Analyse factorielle multiple
L’analyse factorielle multiple (AFM) est la méthode factorielle adaptée à l’étude des tableaux dans lesquels un ensemble d’individus est décrit par un ensemble de variables (quantitatives et/ou qualitatives) structuré en groupes. Elle peut être vue comme une extension :
- de l’Analyse en Composantes Principales (ACP) lorsque les variables sont quantitatives,
- de l’Analyse des Correspondances Multiples (ACM) lorsque les variables sont qualitatives,
- de l’Analyse Factorielle de Données Mixtes (AFDM) lorsque les variables actives sont des deux types.
Pour les articles homonymes, voir AFM.
Exemple introductif
Pour quelles raisons introduire plusieurs groupes de variables en actif dans une même analyse factorielle ?
Données
Plaçons-nous dans le cas de variables quantitatives, c’est-à-dire dans un cadre de l’ACP. Un exemple de données issu de recherches écologiques offre une utile illustration. On dispose, pour 72 stations, de deux types de mesures.
- Le coefficient d’abondance dominance de 50 espèces végétales (coefficient variant de 0 = la plante est absente à 9 = l’espèce recouvre plus des trois-quarts de la surface). L’ensemble des 50 coefficients définit le profil floristique d’une station.
- Onze mesures pédologiques (= concernant le sol) : granulométrie, physicochimie, etc. L’ensemble de ces onze mesures définit le profil pédologique d’une station.
Trois analyses possibles
ACP de la flore (pédologie en supplémentaire).
On s’intéresse d’abord à la variabilité des profils floristiques. Deux stations sont proches si elles ont des profils floristiques voisins. Dans un deuxième temps, les principales dimensions de cette variabilité (i.e. les composantes principales) sont reliées aux mesures pédologiques introduites en supplémentaire.
ACP de la pédologie (flore en supplémentaire).
On s’intéresse d’abord à la variabilité des profils pédologiques. Deux stations sont proches si elles ont le même profil pédologique. Les principales dimensions de cette variabilité (i.e. les composantes principales) sont ensuite reliées aux abondances des plantes.
ACP sur les deux groupes de variables en actif.
On peut vouloir étudier la variabilité des stations du double point de vue de la flore et du sol. Dans cette approche, deux stations doivent être proches si elles ont des flores similaires et des sols similaires.
Équilibre entre les groupes de variables
Méthodologie
La troisième analyse de l’exemple introductif suppose implicitement un équilibre entre la flore et sol. Or, dans cet exemple, le simple fait que la flore soit représentée par 50 variables et le sol par 11 variables implique que l’ACP des 61 variables sera influencée majoritairement par la flore (au moins quant au premier axe). Ce n’est pas souhaitable.
Le cœur de l’AFM repose sur une analyse factorielle (ACP dans le cas de variables quantitatives, ACM dans le cas de variables qualitatives) dans laquelle les variables sont pondérées. Ces poids sont identiques pour les variables d’un même groupe (et varient d’un groupe à l’autre). Ils sont tels que l’inertie axiale maximum d’un groupe est égale à 1 : autrement dit, en faisant l’ACP (ou, le cas échéant, l’ACM) d’un seul groupe avec cette pondération, on obtient une première valeur propre égale à 1. Pour obtenir cette propriété, on affecte à chaque variable du groupe un poids égal à l’inverse de la première valeur propre de l’analyse (ACP ou ACM selon le type de variable) du groupe .

Formellement, en notant la première valeur propre de l’analyse factorielle du seul groupe , l’AFM affecte le poids à chaque variable du groupe .


Le fait d’équilibrer les inerties axiales maximum plutôt que les inerties totales (= le nombre de variables en ACP normée) confère à l’AFM plusieurs propriétés importantes pour l’utilisateur. De façon plus directe, son intérêt apparaît dans l’exemple suivant.
Exemple
Soient deux groupes de variables définis sur le même ensemble d’individus.
- Le groupe 1 est composé des deux variables non corrélées A et B.
- Le groupe 2 est composé de deux variables {C1, C2} identiques à une même variable C peu corrélée aux deux premières.
Cet exemple n’est pas complètement irréaliste. On est souvent conduit à analyser simultanément des groupes multidimensionnels et unidimensionnels.
Chaque groupe, ayant le même nombre de variables, à la même inertie totale.
Dans cet exemple le premier axe de l’ACP est quasiment confondu avec C. En effet, il y a deux variables dans la direction de C : autrement dit, le groupe 2, ayant toute son inertie concentrée dans une direction, influence de façon prépondérante le premier axe. De son côté, le groupe 1, étant composé de deux variables orthogonales (= non corrélées), a son inertie équirépartie dans un plan (celui engendré par les deux variables) et ne pèse quasiment pas sur le premier axe.
Exemple numérique
|
|












Le tableau 2 regroupe les inerties des deux premiers axes de l’ACP et de l’AFM du tableau 1.
Les variables du groupe 2 contribuent à 88,95 % de l’inertie de l’axe 1 de l'ACP. Ce premier axe est presque confondu avec C : la corrélation entre C et vaut .976 ;
Le premier axe de l’AFM (du tableau 1) fait jouer un rôle équilibré aux deux groupes de variables : la contribution de chaque groupe à l’inertie de cet axe est rigoureusement égale à 50 %.
Le deuxième axe, quant à lui, ne dépend que du groupe 1. Ceci est naturel puisque ce groupe est bidimensionnel et que le second groupe, unidimensionnel, s’est exprimé sur le premier axe.
Bilan sur l'équilibre entre les groupes
Introduire en actif plusieurs groupes de variables dans une analyse factorielle suppose implicitement un équilibre entre ces groupes.
Cet équilibre doit tenir compte du fait qu’un groupe multidimensionnel influence naturellement plus d’axes qu’un groupe unidimensionnel (qui ne peut être étroitement lié qu’à un seul axe).
La pondération de l’AFM, qui rend égale à 1 l’inertie axiale maximum de chaque groupe, joue ce rôle.
Aperçu sur quelques domaines d'application
Enquête. Les questionnaires sont toujours structurés en thèmes. Chaque thème correspond à un groupe de variables, par exemple des questions d’opinions et des questions de comportement. Ainsi, dans cet exemple, on peut vouloir réaliser une analyse factorielle dans laquelle deux individus sont proches s’ils ont émis les mêmes opinions et déclarés les mêmes comportements.
Analyse sensorielle. Un même ensemble de produits a été évalué par un jury d’experts et par un jury de consommateurs. Pour son évaluation, chaque jury utilise une liste de descripteurs (acide, amer, etc.) que chaque juge note, pour chaque produit, sur une échelle d’intensité allant par exemple de 0 = nul ou très faible à 10 = très fort. Dans le tableau associé à un jury, on trouve, à l’intersection de la ligne et de la colonne , la moyenne des notes attribuées au produit pour le descripteur .


Les individus sont les produits. Chaque jury correspond à un groupe de variables. On veut réaliser une analyse factorielle dans laquelle deux produits sont proches s’ils ont été évalués de la même façon et ce par les deux jurys.
Données multidimensionnelles temporelles. On mesure variables sur individus. Ces mesures sont effectuées à dates. Il y a de nombreuses façons d’analyser de telles données. L’une d’elles, suggérée par l’AFM, revient à considérer chaque date comme un groupe de variables dans l’analyse des tableaux (des données de chaque date) juxtaposés en ligne (le tableau analysé possède donc lignes et x colonnes).



Bilan sur ces exemples : en pratique, le cas où les variables sont structurées en groupe et très fréquent.
Graphiques issus d’une AFM
Au-delà de la pondération des variables, l’intérêt de l’AFM réside dans un ensemble de graphiques et d’indicateurs précieux dans l’analyse d’un tableau dont les colonnes sont structurées en groupes.
Graphiques classiques des analyses factorielles usuelles (ACP, ACM)
Le cœur de l’AFM étant une analyse factorielle pondérée, l’AFM fournit d’abord les résultats classiques de l’analyse factorielle.
1.Représentations des individus dans lesquelles deux individus sont d’autant plus proches qu’ils ont des valeurs voisines pour toutes les variables de tous les groupes ; en pratique, on se limite souvent au premier plan factoriel.
2.Représentations des variables quantitatives comme en ACP (cercle des corrélations).
 Figure1. AFM. Données test. Représentation des individus sur le premier plan. |
 Figure2. AFM. Données test. Représentation des variables sur le premier plan. |
Dans l’exemple :
- le premier axe oppose principalement les individus 1 et 5 (figure1).
- les quatre variables ont une coordonnée positive (figure 2) : le premier axe est un effet taille. De fait, l’individu 1 a de faibles valeurs pour toutes les variables et l’individu 5 à de fortes valeurs pour toutes les variables.
3. Indicateurs d’aide à l’interprétation : inerties projetées, contributions et qualité de représentation. Dans l’exemple, la contribution des individus 1 et 5 à l’inertie du premier axe vaut 45,7 % + 31,5 % = 77,2 % ce qui justifie de centrer l’interprétation sur ces deux points.
4. Représentations des modalités des variables qualitatives comme en ACM (une modalité est au barycentre des individus qui la possèdent). Pas de variables qualitatives dans l'exemple.
Graphiques spécifiques de ce type de tableau multiple
5. Représentations superposées des individus « vus » par chacun des groupes. Un individu considéré du point de vue d’un seul groupe est dit individu partiel (parallèlement, un individu considéré du point de vue de l’ensemble des variables est dit individu moyen car il est au barycentre de ses points partiels). Le nuage partiel rassemble les individus du point de vue du seul groupe (soit ) : c’est le nuage analysé dans l’analyse factorielle (ACP ou ACM) séparée du groupe . La représentation superposée des fournie par l’AFM est analogue, dans sa finalité, à celle fournie par l’analyse procustéenne.


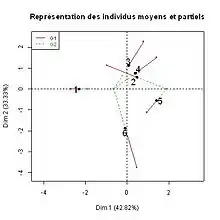
Dans l’exemple (figure 3), l’individu 1 est caractérisé par une petite taille (= petites valeurs) aussi bien du point de vue du groupe 1 que de celui du groupe 2 (les points partiels de l’individu 1 ont une coordonnée négative et sont proches). En revanche, l’individu 5 est plus caractérisé par des grandes valeurs pour les variables du groupe 2 que pour les variables du groupe 1 (pour l’individu 5, le point partiel du groupe 2 est plus éloigné de l’origine que celui du groupe 1). Cette interprétation faite à partir du graphique peut être validée directement dans les données.
6. Représentations des groupes de variables en tant que tels. Dans ces graphiques, chaque groupe de variables est représenté par un point. Deux groupes de variables sont d’autant plus proches qu’ils définissent la même structure sur les individus : à la limite, deux groupes de variables qui définissent des nuages d’individus homothétiques sont confondus. La coordonnée du groupe le long de l’axe est égale à la contribution du groupe à l’inertie du facteur de rang de l’AFM. Cette contribution peut s’interpréter comme un indicateur de liaison (entre le groupe et l’axe de rang , d’où le nom de carré des liaisons donné à ce type de représentation). Cette représentation existe aussi dans d’autres méthodes factorielles (ACM et AFDM en particulier) auquel cas les groupes de variables sont réduits chacun à une seule variable.


Dans l’exemple (figure 4), cette représentation montre que le premier axe est lié aux deux groupes de variables alors que le deuxième axe n’est lié qu’au premier groupe. Ceci est bien en accord avec la représentation des variables (figure 2). En pratique, cette représentation est d’autant plus précieuse que les groupes sont nombreux et comportent beaucoup de variables.
Autre grille de lecture. Les deux groupes de variables ont en commun l’effet taille (premier axe) et diffèrent selon l’axe 2 puisque celui-ci est spécifique du groupe 1 (il oppose les variables A et B).
7. Représentations des facteurs des analyses séparées des différents groupes. Ces facteurs sont représentés comme des variables quantitatives supplémentaires (cercle des corrélations).

Dans l’exemple (figure 5), le premier axe de l’AFM est assez fortement corrélé (r = .80) au premier axe du groupe 2. Ce groupe, étant constitué de deux variables identiques, ne comporte qu’une seule composante principale (confondue avec la variable). Le groupe 1 est constitué de deux variables orthogonales : toute direction du sous-espace engendré par ces deux variables présente la même inertie (égale à 1). Il y a donc indétermination dans le choix des composantes principales et il n’y a aucune raison de s’intéresser à l’une d’entre elles en particulier. Cela étant, les deux composantes fournies par le programme sont bien représentées : le plan de l’AFM est voisin du plan engendré par les deux variables du groupe 1.
Conclusion
L’exemple numérique illustre les sorties de l’AFM. Outre l’équilibre entre les groupes de variables et les graphiques usuels de l’ACP (et de l’ACM dans le cas de variables qualitatives), l’AFM fournit des résultats spécifiques de la structure en groupes définis sur les variables soit, en particulier :
- Une représentation superposée des individus partiels permettant une analyse fixe des résultats ;
- Une représentation des groupes de variables fournissant une image synthétique des données d’autant plus précieuse que des données comportent de nombreux groupes ;
- Une représentations des facteurs des analyses séparées.
La petite taille et la simplicité de l’exemple permettent de valider aisément les règles d’interprétation. Mais la méthode sera d’autant plus précieuse que les données sont volumineuses et complexes. D’autres méthodes adaptées à ce type de données existent. Certaines d’entre elles (Statis, analyse procustéenne) sont comparées à l’AFM dans Le Barzic et al. 1996 et/ou dans Pagès 2013.
Historique
L'AFM a été mise au point par Brigitte Escofier et Jérôme Pagès dans les années 1980. Elle est au cœur des deux livres écrits par ces auteurs : Escofier & Pagès, 2008 et Pagès 2013. L'AFM et ses extensions (AFM hiérarchique, AFM sur tableaux de contingence, etc.) sont un sujet de recherche du laboratoire de mathématiques appliques d'Agrocampus (LMA²)
Logiciels
L’AFM est disponible dans deux packages R (FactoMineR et ADE 4) et dans de nombreux logiciels : SPAD, Uniwin, XLSTAT, etc. Il existe aussi une fonction SAS. Les graphiques de cet article proviennent du package R FactoMineR.
Références
- Brigitte Escofier et Jérôme Pagès, Analyses factorielles simples et multiples : objectifs, méthodes et interprétation, Paris, Dunod, Paris, , 318 p. (ISBN 978-2-10-051932-3)
- François Husson, Sébastien Lê et Jérôme Pagès, Analyse des données avec R, Presses Universitaires de Rennes, , 224 p. (ISBN 978-2-7535-0938-2)
- Jean-François Le Barzic, Frédéric Dazy, Françoise Lavallard et Gilbert Saporta, L'analyse des données évolutives. : Méthodes et applications., Technip, Paris, , 227 p. (ISBN 978-2-7108-0700-1)
- Jérôme Pagès, Analyse factorielle multiple avec R, Les Ulis, EDP sciences, Paris, , 253 p. (ISBN 978-2-7598-0963-9)
Liens externes
- FactoMineR, une bibliothèque de fonctions R destinée à l'analyse des données.
- Fonction SAS pour l'AFM
 Portail des probabilités et de la statistique
Portail des probabilités et de la statistique  Portail de l’informatique
Portail de l’informatique