Partitionnement spectral
En informatique théorique, le partitionnement spectral ou spectral clustering en anglais, est un type de partitionnement de données prenant en compte les propriétés spectrales de l'entrée. Le partitionnement spectral utilise le plus souvent les vecteurs propres d'une matrice de similarités. Par rapport à des algorithmes classiques comme celui des k-moyennes, cette technique offre l'avantage de classer des ensembles de données de structure « non-globulaire », dans un espace de représentation adéquat.
Pour les articles homonymes, voir Classification spectrale.
Ce partitionnement est notamment utilisé en intelligence artificielle, où le terme classification spectrale renvoie au fait de faire de la classification non-supervisée en utilisant ce type de partitionnement.
Définition
Le partitionnement spectral est une méthode de partitionnement en K groupes reposant sur la minimisation d'un critère de type « coupe » (coupe simple à K=2, ou coupe multiple à K≥2). Ces deux mesures expriment la cohésion interne des groupes, relativement à leur dissociation les uns des autres. Elles sont directement fonctions d'une matrice de similarités entre objets, notée S.
Étant donné un ensemble de N objets, il est possible d'obtenir une représentation détaillée de cet ensemble sous la forme d'un graphe pondéré (cf. théorie des graphes), noté G(V,E,S). V désigne l'ensemble des N nœuds du graphe, correspondant aux objets ; E est l'ensemble des arcs inter-nœuds et S est la matrice de poids des arcs (matrice de similarités), symétrique et non négative (Sij indiquant la similarité entre les objets xi et xj).
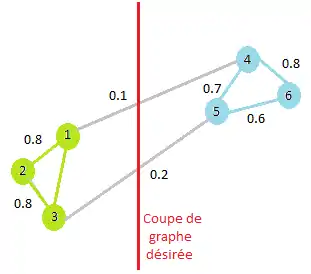
Dans le but de résoudre le problème d'optimisation du critère de coupe défini précédemment, le partionnement spectral s'appuie sur l'utilisation du spectre de la matrice de similarités des données en vue du partitionnement de l'ensemble des objets dans un espace de plus faible dimension. On a alors un problème de partitionnement de graphe pour lequel les nœuds d'un même groupe sont similaires et les nœuds appartenant à des groupes différents sont dissimilaires[1].
Les différents types de graphes pondérés
L'objectif de la construction d'un graphe pondéré est de rendre compte (ou de modéliser) les relations de voisinage entre les objets. Il existe alors plusieurs façons de procéder :
- Graphe de voisinage ε : connexion des nœuds pour lesquels la similarité Sij est supérieure à ε,
- Graphe des k plus proches voisins : connexion du ie nœud avec le je nœud si et seulement si l'objet xj fait partie des k plus proches voisins de l'objet xi.
- Graphe totalement connecté : connexion de tous les nœuds entre eux et pondération des arcs de liaison par la valeur de Sij.
Construction de la matrice de similarités S
Dans la littérature, plusieurs techniques permettent d'obtenir une mesure de similarité entre deux objets. Le choix de la fonction de similarité dépend essentiellement du domaine de provenance des données (par exemple, fouille de documents, fouille de données web, etc.), mais également du type de données (qui peuvent être décrit par des variables numériques, catégorielles, binaires, etc.). Cependant, les deux formules les plus répandues et les plus utilisées sont :
- Noyau Gaussien[2] :

avec d étant une mesure de distance (de type Euclidienne, Manhattan, Minkowski, etc.), et σ, un paramètre d'échelle dont la valeur est fixé par l'utilisateur.
- Distance cosinus[3] :

avec B désignant la matrice de données (constituée de N objets décrits chacun par M attributs) normalisée en ligne.
Construction de l'espace spectral
Les algorithmes de partitionnement spectral utilisent l'information contenue dans les vecteurs propres d'une matrice laplacienne (construite à partir de la matrice de similarités S) afin de détecter une structure des données. Soit D, la matrice diagonale des degrés (D=diag(D11,...,DNN)) telle que :

représente le degré du ie nœud du graphe G. Il est alors possible de construire la matrice laplacienne L en utilisant une des nombreuses normalisations présentes dans la littérature :
- Aucune normalisation[4] :

- Normalisation par division[5] :

- Normalisation par division symétrique[6] :

- Normalisation additive[7] :

(avec dmax désignant le degré maximum de D et I étant la matrice identité). L'étape suivante consiste à extraire les vecteurs propres de la matrice laplacienne. Il est démontré que l'utilisation des K (nombre de groupes souhaité) premiers vecteurs propres orthogonaux de L (correspondant aux K plus petites valeurs propres), permet d'obtenir un espace de projection de plus faible dimension (en K dimensions) que l'espace original (en M dimensions). La matrice X est alors construite en stockant ces vecteurs propres (en colonnes) : . Parmi les algorithme de calcul des valeurs propres, on peut citer la méthode de la puissance itérée.

Partitionnement des données dans l'espace spectral
Le partitionnement des données est alors effectué sur la matrice X. En effet, la première étape consiste à considérer chaque ligne de cette matrice comme représentant un objet dans l'espace spectral (en K dimensions). La seconde étape est alors d'appliquer un algorithme de classification non-supervisée sur cette matrice. Le partitionnement des données en K groupes se résume alors à l'affectation de l'objet original xi au groupe k si et seulement si la ie ligne de X a été affectée au groupe k.
Bien que l'algorithme de partitionnement utilisé le plus souvent dans la littérature soit l'algorithme des K-moyennes, il est tout à fait envisageable d'utiliser n'importe quelle autre méthode non-supervisée afin de classer les différents objets[8],[9].
Applications
Notes et références
- « Von Luxburg U., A Tutorial on Spectral Clustering. Statistics and Computing, vol. 17(4), p. 395-416, 200 7 »
- « Zelnik-Manor L., Perona P., Self-tuning spectral clustering. Advances in Neural Information Processing Systems, vol. 17, p. 1601-1608, 2004 »
- « Salton G., Automatic Text Processing: the transformation, analysis and retrieval of information by computer. Addison-Wesley, 1989 »
- « Deerwester S., Dumais S., Landauer T., Furnas G., Harshman R., Indexing by latent semantic analysis. Journal of the American Society of Information Science, vol. 41(6), p. 391-407, 1990 »
- « Meila M., Shi J., Learning segmentation by random walks. Advances in Neural Information Processing Systems, p. 470-477, 2000 »
- « Ng A., Jordan M., Weiss Y., On spectral clustering: Analysis and an algorithm. JProceedings of Advances in Neural Information Processing Systems, p. 849-856, 2002 »
- « Kamvar S., Klein D., Manning C., Spectral Learning. 18th International Joint Conference on Artificial Intelligence, p. 561-566, 200 3 »
- « Lang K., Fixing two weaknesses of the spectral method. Advances in Neural Information Processing Systems, p. 715-722, 2006 »
- « Bach F., Jordan M., Learning spectral clustering. Advances in Neural Information Processing Systems, p. 305-312, 2004 »
- « Kurucz M., Benczur A., Csalogany K., Lucacs L., Spectral Clustering in Social Networks. Advances in Web Mining and Web usage Analysis, 2009 »
- « Brew C., Schulte im Walde S., Spectral clustering for german verbs. Proceedings of EMNLP-2002, 2002 »
 Portail des probabilités et de la statistique
Portail des probabilités et de la statistique  Portail de l'informatique théorique
Portail de l'informatique théorique