Recherche des plus proches voisins
La recherche des plus proches voisins, ou des k plus proches voisins, est un problème algorithmique classique. De façon informelle le problème consiste, étant donné un point à trouver dans un ensemble d'autres points, quels sont les k plus proches.

La recherche de voisinage est utilisée dans de nombreux domaines, tels la reconnaissance de formes, le clustering, l'approximation de fonctions, la prédiction de séries temporelles et même les algorithmes de compression (recherche d'un groupe de données le plus proche possible du groupe de données à compresser pour minimiser l'apport d'information). C'est en particulier l'étape principale de la méthode des k plus proches voisins en apprentissage automatique.
Définition
La formulation classique du problème est la suivante. Étant donné un ensemble A de n points, dans un espace métrique E, un entier k plus petit que n, et un point supplémentaire x, trouver les k points de A les plus proches de x.
Un cas classique est celui de la recherche du plus proche voisin, c'est-à-dire le cas k=1. Une hypothèse classique est que l'espace sous-jacent E est un espace vectoriel de dimension bornée.
Méthodes exactes
Recherche linéaire
L'algorithme naïf de recherche de voisinage consiste à passer sur l'ensemble des n points de A et à regarder si ce point est plus proche ou non qu'un des plus proches voisins déjà sélectionné, et si oui, l'insérer. On obtient alors un temps de calcul linéaire en la taille de A : O(n) (tant que k << n). Cette méthode est appelée la recherche séquentielle ou recherche linéaire.
Algorithme naïf :
pour i allant de 1 à k
mettre le point D[i] dans proches_voisins
fin pour
pour i allant de k+1 à n
si la distance entre D[i] et x est inférieure à la distance d'un des points de proches_voisins à x
supprimer de proches_voisins le point le plus éloigné de x
mettre dans proches_voisins le point D[i]
fin si
fin pour
proches_voisins contient les k plus proches voisins de x
La recherche linéaire souffre d'un problème de lenteur. Si l'ensemble A est grand, il est alors extrêmement coûteux de tester les n points de l'espace.
Les optimisations de cet algorithme se basent souvent sur des cas particuliers du problème. Le plus souvent, l'optimisation consiste à effectuer au préalable un algorithme (pré-traitement) pouvant avoir une complexité supérieure à O(n) mais permettant d'effectuer par la suite très rapidement un grand nombre de recherches. Il s'agit alors de trouver un juste milieu entre le temps de pré-calculs et le nombre de recherches qui auront lieu par la suite.
Partitionnement de l'espace
Il existe des algorithmes efficaces de recherche lorsque la dimension D est petite (inférieure à ~15). La structure la plus connue est l'arbre k-d, introduite en 1975[1].
Un problème majeur de ces méthodes est de souffrir de la malédiction de la dimension : lorsque la dimension D est trop grande, ces méthodes ont des performances comparables ou inférieures à une recherche linéaire[2].
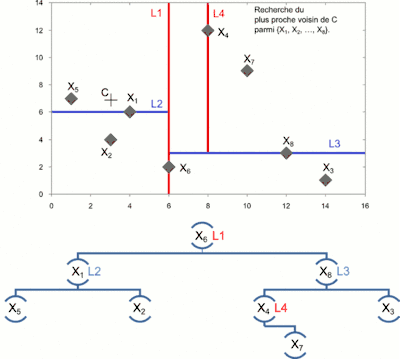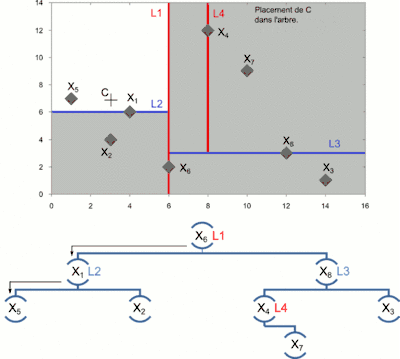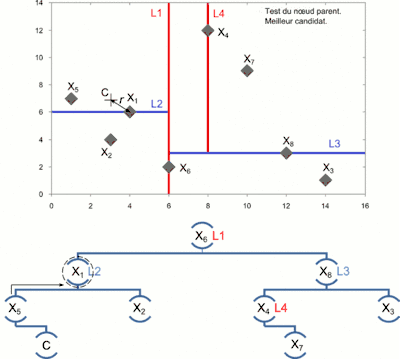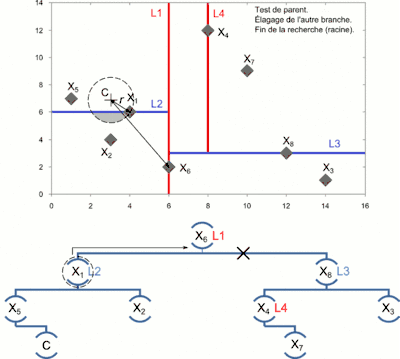
La recherche des plus proches voisins d'un point C dans un arbre k-d se fait de la manière suivante :
- On cherche à placer le point C dans l'arbre, on applique donc l'algorithme d'insertion.
- Une fois arrivé à une feuille, ce point est sauvegardé comme étant le « meilleur candidat pour l'instant ».
- On remonte l'arbre :
- Si le nœud courant est plus proche, il devient le meilleur candidat ;
- On détermine si une partie de la cellule située de l'autre côté de l'hyperplan délimité par le nœud peut contenir un point plus proche. Pour cela, on détermine l'intersection de l'hyperplan avec la boule de recherche[3] :
- si la boule de recherche traverse l'hyperplan, on effectue une recherche en descendant la branche correspondante ;
- sinon, on élimine la branche et on continue à remonter l'arbre.
- On s'arrête à la racine.
Méthodes approchées
Locality sensitive hashing
On remplace les points de l'espace E par une empreinte, typiquement un nombre, calculée par une fonction de hachage. Plutôt que de faire une recherche par les m coordonnées (pour un espace E à m dimensions), on fait une recherche des plus proches voisins par la valeur de l'empreinte. On fait des recherches sur plusieurs empreintes, en utilisant une famille de fonctions de hachage, jusqu'à trouver un candidat statistiquement satisfaisant.
Applications
Concernant un espace géométrique :
- probabilité de collision : dans le cas d'un système dynamique, on peut rechercher les plus proches voisins d'un objet pour tester s'il y a un risque de collision ; par exemple, dans le cas d'un jeu vidéo, pour savoir si le personnage peut être bloqué par un obstacle ;
- interactions à distance : en physique, l'intensité des interactions diminue avec la distance, et la présence de particules peut avoir un effet d'écran ; il est donc utile de déterminer les plus proches voisins d'une particule, pour limiter les calculs d'interaction ;
- gestion administrative d'un territoire : pour déterminer de quel établissement (bureau de poste, établissement scolaire…) une personne dépend, on recherche le plus proche établissement voisin du domicile ; on parle d'ailleurs parfois du « problème du bureau de poste »[4].
L'espace peut aussi être un espace abstrait : si un objet est représenté par un nombre m de paramètres chiffrés, on peut représenter cet objet par un point dans l'espace à m dimensions, l'algorithme permet alors de trouver le ou les objets ayant les propriétés les plus proches. Il peut par exemple s'agir de trouver le meilleur candidat de substitution à un objet donné, le meilleur candidat pour une application donnée (plus proche voisin de l'objet idéal), ou bien trouver l'objet correspondant le mieux à une empreinte relevée (identification, enquête).
Notes et références
- (en) Jon Louis Bentley, « Multidimensional binary search trees used for associative searching », Communications of the ACM, vol. 18, no 9, , p. 509-517 (DOI 10.1145/361002.361007)
- (en) Piotr Indyk et Rajeev Motwani, « Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality. », Proceedings of 30th Symposium on Theory of Computing, (lire en ligne)
- pour un point C(c1, c2, …, cn ) et un rayon R donnés, et pour une norme Lm choisie, la boule de recherche est l'ensemble des points X(x1, x2, …, xn ) vérifiant
;
si m = 2 (norme euclidienne), la boule de recherche est l'hypersphère - Post-office problem, cf. (en) Donald E. Knuth, The Art of Computer Programming, vol. 3 : Sorting and Searching, , 2e éd. [détail de l’édition]. Ce terme est également utilisé pour décrire le problème du cercle minimum ; il s'agit alors de trouver où placer un bureau de poste pour servir au mieux un ensemble de domiciles donnés.

 Portail de l'informatique théorique
Portail de l'informatique théorique