SPARQL
SPARQL (prononcé sparkle, en anglais : « étincelle »[1]) est un langage de requête et un protocole qui permet de rechercher, d'ajouter, de modifier ou de supprimer des données RDF disponibles à travers Internet. Son nom est un acronyme récursif qui signifie SPARQL Protocol and RDF Query Language[2].
| SPARQL | |
| Dernière version | 1.1 |
|---|---|
| Extension de fichier | rq |
SPARQL est considéré dès 2007 comme l'une des technologies clés du Web sémantique par Tim Berners-Lee l'inventeur du Web sémantique qui explique « Tenter d’utiliser le Web sémantique sans SPARQL revient à exploiter une base de données relationnelle sans SQL »[3].
Aujourd'hui, le Web des données (ou Linked Open Data) est constitué de centaines de services SPARQL qui mettent à disposition de plus en plus de données au travers d'Internet comme le fait le projet Wikidata. L'ambition du W3C est d'offrir une interopérabilité non seulement au niveau des services, comme avec les services Web, mais également au niveau des données.
Histoire
Ce standard a été créé par le groupe de travail DAWG (RDF Data Access Working Group[4]) du W3C (Consortium World Wide Web). Les implémentations de SPARQL au sein de triplestores se multiplient[5]. Le premier brouillon a été publié le [6] et le , la version 1.0 est devenue une recommandation officielle du W3C[7].
SPARUL, ou SPARQL / Update, est un ajout ultérieur au langage de recherche SPARQL, également appelé SPARQL / Update 1.0 à partir de afin de pouvoir enregistrer des données via ce langage[8].
La version SPARQL 1.1 a été proposée en 2009[9] puis recommandée officiellement pour remplacer la version 1.0 en 2013[10]. Elle intègre toutes les fonctionnalités précédentes et en propose de nouvelles comme la possibilité de construire des requêtes fédérées afin de pouvoir interroger simultanément plusieurs services SPARQL au travers du protocole que la spécification SPARQL contient.
Bénéfices
Les données touchent tous les domaines d’activité.
Voici des exemples relatifs à l'utilisation de SPARQL pour des données gouvernementales, culturelles, scientifiques, environnementales, économiques et d’infrastructure.
Données gouvernementales
Les États diffusent des données qui leur sont très coûteuses de structurer par eux-mêmes ; ils organisent donc des concours pour le faire à leur place. Cependant, seule une poignée d’entreprises ou d’associations sont en mesure de répondre à ces concours, excluant la majorité des citoyens, qui n’ont pas les moyens de travailler bénévolement à la mise à disposition des données qui les concernent.
L’extension Mediawiki LinkedWiki illustre la capacité de fabriquer n’importe quel rendu à partir des données disponibles à travers SPARQL comme les données du projet Data.gov aux États-Unis.
ex. : où ont eu lieu les tremblements de terre des 7 derniers jours sur la planète ?
Voici un autre exemple pour trouver sur une carte les écoles les plus proches de son domicile avec les données de Data.gov.uk (version britannique de Data.gov) qui offre justement toutes les données relatives aux écoles sur son territoire.
Données culturelles
Les grands médias, les musées et autres centres culturels ne peuvent pas toujours gérer eux-mêmes les besoins créés par les nouveaux médias. Ils ne peuvent plus eux-mêmes développer tous les services qu’il faudrait proposer pour satisfaire leurs clients et usagers. Certains ont trouvé de l’intérêt dans SPARQL, comme la BBC, qui bascule régulièrement ses données dans des triplestores, dont certains sont publics.
ex. : afficher la liste des épisodes de la série Doctor Who de la BBC.
De la même manière, France Télévisions pourrait rendre toutes ses données accessibles pour laisser la possibilité aux téléspectateurs de créer de nouveaux services culturels.
Par exemple, durant une émission sur les œuvres d’art sur une chaîne de France Télévisions, on pourrait synchroniser l’émission à une application sur sa tablette PC avec les données de la Bibliothèque Nationale de France (BnF), avec les peintures du Louvre et du musée du Quai Branly. DBpedia, un projet exploratoire utilisant Wikipédia, a déjà commencé à mettre des données en ligne de Wikipédia. Malheureusement les données de DBpedia ne sont pas synchrones avec les contributions de Wikipédia et les contributeurs ne peuvent intervenir dynamiquement sur la structuration des données mises en ligne.
ex. : quelles sont les peintures de musées disponibles dans Wikipédia (à travers DBpedia) ?
Pour terminer, voici un exemple pour démontrer la combinaison infinie avec des œuvres culturelles. ex. : durant un documentaire de Steven Spielberg, proposer aux spectateurs la liste des VOD de ce réalisateur.
À l’avenir, nous pourrons même afficher la description de chaque poisson durant la rediffusion des documentaires du commandant Cousteau. Les téléspectateurs pourront associer les poissons dans un documentaire aux fiches qu’ils trouveraient au sein des bases de données du Muséum national d’histoire naturelle et de Wikipédia.
Données scientifiques
L’un des premiers articles[Lequel ?] de Tim Berners-Lee sur le sujet annonce que l’objectif final du Web sémantique est d’offrir la capacité à des agents (programme informatique autonome) de trouver les incohérences dans une nouvelle théorie. Un scientifique gagnera ainsi à l’avenir un temps infini à proposer de nombreuses hypothèses qui seront éprouvées par des machines parcourant toutes les connaissances disponibles. Cela deviendra indispensable, car il est humainement impossible de lire tous les documents dans un domaine scientifique.
À l’avenir, il sera donc indispensable de stocker et partager toutes les données scientifiques. Certaines structures commencent à le faire, comme les banques de description des génomes, ou Eurostat, l’Office statistique de l’Union européenne.
Données environnementales et économiques
On peut déjà par exemple créer une application mobile pour référencer les codes-barres des produits au sein d’un wiki sur le Web afin d’indiquer les ingrédients dans chaque produit.
Grâce à la flexibilité d'un wiki, les contributeurs pourront eux-mêmes créer les propriétés comme l’origine d’un produit, le calcul de l’empreinte carbone, quantité d’emballage, etc. En un mot, les consommateurs vont devenir acteur de leurs consommations.
Imaginez que tous les consommateurs puissent scanner un produit avant son achat pour savoir s’il satisfait à des critères écologiques indiqués par eux-mêmes !
Caractéristiques
SPARQL est adapté à la structure spécifique des graphes RDF, et s'appuie sur les triplets qui les constituent. En cela, il est différent du classique SQL (langage de requête qui est adapté aux bases de données de type relationnelles), mais sa syntaxe et ses fonctionnalités paraissent en être fortement inspirées. Certaines caractéristiques peuvent s’apparenter avec Prolog.
SPARQL permet d'exprimer des requêtes interrogatives ou constructives :
- une requête
SELECT, de type interrogative, permet d'extraire du graphe RDF un sous-graphe correspondant à un ensemble de ressources vérifiant les conditions définies dans une clauseWHERE; - une requête
CONSTRUCT, de type constructive, engendre un nouveau graphe qui complète le graphe interrogé.
Par exemple sur un graphe RDF contenant des informations généalogiques, on pourra par une requête SELECT trouver les parents ou grands-parents d'une personne donnée, et par des requêtes CONSTRUCT ajouter des relations frère-sœur, cousin-cousine, oncle-neveu, qui ne seraient pas explicitement déclarées dans le graphe initial.
Exemple
Exemple de requête SPARQL retournant une liste de photos avec le nom de la personne qu'elles représentent et une description, à partir d'une base de données de type RDF utilisant l'ontologie (vocabulaire) FOAF (une des plus connues et utilisée pour décrire les personnes et les liens entre elles).
- Extrait du graphe RDF (écriture XML) d'exemple :
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:rss="http://purl.org/rss/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<foaf:Person rdf:about="http://example.net/Paul_Dupont">
<foaf:name>Paul Dupont</foaf:name>
<foaf:img rdf:resource="http://example.net/Paul_Dupont.jpg"/>
<foaf:knows rdf:resource="http://example.net/Pierre_Dumoulin"/>
</foaf:Person>
<foaf:Person rdf:about="http://example.net/Pierre_Dumoulin">
<foaf:name>Pierre Dumoulin</foaf:name>
<foaf:img rdf:resource="http://example.net/Pierre_Dumoulin.jpg"/>
</foaf:Person>
<foaf:Image rdf:about="http://example.net/Paul_Dupont.jpg">
<dc:description>Photo d'identité de Paul Dupont</dc:description>
</foaf:Image>
<foaf:Image rdf:about="http://example.net/Pierre_Dumoulin.jpg">
<dc:description>Photo d'identité de Pierre Dumoulin</dc:description>
</foaf:Image>
</rdf:RDF>
- La requête SPARQL :
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT DISTINCT ?nom ?image ?description
WHERE {
?personne rdf:type foaf:Person.
?personne foaf:name ?nom.
?image rdf:type foaf:Image.
?personne foaf:img ?image.
?image dc:description ?description
}
On remarque la déclaration des espaces de noms en début, suivis de la requête proprement dite.
Le nom des variables est précédé d'un point d'interrogation ?.
La ligne SELECT permet de sélectionner l'ensemble des tuples, ou lignes de variables (nom, image, description) correspondant aux contraintes de la clause WHERE.
La première ligne de la clause WHERE se lit : la variable personne est de type Person au sens de l'ontologie FoaF.
La seconde ligne permet de définir la variable nom en tant que propriété name de la variable personne.
- Le résultat SPARQL :
<sparql xmlns="http://www.w3.org/2005/sparql-results#"> <head> <variable name="nom"/> <variable name="image"/> <variable name="description"/> </head> <results ordered="false" distinct="true"> <result> <binding name="nom"> <literal>Pierre Dumoulin</literal> </binding> <binding name="image"> <uri>http://example.net/Pierre_Dumoulin.jpg</uri> </binding> <binding name="description"> <literal>Photo d'identité de Pierre Dumoulin</literal> </binding> </result> <result> <binding name="nom"> <literal>Paul Dupont</literal> </binding> <binding name="image"> <uri>http://example.net/Paul_Dupont.jpg</uri> </binding> <binding name="description"> <literal>Photo d'identité de Paul Dupont</literal> </binding> </result> </results> </sparql>
{kind=link}
{kind=link}
Spécifications
Il y a trois recommandations (SPARQL 1.0) du W3C avec une note ainsi que dix documents en fin d'élaboration concernant la version suivante (SPARQL 1.1)[11] :
- Langage d'interrogation SPARQL pour RDF[12]
- Format XML des résultats d'interrogation SPARQL[13]
- Protocole SPARQL pour RDF[14]
Et la note du W3C :
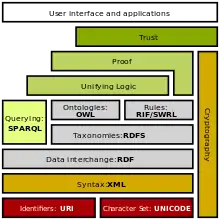
SPARQL est une des couches pour la mise en œuvre du Web sémantique.
Glossaire
Le terme « nœud SPARQL » renvoie à un fournisseur de contenu intégré dans l’architecture du Web des données. Un exemple de nœud SPARQL est DBpedia.
Notes et références
- (en) Jim Rapoza, « SPARQL Will Make the Web Shine », eWeek, (consulté le )
- (en) Toby Segaran, Colin Evans, Jamie Taylor, Programming the Semantic Web, O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472, , 280 p. (ISBN 978-0-596-15381-6), p. 84
- Le W3C ouvre les données sur le Web avec SPARQL
- « RDF Data Access WG Charter », sur www.w3.org (consulté le )
- (en) « SparqlImplementations - ESW Wiki », Esw.w3.org (consulté le )
- « SPARQL Query Language for RDF », sur www.w3.org (consulté le )
- (en) « W3C Semantic Web Activity News - SPARQL is a Recommendation », W3.org, (consulté le )
- / SPARUL Mise à jour de SPARQL 1.0
- SPARQL1.1 SPARQL version 1.1
- SPARQL état actuel
- (en) « SPARQL Current Status », W3.org, (consulté le ).
- (en) « Langage d'interrogation SPARQL pour RDF », W3.org, (consulté le ).
- (en) « Format XML des résultats d'interrogation SPARQL », W3.org, (consulté le ).
- (en) « Protocole SPARQL pour RDF », W3.org, (consulté le ).
- (en) « Serializing SPARQL Query Results in JSON », W3.org, (consulté le ).
Liens externes
- Spécifications du W3C.
 Portail du Web sémantique
Portail du Web sémantique  Portail de l’informatique
Portail de l’informatique  Portail d’Internet
Portail d’Internet