el tono, la velocidad y modulación del texto hablado.
El sistema operativo iOS de Apple, usado en el iPhone, iPad y iPod Touch usa la síntesis de voz de VoiceOver para accesibilidad.[50] Algunas aplicaciones también emplean síntesis de voz para facilitar la navegación, leer páginas web o traducir texto.
AmigaOS
El segundo sistema operativo en incluir un capacidades avanzadas de síntesis de voz fue AmigaOS, introducido en 1985. La síntesis de voz fue licenciada por Commodore International desde SoftVoice, Inc., quien también desarrolló el sistema texto-voz MacinTalk. Incluía un sistema completo de emulación de voz americana para el idioma inglés, con voces femeninas y masculinas y marcadores de "estrés", fue posible a través del chipset de Amiga.[51] El sistema de síntesis fue dividido en un dispositivo de narración, el cual era responsable de modular y concatenar fonemas, y una librería de traducción la cual traducción el texto en inglés a fonemas a través de un conjunto de reglas. AmigaOS también incluía procesador de habla de alto nivel que permitía a los usuario reproducir texto a través de líneas de comandos. La síntesis de voz ocasionalmente era usada por programas de terceros, particularmente procesadores de texto y software educativo. El software de síntesis se mantuvo intacto desde el primer lanzamiento de AmigaOS y Commodore finalmente removería la síntesis de voz a partir de AmigaOS 2.1.
Pese a la limitación de los fonemas de inglés americano, una versión no oficial con síntesis de voz de varios idiomas fue desarrollada. Esto hacía uso de una versión extendida de la libraría del traductor la cual podía traducir a un número de lenguajes, a partir de las reglas de cada lenguaje.[52]
Microsoft Windows
Sistemas modernos de escritorio de Windows pueden implementar componentes SAPI 1-4 y SAPI 5 para apoyar la síntesis de voz y el reconocimiento del habla. SAPI 4.0 estuvo disponible como una opción adicional para Windows 95 y Windows 98. Windows 2000 agregó el Microsoft Narrator, una utilidad para texto-voz para las personas que tuvieran alguna discapacidad visual. Programas de terceros como CoolSpeech, Textaloud y Ultra Hal pueden realizar varias tareas de texto-voz como leer texto desde un sitio web específico, correo electrónico, documento de texto, texto introducido por el usuario, etc. No todos los programas pueden usar la síntesis de voz de manera directa.[53] Algunos programas pueden emplear extensiones para leer texto.
Microsoft Speech Server es un paquete de voces para síntesis y reconocimiento basado en un servidor. Está diseñado para su uso en red con aplicaciones web y centros de llamadas.
Text-to-Speech (TTS) se refiere a la habilidad de las computadoras para leer texto. Un Motor TTS convierte el texto escrito en una representación fonética, posteriormente convierte la representación en ondas de sonido que pueden ser escuchadas. Motores TTS con diferentes lenguajes, dialectos y vocabularios especializados están disponibles a través de terceros.[54]
Internet
En la actualidad, existen un número de aplicaciones, plug-ins y gadgets que pueden leer mensajes directamente desde un cliente de correo electrónico y páginas web desde un navegador web o Google Toolbar como Text to Voice que es un complemento de Firefox. Algunos software especializados pueden narrar RSS. Por otra parte, los narradores RRS simplifican la información enviada permitiendo a los usuarios escuchar sus fuentes de noticias favoritas y convertirlas en podcasts. Existen lectores RSS en casi cualquier PC conectada a internet. Los usuarios pueden descargar archivos de audio generados a dispositivos portátiles, ej. con la ayuda de un receptor de podcast y escucharlos mientras caminas, corres, etc.
Un creciente campo en el internet basada en TTS son las tecnologías de apoyo como 'Browsealoud' de una compañía de Reino Unido y Readspeaker. Permiten la funcionalidad TTS a cualquiera (por cuestiones de accesibilidad, convencía, entretenimiento o información) con acceso a un navegador de internet. El proyecto Pediaphon fue creado en 2006 para permiter una navegación web similar a la basada en interfaz TTS en Wikipedia.[56]
Otros trabajos están en desarrollo en el contexto de W3C a través de W3C Audio Incubator Group con el apoyo de BBC y Google Inc.
Otros
- Seguido del fracaso comercial del hardware Intellivoice, los desarrolladores de videojuegos emplearon el software de síntesis de voz con moderación para futuros juegos. Un famoso ejemplo es la narración introductoria del videojuego Super Metroid de Nintendo para el Super Nintendo Entertainment System. Otros de los primeros sistemas en utilizar la síntesis de software en videojuegos son Atari 5200 (Baseball) y Atari 2600 (Quadrun y Open Sesame).
- Algunos lectores de e-books, como Amazon Kindle, Samsung E6, PocketBook eReader Pro, enTourage eDGe y Bebook Neo.
- El BBC Micro incorporó el chip de síntesis de voz TMS5220 de Texas Instruments.
- Algunos modelos de computadoras Texas Instruments producidas en 1979 y 1981 (Texas Instruments TI-99/4 y TI-99/4A) eran capaces de la síntesis de texto-fonema o recitar palabras completas y frases (texto-diccionario), usando el popular periférico Speech Synthesizer. TI usó un codec propio para completar las frases generadas en aplicaciones, principalmente juegos.[57]
- OS/2 Warp 4 de IBM incluía el VoiceType, un precursor del IBM ViaVoice.
- Sistemas que operan con software gratuito y open source incluyendo Linux son variados e incluyen programas open-source como Festival Speech Synthesis System, el cual usa la síntesis basada en difonos (puede usar un número limitado de voces MBROLA) y gnuspeech el cual emplea la síntesis articulatoria[58] de Free Software Foundation.
- Las unidades GPS producidas por Garmin, Magellan, TomTom y otros emplean la síntesis de voz para la navegación de automóviles.
- Yamaha produjo un sintetizador en 1999, el Yamaha FS1R el cual incluía capacidades de síntesis de formantes. Secuencias hasta de 512 formantes de vocales individuales y consonantes podía ser almacenadas y reproducidas, permitiendo frases cortas sintetizadas.
Lenguajes de marcado de síntesis de voz
Un número de lenguajes de marcado han sido establecidos para la interpretación de texto como voz en un formato de compilación XML. El más reciente es el Speech Synthesis Markup Language (SSML), el cual se convirtió en una recomendación W3C en 2004. Sistemas de lenguaje de marcado de síntesis de voz antiguos incluyen el Java Speech Markup Language (JSML) y SABLE. Aunque cada uno de estos fue propuesto como un estándar, ninguno de ellos ha sido adoptado ampliamente.
Los lenguajes de marcado de síntesis de voz son distinguidos de los lenguajes de marcado de diálogo. VoiceXML, por ejemplo, incluye tags relacionados al reconociendo de voz, manejo de diálogo y marcado, además de marcado de síntesis de voz.
Aplicaciones
La síntesis de voz ha sido una de las herramientas vitales de tecnologías de apoyo y su aplicación en esta área es significante y de gran uso. Permite que las barreras ambientales sean removidas para personas con diferentes discapacidades. La aplicación con mayor uso han sido los lectores de pantalla para personas con discapacidades visuales, pero los sistemas de texto-voz ahora son comúnmente usados por personas con dislexia y otras dificultades para la lectura, así como para los niños. También son frecuentemente empleados para ayudar a aquellos con discapacidades comunicativas usualmente a través de una voz de ayuda.
Las técnicas de síntesis de voz son usadas en productos de entretenimiento como juegos o animaciones. En 2007, Animo Limited anunció el desarrollo de una aplicación de software basada en la síntesis de voz de FineSpeech, explícitamente enfocada a consumidores en la industria del entretenimiento, permitiendo generar narraciones y líneas de diablo desacuerdo a las especificaciones del usuario.[59] La aplicación maduró en 2008 cuando NEC Biglobe anunció un servicio web que permitía a los usuarios crear frases apartar de voces de los personajes de Code Geass: Lelouch of the Rebellion R2,[60]
El texto-voz ha encontrado nuevas aplicaciones fuera del mercado de la ayuda a los discapacitados. Por ejemplo, la síntesis de voz , combinada con el reconocimiento de voz, permite la interacción con dispositivos móviles a través de interfaces de procesamiento de lenguajes naturales. También ha sido usado como un segundo lenguaje de adquisición. Voki, por ejemplo, es una herramienta educativa creada por Oddcast que permite a los usuarios seleccionar su propio avatar, usando diferentes acentos. Pueden ser enviados a través de correo electrónico o ser colocados en sitios web o redes sociales.
API
Múltiples compañías ofrecen APIs TTS a los consumidores para acelerar el desarrollo de nuevas aplicaciones usando la tecnología TTS. Las compañías que ofrecen API TTS incluyen a AT&T, IVONA, Neospeech, Readspeaker y YAKiToMe!. Para el desarrollo de aplicación para móviles, el sistema operativo Android ha ofrecido una API TTS por un largo tiempo. De manera reciente, con iOS7, Apple ha comenzado a ofrecer de igual manera una API TTS.
Véase también
- Wikiproyecto:Wikipedia grabada
- Conversor texto-voz
- Lector de pantalla
- LibriVox
- Lingüística computacional
- Podcast
- Procesamiento de lenguaje natural
- Prosodia
- Qwiki
- Reconocimiento de voz
- Síntesis (sonido)
- Sintetizador del habla
- Transcriptor fonético
- Loquendo
- VOCALOID (cantador)
- Microsoft Speech API (en inglés)
- Programas de reconocimiento de voz (en inglés)
- Síntesis de habla en la televisión digital (en inglés)
- Speech Synthesis Markup Language (en inglés)
- UTAU
- Chipspeech
Referencias
- Allen, Jonathan; Hunnicutt, M. Sharon; Klatt, Dennis (1987). From Text to Speech: The MITalk system. Cambridge University Press. ISBN 0-521-30641-8.
- Rubin, P.; Baer, T.; Mermelstein, P. (1981). «An articulatory synthesizer for perceptual research». Journal of the Acoustical Society of America 70 (2): 321-328. doi:10.1121/1.386780.
- van Santen, Jan P. H.; Sproat, Richard W.; Olive, Joseph P.; Hirschberg, Julia (1997). Progress in Speech Synthesis. Springer. ISBN 0-387-94701-9.
- Van Santen, J. (16 de abril de 1994). «Assignment of segmental duration in text-to-speech synthesis». Computer Speech & Language 8 (2): 95-128. doi:10.1006/csla.1994.1005.
- History and Development of Speech Synthesis, Helsinki University of Technology, Retrieved on November 4, 2006
- Mechanismus der menschlichen Sprache nebst der Beschreibung seiner sprechenden Maschine ("Mechanism of the human speech with description of its speaking machine," J. B. Degen, Wien). (en alemán)
- Mattingly, Ignatius G. (1974). «Speech synthesis for phonetic and phonological models». En Sebeok, Thomas A., ed. Current Trends in Linguistics (Mouton, The Hague) 12: 2451-2487. Archivado desde el original el 12 de mayo de 2013. Consultado el 1 de julio de 2015.
- Lawrence, J. (2007). «2». Speech Science Primer: Physiology, Acoustics, and Perception of Speech (en inglés). p. 24.
- «The Pattern Playback» (en inglés). Consultado el 3 de julio de 2015.
-
Klatt, Dennis (16 de abril de 1987), «How Klattalk became DECtalk: An Academic's Experiences in the Business World», The official proceedings of Speech Tech '87 (New York: Media Dimensions Inc./Penn State): 293-294
|obra=y|periódico=redundantes (ayuda). - Sproat, Richard W. (1997). Multilingual Text-to-Speech Synthesis: The Bell Labs Approach. Springer. ISBN 0-7923-8027-4.
- [[Raymond Kurzweil Raymond Kurzweil|Kurzweil, Raymond]] (2005). The Singularity is Near. Penguin Books. ISBN 0-14-303788-9.
- Klatt, D. (1987) "Review of Text-to-Speech Conversion for English" Journal of the Acoustical Society of America 82(3):737-93
- Lambert, Bruce (21 de marzo de 1992). «Louis Gerstman, 61, a Specialist In Speech Disorders and Processes». New York Times.
- «Arthur C. Clarke Biography». Archivado desde el original el 11 de diciembre de 1997. Consultado el 11 de diciembre de 1997.
- «Where "HAL" First Spoke (Bell Labs Speech Synthesis website)». Bell Labs. Archivado desde el original el 29 de abril de 2011. Consultado el 17 de febrero de 2010.
- Anthropomorphic Talking Robot Waseda-Talker Series
- TSI Speech+ & other speaking calculators
- Gevaryahu, Jonathan, "TSI S14001A Speech Synthesizer LSI Integrated Circuit Guide"Uso incorrecto de la plantilla enlace roto (enlace roto disponible en Internet Archive; véase el historial, la primera versión y la última).
- Breslow, et al. United States Patent 4326710: "Talking electronic game" April 27, 1982
- Voice Chess Challenger
- Gaming's Most Important Evolutions, GamesRadar
- "Far-out phonemes." Popular Mechanics (Tech Front Lines). Jun 1981
- Gahlawata, M., Malika, A., Bansalb, P. Natural Speech Synthesizer for Blind Persons Using Hybrid Approach’’. Procedia Computer Science, 2014, p. 86
- Schröder, M., Emotional Speech Synthesis: A Review’’. University of the Saarland, 2001, p.1
- Alan W. Black, Perfect synthesis for all of the people all of the time. IEEE TTS Workshop 2002.
- John Kominek and Alan W. Black. (2003). CMU ARCTIC databases for speech synthesis. CMU-LTI-03-177. Language Technologies Institute, School of Computer Science, Carnegie Mellon University.
- Julia Zhang. Language Generation and Speech Synthesis in Dialogues for Language Learning, masters thesis, Section 5.6 on page 54.
- William Yang Wang and Kallirroi Georgila (2011). Automatic Detection of Unnatural Word-Level Segments in Unit-Selection Speech Synthesis, IEEE ASRU 2011.
- «Pitch-Synchronous Overlap and Add (PSOLA) Synthesis». Archivado desde el original el 22 de febrero de 2007. Consultado el 28 de mayo de 2008.
- T. Dutoit, V. Pagel, N. Pierret, F. Bataille, O. van der Vrecken. The MBROLA Project: Towards a set of high quality speech synthesizers of use for non commercial purposes. ICSLP Proceedings, 1996.
- R Muralishankar, A.G.Ramakrishnan and P Prathibha. Modification of Pitch using DCT in the Source Domain. "Speech Communication", 2004, Vol. 42/2, pp. 143-154.
- L.F. Lamel, J.L. Gauvain, B. Prouts, C. Bouhier, R. Boesch. Generation and Synthesis of Broadcast Messages, Proceedings ESCA-NATO Workshop and Applications of Speech Technology, September 1993.
- Dartmouth College: Music and Computers, 1993.
- como Astro Blaster, Space Fury y Star Trek: Strategic Operations Simulator
- como Star Wars, Firefox, Return of the Jedi, Road Runner, The Empire Strikes Back, Indiana Jones and the Temple of Doom, 720°, Gauntlet, Gauntlet II, A.P.B., Paperboy, RoadBlasters, Vindicators Part II, Escape from the Planet of the Robot Monsters
- John Holmes and Wendy Holmes (2001). Speech Synthesis and Recognition (2ª edición). CRC. ISBN 0-7484-0856-8.
- «The HMM-based Speech Synthesis System». Hts.sp.nitech.ac.j. Consultado el 22 de febrero de 2012.
- Remez, R.; Rubin, P.; Pisoni, D.; Carrell, T. (22 de mayo de 1981). «Speech perception without traditional speech cues». Science 212 (4497): 947-949. PMID 7233191. doi:10.1126/science.7233191.
- «Speech synthesis». World Wide Web Organization.
- «Blizzard Challenge». Festvox.org. Consultado el 22 de febrero de 2012.
- «Smile -and the world can hear you». University of Portsmouth. 9 de enero de 2008. Archivado desde el original el 17 de mayo de 2008.
- «Smile - And The World Can Hear You, Even If You Hide». Science Daily. 16 de enero de 2008.
- Drahota, A. (2008). «The vocal communication of different kinds of smile». Speech Communication 50 (4): 278-287. doi:10.1016/j.specom.2007.10.001. Archivado desde el original el 3 de julio de 2013.
- Muralishankar, R.; Ramakrishnan, A. G.; Prathibha, P. (16 de febrero de 2004). «Modification of pitch using DCT in the source domain». Speech Communication 42 (2): 143-154. doi:10.1016/j.specom.2003.05.001. Consultado el 7 de diciembre de 2014.
- Prathosh, A. P.; Ramakrishnan, A. G.; Ananthapadmanabha, T. V. (16 de diciembre de 2013). «Epoch extraction based on integrated linear prediction residual using plosion index». IEEE Trans. Audio Speech Language Processing 21 (12): 2471-2480. doi:10.1109/TASL.2013.2273717. Consultado el 19 de diciembre de 2014.
- EE Times. "TI will exit dedicated speech-synthesis chips, transfer products to Sensory Archivado el 16 de enero de 2013 en Wayback Machine.." June 14, 2001.
- «1400XL/1450XL Speech Handler External Reference Specification» (PDF). Consultado el 22 de febrero de 2012.
- «It Sure Is Great To Get Out Of That Bag!». folklore.org. Consultado el 24 de marzo de 2013.
- «iPhone: Configuring accessibility features (Including VoiceOver and Zoom)». Apple. Consultado el 29 de enero de 2011.
- Miner, Jay et al. (1991). Amiga Hardware Reference Manual (3ª edición). Addison-Wesley Publishing Company, Inc. ISBN 0-201-56776-8.
- Devitt, Francesco (30 de junio de 1995). «Translator Library (Multilingual-speech version)». Archivado desde el original el 26 de febrero de 2012. Consultado el 9 de abril de 2013.
- «Accessibility Tutorials for Windows XP: Using Narrator». Microsoft. 29 de enero de 2011. Consultado el 29 de enero de 2011.
- «How to configure and use Text-to-Speech in Windows XP and in Windows Vista». Microsoft. 7 de mayo de 2007. Consultado el 17 de febrero de 2010.
- Jean-Michel Trivi (23 de septiembre de 2009). «An introduction to Text-To-Speech in Android». Android-developers.blogspot.com. Consultado el 17 de febrero de 2010.
- Andreas Bischoff, The Pediaphon - Speech Interface to the free Wikipedia Encyclopedia for Mobile Phones, PDA's and MP3-Players, Proceedings of the 18th International Conference on Database and Expert Systems Applications, Pages: 575-579 ISBN 0-7695-2932-1, 2007
- «Smithsonian Speech Synthesis History Project (SSSHP) 1986-2002». Mindspring.com. Archivado desde el original el 3 de octubre de 2013. Consultado el 17 de febrero de 2010.
- «gnuspeech». Gnu.org. Consultado el 17 de febrero de 2010.
- «Speech Synthesis Software for Anime Announced». Anime News Network. 2 de mayo de 2007. Consultado el 17 de febrero de 2010.
- «Code Geass Speech Synthesizer Service Offered in Japan». Animenewsnetwork.com. 9 de septiembre de 2008. Consultado el 17 de febrero de 2010.
| Control de autoridades |
|
|---|
 Datos: Q16346
Datos: Q16346 Multimedia: Speech synthesis / Q16346
Multimedia: Speech synthesis / Q16346