Méthode des k plus proches voisins
En intelligence artificielle, plus précisément en apprentissage automatique, la méthode des k plus proches voisins est une méthode d’apprentissage supervisé. En abrégé k-NN ou KNN, de l'anglais k-nearest neighbors.
| Nature | |
|---|---|
| Sigle |
(en) k-NN |
Dans ce cadre, on dispose d’une base de données d'apprentissage constituée de N couples « entrée-sortie ». Pour estimer la sortie associée à une nouvelle entrée x, la méthode des k plus proches voisins consiste à prendre en compte (de façon identique) les k échantillons d'apprentissage dont l’entrée est la plus proche de la nouvelle entrée x, selon une distance à définir. Puisque cet algorithme est basé sur la distance, la normalisation peut améliorer sa précision.[1],[2]
Par exemple, dans un problème de classification, on retiendra la classe la plus représentée parmi les k sorties associées aux k entrées les plus proches de la nouvelle entrée x.
En reconnaissance de forme, l'algorithme des k plus proches voisins (k-NN) est une méthode non paramétrique utilisée pour la classification et la régression. Dans les deux cas, il s'agit de classer l'entrée dans la catégorie à laquelle appartient les k plus proches voisins dans l'espace des caractéristiques identifiées par apprentissage. Le résultat dépend si l'algorithme est utilisé à des fins de classification ou de régression :
- en classification k-NN, le résultat est une classe d'appartenance. Un objet d'entrée est classifié selon le résultat majoritaire des statistiques de classes d'appartenance de ses k plus proches voisins, (k est un nombre entier positif généralement petit). Si k = 1, alors l'objet est affecté à la classe d'appartenance de son proche voisin.
- en régression k-NN, le résultat est la valeur pour cet objet. Cette valeur est la moyenne des valeurs des k plus proches voisins.
La méthode k-NN est basée sur l'apprentissage préalable, ou l'apprentissage faible, où la fonction est évaluée localement, le calcul définitif étant effectué à l'issue de la classification. L'algorithme k-NN est parmi les plus simples des algorithmes de machines learning.
Que ce soit pour la classification ou la régression, une technique efficace peut être utilisée pour pondérer l'influence contributive des voisinages, ainsi les plus proches voisins contribuent-ils plus à la moyenne que les voisins plus éloignés. Pour exemple, un schéma courant de pondération consiste à donner à chaque voisin une pondération de 1/d, ou d est la distance de l'élément, à classer ou à pondérer, de ce voisin.
Les voisins sont pris depuis un ensemble d'objets pour lesquels la classe (en classification k-NN) ou la valeur (pour une régression k-NN) est connue. Ceci peut être considéré comme l'ensemble d'entraînement pour l'algorithme, bien qu'un entraînement explicite ne soit pas particulièrement requis.
Une particularité des algorithmes k-NN est d'être particulièrement sensible à la structure locale des données.
Hypothèse statistique et choix de k
On suppose des couples de données prenant leur valeur dans l'ensemble , où Y est la classe de labellisation de X, tel que pour (et une loi de distribution de probabilités ). Étant donnée une norme quelconque sur et un point , soit , un ré-arrangement des données d'apprentissage tel que les couples soient les plus proches voisins appartenant à une même classe respectant la métrique (classe de population proposant k éléments dans le voisinage). L'algorithme nécessite de connaître k, le nombre de voisins à considérer. Une méthode classique pour avoir cette valeur est la validation croisée (cross validation).










Algorithme
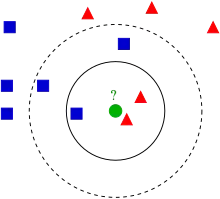
Les exemples d'apprentissage sont des vecteurs dans un espace de caractéristiques multidimensionnel, chacun avec une étiquette de classe d'appartenance. La phase d'apprentissage de l'algorithme consiste seulement dans le stockage des vecteurs caractéristiques et des étiquettes de classe des échantillons d'apprentissage.
Dans la phase de classification, k est une constante définie par l'utilisateur, et un vecteur non étiqueté (une requête ou un point de test) est classé en lui affectant l'étiquette qui est la plus fréquente parmi les k échantillons d'entraînement les plus proches du point à classer.
La distance commune pour des variables continues est la distance euclidienne. Pour des variables discrètes, comme en classification de texte, une autre distance peut être utilisée, telle que la distance de recouvrement (ou la distance de Hamming). Dans le contexte de micro-tableau de données génétiques, par exemple, k-NN a aussi été employée avec des coefficients de corrélation de Pearson et Spearman[3]. Fréquemment, la précision de la classification k-NN peut être améliorée de manière significative si la distance est apprise par des algorithmes spécialisés tels que la méthode du plus proche voisin à grande tolérance ou l'analyse des composantes de voisinage.
Une faiblesse de la classification dans sa version de base par vote majoritaire apparaît quand la distribution de classe est asymétrique. C'est-à-dire, des exemples d'une classe plus fréquente tendent à dominer la prédiction de classification du nouvel entrant, car elle serait statistiquement plus fréquente parmi les k plus proches voisins par définition[4]. Un moyen de surmonter cette difficulté est de pondérer la classification, en prenant en compte la distance du nouvel entrant à chacun de ses k plus proches voisins. La classe (ou la valeur en cas de régression) de chacun de ces k plus proches voisins est multipliée par une pondération proportionnelle à l'inverse de la distance de ce voisin au point à classer. Une autre façon de s'affranchir de cette asymétrie se fait par abstraction dans la représentation des données. Par exemple, dans une carte auto adaptative (SOM), chaque nœud est représentatif du barycentre d'un amas de points similaires, indépendamment de leur densité dans les données originales d'apprentissage. La méthode k-NN peut être employée pour les SOM.
Notes et références
- (en) S. Madeh Piryonesi et Tamer E. El-Diraby, « Role of Data Analytics in Infrastructure Asset Management: Overcoming Data Size and Quality Problems », Journal of Transportation Engineering, Part B: Pavements, vol. 146, no 2, , p. 04020022 (ISSN 2573-5438 et 2573-5438, DOI 10.1061/JPEODX.0000175, lire en ligne, consulté le )
- Hastie, Trevor. et Friedman, J. H. (Jerome H.), The elements of statistical learning : data mining, inference, and prediction : with 200 full-color illustrations, Springer, (ISBN 0-387-95284-5 et 978-0-387-95284-0, OCLC 46809224, lire en ligne)
- P. A. Jaskowiak et R. J. G. B. Campello, « Comparing Correlation Coefficients as Dissimilarity Measures for Cancer Classification in Gene Expression Data », sur http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.208.993, Brazilian Symposium on Bioinformatics (BSB 2011) (consulté le ), p. 1–8
- D. Coomans et D.L. Massart, « Alternative k-nearest neighbour rules in supervised pattern recognition : Part 1. k-Nearest neighbour classification by using alternative voting rules », Analytica Chimica Acta, vol. 136, , p. 15–27 (DOI 10.1016/S0003-2670(01)95359-0)
Voir aussi
 Portail de l'informatique théorique
Portail de l'informatique théorique  Portail des probabilités et de la statistique
Portail des probabilités et de la statistique