Deep packet inspection
L'inspection profonde de paquets ou en anglais Deep Packet Inspection, abrégée IPP ou DPI est une technique d'analyse des flux passant dans des équipements réseau au-delà de l'entête. L'équipement recherche des informations dans la charge utile des paquets plutôt que dans les entêtes (à l'inverse des approches classiques). Des signatures sont le plus souvent recherchées pour détecter des types de flux et agir en conséquence. Il existe plusieurs domaines d'applications : priorisation ou ralentissement de flux particuliers, censure, détection d'intrusion. L'inspection est mise en œuvre par des gouvernements, des FAI et des organisations à ces fins.
L'inspection peut fortement ralentir le trafic là où elle est utilisée, cela est dû à la grande puissance de calcul nécessaire pour gérer un trafic important. Pour pallier ce problème, plusieurs solutions sont proposées tant au niveau logiciel que matériel. L'IPP soulève aussi des questions quant au respect de la vie privée. En effet, les différents acteurs analysent le contenu du trafic, et ce avec différents objectifs.
Technologie
L'IPP amène de gros problèmes de ralentissement du trafic. Une grande quantité de calcul et de mémoire est nécessaire pour traiter efficacement des grandes quantités de paquets. Plusieurs solutions sont apportées, au niveau logiciel et matériel.
Algorithmique
Les outils d'IPP recherchent des signatures d'applications connues en utilisant des ensembles d'expressions régulières. Les expressions régulières utilisées par des systèmes de détection d'intrusion consistent généralement en un ensemble de patterns contenant: de simples chaines de caractère, des plages de caractères, jokers, des sous-patterns se répétant indéfiniment ou un certain nombre de fois[1]. Ces expressions sont transcrites en automates et nécessitent de grandes quantités de mémoire et de puissance de calcul. Les optimisations possibles sont donc la diminution de l'empreinte mémoire et de la puissance de calcul nécessaire ou la répartition de celle-ci.
Automates
Les expressions régulières peuvent être traduites en automates de deux types: des Automates finis déterministes (AFD) et des Automates finis non déterministes (AFND). Leurs différences résident dans le fait que dans un automate déterministe, un symbole ne déclenche qu'une seule transition depuis un état. Dans un automate non déterministe, un même symbole peut déclencher plusieurs transitions vers un état. Le schéma ci-contre représente un automate déterministe pour l'expression abcd.

Les automates déterministes présentent plusieurs avantages. Premièrement, une chaîne de caractères ne fera qu'un passage dedans. Chaque symbole ne déclenchant qu'un changement d'état, les accès à la mémoire sont donc déterministes. Ensuite une expression régulière peut être traduite en automate fini avec un nombre minimum d'états[2]. Cependant ceux-ci ont tendance à augmenter fortement en agrégeant des ensembles d'expressions. Le schéma ci-contre représente un automate non déterministe pour l'expression a*ba*
Les automates non déterministes quant à eux demandent moins d'espace mémoire mais une plus grande puissance de calcul ainsi que des accès mémoires variables [3]. Tout automate non déterministe peut être transformé en déterministe souvent au prix d'une explosion des états[4].

Le tableau suivant représente la complexité et le coût en mémoire pour un automate fini déterministe et non déterministe pour une expression régulière de taille n[5].
| Complexité | Coût en mémoire | |
|---|---|---|
| Non déterministe | O(n²) | O(n) |
| Déterministe | O(1) | O(Σn) |
Des patterns imbriqués dans des expressions provoquent des retours en boucle dans les automates correspondant[1].
Pour exemple, La règle Snort User-Agent\x3A[^\r\n]*ZC-Bridge, recherche une occurrence du sous pattern «ZC-Bridge» seulement si «User-Agent\x3A» a été précédemment rencontré et qu'il n'y a pas eu de retour à la ligne entre. Ces patterns affectent les transitions dans les automates déterministes mais pas dans le nombre d'états[6].
Les automates finis qui correspondent à des ensembles de règles de systèmes de détection d'intrusion ont une grande redondance de changements d'état[1].
Cependant quand on combine plusieurs expressions il y a une forte augmentation du nombre d'états. Surtout si une expression contient une condition .*correspondant à n'importe quel caractère un nombre arbitraire de fois. En effet si on considère deux expressions R1 et R2, R2 contenant une condition .*. En combinant les deux sous la forme .*(R1|R2), l'automate correspondant à R1 sera répliqué dans la condition .* de R2. En combinant les expressions on aura donc une augmentation linéaire du nombre d'états en fonction du nombre de conditions .* [7].
Les contraintes de nombres de caractères de type ab.{3}cd causent quant à elle une augmentation exponentielle du nombre d'état[7]. La situation empire encore en les combinant avec des .*.
Bien que les automates finis ont l'avantage de trouver une certaine séquence en un temps linéaire, quand ils subissent une explosion d'états ils ne sont, bien souvent, pas représentables.
Une solution pour éviter cette explosion est de construire l'automate déterministe découlant d'un automate non déterministe et d'interrompre lorsqu'une augmentation d'états apparait. Dans le cas précédent c'est dans la condition .* de R2 que l'on peut retrouver ça. L'automate alors créé est dit hybride, il possède plusieurs propriétés intéressantes [8] :
- l'état de départ est déterministe ;
- les parties non déterministes ne seront évaluées qu'en arrivant en bordure ;
- en revenant de la partie non déterministe, il n'y aura pas de rétroactivation de la partie déterministe.
Grâce à cette technique, on arrive donc à représenter la majeure partie de l'automate de façon déterministe, réduisant les accès mémoire. Cependant l'empreinte mémoire de l'automate créé peut être réduite avec plusieurs méthodes de compression selon la partie (déterministe ou pas).
La première solution consiste à simplement modifier l'expression régulière selon deux façons:
- Il est possible de transformer
^A+[A-Z]{j}" en "^A[A-Z]{j}[9]. La taille de l'automate résultant en est grandement réduite. Pour exemple l'expression^SEARCH\s+[^\n]{1024}(utilisée par Snort) génère un automate de taille quadratique du a des plages de caractères qui se chevauchent (\set^\n)[10] En la transformant en^SEARCH\s[\n]{1024}; - Utiliser des classes d'exclusions[9]. Pour exemple l'expression
.*AUTH\s[^\n]{100}peut être transformée en([^A]|A[^U]|AU[^T]|AUT[^H]|AUTH[^\s]|AUTH\s[^\n]{0,99}\n)*AUTH\s[^\n]{100}. La règle énumère premièrement tous les mauvais cas et quand l'automate atteint la partie suivante, il y aura d'office une correspondance[9].
La fusion d'états est une deuxième solution. Deux états ayant une transition sur des états communs peuvent être fusionnés. Et cela même si certaines transitions diffèrent[11]. Pour le fonctionnement de ce système il faut ajouter un label aux entrées des états afin de différencier quel est le nœud d'origine et ainsi en déduire les données d'entrées de l'état suivant. De plus des états fusionnés peuvent amener d'autres possibilités de rassemblement[11].
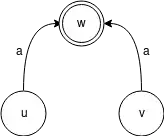
Les automates déterministes finis à retard d'entrée sont une autre réponse aux problèmes de quantité de mémoire malheureusement ils viennent avec un compromis au niveau des accès à celle-ci[12]. Cette technique définit un principe de transition par défaut, il ne peut y en avoir qu'une seule par nœud, il faut donc la choisir avec soin [13]. Dans l'exemple suivant, si on ajoute une transition par défaut de u vers v on peut supprimer la transition de u vers w sans changer le comportement de l'automate.
Il est encore possible d'optimiser ces derniers avec les automates finis à retard d'entrée avec label de contenu. Les numéros d'états sont alors remplacés par des labels de contenu. Dans une implémentation classique, les états sont identifiés par un nombre référençant une entrée dans une table contenant les informations du nœud. Ici, une partie du contenu de la table est donc stockée dans le label de l'état [14]. Cette dernière technique de compression peut être appliquée sur des automates déterministes et peut être adaptée pour les non déterministes[15].
Toutes ces optimisations permettent de réduire l'empreinte mémoire (bande passante et quantité) ainsi que la puissance de calcul nécessaire pour des automates. Ceux-ci seront utilisés dans des logiciels (Snort, Bro/Zeek...) ou bien dans du matériel dédié.
Context Based DPI
L'inspection de paquet profonde basée sur le contexte ou context based deep packet inspection (CDPI) est une forme d'IPP qui ne se contente pas juste d'analyser les paquets les uns à la suite des autres. Il a pour objectif d'analyser le flux de paquet pour en extraire des informations. Cela permet de s'affranchir de l'analyse de l'information du paquet elle-même tout en obtenant l'information générale.
Exemple d'utilisation du context bases deep packet inspection : la détection de la première phase d'échange de clés d'IPsec[16]. L'analyse d'un paquet seul via le DPI classique ne permet pas de connaitre le protocole utilisé. Or, l'utilisation du CDPI permet non seulement de repérer la phase d'échange de clé d'IPsec, mais aussi de savoir si les messages sont légitimes ou une imitation. De plus, on peut afficher l'intégralité de la première phase d'échange. De ce fait, le CDPI peut être une bonne approche pour s'assurer de l'intégrité et de la validité de la phase d'échange de clés.
MapReduce
L'émergence de réseaux à haute vitesse tel que 20/40 Gbit/s Ethernet et au-delà requièrent une analyse rapide d'un large volume de trafic réseau. Bien que la plupart des FAI agrègent le trafic de multiples routeurs vers un gros serveur avec beaucoup de stockage. Des compromis sont faits pour être capables de gérer du trafic à l'échelle d'un pays : agrégation des flux, résumé des paquets, etc[17]. Le tout au prix de grosses latences. De plus la tolérance aux pannes est très faible et le passage à l’échelle compliqué. On se rend donc bien vite compte que cette tâche est au-delà des capacités d'une seule machine [18]. L'analyse à la volée de liens à haute vitesse demande un compromis entre précision, temps, consommation de ressources et coût[18]. Ce n'est pas une tâche triviale pour une seule machine car la correspondance de patterns dans l'IPP est généralement implémentée en espace utilisateur et requiert beaucoup de puissance processeur. Cela provoque un haut niveau de perte de paquets[18].
C'est alors qu'est venue l'idée d'utiliser MapReduce un nouveau paradigme de programmation qui permet de répartir le traitement sur plusieurs machines augmentant ainsi la puissance de calcul disponible, cette façon de faire amène aussi un haut niveau d'abstraction et une bonne tolérance aux pannes. La bibliothèque Hadoop créée par Yahoo en est une implémentation, elle regroupe deux éléments essentiels: la répartition du calcul sur des groupes de machines et la répartition du stockage via HDFS. Les calculs sont divisés en trois phases : mapping, shuffle et reduce. La première consiste à définir des couples de clefs/valeurs. Après celle-ci on regroupe les clefs similaires (Shuffle) et on finit par réduire de plusieurs façons possibles : somme, moyenne, comptage... Tout ces travaux peuvent s'exécuter sur des machines différentes. On voit donc que le logiciel est bien adapté pour l'analyse de grandes quantités de trafic à la volée de façon distribuée.
Les premières implémentations utilisaient donc la bibliothèque Hadoop. Les multiples flux Netflow envoyés par les routeurs sont collectés sur les nœuds par flow-tools. Ils sont ensuite transformés en fichiers texte (format supporté par Hadoop) et placés sur le système de fichier HDFS à intervalle régulier[19]. Chaque ligne est généralement composée d'un marqueur temporel, les adresses et ports source et destination, le protocole utilisé, les différents flags ainsi que le contenu des paquets[20]. L'opération de mapping dépend de l'analyse qui veut être faite sur les flux. Un simple exemple est de calculer la somme des octets pour un port, pour cela on créerait des couples numéro port → nombre d'octets. Les couples ayant les mêmes clefs sont ensuite regroupés et sommés pour récupérer le total. Les résultats sont écrits sur le système de fichiers ou dans une base de données.
Cependant cette implémentation ne permet pas de mettre en œuvre l'IPP en temps réel. Le découpage en phases bloquantes de Hadoop où le réducteur ne peut pas démarrer avant que toutes les opérations de mapping ne soient terminées amène un blocage au niveau des performances[21]. De plus l'écriture des résultats intermédiaires sur disque entre les phases crée un goulot d'étranglement sur les entrées/sorties[21].
Des implémentations plus adaptées ont été créées tel que StreamMine3G. C'est un moteur orienté Complex event processing[22]. Le système proposé est divisé en quatre phases : la capture de paquets, la génération du flux, sa classification, son analyse et sa présentation. Ces 4 phases sont organisées sous forme de pipeline[23]. Les phases peuvent bien sûr être distribuées sur plusieurs machines. Cette implémentation offre plusieurs avantages par rapport à Hadoop. Premièrement les phases ne sont pas bloquantes, des réducteurs peuvent démarrer même si tous les mappers n'ont pas terminé leurs opérations. Ensuite, les résultats intermédiaires sont gardés en mémoire vive plutôt que sur le disque; Ceci amène un gros gain en performances. Là où Hadoop adopte une approche de stockage/traitement StreamMine3G s'oriente vers du traitement en temps réel avec peu de latence [22] où les différents opérateurs sont reliés sous forme de graphe acyclique et traitent les données à la volée[24].
Le dernier écueil dans l'utilisation de Hadoop pour l'IPP sur la dorsale de l'Internet est son système de répartition des données. Bien que celui-ci offre de très bonnes capacités de tolérance aux pannes, de redondance et répartition; il découpe les données en sous-ensembles répartis sur les différentes machines de façon à les distribuer de façon équitable pour que les nœuds aient plus ou moins le même temps de traitement. Le problème de cette approche est que l'on perd le contexte, certaines tendances et anomalies sur des réseaux à très haut trafic ne peuvent être détectées que lorsque les paquets sont analysés ensemble. En découpant un sous-ensemble de paquets, il est donc beaucoup plus compliqué de découvrir des tendances[25].
Les systèmes de détection utilisent généralement une fenêtre de temps, s'il y a plus de X paquets dans un certain temps, une anomalie est remontée. En découpant de façon égale, on se base plutôt sur le nombre de paquets et on diminue donc la fenêtre de temps dans un sous-ensemble. Deux paquets d'un même flux peuvent se retrouver dans deux ensembles différents (Problème de temporalité). Enfin si du trafic émanant d'un même hôte ou réseau est réparti dans plusieurs sous-groupes, il est compliqué de découvrir les tendances si elles sont divisées (Problème de spacialisation)[26].
Pour répondre à cette problématique, un système de hachage peut être mis en place. Pour chaque paquet disponible dans une capture, les mappers calculent deux hashs pour définir dans quel collecteur le résultat sera stocké. Les deux méthodes sont (où N est le nombre de collecteurs par technique de hachage) :
- Un hachage de l'adresse source % N;
- (Un hachage de l'adresse de destination % N) + N.
Chaque mapper émet donc deux paires de clef-valeur. La clef est composée du hash et du marquage temporel, la valeur est le paquet associé. L'opération de shuffle sépare les paquets en 2N collecteurs et trie les paquets par ordre chronologique dans ceux-ci. Enfin les réducteurs lisent un collecteur à la fois et les écrivent dans le système de fichiers en un morceau[27].
Les fichiers créés pourront être utilisés par d'autres jobs MapReduce pour détecter des anomalies. Grâce au prédécoupage, il est plus simple de les repérer; Les données seront par contre réparties moins équitablement (un collecteur pouvant être plus grand qu'un autre).
Hardware
Les implémentations des automates peuvent être programmées de façon logicielle mais pour pousser l'optimisation et les gains de performances, il est possible d'utiliser des solutions matérielles dédiées. Elles n'offrent cependant pas la flexibilité des solutions logicielles.
FPGA/ASIC
Les FPGA permettent l'optimisation de l'IPP grâce à la mise en place d'algorithmes de correspondance de chaînes de caractères ou d'automates grâce à l'implémentation de ces algorithmes directement en circuit logique.
L'implémentation des Automates Finis Non déterministe (AFND) en portes logiques est une bonne méthode pour obtenir un gain de performance. Chaque état de l'automate est une bascule, que ce soit un automate fini non déterministe ou un automate fini déterministe. La différence qui caractérise l'AFND, à savoir plusieurs branches de sortie vers différents états, sera représentée en logique par une sortie de bascule qui peut être connectée à plusieurs entrées d'autres bascules[28].
Différentes structures logiques seront utilisées pour l'implémentation des AFND. Pour comparer deux caractères entre eux, un ET est utilisé entre deux tables de correspondance (ou Lookup Table) contenant la représentation ASCII des caractères. Ensuite, pour la construction de l'automate, on associe le résultat de cette correspondance avec un ET à la bascule de l'état associé à cette comparaison. Les bascules sont chaînées entre elles pour s'activer les unes à la suite des autres dans l'ordre voulu[29].
La construction de l'automate fini non déterministe prend un temps de construction que ce soit en FPGA ou avec un ordinateur classique. L'utilisation de FPGA permet un gain de temps dans ce domaine. Si l'on veut que le traitement d'un caractère ait un coût en temps de l'ordre de O(1) cycles d'horloge, le temps de construction pour une FPGA sera de l'ordre de O(n) tandis que celui d'une machine séquentielle sera de l'ordre de O(2n)[30].
L'utilisation de FPGA permet un gain d'espace par rapport à l'utilisation d'une machine séquentielle. En effet, pour le traitement d'une expression régulière de longueur n, un ordinateur classique aura besoin de O(2n) de mémoire et aura une complexité en temps de O(1) pour le travail effectué sur un caractère. Tandis que du côté des FPGA, la complexité en temps sera identique mais n'aura besoin que O(n²) de mémoire, ce qui est un gain non négligeable[31].
Usage
Les usages de l'inspection de paquet profonde sont multiples, et peuvent survenir dans plusieurs domaines d'application :
- Le P2P : du fait de l'utilisation de port aléatoire et de la signature placée dans la charge utile plutôt que dans l'en-tête, il peut être difficile de détecter le P2P avec un pare-feu classique. Cependant, il est tout de même possible de le faire grâce à l'IPP[32];
- La qualité de service : l'IPP peut servir pour assurer de la qualité de service. En effet, pouvoir identifier précisément quel type de contenu passe permet de sélectionner quel contenu aura la priorité sur les autres. Cela peut servir en entreprise pour s'assurer que certains services disposent de la bande passante nécessaire, ou pour les fournisseurs d'accès à internet afin de vendre la bande passante pour certains sites web.
Société
L'inspection profonde de paquets a de grosses implications au niveau sociétal. En effet les données analysées étant pour la plupart privées, l'IPP pose des questions juridiques quant à la protections de ces données.
Juridique
Le domaine étant assez récent, il existe un flou juridique. Les lois selon les pays diffèrent et sont appliquées de manière disparate.
Copyright
L'inspection de paquet profonde peut être utilisé à des fins de protection de la propriété intellectuelle. En effet, le trafic P2P, qui est fortement utilisé pour l'échange illégal de fichiers protégés par la propriété intellectuelle, peut être détecté via l'IPP[32].
L'usage du l'IPP a été envisagé par le Parlement néerlandais dans un rapport de 2009 en tant que mesure qui aurait été ouverte aux parties tiers pour renforcer la surveillance du respect de la propriété intellectuelle, visant plus particulièrement à réprimer le téléchargement de contenu protégé sous copyright. À la suite de critiques émanant d'ONG, cette proposition devrait être abandonnée[33].
Législation
L'article 66 de l'autorité des télécommunications de la République populaire de Chine qui a été promulguée en 2000 stipule que «La liberté et la vie privée des utilisateurs légaux des télécommunications sont protégées par la loi. Aucune organisation ou personne ne peut inspecter le contenu des communications pour n'importe quelle raison»[34].
Vie privée
L'inspection de paquet profonde peut avoir un impact sur la vie privée. En effet, il s'est avéré qu'il est utilisé dans l'espionnage des habitudes des usagers[35].
FAI
L'inspection profonde de paquet peut servir d'outil aux fournisseurs d'accès à internet (FAI). En effet, ceux-ci peuvent être tentés d'utiliser l'IPP afin de mettre en place de la publicité ciblée [36], d'améliorer la qualité du service ou encore de mettre en place un filtrage d'application [36] ou de sites web à des fins commerciales. Ce dernier point remet en cause la neutralité du réseau[35].
En Belgique en 2011, la Sabam a découvert que les utilisateurs Scarlet utilisaient le réseau en pair-à-pair pour partager du contenu avec des droits d'auteurs. L'organisme demanda au tribunal de Bruxelles d'ordonner à Scarlet de bloquer les utilisateurs désirant distribuer du contenu violant les droits d'auteurs[37]. Bien que la décision fut approuvée par le tribunal, elle fût rejetée en cour d'appel car celle-ci fit appel à la Cour de Justice de l'Union Européenne. Dû a une réponse ambigüe en rapport avec l'article 15 de la directive e-commerce, la motion ne fut pas acceptée.
Du côté de la Chine, l'usage de l'IPP est théoriquement interdit par la loi. Pourtant, les FAI ont déployé des technologies d'inspection profonde sans intervention du gouvernement[34].
État
En Chine, la plupart des fournisseurs d'accès à internet sont la propriété du gouvernement. De ce fait, les données récoltées par les FAI chinois sont en fait récupérées par le gouvernement, qui ne respecte pas la loi en vigueur[34].
Depuis 1996 au Royaume-Uni, l'IWF (Internet Watch Foundation) un organisme fondé par l'Union Européenne et les acteurs de l'Internet, a développé une ligne téléphonique pour recevoir des plaintes en rapport avec de la pédopornographie. Si la plainte était avérée, elle était transférée à la police et l'hébergeur était tenu de retirer le contenu. Malgré cela, si le matériel était hébergé à l'étranger l'opération n'était pas possible[38].
C'est alors que British Telecom développa une solution nommée Cleanfeed avec des acteurs privés de l'Internet et l'Union Européenne. Le but était dans une première phase de détecter les adresses suspicieuses. Si une telle requête était détectée, elle passait par un proxy appliquant des filtres de l'IPP. Et, si un contenu illégal était détecté, une erreur HTTP 404 était renvoyée. C'était le premier usage de l'IPP à grande échelle dans une démocratie occidentale. Aucune information sur les utilisateurs n'étaient cependant stockée[36]. La principale critique émise par rapport à ce système est la quantité de pouvoir donnée à un organisme privé[39].
La polémique vint quand en 2008, l'URL de Wikipédia fut insérée dans la base de données de Cleanfeed. Cela était dû à une pochette d'album du groupe Scorpions, Virgin Killer, celui-ci portant une image d'enfant. L'album était pourtant en vente depuis 1976. Les requêtes vers Wikipédia étaient donc redirigées vers le proxy et la page du groupe bloquée durant 4 jours avant le retrait de Wikipédia de la liste des sites suspicieux[36].
Voir aussi
Références
- Becchi 2007, p. 2
- Holzer 2010, p. 10
- Pao 2013, p. 1256
- Hopcroft 1979, p. 61
- Fang 2006, p. 95
- Becchi 2007, p. 3
- Becchi 2007, p. 4
- Becchi 2007, p. 5
- Fang 2006, p. 98
- Fang 2006, p. 97
- Becchi 2007, p. 1067
- Kumar 2006, p. 340
- Kumar 2006, p. 342
- Kumar 2006, p. 82
- Becchi 2007, p. 9
- Zhuli 2010, p. 3
- Lee 2010, p. 357
- Le Quoc 2013, p. 446
- Lee 2010, p. 358
- Lee 2010, p. 359
- Le Quoc 2013, p. 447
- Brito 2013, p. 1014
- Le Quoc 2013, p. 448
- Brito 2013, p. 1015
- Fontugne 2014, p. 494
- Fontugne 2014, p. 495
- Fontugne 2014, p. 496
- Reetinder 2001, p. 228
- Reetinder 2001, p. 229
- Reetinder 2001, p. 230
- Reetinder 2001, p. 237
- Wang 2009, p. 1
- EDRI, Dutch copyright working group strikes deep packet inspection, 21 avril 2010
- Yang 2015, p. 350
- Roth 2013, p. 284
- Stalla-Bourdillon 2014, p. 675
- Stalla-Bourdillon 2014, p. 676
- Stalla-Bourdillon 2014, p. 674
- Davies 2009, p. 1
Bibliographie
- (en) Alfred V. Aho et Margaret J. Corasick, « Efficient string matching: an aid to bibliographic search », Magazine Communications of the ACM, vol. 18, no 6, , p. 333-340 (DOI 10.1145/360825.360855)
- (en) Rodrigo Braga, Edjard Mota et Alexandre Passito, « Lightweight DDoS flooding attack detection using NOX/OpenFlow », 35th Annual IEEE Conference on Local Computer Networks, , p. 408-415 (ISBN 978-1-4244-8389-1, DOI 10.1109/LCN.2010.5735752)
- (en) Christian Roth et Rolf Schillinger, « Detectability of Deep Packet Inspection in common provider/consumer relations », 25th International Workshop on Database and Expert Systems Applications, , p. 283-287 (ISBN 978-1-4799-5722-4, DOI 10.1109/DEXA.2014.64)
- (en) Piti Piyachon et Yan Luo, « Efficient memory utilization on network processors for deep packet inspection », 2006 Symposium on Architecture For Networking And Communications Systems, , p. 71-80 (ISBN 978-1-59593-580-9, DOI 10.1145/1185347.1185358)
- (en) Meng Zhuli, Li Wenjing et Gao ZhiPeng, « Context-based Deep Packet Inspection of IKE Phase One Exchange in IPSec VPN », 2010 International Conference on Innovative Computing and Communication and 2010 Asia-Pacific Conference on Information Technology and Ocean Engineering, , p. 3-6 (ISBN 978-1-4244-5635-2, DOI 10.1109/CICC-ITOE.2010.8)
- (en) Sorin Zoican et Roxana Zoican, « Intrusive detection system implementation using deep packet inspection », 2013 11th International Conference on Telecommunications in Modern Satellite, Cable and Broadcasting Services (TELSIKS), , p. 413-416 (ISBN 978-1-4799-0902-5, DOI 10.1109/TELSKS.2013.6704411)
- (en) Ning Wenga, Luke Vespaa et Benfano Soewitob, « Deep packet pre-filtering and finite state encoding for adaptive intrusion detection system », Computer Networks 55 Issue 8, , p. 1648-1661 (DOI 10.1016/j.comnet.2010.12.007)
- (en) Michela Becchi et Patrick Crowley, « A Hybrid Finite Automaton for Practical Deep Packet Inspection », Proceeding CoNEXT '07 Proceedings of the 2007 ACM CoNEXT conference, (ISBN 978-1-59593-770-4, DOI 10.1145/1364654.1364656)
- (en) Michela Becchi et Patrick Crowley, « An Improved Algorithm to Accelerate Regular Expression Evaluation », ANCS '07 Proceedings of the 3rd ACM/IEEE Symposium on Architecture for networking and communications systems, , p. 145-154 (ISBN 978-1-59593-945-6, DOI 10.1145/1323548.1323573)
- (en) Sailesh Kumar, Jonathan Turner et John Williams, « Advanced algorithms for fast and scalable deep packet inspection », ANCS '06 Proceedings of the 2006 ACM/IEEE symposium on Architecture for networking and communications systems, , p. 81-92 (ISBN 1-59593-580-0, DOI 10.1145/1185347.1185359)
- (en) Terry Nelms et Mustaque AhamadYang2015, « Packet scheduling for deep packet inspection on multi-core architectures », 2010 ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), (ISBN 978-1-4503-0379-8, DOI 10.1145/1872007.1872033)
- (en) Feng Yang, « The tale of deep packet inspection in China: Mind the gap », 2015 3rd International Conference on Information and Communication Technology (ICoICT), , p. 348-351 (ISBN 978-1-4799-7752-9, DOI 10.1109/ICoICT.2015.7231449)
- (en) Do Le Quoc, André Martin et Christof Fetzer, « Scalable and Real-Time Deep Packet Inspection », 2013 IEEE/ACM 6th International Conference on Utility and Cloud Computing, , p. 446-451 (ISBN 978-0-7695-5152-4, DOI 10.1109/UCC.2013.88)
- (en) Harish Muhammad Nazief, Tonny Adhi Sabastian, Alfan Presekal et Gladhi Guarddin, « Development of University of Indonesia next generation firewall prototype and access control with deep packet inspection », 2014 International Conference on Advanced Computer Science and Information System, , p. 47-52 (ISBN 978-1-4799-8075-8, DOI 10.1109/ICACSIS.2014.7065869)
- (en) Rafael Antonello, Steni Fernandes, Carlos Kamienski, Djamel Sadok, Judith Kelner, István Gódor, Géza Szabó et Tord Westholm, « Deep packet inspection tools and techniques in commodity platforms: Challenges and trends », Journal of Network and Computer Applications, vol. 35, no 6, , p. 1863-1878 (DOI 10.1016/j.jnca.2012.07.010)
- (en) Jon M. Peha et Alexandre M. Mateus, « Policy implications of technology for detecting P2P and copyright violations », Telecommunications Policy, vol. 38, no 1, , p. 66-85 (DOI 10.1016/j.telpol.2013.04.007)
- (en) Ralf Bendrath et Milton Mueller, « The end of the net as we know it? Deep packet inspection and internet governance », New Media & Society, vol. 13, no 7, , p. 1142-1160 (DOI 10.1177/1461444811398031)
- (en) Ben Wagner, « Deep Packet Inspection and Internet Censorship: International Convergence on an 'Integrated Technology of Control' », SSRN, (DOI 10.2139/ssrn.2621410)
- (en) Eric H. Corwin, « Deep Packet Inspection: Shaping the Internet and the Implications on Privacy and Security », Information Security Journal: A Global Perspective, vol. 20, no 6, , p. 311-316 (ISSN 1939-3555, DOI 10.1080/19393555.2011.624162)
- (en) Ralf Bendrath, « Global technology trends and national regulation: Explaining Variation in the Governance of Deep Packet Inspection », International Studies Annual Convention New York City,
- (en) John Hopcroft et Jeffrey Ullman, Introduction to Automata Theory, Languages, and Computation, , 537 p. (ISBN 0-201-02988-X), p. 2.3
- (en) Markus Holzer et Andreas Maletti, « An nlogn algorithm for hyper-minimizing a (minimized) deterministic automaton », Theoretical Computer Science, vol. 411, , p. 3404-3413 (ISSN 0304-3975, DOI 10.1016/j.tcs.2010.05.029)
- (en) Sailesh Kumar, Sarang Dharmapurikar, Fang Yu, Patrick Crowley et Jonathan Turner, « Algorithms to accelerate multiple regular expressions matching for deep packet inspection », ACM SIGCOMM Computer Communication Review, vol. 36, , p. 339-350 (ISSN 0146-4833, DOI 10.1145/1151659.1159952)
- (en) Fang Yu, Zhifeng Chen, Yanlei Diao, T. V. Lakshman et Randy H. Katz, « Fast and memory-efficient regular expression matching for deep packet inspection », ANCS '06 Proceedings of the 2006 ACM/IEEE symposium on Architecture for networking and communications systems, , p. 93-102 (ISBN 1-59593-580-0, DOI 10.1145/1185347.1185360)
- (en) Reetinder Sidhu et Viktor Prasanna, « Fast Regular Expression Matching Using FPGAs », The 9th Annual IEEE Symposium on Field-Programmable Custom Computing Machines, , p. 227-238 (ISBN 0-7695-2667-5)
- (en) Michela Becchi et Srihari Cadambi, « Memory-Efficient Regular Expression Search Using State Merging », IEEE INFOCOM 2007 - 26th IEEE International Conference on Computer Communications, , p. 1064-1072 (ISBN 1-4244-1047-9, ISSN 0743-166X, DOI 10.1109/INFCOM.2007.128)
- (en) Chunzhi Wang, Xin Zhou, Fangping You et Hongwei Chen, « Design of P2P Traffic Identification Based on DPI and DFI », 2009 International Symposium on Computer Network and Multimedia Technology, , p. 1-4 (DOI 10.1109/CNMT.2009.5374577)
- (en) Jin Qu, Rongcai Zhao, Peng Liu, Zishuang Li et Qin Li, « A delayed input DFA optimized algorithm of bounding default path », 2011 IEEE International Conference on Computer Science and Automation Engineering, vol. 4, , p. 702-705 (ISBN 978-1-4244-8727-1, DOI 10.1109/CSAE.2011.5952942)
- (en) Sailesh Kumar, Sarang Dharmapurikar, Fang Yu, Patrick Crowley et Jonathan Turner, « Algorithms to accelerate multiple regular expressions matching for deep packet inspection », ACM SIGCOMM Computer Communication Review, vol. 36, , p. 339 (ISBN 1-59593-308-5, DOI 10.1145/1151659.1159952)
- (en) Youngseok Lee, Wonchul Kang et Hyeongu Son, « An Internet traffic analysis method with MapReduce », 2010 IEEE/IFIP Network Operations and Management Symposium Workshops, , p. 357-361 (ISBN 978-1-4244-6037-3, DOI 10.1109/NOMSW.2010.5486551)
- (en) Thiago Vieira, Paulo Soares, Marco Machado, Rodrigo Assad et Vinicius Garcia, « Evaluating Performance of Distributed Systems With MapReduce and Network Traffic Analysis », ICSEA 2012 : The Seventh International Conference on Software Engineering Advances, , p. 705-802 (ISBN 978-1-61208-230-1)
- (en) Romain Fontugne, Johan Mazel et Kensuke Fukuda, « Hashdoop: A MapReduce framework for network anomaly detection », 2014 IEEE Conference on Computer Communications Workshops, , p. 494-499 (ISBN 978-1-4799-3088-3, DOI 10.1109/INFCOMW.2014.6849281)
- (en) Sophie Stalla-Bourdillon, Evangelia Papadaki et Tim Chown, « From porn to cybersecurity passing by copyright: How mass surveillance technologies are gaining legitimacy … The case of deep packet inspection technologies », Computer Law & Security Review: The International Journal of Technology Law and Practice, vol. 30, , p. 670-686 (ISSN 0267-3649, DOI 10.1016/j.clsr.2014.09.006)
- (en) Chris J. Davies, « The hidden censors of the internet », Wired, (lire en ligne, consulté le )
- (en) Andrey Brito, André Martin, Christof Fetzer, Isabelly Rocha et Telles Nóbrega, « StreamMine3G OneClick -- Deploy & Monitor ESP Applications With A Single Click », 2013 42nd International Conference on Parallel Processing, , p. 1014-1019 (ISBN 978-0-7695-5117-3, ISSN 0190-3918, DOI 10.1109/ICPP.2013.120)
- (en) Derek Pao, Nga Lam Or et Ray C.C Cheung, « A memory-based NFA regular expression match engine for signature-based intrusion detection », Computer Communications, vol. 36, , p. 1255-1267 (ISSN 0140-3664, DOI 10.1016/j.comcom.2013.03.002)
 Portail des réseaux informatiques
Portail des réseaux informatiques  Portail de l’informatique
Portail de l’informatique  Portail d’Internet
Portail d’Internet  Portail des télécommunications
Portail des télécommunications