SQLite
SQLite (prononcé [ɛs.ky.ɛl.ajt]) est une bibliothèque écrite en langage C qui propose un moteur de base de données relationnelle accessible par le langage SQL. SQLite implémente en grande partie le standard SQL-92 et des propriétés ACID.

| Développé par | D. Richard Hipp |
|---|---|
| Première version | |
| Dernière version | 3.39.2 ()[1] |
| Dépôt | www.sqlite.org/src |
| Écrit en | C |
| Système d'exploitation | Multiplateforme |
| Formats lus | SQLite database file format (d), SQLite 3.x database (d) et SQLite rollbak journal (d) |
| Formats écrits | SQLite database file format (d), SQLite 3.x database (d), SQLite Zipvfs compressed database (d) et SQLite rollbak journal (d) |
| Type | Système de gestion de base de données embarqué (d) |
| Licence | Domaine public |
| Site web | sqlite.org |
Contrairement aux serveurs de bases de données traditionnels, comme MySQL ou PostgreSQL, sa particularité est de ne pas reproduire le schéma habituel client-serveur mais d'être directement intégrée aux programmes. L'intégralité de la base de données (déclarations, tables, index et données) est stockée dans un fichier indépendant de la plateforme.
D. Richard Hipp, le créateur de SQLite, a choisi de mettre cette bibliothèque ainsi que son code source dans le domaine public, ce qui permet son utilisation sans restriction aussi bien dans les projets open source que dans les projets propriétaires. Le créateur ainsi qu'une partie des développeurs principaux de SQLite sont employés par la société américaine Hwaci[2].
SQLite est le moteur de base de données le plus utilisé au monde, grâce à son utilisation :
- dans de nombreux logiciels grand public comme Firefox, Skype, Google Gears,
- dans certains produits d'Apple, d'Adobe et de McAfee,
- dans les bibliothèques standards de nombreux langages comme PHP ou Python.
De par son extrême légèreté (moins de 600 Kio[3]), il est également très populaire sur les systèmes embarqués, notamment sur la plupart des smartphones et tablettes modernes : les systèmes d'exploitation mobiles iOS, Android et Symbian l'utilisent comme base de données embarquée[4]. Au total, on peut dénombrer plus d'un milliard de copies connues et déclarées de la bibliothèque[5].
Historique
D. Richard Hipp et un collègue commencèrent la conception de SQLite début 2000 lorsqu'ils travaillaient chez General Dynamics, alors en contrat avec l'US Navy. SQLite devait être utilisée dans des missiles guidés, dans le but de remplacer des bases de données IBM Informix fonctionnant sur des machines HP-UX. Le principal objectif était de pouvoir s'affranchir de toute installation ou administration : l'installation ou la mise à jour de la base de données pouvait prendre une journée entière[6].
En août 2000, la première version de SQLite est publiée. Elle utilisait gdbm (GNU Database Manager) pour manipuler des arbres B.
SQLite 2.0 supprime la dépendance à gdbm et ajoute le support des transactions.
SQLite 3.0, produite avec l'aide d'AOL, est publiée en 2004 et ajoute, entre autres, la régionalisation (avec le support des collations et de l'Unicode) et la déclaration des types de données.
Caractéristiques
Base de données embarquée
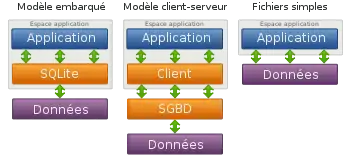
La majorité des systèmes de gestion de base de données sont construits selon le paradigme client-serveur, c'est-à-dire qu'une bibliothèque logicielle cliente est intégrée et utilisée dans une ou plusieurs applications alors que le moteur de base de données fonctionne dans un espace d'exécution qui lui est propre, voire sur une machine différente, en tant que service informatique.
SQLite, au contraire, est directement intégrée dans l'application qui utilise sa bibliothèque logicielle, avec son moteur de base de données. L'accès à une base de données avec SQLite se fait par l'ouverture du fichier correspondant à celle-ci : chaque base de données est enregistrée dans un fichier qui lui est propre, avec ses déclarations, ses tables et ses index mais aussi ses données.
Cette caractéristique rend SQLite intéressante comme alternative aux fichiers textes, utilisés comme moyen de stockage intégré dans beaucoup d'applications (paramètres, historique, cache...), car elle rend l'accès aux données plus rapide, plus sécurisé, plus structuré, plus facile et totalement indépendant de la plateforme, tout en ne portant pas atteinte à la facilité de déploiement de l'application qui l'utilise.
La suppression de l'intermédiaire entre l'application et les données permet également de réduire légèrement la latence d'accès aux données comparée aux systèmes utilisant le paradigme client-serveur.
Cependant, cette architecture pose plusieurs problèmes :
- lorsqu'un nombre important de clients accèdent à une même base, si un des clients commence la lecture d'une partie, la totalité de la base est bloquée en écriture pour les autres clients, et inversement si un des clients démarre l'écriture dans une partie, la totalité de la base est bloquée en lecture pour les autres clients. Ces derniers sont alors mis en attente durant ce laps de temps, ce qui peut être contre-performant ;
- il est très compliqué de répartir la charge sur plusieurs machines : l'utilisation d'un système de fichiers sur le réseau engendre des latences et un trafic considérable, du fait que la base doit être rechargée chez le client à chaque ouverture. Ce problème est encore plus important avec des sites web où la base est rouverte pour chaque page demandée. De plus, il peut se produire des erreurs dans la synchronisation des verrous sur les fichiers qui pourraient autoriser l'écriture simultanée à deux clients différents sur une même partie de la base et ainsi aboutir à la corruption de la base de données ;
- avec des bases de grande envergure, il est impossible de diviser la base en plusieurs parties ou fichiers dans le but de distribuer la charge sur plusieurs machines. Certains systèmes de fichiers, comme le FAT 32, ont une taille maximale de fichier qui pourrait rapidement limiter l'expansion d'une base.
Il n'y a pas d'extension propre aux fichiers de base de données de SQLite, mais il est courant de rencontrer des extensions comme .sqlite ou .db, parfois suivie du numéro de version de la bibliothèque (.sqlite3, .db2, etc.). Il est possible d'utiliser une base de données uniquement sauvegardée en mémoire vive, sans créer de fichier de base de données sur le disque, via le nom de fichier spécial :memory:.
D'une manière générale, il est conseillé d'utiliser SQLite là où les données ne sont pas centralisées et où l'expansion de la taille de la base ne risque pas de devenir critique. Si la base de données a pour but de centraliser une grande masse de données et de les fournir à un grand nombre de clients, il est préférable d'utiliser des SGBD basés sur le paradigme client-serveur. SQLite a pour objectif de remplacer les fichiers texte et non les serveurs de base de données traditionnels[3].
Compilateur et machine virtuelle
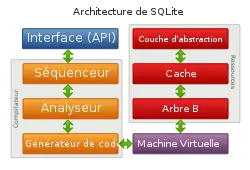
Lorsqu'une requête SQL est transmise à SQLite par l'intermédiaire de l'interface de programmation, elle est compilée avant d'être exécutée.
Le séquenceur du compilateur divise les commandes données en parties traitables séparément (une requête et sa sous-requête par exemple), celles-ci sont passées à l'analyseur syntaxique qui s'occupe de décomposer les requêtes en différents objets qui représentent les différents ordres et clauses du langage SQL. Ces objets sont passés au générateur de code qui crée un code intermédiaire de bas niveau, ou bytecode.
Le code obtenu est un ensemble d'instructions (137 instructions différentes) appelées OpCodes[7]. Celui-ci est lancé dans la machine virtuelle de SQLite, qui les voit comme de petits programmes décrivant des opérations de recherche, de lecture et de modifications des données[8].
Lorsque la machine virtuelle interprète ces instructions, elle fait appel au gestionnaire d'arbre B qui repose sur des couches de plus bas niveau dont le cache des pages disque et sa couche d'abstraction matérielle[9].
Gestion des droits
SQLite n'intègre pas de gestion des droits d'accès et de modification des données. La gestion est faite par le système de fichiers du système d'exploitation : si le fichier contenant la base de données n'est pas accessible en écriture à un utilisateur, ce dernier ne pourra également pas modifier les enregistrements et la structure de la base de données.
La gestion des droits avec GRANT et REVOKE est donc inexistante, bien que ceux-ci fassent partie de la spécification SQL-92[10].
L'utilisation d'une base SQLite ne nécessite aucune procédure d'installation ou de configuration[11].
Portabilité
La bibliothèque est entièrement écrite en C-ANSI, la version normalisée du langage de programmation C, et n'utilise aucune autre bibliothèque externe que la bibliothèque standard du langage. Ceci rend SQLite compilable sans modification majeure sur toutes les architectures informatiques mettant à disposition un compilateur C respectant la norme ANSI[12].
Les fichiers de base de données de SQLite sont entièrement indépendants du système d'exploitation et de l'architecture sur laquelle ils sont utilisés. Le même fichier de base de données peut être utilisé sur deux architectures ayant un fonctionnement radicalement différent, SQLite fournissant une couche d'abstraction transparente pour le développeur. Les fichiers sont compatibles entre eux pour chaque version majeure de la bibliothèque depuis la version 3.0.0 de SQLite, ainsi un fichier créé avec la version 3.0.0 sera utilisable avec la version 3.6.19 et vice-versa, les fichiers créés entre deux versions majeures différentes (2.0.0 et 3.0.0 par exemple) peuvent s'avérer compatibles (en particulier en compatibilité ascendante), mais ce n'est pas toujours le cas[13].
Types de données
SQLite utilise un typage dynamique pour le contenu des cellules, contrairement à la quasi-totalité des SGBD qui utilisent un typage statique : lors de la création d'une nouvelle table dans la base de données, c'est un type recommandé ou d'affinité, non forcé, de la donnée à stocker dans la colonne qui est renseigné et non un type qui définit la façon dont celle-ci sera représentée en mémoire, cette tâche étant réservée à la cellule elle-même. Lorsque des données seront entrées dans la base, SQLite tentera de convertir les nouvelles données vers le type recommandé mais ne le fera pas si cela s'avère impossible[14].
Il existe plusieurs types d'affinité dans SQLite, ceux-ci définissant la façon dont SQLite va travailler lors de l'entrée des nouvelles données[14] :
- TEXT : enregistre la donnée comme une chaine de caractères, sans limite de taille. Si un nombre est entré dans une colonne de ce type, il sera automatiquement converti en une chaine de caractères ;
- NUMERIC : tente d'enregistrer la donnée comme un entier ou comme un réel, mais si cela s'avère impossible, la donnée sera enregistrée comme une chaine de caractères ;
- INTEGER : enregistre la donnée comme un entier si celle-ci peut être encodée sans perte, mais peut utiliser les types REAL ou TEXT si ça ne peut être fait ;
- REAL : enregistre la donnée comme un réel, même s'il s'agit d'un entier. Si la valeur est trop grande, la donnée sera convertie en chaine de caractères ;
- NONE : la donnée est enregistrée telle quelle, sans conversion.
Ainsi, chaque type d'affinité peut accepter n'importe quel type de donnée, la seule exception est le type particulier INTEGER PRIMARY KEY, lorsqu'il est appliqué sur une seule colonne, car il ne s'agit pas d'un type habituel mais d'un alias à la colonne interne au moteur ROWID qui correspond à l'adresse de l'enregistrement, unique à travers la table[15].
L'utilisation d'un typage dynamique améliore l'homogénéité entre les données de la base de données et les types du langage utilisé pour l'interroger si celui-ci est également un langage au typage dynamique (comme Python, PHP, Perl ou Ruby) sans poser de réels problèmes avec les langages utilisant un typage statique (comme C/C++ ou Java).
Détermination du type d'affinité
Pour maintenir la compatibilité avec les autres bases de données relationnelles, SQLite convertit automatiquement les noms des types déclarés dans le type d'affinité correspondant le mieux, ainsi :
- tous les noms de type contenant le mot clé INT seront reconnus comme des champs INTEGER. Cependant, seule la déclaration INTEGER PRIMARY KEY sera reconnue comme un alias du ROWID ;
- tous les noms de type contenant un des mots clés suivants : CHAR (ceci comprend VARCHAR), CLOB ou TEXT seront reconnus comme des champs TEXT ;
- tous les noms de type contenant le mot clé BLOB seront reconnus comme des champs à l'affinité NONE ;
- tous les noms de type contenant un des mots clés suivants : REAL, FLOAT ou DOUBLE seront reconnus comme des champs REAL ;
- dans tous les autres cas, ou si le type n'est pas renseigné, c'est l'affinité NUMERIC qui sera utilisée.
Classes de stockage
Bien que SQLite utilise un typage dynamique, la représentation en mémoire et les traitements effectués sur les données nécessitent l'utilisation de différentes classes de stockage. Ceci est uniquement valable pour la version 3 et ses versions ultérieures, car les données étaient enregistrées comme des chaines de caractères dans les versions antérieures.
Toutes les données manipulées par le moteur de base de données utilisent l'un des types suivants[14] :
- NULL : la donnée correspond au type spécial NULL, qui indique l'absence d'information ou une valeur non définie ;
- INTEGER : la donnée est un nombre entier signé et celui-ci est enregistré, en fonction de son ordre de grandeur, sur 1, 2, 3, 4, 6 ou 8 octets, mais en mémoire, c'est converti en 8 octets (8-byte signed integer[14]) ;
- REAL : la donnée est un nombre à virgule flottante enregistré sur 8 octets selon la norme IEEE ;
- TEXT : la donnée est une chaine de caractères, encodée en UTF-8 (par défaut[16]), UTF-16-BE ou UTF-16-LE ;
- BLOB : la donnée est enregistrée comme elle a été donnée.
Type NULL
La norme ne définit pas exactement de quelle façon doit être traité le type NULL.
Comme pour la majorité des bases de données relationnelles, tous les enregistrements NULL sont considérés comme distincts par la contrainte UNIQUE mais sont considérés comme identiques par l'opérateur UNION et par le mot clé DISTINCT[17].
Les opérations arithmétiques comprenant un type NULL dans leur expression retournent la valeur UNKNOWN (valeur indéterminée). Dans les opérations booléennes, la valeur de retour pourrait être UNKNOWN si un type NULL intervient et que le résultat ne peut être déterminé avec certitude : NULL OR 1 donnera la valeur 1, mais NULL OR 0 donnera la valeur UNKNOWN car l'opération ne peut être résolue avec certitude.
Dates
SQLite ne possède pas de type pour représenter des dates. Cependant, un ensemble de fonctions existe pour manipuler celles-ci. Le stockage d'une date peut se faire dans une chaine de caractères sous sa forme ISO 8601 ou dans un entier sous la forme d'un timestamp UNIX[18].
Contraintes
SQLite gère les contraintes sur une ou plusieurs colonnes. Les contraintes NOT NULL, CHECK, DEFAULT et COLLATE sont déclarées sur la colonne[19] alors que les contraintes PRIMARY KEY, UNIQUE, CHECK et FOREIGN KEY peuvent être déclarées sur une ou plusieurs colonnes[19].
La contrainte UNIQUE crée automatiquement un index sur la ou les colonnes sur lesquelles elle est appliquée[15].
PRIMARY KEY
La contrainte de clé primaire va créer une contrainte UNIQUE sur la ou les colonnes concernées, cependant, et contrairement à la norme, la contrainte PRIMARY KEY de SQLite autorise des entrées ayant la valeur NULL. Il s'agit d'un non-respect de la norme, et cet écart pourrait être réglé dans les prochaines versions[15]. Il est donc conseillé de rajouter la contrainte NOT NULL à la déclaration d'une clé primaire.
ROWID et AUTOINCREMENT
Chaque ligne d'une table est identifiée par un entier signé de 64 bits appelé ROWID. Lorsqu'une table est déclarée avec une et une seule colonne INTEGER PRIMARY KEY, cette colonne devient un alias du ROWID. L'utilisation d'un alias à l'identifiant ROWID permet d'augmenter la vitesse des recherches, celles-ci pouvant être jusqu'à deux fois plus rapides qu'avec une clé primaire normale associée à son index d'unicité[15].
Lorsque la table est vide, l'algorithme attribue la valeur 1 à l'identifiant, qu'il incrémente pour chaque nouvel enregistrement, jusqu'à atteindre la limite d'un entier signé de 64 bits (). Une fois cette limite atteinte, il va réutiliser les espaces libérés par les enregistrements supprimés. L'attribution des identifiants n'est donc plus incrémentale mais aléatoire[20].

Il est possible d'utiliser le mot clé AUTOINCREMENT. Ce dernier modifie légèrement l'algorithme : une fois la limite d'un entier atteinte, il ne sera plus possible d'insérer un nouvel enregistrement. Ceci permet de garantir qu'un même identifiant ne sera jamais porté par deux enregistrements distincts, même s'ils ne coexistent pas à un même moment[20].
FOREIGN KEY
Depuis la version 3.6.19, SQLite est apte à gérer les contraintes de clé étrangère.
Pour des raisons de compatibilité descendante, le support des clés étrangères n'est pas activé par défaut. L'activation se fait par le pragma foreign_keys[21].
Toute colonne référencée par une clé étrangère doit être déclarée comme UNIQUE (PRIMARY KEY crée une clé d'unicité)[21]. SQLite ne prend pas encore en compte la clause MATCH dans la définition des clés étrangères[21].
Déclencheurs
SQLite gère d'une manière assez complète les déclencheurs (triggers en anglais). Des déclencheurs BEFORE, AFTER ou INSTEAD OF peuvent être déclarés. SQLite supporte l'option FOR EACH ROW (fonctionnement par défaut) mais pas FOR EACH STATEMENT[22].
Vues
SQLite permet la création de vues pour alléger la longueur des requêtes.
Les vues sont en lecture seule, mais il est possible d'utiliser des déclencheurs avec la propriété INSTEAD OF pour simuler la possibilité de modifier celles-ci[23].
Transactions
Toutes les commandes SQL visant à modifier l'état de la base de données (à peu près tout autre ordre que SELECT) impliquent la création d'une transaction qui leur est dédiée, pour autant qu'une transaction qui inclut la commande ne soit déjà créée. Ceci signifie que toutes les commandes sont atomiques. Si l'exécution de la commande ne provoque pas d'erreur, la modification est automatiquement validée (autocommit), mais si ce n'est pas le cas, l'intégralité des modifications effectuées par la commande est annulée.
Toutes les modifications sur la base de données sont sérialisées : une seule modification est effectuée à la fois et la base est verrouillée en lecture lors d'une modification.
SQLite permet la création de transactions ainsi que la création de points de retour[24] (SAVEPOINT) mais ne permet pas de gérer différents degrés d'isolation. Dans une transaction, lors du premier appel à une commande de lecture, un verrou partagé[25] est activé qui autorise l'accès en lecture mais interdit toute modification des données par une autre transaction, lors du premier appel en écriture, l'ensemble de la base est verrouillée en lecture et en écriture pour les autres transactions[26].
ACID
Même si SQLite respecte à première vue l'ensemble des propriétés ACID, qui déterminent la fiabilité d'un système transactionnel, il reste possible de placer la base de données dans un état incohérent du fait que les types ne sont pas forcés : il est possible, par exemple, d'insérer une chaine de caractères dans une colonne dont le type d'affinité est défini comme un entier. Dans leurs interprétations strictes, SQLite ne respecte pas l'ensemble des propriétés ACID.
Tables temporaires
SQLite permet la création de tables temporaires dont la définition, les données et les index ne sont pas enregistrés dans le fichier de la base de données et sont donc perdus lors de la fermeture de celle-ci[15].
Tables virtuelles
Il est possible de créer, directement depuis la bibliothèque, son propre moteur de stockage pour simuler une table de la base de données. La création d'une table virtuelle se fait par l'implémentation d'un ensemble de fonctions. L'accès à la table se fait de façon tout à fait transparente, hormis l'absence de certaines fonctionnalités (impossible de créer des déclencheurs ou des index ou de modifier la structure de la table)[27].
Ce mécanisme permet l'accès à l'aide du langage SQL à toute sorte de source de données, comme des fichiers CSV ou XML.
Fonctions utilisateur
SQLite offre une interface de programmation, via sa bibliothèque, pour la création de fonctions utilisateur. L'ensemble de fonctions définies par la bibliothèque peuvent être surchargées, pour redéfinir leur implémentation. Certains opérateurs, comme LIKE utilisent en sous-couche des fonctions éponymes qui peuvent elles aussi être remplacées par des fonctions définies par l'utilisateur[28].
SQLite ne supporte pas la création de procédures, mais leur nécessité est moindre du fait de l'architecture embarquée.
Index
SQLite permet la création d'index sur une ou plusieurs colonnes. Les index peuvent être montants (ASC) ou descendants (DESC) ainsi qu'uniques (ceci s'apparente à la création d'une contrainte d'unicité)[29]. SQLite utilise ses index en arbre B.
SQLite introduit le mot clé EXPLAIN qui permet de décrire les étapes nécessaires à l'exécution d'une commande ainsi que les index utilisés[30].
Pragmas
Les pragmas sont des paires de clés/valeurs de configuration de SQLite. Ils sont internes à une base de données et permettent de décrire de quelle façon SQLite doit interpréter certaines opérations[31]. Ils permettent également d'activer ou de désactiver certaines fonctionnalités, notamment pour des raisons de compatibilité descendante.
Adoption
Outre son implantation officielle en C, des bindings pour d'autres langages existent (C++, Perl, Ruby, TCL, les langages utilisant le framework .NET via un pilote ADO.NET[32]...).
Quelques langages de programmation incluent SQLite dans leur bibliothèque standard, c'est le cas, entre autres, de Python[33] (depuis la version 2.5) et de PHP[34] (depuis la version 5).
SQLite est utilisée dans de nombreux logiciels libres, comme Mozilla Firefox ou SPIP (depuis 2007)[35], dans de nombreuses distributions GNU/Linux, dans les systèmes d'exploitation serveurs et de bureau comme Solaris ou mobiles comme Android, Firefox OS ou Symbian, dans certains logiciels d'Apple, de Google, d'Adobe et de McAfee ainsi que dans certains appareils de Philips[4].
SQLite est également offerte avec la version 8.4 du Logiciel Primavera P6 d'Oracle.
Le brouillon concernant le stockage d'une base de données SQL du côté du navigateur web publiée par le W3C stipule également que les logiciels implémentant cette fonctionnalité doivent être capable d'interpréter correctement le dialecte de SQLite dans sa version 3.6.19[36]. Même si SQLite n'est pas imposé par le W3C, Google Chrome[37], Apple Safari[38] et Opera Browser[39] l'utilisent pour cet usage.
Différentes versions
SQLite existe sous 2 principales versions : 2.x et 3.x. Les versions 2 et 3 de SQLite se distinguent par plusieurs évolutions :
- les fichiers des bases ne sont pas toujours compatibles entre eux. Cela signifie qu’une base au format SQLite 2 ne pourra pas être lue à coup sûr par SQLite 3 et vice versa ;
- des syntaxes SQL ne sont pas présentes en SQLite 2 : IF NOT EXISTS pour les requêtes, et CREATE TABLE, ADD COLUMN et RENAME COLUMN pour les requêtes ALTER TABLE ;
- seules les versions les plus récentes de SQLite prennent en charge certaines fonctionnalités plus avancées, comme la gestion des clés étrangères ou les contraintes CHECK ;
- SQLite 3 prend en charge les normes UTF-8 et UTF-16 ;
- SQLite 3 encode les identifiants de lignes sur 64 bits et non plus sur 32 bits, ce qui permet un nombre de lignes quasiment illimité ;
- PHP utilise une classe PDO ou, avec PHP 5.3, des fonctions sqlite3_*() pour gérer SQLite 3 alors qu’il utilise des fonctions sqlite_*() pour SQLite 2.
Notes et références
- « SQLite Release 3.39.2 On 2022-07-21 »
- « SQLite Copyright », sur www.sqlite.org
- « About SQLite », sur www.sqlite.org
- « Well-Known Users Of SQLite », sur www.sqlite.org
- « Most Widely Deployed SQL Database Engine », sur www.sqlite.org
- (en) Michael Owens, The Definitive Guide to SQLite, Berkeley, Apress, (ISBN 978-1-59059-673-9, DOI 10.1007/978-1-4302-0172-4_1)
- « The SQLite Bytecode Engine », sur www.sqlite.org
- « The Virtual Database Engine of SQLite », sur www.sqlite.org
- « Architecture of SQLite », sur www.sqlite.org
- « SQL Features That SQLite Does Not Implement », sur www.sqlite.org
- « Zero-Configuration », sur www.sqlite.org
- « SQLite is a Self Contained System », sur www.sqlite.org
- « SQLite: Single File Database », sur www.sqlite.org
- « Datatypes In SQLite Version 3 », sur www.sqlite.org
- « SQLite Query Language: CREATE TABLE », sur www.sqlite.org
- « SQLite Version 3 Overview », sur www.sqlite.org
- « NULL Handling in SQLite », sur www.sqlite.org
- « SQLite Query Language: Date And Time Functions », sur www.sqlite.org
- « Syntax Diagrams For SQLite », sur www.sqlite.org
- « SQLite Autoincrement », sur www.sqlite.org
- « SQLite Foreign Key Support », sur www.sqlite.org
- « SQLite Query Language: CREATE TRIGGER », sur www.sqlite.org
- « SQLite Query Language: CREATE VIEW », sur www.sqlite.org
- « SQLite Query Language: SAVEPOINT », sur www.sqlite.org
- « File Locking And Concurrency In SQLite Version 3 », sur www.sqlite.org
- « SQLite Query Language: BEGIN TRANSACTION », sur www.sqlite.org
- « The Virtual Table Mechanism Of SQLite », sur www.sqlite.org
- « SQLite Query Language: Core Functions », sur www.sqlite.org
- « SQLite Query Language: CREATE INDEX », sur www.sqlite.org
- « SQLite Query Language: EXPLAIN », sur www.sqlite.org
- « Pragma statements supported by SQLite », sur www.sqlite.org
- http://sqlite.phxsoftware.com/
- « sqlite3 — DB-API 2.0 interface for SQLite databases — Python 3.7.3 documentation », sur docs.python.org
- « PHP: Hypertext Preprocessor », sur www.php.net
- Déesse A. et Matthieu Marcillaud, « Portage de SPIP en SQLite », sur contrib.spip.net, (consulté le )
- « Web SQL Database », sur dev.w3.org
- « More Resources for Developers »
- « WebKit HTML 5 SQL Storage Notes Demo », sur webkit.org
- « Dev.Opera — Blog », sur dev.opera.com
Liens externes
- Site officiel
- (en) The SQLite Consortium, Mitchell Baker, le 27 février 2008.
- SQLite devient la base de données standard du Web déconnecté, David Maume, 01net, .
 Portail des bases de données
Portail des bases de données  Portail des logiciels libres
Portail des logiciels libres