Representational state transfer
REST (representational state transfer) est un style d'architecture logicielle définissant un ensemble de contraintes à utiliser pour créer des services web. Les services web conformes au style d'architecture REST, aussi appelés services web RESTful, établissent une interopérabilité entre les ordinateurs sur Internet. Les services web REST permettent aux systèmes effectuant des requêtes de manipuler des ressources web via leurs représentations textuelles à travers un ensemble d'opérations uniformes et prédéfinies sans état. D'autres types de services web tels que les services web SOAP exposent leurs propres ensembles d'opérations arbitraires[1].
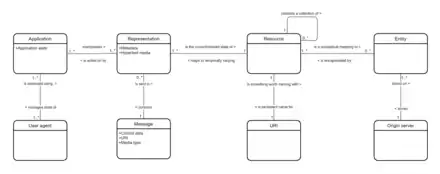
Les ressources web ont été définies pour la première fois sur le World Wide Web comme des documents ou des fichiers identifiés par leur URL. Cependant, elles ont aujourd'hui une définition beaucoup plus générique et abstraite qui inclut toute chose ou entité pouvant être identifiée, nommée, adressée ou gérée d'une façon quelconque sur le web. Dans un service web REST, les requêtes effectuées sur l'URI d'une ressource produisent une réponse dont le corps est formaté en HTML, XML, JSON ou un autre format. La réponse peut confirmer que la ressource stockée a été altérée et elle peut fournir des liens hypertextes vers d'autres ressources ou collection de ressources liées. Lorsque le protocole HTTP est utilisé, comme c'est souvent le cas, les méthodes HTTP disponibles sont GET, HEAD, POST, PUT, PATCH, DELETE, CONNECT, OPTIONS et TRACE[2].
Avec l'utilisation d'un protocole sans état et d'opérations standards, les systèmes REST visent la réactivité, la fiabilité et l'extensibilité, par la réutilisation de composants pouvant être gérés et mis à jour sans affecter le système global, même pendant son fonctionnement.
Le terme representational state transfer a été défini pour la première fois en 2000 par Roy Fielding dans le chapitre 5 de sa thèse de doctorat[3],[4],[5]. La thèse de Fielding a expliqué les principes de REST auparavant connus comme le « modèle objet de HTTP » depuis 1994 et qui ont été utilisés dans l'élaboration des standards HTTP 1.1 et URI. Le terme est censé évoquer comment une application web bien conçue se comporte : c'est un réseau de ressources (une machine à états virtuelle) au sein duquel l'utilisateur évolue en sélectionnant des identifiants de ressources telles que http://www.exemple.com/articles/21 et des opérations sur les ressources telles que GET ou POST (des transitions d'état de l'application) transférant une représentation de la ressource suivante (le nouvel état de l'application) vers l'utilisateur pour être utilisée.
Histoire

Roy Fielding a défini REST en 2000 dans sa thèse de doctorat Architectural Styles and the Design of Network-based Software Architectures à l'université de Californie à Irvine[3]. Il y a développé le style d'architecture REST en parallèle du protocole HTTP 1.1 de 1996 à 1999, basé sur le modèle existant de HTTP 1.0 de 1996[6].
Lors d'un regard rétrospectif sur le développement de REST, Fielding a déclaré:
Throughout the HTTP standardization process, I was called on to defend the design choices of the Web. That is an extremely difficult thing to do within a process that accepts proposals from anyone on a topic that was rapidly becoming the center of an entire industry. I had comments from well over 500 developers, many of whom were distinguished engineers with decades of experience, and I had to explain everything from the most abstract notions of Web interaction to the finest details of HTTP syntax. That process honed my model down to a core set of principles, properties, and constraints that are now called REST.
« Au cours de la procédure de standardisation de HTTP, on m'a appelé pour défendre les choix d'architecture du Web. C'est une tâche extrêmement compliquée dans la mesure où la procédure accepte les propositions de n'importe qui sur un sujet qui était en train de devenir rapidement le centre d'une industrie entière. Je recevais les commentaires de plus de 500 développeurs, dont de nombreux étaient des ingénieurs renommés avec des décennies d'expérience, et je devais tout expliquer, des notions les plus abstraites des interactions du Web jusqu'aux détails les plus subtils de la syntaxe de HTTP. Cette procédure a réduit mon modèle à un ensemble fondamental de principes, propriétés et contraintes qui sont aujourd'hui appelés REST. »
Contraintes architecturales
Six contraintes architecturales définissent un système REST[7],[8]. Ces contraintes restreignent la façon dont le serveur peut traiter et répondre aux requêtes du client afin que, en agissant dans ces contraintes, le système gagne des propriétés non fonctionnelles désirables, telles que la performance, l'extensibilité, la simplicité, l'évolutivité, la visibilité, la portabilité et la fiabilité[3]. Un système qui viole une de ces contraintes ne peut pas être considéré comme adhérant à l'architecture REST.
Client–serveur
Les responsabilités sont séparées entre le client et le serveur. Découpler l'interface utilisateur du stockage des données améliore la portabilité de l'interface utilisateur sur plusieurs plateformes. L'extensibilité du système se retrouve aussi améliorée par la simplification des composants serveurs. Mais peut-être encore plus essentiel pour le Web, la séparation permet aux composants d'évoluer indépendamment, supportant ainsi les multiples domaines organisationnels nécessaires à l'échelle d'Internet.
Sans état
La communication client–serveur s'effectue sans conservation de l'état de la session de communication sur le serveur entre deux requêtes successives. L'état de la session est conservé par le client et transmis à chaque nouvelle requête. Les requêtes du client contiennent donc toute l'information nécessaire pour que le serveur puisse y répondre. La visibilité des interactions entre les composants s'en retrouve améliorée puisque les requêtes sont complètes. La tolérance aux échecs est également plus grande. De plus, le fait de ne pas avoir à maintenir une connexion permanente entre le client et le serveur permet au serveur de répondre à d'autres requêtes venant d'autres clients sans saturer l'ensemble de ses ports de communication, ce qui améliore l'extensibilité du système.
Cependant une exception usuelle à ce mode sans état est la gestion de l'authentification du client, afin que celui-ci n'ait pas à renvoyer ces informations à chacune de ses requêtes.
Avec mise en cache
Les clients et les serveurs intermédiaires peuvent mettre en cache les réponses. Les réponses doivent donc, implicitement ou explicitement, se définir comme pouvant être mise en cache ou non, afin d'empêcher les clients de récupérer des données obsolètes ou inappropriées en réponse à des requêtes ultérieures. Une mise en cache bien gérée élimine partiellement voire totalement certaines interactions client–serveur, améliorant davantage l'extensibilité et la performance du système.
En couches
Un client ne peut habituellement pas dire s'il est connecté directement au serveur final ou à un serveur intermédiaire. Les serveurs intermédiaires peuvent améliorer l'extensibilité du système en mettant en place une répartition de charge et un cache partagé. Ils peuvent aussi renforcer les politiques de sécurité.
Avec code à la demande (facultative)
Les serveurs peuvent temporairement étendre ou modifier les fonctionnalités d'un client en lui transférant du code exécutable. Par exemple par des applets Java ou des scripts JavaScript. Cela permet de simplifier les clients en réduisant le nombre de fonctionnalités qu'ils doivent mettre en œuvre par défaut et améliore l'extensibilité du système. En revanche, cela réduit aussi la visibilité de l'organisation des ressources. De ce fait, elle constitue une contrainte facultative dans une architecture REST.
Interface uniforme
La contrainte d'interface uniforme est fondamentale dans la conception de n'importe quel système REST. Elle simplifie et découple l'architecture, ce qui permet à chaque composant d'évoluer indépendamment. Les quatre contraintes de l'interface uniforme sont les suivantes.
- Identification des ressources dans les requêtes
- Chaque ressource est identifiée dans les requêtes, par exemple par un URI dans le cas des systèmes REST basés sur le Web. Les ressources elles-mêmes sont conceptuellement distinctes des représentations qui sont retournées au client. Par exemple, le serveur peut envoyer des données de sa base de données en HTML, XML ou JSON, qui sont des représentations différentes de la représentation interne de la ressource.
- Manipulation des ressources par des représentations
- Chaque représentation d'une ressource fournit suffisamment d'informations au client pour modifier ou supprimer la ressource.
- Messages auto-descriptifs
- Chaque message contient assez d'information pour savoir comment l'interpréter. Par exemple, l'interpréteur à invoquer peut être décrit par un type de médias.
- Hypermédia comme moteur d'état de l'application (HATEOAS)
- Après avoir accédé à un URI initial de l'application — de manière analogue aux humains accédant à la page d'accueil d'un site web —, le client doit être en mesure d'utiliser dynamiquement les hyperliens fournis par le serveur pour découvrir toutes les autres actions possibles et les ressources dont il a besoin pour poursuivre la navigation. Il n'est pas nécessaire pour le client de coder en dur cette information concernant la structure ou la dynamique de l'application.
Propriétés architecturales
Les contraintes architecturales de REST confèrent aux systèmes qui les respectent les propriétés architecturales suivantes[3],[7] :
- performance dans les interactions des composants, qui peuvent être le facteur dominant dans la performance perçue par l'utilisateur et l'efficacité du réseau[9] ;
- extensibilité permettant de supporter un grand nombre de composants et leurs interactions. Roy Fielding décrit l'effet de REST sur l'extensibilité comme suit :
REST's client–server separation of concerns simplifies component implementation, reduces the complexity of connector semantics, improves the effectiveness of performance tuning, and increases the scalability of pure server components. Layered system constraints allow intermediaries—proxies, gateways, and firewalls—to be introduced at various points in the communication without changing the interfaces between components, thus allowing them to assist in communication translation or improve performance via large-scale, shared caching. REST enables intermediate processing by constraining messages to be self-descriptive: interaction is stateless between requests, standard methods and media types are used to indicate semantics and exchange information, and responses explicitly indicate cacheability.
« La séparation des préoccupations client–serveur simplifie l'implémentation des composants, réduit la complexité de la sémantique des connecteurs, améliore l'efficacité de l'optimisation des performances et augmente l'extensibilité des composants purement serveurs. La contrainte d'architecture en couches permet aux intermédiaires — serveurs mandataires, passerelles et pare-feu — d'être introduits à différents niveaux dans la communication sans changer les interfaces entre les composants, leur permettant ainsi d'intervenir dans la traduction des communications ou d'améliorer les performances via des systèmes de cache à grande échelle. REST permet les traitements intermédiaires en forçant des messages auto-descriptifs : l'interaction est sans état entre les requêtes, les méthodes standard et les types de média sont utilisés pour indiquer la sémantique et échanger l'information, et les réponses indiquent explicitement la possibilité de la mise en cache. »
- simplicité d'une interface uniforme ;
- évolutivité des composants pour répondre aux besoins (même lorsque l'application est en cours de fonctionnement) ;
- visibilité des communications entre les composants par des agents de service ;
- portabilité des composants en déplaçant le code avec les données ;
- fiabilité dans la résistance aux pannes du système en cas de pannes des composants, des connecteurs ou des données[9].
Appliqué aux services web
Les API REST basées sur HTTP sont définies par[8] :
- un URI de base, comme
http://api.example.com/collection/; - des méthodes HTTP standards (par ex. : GET, POST, PUT, PATCH et DELETE) ;
- un type de médias pour les données permettant une transition d'état (par ex. : Atom, microformats, application/vnd.collection+json, etc.). La nature hypermédia de l'application permet d'accéder aux états suivants de l'application par inspection de la représentation courante. Cela peut être aussi simple qu'un URI ou aussi complexe qu'un applet Java.
Relation entre URI et méthodes HTTP
Le tableau suivant affiche comment les méthodes HTTP sont généralement utilisées dans une API REST :
| URI | GET | POST | PUT | PATCH | DELETE |
|---|---|---|---|---|---|
Ressource collection, telle que http://api.exemple.com/collection/ |
Récupère les URI des ressources membres de la ressource collection dans le corps de la réponse. | Crée une ressource membre dans la ressource collection en utilisant les instructions du corps de la requête. L'URI de la ressource membre créée est attribué automatiquement et retourné dans le champ d'en-tête Location de la réponse. | Remplace toutes les représentations des ressources membres de la ressource collection par la représentation dans le corps de la requête, ou crée la ressource collection si elle n'existe pas. | Met à jour toutes les représentations des ressources membres de la ressource collection en utilisant les instructions du corps de la requête, ou crée éventuellement la ressource collection si elle n'existe pas. | Supprime toutes les représentations des ressources membres de la ressource collection. |
Ressource membre, telle que http://api.exemple.com/collection/item3 |
Récupère une représentation de la ressource membre dans le corps de la réponse. | Crée une ressource membre dans la ressource membre en utilisant les instructions du corps de la requête. L'URI de la ressource membre créée est attribué automatiquement et retourné dans le champ d'en-tête Location de la réponse. | Remplace toutes les représentations de la ressource membre, ou crée la ressource membre si elle n'existe pas, par la représentation dans le corps de la requête. | Met à jour toutes les représentations de la ressource membre, ou crée éventuellement la ressource membre si elle n'existe pas, en utilisant les instructions du corps de la requête. | Supprime toutes les représentations de la ressource membre. |
La méthode GET est sûre, c'est-à-dire que l'appliquer sur une ressource ne résulte pas en un changement d'état de la ressource (sémantique de lecture seule)[10]. Les méthodes GET, PUT et DELETE sont idempotentes, c'est-à-dire que les appliquer plusieurs fois sur une ressource résulte en le même changement d'état de la ressource que les appliquer une seule fois, bien que la réponse puisse différer[11]. Les méthodes GET et POST sont stockables en cache, c'est-à-dire que le stockage des réponses à ces requêtes pour une future réutilisation est autorisé[12].
Contrairement aux services web orientés SOAP, il n'y a pas de norme officielle pour les API REST[13], parce que REST est une architecture alors que SOAP est un protocole. REST n'est pas une norme en soi, mais les implémentations qui suivent cette architecture utilisent des normes comme HTTP, URI, JSON et XML[13].
Bibliographie
- RESTful Web Services, par Leonard Richardson et Sam Ruby, est un ouvrage en anglais sorti en . Celui-ci a popularisé le style d’architecture REST[14].
- Building Hypermedia APIs with HTML5 and Node, par Mike Amundsen, sorti en [15].
- REST in Practice, par Jim Webber, Savas Parastatidis, Ian Robinson, sorti en [16].
- REST API Design Rulebook, Designing Consistent RESTful Web Service Interfaces, par Mark Masse, sorti en [17].
Voir aussi
Articles connexes
Liens externes
- (en) Architectural Styles and the Design of Network-based Software Architectures La thèse de Roy Fielding dans laquelle il décrit l’architecture REST
- Thèse de Roy T. Fielding - Traduction du Chapitre 5 : REST
- Tutoriel pour un Web Service écrit avec JSP
- Web Services : JBoss privilégie l’approche REST
- (en) howto rest pour AOLserver, PyWX, Quixote
- (en) JBoss Helps Developers RESTEasy Writing REST-based Java Web Services
Notes et références
- (en) « Web Services Architecture », sur W3, (consulté le )
- (en) « Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content », sur Internet Engineering Task Force (IETF), (consulté le )
- (en) Roy Thomas Fielding, Architectural Styles and the Design of Network-based Software Architectures, Irvine, université de Californie à Irvine, , 162 p. (lire en ligne), chap. 5 (« Representational State Transfer (REST) »)
- « Thèse de Roy T. Fielding - Traduction du Chapitre 5 : REST », sur Opikanoba, (consulté le )
- (en) « Fielding discute de la définition du terme REST », sur Yahoo, (consulté le )
- (en) « Discussion sur le développement de REST » [archive du ], sur Yahoo, (consulté le )
- (en) Thomas Erl, Benjamin Carlyle, Cesare Pautasso et Raj Balasubramanian, SOA with REST : Principles, Patterns & Constraints for Building Enterprise Solutions with REST, Upper Saddle River, New Jersey, Prentice Hall, , 624 p. (ISBN 978-0-13-701251-0), chap. 5.1
- (en) Leonard Richardson et Sam Ruby, RESTful Web Services, Sebastopol, Californie, O'Reilly Media, , 446 p. (ISBN 978-0-596-52926-0, lire en ligne)
- (en) Roy Thomas Fielding, Architectural Styles and the Design of Network-based Software Architectures, Irvine, université de Californie à Irvine, , 162 p. (lire en ligne), chap. 2 (« Network-based Application Architectures »)
- (en) « Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content », sur Internet Engineering Task Force (IETF), (consulté le )
- (en) « Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content », sur Internet Engineering Task Force (IETF), (consulté le )
- (en) « Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content », sur Internet Engineering Task Force (IETF), (consulté le )
- (en) « Learn REST: A Tutorial », sur Elkstein, (consulté le )
- (en) Leonard Richardson et Sam Ruby, RESTful Web Services, O'Reilly Media, , 454 p. (ISBN 978-0-596-52926-0, lire en ligne)
- (en) Mike Amundsen, Building Hypermedia APIs with HTML5 and Node, O'Reilly Media, , 244 p. (ISBN 978-1-4493-0657-1, lire en ligne)
- (en) Jim Webber, Savas Parastatidis et Ian Robinson, REST in Practice : Hypermedia and Systems Architecture, O'Reilly Media, , 448 p. (ISBN 978-0-596-80582-1, lire en ligne)
- (en) Mark Masse, REST API Design Rulebook, O'Reilly Media, , 116 p. (ISBN 978-1-4493-1050-9, lire en ligne)
 Portail de l’informatique
Portail de l’informatique