K-moyennes
Le partitionnement en k-moyennes (ou k-means en anglais) est une méthode de partitionnement de données et un problème d'optimisation combinatoire. Étant donnés des points et un entier k, le problème est de diviser les points en k groupes, souvent appelés clusters, de façon à minimiser une certaine fonction. On considère la distance d'un point à la moyenne des points de son cluster ; la fonction à minimiser est la somme des carrés de ces distances.
Il existe une heuristique classique pour ce problème, souvent appelée méthodes des k-moyennes, utilisée pour la plupart des applications. Le problème est aussi étudié comme un problème d'optimisation classique, avec par exemple des algorithmes d'approximation.
Les k-moyennes sont notamment utilisées en apprentissage non supervisé où l'on divise des observations en k partitions. Les nuées dynamiques sont une généralisation de ce principe, pour laquelle chaque partition est représentée par un noyau pouvant être plus complexe qu'une moyenne. Un algorithme classique de k-means est le même que l'algorithme de quantification de Lloyd-Max.
Définition
Étant donné un ensemble de points (x1, x2, …, xn), on cherche à partitionner les n points en k ensembles S = {S1, S2, …, Sk} (k ≤ n) en minimisant la distance entre les points à l'intérieur de chaque partition :

où μi est le barycentre des points dans Si.
Historique
Le terme « k-means » a été utilisé pour la première fois par James MacQueen en 1967[1], bien que l'idée originale ait été proposée par Hugo Steinhaus en 1957[2]. L'algorithme classique a été proposé par Stuart Lloyd en 1957 à des fins de modulation d'impulsion codée, mais il n'a pas été publié en dehors des Bell Labs avant 1982[3]. En 1965, E. W. Forgy publia une méthode essentiellement similaire, raison pour laquelle elle est parfois appelée « méthode de Lloyd-Forgy » [4]. Une version plus efficace, codée en Fortran, a été publiée par Hartigan et Wong en 1975/1979[5],[6].
Algorithme classique
Il existe un algorithme classique pour le problème, parfois appelé méthode des k-moyennes, très utilisé en pratique et considéré comme efficace bien que ne garantissant ni l'optimalité, ni un temps de calcul polynomial[7].
Description
- Choisir k points qui représentent la position moyenne des partitions m1(1), …, mk(1) initiales (au hasard par exemple) ;
- Répéter jusqu'à ce qu'il y ait convergence :
- – affecter chaque observation à la partition la plus proche (c.-à-d. effectuer une partition de Voronoï selon les moyennes) :
- ,
- – mettre à jour la moyenne de chaque cluster :
- .


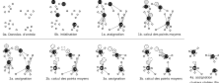
Initialisation
L'initialisation est un facteur déterminant dans la qualité des résultats (minimum local). De nombreux travaux traitent ce point. Il existe deux méthodes d'initialisation habituelles: la méthode de Forgy d'une part et le partitionnement aléatoire d'autre part. La méthode de Forgy affecte les k points des moyennes initiales à k données d'entrée choisies aléatoirement. Le partitionnement aléatoire affecte aléatoirement un cluster à chaque donnée et procède ensuite au (avant-premier) calcul des points de moyennes initiales.
K-moyennes++[8] est un algorithme d’initialisation des k points qui propose une initialisation améliorant la probabilité d'obtenir la solution optimale (minimum global). L'intuition derrière cette approche consiste à répartir les k points des moyennes initiales. Le point de moyenne initial du premier cluster est choisi aléatoirement parmi les données. Puis chaque point de moyenne initiale est choisi parmi les points restants, avec une probabilité proportionnelle au carré de la distance entre le point et le cluster le plus proche.
Analyse
Il y a un nombre fini de partitions possibles à k classes[9]. De plus, chaque étape de l'algorithme fait strictement diminuer la fonction de coût, positive, et fait découvrir une meilleure partition. Cela permet d'affirmer que l'algorithme converge toujours en temps fini, c'est-à-dire termine.
Le partitionnement final n'est pas toujours optimal. De plus le temps de calcul peut être exponentiel en le nombre de points, même dans le plan[10]. Dans la pratique, il est possible d'imposer une limite sur le nombre d’itérations ou un critère sur l'amélioration entre itérations.
À k fixé, la complexité lisse est polynomiale pour certaines configurations, dont des points dans un espace euclidien[7] et le cas de la divergence de Kullback-Leibler[11]. Si k fait partie de l'entrée, la complexité lisse est encore polynomiale pour le cas euclidien[12]. Ces résultats expliquent en partie l'efficacité de l'algorithme en pratique.
Autres aspects algorithmiques
Le problème des k-moyennes est NP-difficile dans le cas général[13]. Dans le cas euclidien, il existe un algorithme d'approximation polynomial, de ratio 9, par recherche locale[14].
Applications
Avantages et inconvénients pour l'apprentissage
Un inconvénient possible des k-moyennes pour le partitionnement est que les clusters dépendent de l'initialisation et de la distance choisie[réf. souhaitée].
Le fait de devoir choisir a priori le paramètre k peut être perçu comme un inconvénient ou un avantage. Dans le cas du calcul des sac de mots par exemple, cela permet de fixer exactement la taille du dictionnaire désiré. Au contraire, dans certains partitionnements de données, on préférera s'affranchir d'une telle contrainte.
Notes et références
- J. B. MacQueen (1967). « Some Methods for classification and Analysis of Multivariate Observations » dans Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability 1: 281–297 p.. Consulté le 7 avril 2009.
- H. Steinhaus, « Sur la division des corps matériels en parties », Bull. Acad. Polon. Sci., vol. 4, no 12, , p. 801–804 (Math Reviews 0090073, zbMATH 0079.16403).
- S. P. Lloyd, « Least square quantization in PCM », Bell Telephone Laboratories Paper, Published in journal much later: S. P. Lloyd., « Least squares quantization in PCM », IEEE Transactions on Information Theory, vol. 28, no 2, , p. 129–137 (DOI 10.1109/TIT.1982.1056489, lire en ligne, consulté le ).
- E.W. Forgy, « Cluster analysis of multivariate data: efficiency versus interpretability of classifications », Biometrics, vol. 21, , p. 768–769 (JSTOR 2528559).
- J. A. Hartigan, Clustering algorithms, John Wiley & Sons, Inc., .
- J. A. Hartigan et M. A. Wong, « Algorithm AS 136: A K-Means Clustering Algorithm », Journal of the Royal Statistical Society, Series C, vol. 28, no 1, , p. 100–108 (JSTOR 2346830).
- David Arthur et Sergei Vassilvitskii, « Worst-Case and Smoothed Analysis of the ICP Algorithm, with an Application to the k-Means Method », SIAM J. Comput., vol. 39, no 2, , p. 766-782.
- Arthur, David et Vassilvitskii, Sergei, « k-means++: the advantages of careful seeding », ACM-SIAM symposium on Discrete algorithms, (lire en ligne).
- Voir Nombre de Stirling pour plus de détails.
- Andrea Vattani, « k-means Requires Exponentially Many Iterations Even in the Plane », Discrete & Computational Geometry, vol. 45, no 4, , p. 596-616
- Bodo Manthey et Heiko Röglin, « Worst-Case and Smoothed Analysis of k-Means Clustering with Bregman Divergences », JoCG, vol. 4, no 1, , p. 94-132.
- David Arthur, Bodo Manthey et Heiko Röglin, « Smoothed Analysis of the k-Means Method », Journal of the ACM, vol. 58, no 5, , p. 19 (lire en ligne)
- The Hardness of Kmeans Clustering Sanjoy Dasgupta, Technical Report CS2008-06, Department of Computer Science and Engineering, University of California, San Diego
- Tapas Kanungo, David M. Mount, Nathan S. Netanyahu, Christine D. Piatko, Ruth Silverman et Angela Y. Wu, « A local search approximation algorithm for k-means clustering », Comput. Geom., vol. 28, nos 2-3, , p. 89-112 (lire en ligne)
Voir aussi
Bibliographie
- (en) Richard O. Duda, Peter E. Hart, David G. Stork, Pattern Classification, Wiley-interscience, (ISBN 0-471-05669-3) [détail des éditions]