UTF-8
UTF-8 (abréviation de l'anglais Universal Character Set Transformation Format[1] - 8 bits) est un codage de caractères informatiques conçu pour coder l'ensemble des caractères du « répertoire universel de caractères codés », initialement développé par l'ISO dans la norme internationale ISO/CEI 10646, aujourd'hui totalement compatible avec le standard Unicode, en restant compatible avec la norme ASCII limitée à l'anglais de base, mais très largement répandue depuis des décennies.
L'UTF-8 est utilisé par 82,2 % des sites web en [2], 87,6 % en 2016[3], 90,5 % en 2017[4], 93,1 % en [5] et près de 95,2 % en . Par sa nature, UTF-8 est d'un usage de plus en plus courant sur Internet, et dans les systèmes devant échanger de l'information. Il s'agit également du codage le plus utilisé dans les systèmes GNU/Linux et compatibles pour gérer le plus simplement possible des textes et leurs traductions dans tous les systèmes d'écritures et tous les alphabets du monde.
Liens avec la norme internationale ISO/CEI 10646 et les standards Unicode et d'Internet
UTF-8 est un « format de transformation » issu à l'origine des travaux pour la norme ISO/CEI 10646, c'est-à-dire que UTF-8 définit un codage pour tout point de code scalaire (caractère abstrait ou « non-caractère ») du répertoire du jeu universel de caractères codés (Universal Character Set, ou UCS). Ce répertoire est aujourd'hui commun à la norme ISO/CEI 10646 (depuis sa révision 1.) et au standard Unicode (depuis sa version 1.1).
UTF-8 est officiellement défini dans la norme ISO/CEI 10646 depuis son adoption dans un amendement publié en 1996. Il fut aussi décrit dans le standard Unicode et fait partie de ce standard depuis la version 3.0 publiée en 2000. En 1996 fut publiée la RFC 2044[6] (« UTF-8, a transformation format of ISO 10646 ») dans le but de fournir une spécification accessible d'UTF-8 et d'entamer sa standardisation au sein de l'Internet Engineering Task Force (IETF). Cette RFC fut révisée en 1998 (RFC 2279[7]) puis finalement en 2003 (RFC 3629[8]), cette dernière version faisant d'UTF-8 un des standards de l'internet (STD 63).
Description technique
Techniquement, il s'agit de coder les caractères Unicode sous forme de séquences de un à quatre codets d'un octet chacun. La norme Unicode définit entre autres un ensemble (ou répertoire) de caractères. Chaque caractère est repéré dans cet ensemble par un index entier aussi appelé « point de code ». Par exemple le caractère « € » (euro) est le 8365e caractère du répertoire Unicode, son index, ou point de code, est donc 8364 (0x20AC) (on commence à compter à partir de 0).
Le répertoire Unicode peut contenir plus d'un million de caractères, ce qui est bien trop grand pour être codé par un seul octet (limité à des valeurs entre 0 et 255). La norme Unicode définit donc des méthodes standardisées pour coder et stocker cet index sous forme de séquence d'octets : UTF-8 est l'une d'entre elles, avec UTF-16, UTF-32 et leurs différentes variantes.
La principale caractéristique d'UTF-8 est qu'elle est rétro-compatible avec le standard ASCII, c'est-à-dire que tout caractère ASCII se code en UTF-8 sous forme d'un unique octet, identique au code ASCII. Par exemple « A » (A majuscule) a pour code ASCII 65 (0x41) et se code en UTF-8 par l'octet 65. Chaque caractère dont le point de code est supérieur à 127 (0x7F) (caractère non ASCII) se code sur 2 à 4 octets. Le caractère « € » (euro) se code par exemple sur 3 octets : 226, 130, et 172 (0xE2, 0x82 et 0xAC).
Description
Le numéro (valeur scalaire) de chaque point de code dans le jeu universel de caractères (UCS) est donné par la norme ISO/CEI 10646 qui assigne un point de code à chaque caractère valide, puis permet leur codage en leur attribuant une valeur scalaire identique au point de code ; cette norme est reprise dans le standard Unicode (qui utilise depuis la version 1.1 le même répertoire).
Tous les « points de code » (code points en anglais) de U+0000 à U+D7FF et de U+E000 à U+10FFFF sont représentables en UTF-8 — même ceux qui sont attribués à des « non-caractères » (non-character) et tous ceux qui ne sont pas encore attribués — et uniquement ceux-là. Les seuls points de code valides dans l'espace de l'UCS et qui ne doivent pas être représentés dans UTF-8 sont ceux qui sont attribués aux « demi-codets » (surrogates en anglais), car ils ne sont pas représentables de façon bijective dans le codage UTF-16 et ne sont pas non plus par eux-mêmes des caractères : contrairement aux autres points de code, les demi-codets n'ont donc pas de « valeur scalaire » (scalar value en anglais) définie.
Les points de code ayant une valeur scalaire de 0 à 127 (points de codes U+0000 à U+007F, attribués aux caractères du jeu codé sur 7 bits dans l'ASCII) sont codés sur un seul octet dont le bit de poids fort est nul.
Les autres points de code (attribués ou non à des caractères) ayant une valeur scalaire supérieure à 127 (sauf ceux auxquels sont attribués des « demi-codets » qui ne sont pas eux-mêmes des caractères) sont codés sur plusieurs octets ayant chacun leur bit de poids fort non nul : les bits de poids fort du premier octet de la séquence codée forment une suite de 1 de longueur égale au nombre total d'octets (au moins 2) utilisés pour la séquence entière suivie d'un 0 et les octets suivants nécessaires ont leurs deux bits de poids fort positionnés à 10.
| Caractères codés | Représentation binaire UTF-8 | Premier octet valide (hexadécimal) | Signification |
|---|---|---|---|
| U+0000 à U+007F | 0ƀƀƀ·ƀƀƀƀ | 00 à 7F | 1 octet, codant jusqu'à 7 bits |
| U+0080 à U+07FF | 110ƀ·ƀƀƀƀ 10ƀƀ·ƀƀƀƀ | C2 à DF | 2 octets, codant jusqu'à 11 bits |
| U+0800 à U+FFFF | 1110·ƀƀƀƀ 10ƀƀ·ƀƀƀƀ 10ƀƀ·ƀƀƀƀ | E0 à EF | 3 octets, codant jusqu'à 16 bits |
| U+10000 à U+10FFFF | 1111·00ƀƀ 10ƀƀ·ƀƀƀƀ 10ƀƀ·ƀƀƀƀ 10ƀƀ·ƀƀƀƀ | F0 à F3 | 4 octets, codant jusqu'à 21 bits |
| 1111·0100 1000·ƀƀƀƀ 10ƀƀ·ƀƀƀƀ 10ƀƀ·ƀƀƀƀ | F4 |
Ce principe pourrait être étendu jusqu'à huit octets pour un seul point de code (pour représenter des points de code comprenant jusqu'à 42 bits), mais la version normalisée actuelle d'UTF-8 pose la limite à quatre[9].
Le codage interdit la représentation des points de code réservés aux demi-codets (qui n'ont pas de valeur scalaire définie, afin de préserver la compatibilité avec UTF-16 qui ne permet pas non plus de les représenter). Il autorise cependant la représentation des points de code assignés à des non-caractères (alors même que leur présence est interdite dans un texte conforme).
Exemples
| Type | Caractère | Point de code (hexadécimal) |
Valeur scalaire | Codage UTF-8 | ||
|---|---|---|---|---|---|---|
| décimal | binaire | binaire | hexadécimal | |||
| Contrôle | [NUL] | U+0000 | 0 | 0 | 00000000 | 00 |
| [US] | U+001F | 31 | 1·1111 | 00011111 | 1F | |
| Texte | [SP] | U+0020 | 32 | 10·0000 | 00100000 | 20 |
| A | U+0041 | 65 | 100·0001 | 01000001 | 41 | |
| ~ | U+007E | 126 | 111·1110 | 01111110 | 7E | |
| Contrôle | [DEL] | U+007F | 127 | 111·1111 | 01111111 | 7F |
| [PAD] | U+0080 | 128 | 000 1000·0000 | 11000010 10000000 | C2 80 | |
| [APC] | U+009F | 159 | 000 1001·1111 | 11000010 10011111 | C2 9F | |
| Texte | [NBSP] | U+00A0 | 160 | 000 1010·0000 | 11000010 10100000 | C2 A0 |
| é | U+00E9 | 233 | 000 1110·1001 | 11000011 10101001 | C3 A9 | |
| ߿ | U+07FF | 2047 | 111 1111·1111 | 11011111 10111111 | DF BF | |
| ࠀ | U+0800 | 2048 | 1000 0000·0000 | 11100000 10100000 10000000 | E0 A0 80 | |
| € | U+20AC | 8 364 | 10·0000 1010·1100 | 11100010 10000010 10101100 | E2 82 AC | |
| | U+D7FF | 55 295 | 1101·0111 1111·1111 | 11101101 10011111 10111111 | ED 9F BF | |
| Demi-codet | U+D800 | (néant) | (codage interdit) | |||
| U+DFFF | ||||||
| Usage privé | [] | U+E000 | 57 344 | 1110·0000 0000·0000 | 11101110 10000000 10000000 | EE 80 80 |
| [] | U+F8FF | 63 743 | 1111·1000 1111·1111 | 11101111 10100011 10111111 | EF A3 BF | |
| Texte | U+F900 | 63 744 | 1111·1001 0000·0000 | 11101111 10100100 10000000 | EF A4 80 | |
| ﷏ | U+FDCF | 64 975 | 1111·1101 1100·1111 | 11101111 10110111 10001111 | EF B7 8F | |
| Non-caractères | U+FDD0 | 64 976 | 1111·1101 1101·0000 | 11101111 10110111 10010000 | EF B7 90 | |
| U+FDEF | 65 007 | 1111·1101 1110·1111 | 11101111 10110111 10101111 | EF B7 AF | ||
| Texte | ﷰ | U+FDF0 | 65 008 | 1111·1101 1111·0000 | 11101111 10110111 10110000 | EF B7 B0 |
| � | U+FFFD | 65 533 | 1111·1111 1111·1101 | 11101111 10111111 10111101 | EF BF BD | |
| Non-caractères | U+FFFE | 65 534 | 1111·1111 1111·1110 | 11101111 10111111 10111110 | EF BF BE | |
| U+FFFF | 65 535 | 1111·1111 1111·1111 | 11101111 10111111 10111111 | EF BF BF | ||
| Texte | 𐀀 | U+10000 | 65 536 | 1 0000·0000 0000·0000 | 11110000 10010000 10000000 10000000 | F0 90 80 80 |
| 𝄞 | U+1D11E | 119 070 | 1 1101·0001 0001·1110 | 11110000 10011101 10000100 10011110 | F0 9D 84 9E | |
| | U+1FFFD | 131 069 | 1 1111·1111 1111·1101 | 11110000 10011111 10111111 10111101 | F0 9F BF BD | |
| Non-caractères | U+1FFFE | 131 070 | 1 1111·1111 1111·1110 | 11110000 10011111 10111111 10111110 | F0 9F BF BE | |
| U+1FFFF | 131 071 | 1 1111·1111 1111·1111 | 11110000 10011111 10111111 10111111 | F0 9F BF BF | ||
| Texte | 𠀀 | U+20000 | 131 072 | 10 0000·0000 0000·0000 | 11110000 10100000 10000000 10000000 | F0 A0 80 80 |
| | U+2FFFD | 196 605 | 10 1111·1111 1111·1101 | 11110000 10101111 10111111 10111101 | F0 AF BF BD | |
| Non-caractères | U+2FFFE | 196 606 | 10 1111·1111 1111·1110 | 11110000 10101111 10111111 10111110 | F0 AF BF BE | |
| U+2FFFF | 196 607 | 10 1111·1111 1111·1111 | 11110000 10101111 10111111 10111111 | F0 AF BF BF | ||
| ...autres plans réservés... | ||||||
| Spéciaux | | U+E0000 | 917 504 | 1110 0000·0000 0000·0000 | 11110011 10100000 10000000 10000000 | F3 A0 80 80 |
| | U+EFFFD | 983 037 | 1110 1111·1111 1111·1101 | 11110011 10101111 10111111 10111101 | F3 AF BF BD | |
| Non-caractères | U+EFFFE | 983 038 | 1110 1111·1111 1111·1110 | 11110011 10101111 10111111 10111110 | F3 AF BF BE | |
| U+EFFFF | 983 039 | 1110 1111·1111 1111·1111 | 11110011 10101111 10111111 10111111 | F3 AF BF BF | ||
| Usage privé | [] | U+F0000 | 983 040 | 1111 0000·0000 0000·0000 | 11110011 10110000 10000000 10000000 | F3 B0 80 80 |
| [] | U+FFFFD | 1 048 573 | 1111 1111·1111 1111·1101 | 11110011 10111111 10111111 10111101 | F3 BF BF BD | |
| Non-caractères | U+FFFFE | 1 048 574 | 1111 1111·1111 1111·1110 | 11110011 10111111 10111111 10111110 | F3 BF BF BE | |
| U+FFFFF | 1 048 575 | 1111 1111·1111 1111·1111 | 11110011 10111111 10111111 10111111 | F3 BF BF BF | ||
| Usage privé | [] | U+100000 | 1 048 576 | 1·0000 0000·0000 0000·0000 | 11110100 10000000 10000000 10000000 | F4 80 80 80 |
| [] | U+10FFFD | 1 114 109 | 1·0000 1111·1111 1111·1101 | 11110100 10001111 10111111 10111101 | F4 8F BF BD | |
| Non-caractères | U+10FFFE | 1 114 110 | 1·0000 1111·1111 1111·1110 | 11110100 10001111 10111111 10111110 | F4 8F BF BE | |
| U+10FFFF | 1 114 111 | 1·0000 1111·1111 1111·1111 | 11110100 10001111 10111111 10111111 | F4 8F BF BF | ||
Caractéristiques
Dans toute chaîne de caractères codée en UTF-8, on remarque que :
- tout octet de bit de poids fort nul désigne un unique « point de code » assigné à un caractère du répertoire de l'US-ASCII et codé sur ce seul octet, d'une valeur scalaire identique à celle du codet utilisé dans le codage US-ASCII ;
- tout octet de bits de poids fort valant 11 est le premier octet d'une séquence unique représentant un « point de code » (assigné à un caractère ou un non-caractère) et codé sur plusieurs octets ;
- tout octet de bits de poids fort valant 10 est un des octets suivants d'une séquence unique représentant un « point de code » (assigné à un caractère ou un non-caractère) et codé sur plusieurs octets ;
- aucun octet ne peut prendre une valeur hexadécimale entre C0 et C1, ni entre F5 et FF (le plus haut point de code valide et assigné à un caractère représentable est U+10FFFD ; c'est un caractère à usage privé alloué dans le 17e plan valide).
Le plus grand point de code valide assignable à un caractère valide non privé est U+EFFFD dans le 15e plan (il n'est pas encore assigné mais peut le devenir dans l'avenir), mais le codage UTF-8 peut être utilisé aussi, de façon conforme aux normes, pour représenter n'importe quel caractère valide à usage privé (dans une des trois plages U+E000 à U+F8FF, U+F0000 à U+FFFFD, et U+100000 à U+10FFFD).
L'acceptation ou non des non-caractères ou des caractères d'usage privé est laissée aux applications ou protocoles de transport de texte. Cependant les non-caractères ne sont normalement pas acceptés dans des textes strictement conformes au standard Unicode où à la norme ISO/CEI 10646.
Certaines applications imposent des restrictions supplémentaires sur les points de code utilisables (par exemple, les standards HTML et XML interdisent, dans tout document conforme à ces spécifications, la présence de la plupart des caractères de contrôle entre U+0000 et U+001F et entre U+0080 et U+009F, en dehors du contrôle de la tabulation U+0009 considéré comme un caractère blanc, et interdisent aussi les non-caractères).
Tout point de code est toujours représenté par exactement la même séquence binaire, quelle que soit sa position relative dans le texte, et ces séquences sont autosynchronisées sur la position indivise des codets significatifs (ici les octets : on peut toujours savoir si un octet débute ou non une séquence binaire effective) ; ce codage autorise donc les algorithmes rapides de recherche de texte, tels que l'algorithme de Boyer-Moore.
Ce n'est pas toujours le cas des codages contextuels (qui utilisent généralement la compression de données, par exemple SCSU défini dans la note technique standard UTS#6 optionnelle complétant le standard Unicode) et qui peuvent nécessiter de lire le texte complètement depuis le début, ni des codages basés sur plus d'une seule variable d'état (ou qui incorporent des codes supplémentaires de redondance) ; au mieux certains de ces codages peuvent demander d'utiliser des algorithmes complexes de resynchronisation, basés souvent sur des heuristiques qui peuvent échouer ou conduire à de fausses interprétations si on ne lit pas le texte depuis le début (par exemple BOCU-1).
Principe et unicité du codage
Dans le tableau ci-dessus, on voit que le caractère « € » se trouve au point de code U+20AC, soit en décimal 8364, ou en binaire : 100000 10101100.
Ce dernier nombre comporte chiffres binaires significatifs, donc 14 bits au moins sont nécessaires pour coder le caractère « € ». La norme présentée ci-dessus impose en réalité trois octets pour représenter ces caractères.

Avec quatre octets à disposition, il serait possible de placer selon cette norme jusqu'à 21 bits, donc en particulier de représenter le caractère « € » par 00000 00100000 10101100, en lui ajoutant en tête 7 zéros non significatifs. Toutefois, la norme impose qu'un programme décodant l'UTF-8 ne doit pas accepter de chaînes d'octets inutilement longues comme dans cet exemple, ce pour des raisons de sécurité (éviter l'exploitation de tests de sous-chaînes trop tolérants)[10]. Ainsi « € » se codera : 11100010 10000010 10101100, mais le codage 11110000 10000010 10000010 10101100, déduit de la représentation de « € » sur 21 bits, bien qu'univoque, ne doit pas être utilisé.
Une telle forme plus longue que nécessaire s'appelle en anglais overlong. De telles formes (initialement autorisées dans des spécifications anciennes avant qu'elles soient normalisées successivement par la RFC initiale publiée par le Consortium X/Open, puis parallèlement par la norme ISO 10646 et le standard Unicode) sont interdites et doivent être traitées comme invalides.
Types d'octets, séquences valides et décodage
Le codage est prédictif et permet toujours de retrouver la position du premier octet d'une séquence représentant un point de code, à partir de la valeur d'un octet quelconque et de la lecture d'un nombre limité d'octets voisins, dans les deux directions de lecture (ce sera toujours l'octet lui-même, ou le premier éligible dans un des 1 à 3 octets voisins).
- Tout octet de continuation dans une séquence UTF-8 valide ne peut prendre que les valeurs hexadécimales 80 à BF ;
- il ne peut exister qu'à la suite d'un octet de début de séquence (représentant un point de code), qui sera le dernier codé dans un des 1 à 3 octets précédents et qui n'est pas non plus un octet de continuation ;
- le point de code suivant, s'il y en a un, ne peut commencer au maximum que dans les 1 à 3 octets suivants.
- Le premier octet d'une séquence UTF-8 valide ne peut prendre que les valeurs hexadécimales 00 à 7F ou C2 à F4 :
- le premier octet hexadécimal 00 à 7F d'une séquence n'est suivi d'aucun octet de continuation ;
- le premier octet hexadécimal C2 à DF d'une séquence est toujours suivi d'un seul octet de continuation (chacun de valeur hexadécimale entre 80 et BF) ;
- le premier octet hexadécimal E0 à EF d'une séquence est toujours suivi de deux octets de continuation (chacun de valeur hexadécimale entre 80 et BF) ;
- cependant, si le premier octet d'une séquence prend la valeur hexadécimale E0, le premier octet de continuation est restreint à une valeur hexadécimale entre A0 et BF ;
- cependant, si le premier octet d'une séquence prend la valeur hexadécimale ED, le premier octet de continuation est restreint à une valeur hexadécimale entre 80 et 9F ;
- le premier octet hexadécimal F0 à F4 d'une séquence est toujours suivi de trois octets de continuation (chacun de valeur hexadécimale entre 80 et BF) ;
- cependant, si le premier octet d'une séquence prend la valeur hexadécimale F0, le premier octet de continuation est restreint à une valeur hexadécimale entre 90 et BF ;
- cependant, si le premier octet d'une séquence prend la valeur hexadécimale F4, le premier octet de continuation est restreint à une valeur hexadécimale entre 80 et 8F.
Séquences interdites
- Les points de code sont toujours représentés par la séquence d'octets la plus courte possible :
- par conséquent, aucune séquence d'octets ne contient des octets initiaux de valeur hexadécimale C0 ou C1 dans un texte valide codé en UTF-8 ;
- de même, aucune séquence commençant par l'octet initial E0 ne peut avoir un premier octet de continuation de valeur hexadécimale 80 à 9F.
- Les points de code allant de U+D800 à U+DFFF sont interdits (leur valeur scalaire est réservée pour la représentation UTF-16 des points de code supplémentaires avec des paires de demi-codets) :
- par conséquent, le premier octet de continuation d'une séquence qui commence par l'octet hexadécimal ED ne peut prendre aucune des valeurs hexadécimales A0 à BF ;
- ces séquences interdites en UTF-8 sont en revanche autorisées dans la transformation CESU-8 (non recommandée, qui ne doit en aucun cas être confondue avec UTF-8, car CESU-8 utilise ces séquences pour coder les caractères des plans supplémentaires en 2 séquences de 3 octets chacune, au lieu d'une seule séquence de 4 octets en UTF-8).
- De même que tout codage pouvant donner un point de code de valeur supérieure à U+10FFFF est interdit :
- par conséquent, le premier octet de continuation d'une séquence qui commence par l'octet hexadécimal F4 ne peut prendre aucune des valeurs hexadécimales 90 à BF ;
- et aucune séquence d'octets ne contient des octets initiaux de valeur hexadécimale F5 à FF.
De telles séquences sont dites mal formées (ill-formed). (Voir la référence ci-dessus, notamment la seconde table dans la clause de conformité D36 du standard ou l'article Unicode).
En revanche, les points de code réservés (pas encore alloués à des caractères) sont autorisés (même si l'interprétation des caractères peut rester ambigüe) : il appartient aux applications de décider si ces caractères sont acceptables ou non, sachant que les mêmes applications continueront probablement à être utilisées alors que ces positions auront été assignées dans les normes Unicode et ISO 10646 à de nouveaux caractères parfaitement valides.
De même les autres points de code assignés de façon permanente aux autres « non-caractères » sont interdits dans les textes conformes à la norme ISO/CEI 10646 ou au standard Unicode : par exemple U+xFFFE à U+xFFFF (où x indique un numéro de plan hexadécimal de 0 à 10). Mais ils restent codables et décodables en tant que tels en UTF-8 (les non-caractères sont à disposition des applications qui peuvent en faire un usage au sein d'API internes, par exemple comme codes intermédiaires nécessaires à l'implémentation de certains traitements).
La restriction de l'espace de représentation aux seuls points de code inférieurs ou égaux à U+10FFFF (non compris les points de codes assignés aux demi-codets) n'a pas toujours été appliquée :
- Cela n'a pas toujours été le cas dans la norme ISO/CEI 10646, qui prévoyait à l'origine de pouvoir coder un très grand nombre de plans possibles (l'UCS-4 permettait un codage jusqu'à 31 bits), alors que Consortium Unicode (depuis la fusion du répertoire commun dans sa version 1.1) n'utilisait encore que le plan multilingue de base et n'avait pas encore envisagé de couvrir autant d'écritures qu'aujourd'hui ;
- L'introduction par Unicode du codage UTF-16 dans une annexe standard (quand il a admis que plus de 65536 caractères seraient rapidement nécessaires) a demandé l'allocation préalable par l'ISO/CEI 10646 d'un bloc de points de codes pour des « demi-codets » qui étaient considérés au début par l'ISO/CEI 10646 comme des caractères spéciaux (une concession faite à Unicode alors que l'UCS-4 avait été créé comme un espace de codage linéaire où tous les points de code avaient une valeur scalaire), alors qu'Unicode n'utilisait encore que le sous-espace UCS-2 et pas l'espace UCS-4 complet ;
- Pour éviter des problèmes d'interopérabilité avec les autres applications (non Unicode) basées sur UCS-2, une première révision de l'UTF-8 a été publiée par l'ISO en 1998, mentionnant que ces demi-codets n'avaient donc pas de valeur scalaire définie et qu'aucun point de code assignés aux « demi-codets » dans les deux blocs successifs alloués ne devait pas être codés en UTF-8 ;
- Mais selon l'accord final intervenu entre le comité technique du Consortium Unicode et celui chargé de la norme ISO/CEI 10646, toute utilisation de plus de 17 plans a été proscrite, afin d'assurer l'interopérabilité totale avec le codage UTF-16 défini par Unicode, un codage déjà massivement déployé dans les systèmes d'exploitation (par exemple Microsoft Windows), ou sous-systèmes (par exemple OpenType), ou encore dans de nombreux langages de programmation qui en dépendent pour leur interopérabilité (dont certains issus de normes nationales ou internationales, tels que les langages C et C++ qui ont eu des difficultés à supporter le répertoire universel) ;
- En effet, après une vingtaine d'années d'efforts pour la définition de l'UCS pour toutes les écritures du monde, des règles plus strictes ont été établies pour limiter les caractères codables selon un modèle assurant une compatibilité ascendante mais aussi de meilleures pratiques de codage. Pratiquement toutes les écritures modernes du monde ont été codées, et on dispose d'estimations fiables de l'ordre de grandeur sur la quantité de caractères nécessaires pour le support des autres écritures, ainsi que sur les besoins de codage pour de nouveaux caractères ;
- La croissance initiale très forte des allocations dans l'UCS (ou des caractères restant encore à coder) s'est fortement ralentie, et seulement 6 des 17 plans sont utilisés fin 2011 (mais deux seulement ont un taux de remplissage significatif : le plan multilingue de base, pratiquement plein, et le plan idéographique supplémentaire ; c'est sur le plan multilingue complémentaire que se concentrent la majorité des autres écritures anciennes restant à coder, ou des nouveaux ensembles de symboles et caractères de notation technique) ;
- Le rythme de croissance des allocations dans l'UCS pour la norme ISO/CEI 10646 ne permet pas d'envisager sa saturation avant un terme dépassant de très loin le cycle de vie des normes internationales (et encore plus celui des standards industriels comme Unicode). À ce terme trop lointain, il est tout à fait possible que UTF-16 soit devenu obsolète depuis fort longtemps, ou qu'une nouvelle norme de codification ait vu le jour et ait été massivement déployée (et que les outils de conversion automatique auront aussi été normalisés et déployés). Rien ne justifie encore de maintenir une extension possible non nécessaire au besoin immédiat d'interopérabilité des normes et standards actuels ou des futures normes envisagées ;
- Un ou deux autres plans seulement sont envisagés pour les écritures sinographiques, anciennes écritures cunéiformes ou hiéroglyphiques, et éventuellement un autre plan pour des collections de symboles et pictogrammes nécessaires à l'interopérabilité de certaines applications modernes (par exemple les emojis des messageries et services interactifs est-asiatiques, ou des symboles nécessaires à des normes internationales de signalisation ou de sécurité) ;
- Les « groupes » supplémentaires d'usage privé à la fin de l'UCS-4, ainsi que les « plans » supplémentaires d'usage privé dans l'UCS-4 à la fin du groupe 0, qui avaient été envisagés par l'ISO depuis le début de ses travaux de normalisation, ont été abandonnés pour ne garder, parmi les 17 premiers plans du premier groupe, que les deux derniers plans à cet usage privé (en plus du bloc d'usage privé U+E000 à U+F8FF déjà alloué dans le plan multilingue de base), ce qui s'avère suffisant pour toutes les applications ;
- Cela a fait l‘objet de la révision en 2003 de la RFC publiée par le comité technique de l'ISO définissant le codage UTF-8 pour la norme ISO/CEI 10646, et simultanément d'une mise à jour de l'annexe standard au standard Unicode (une annexe standard qui a, depuis, été intégrée au standard lui-même) ;
- Depuis ces mises à jour de 2003, le codage UCS-4 défini par la norme ISO/CEI 10646 est devenu en pratique équivalent à UTF-32 (défini dans la norme Unicode qui adjoint des propriétés supplémentaires mais sans différence de codage). Et la dernière RFC publiée par l'ISO et approuvée par l'IETF en 2003 fait d'ailleurs maintenant une référence normative à la définition de l'UTF-8 publiée conjointement avec (ou dans) le standard Unicode.
Avantages
Universalité
- Ce codage permet de représenter les milliers de caractères du répertoire universel, commun à la norme ISO/CEI 10646 et au standard Unicode (du moins depuis sa version 1.1.1).
Compatibilité avec US-ASCII
Un texte en US-ASCII est codé identiquement en UTF-8 (lorsque le BOM n'est pas utilisé).
Interopérabilité
Du fait qu'un caractère est découpé en une suite d'octets (et non en mots de plusieurs octets), il n'y a pas de problème de boutisme (endianness en anglais).
- Ce problème apparaît avec les codages UTF-16 et UTF-32 par exemple, si on ne les utilise pas avec un marqueur d'ordonnancement (appelé BOM pour Byte Order Mark) codé en début de fichier à l'aide du caractère U+FEFF, qui était auparavant destiné à un autre usage (ZWNBSP pour zero-width non-breaking space, une fonction d'agglutination de mots à afficher sans espace séparatrice ni césure que remplit aujourd'hui le caractère WJ pour word-joiner). En revanche, les codages dérivés UTF-16BE, UTF-16LE, UTF-32BE et UTF-32LE sont conçus avec un ordonnancement précis ne nécessitant l'emploi d'aucun BOM ;
- Pour différentes raisons de compatibilité (notamment via des processus de transcodage), il est cependant resté admis qu'un BOM (U+FEFF), non absolument nécessaire, puisse encore être codé en tête d'un fichier UTF-8 (leur interprétation reste celle du caractère ZWNBSP, même si de nombreux protocoles ont choisi d'ignorer et filtrer silencieusement ce caractère puisqu'il ne sert plus qu'à cet usage et que son ancienne fonction, quand elle reste nécessaire à l'interprétation du texte lui-même, est désormais transférée sur un autre caractère codé exprès).
Efficacité
Pour la plupart des langues à écriture latine, les fichiers de données numériques ou les codes sources de programmes, ou de nombreux protocoles textuels de communication (comme FTP, HTTP ou MIME), qui utilisent abondamment (voire parfois exclusivement dans certaines parties) les caractères US-ASCII, UTF-8 nécessite moins d'octets que l'UTF-16 ou l'UTF-32.
Réutilisabilité
De nombreuses techniques de programmation informatique valables avec les caractères uniformément codés sur un octet le restent avec UTF-8, notamment :
- la manière de repérer la fin d'une chaîne de caractères C, car tout octet binaire 00000000 trouvé dans une chaîne de caractères codés en UTF-8 est toujours le caractère nul (en revanche il est alors impossible de représenter le caractère NUL lui-même comme membre de la chaîne de caractères, à moins que l'information de longueur effective du texte codé soit stockée ou transportée en dehors de celui-ci, auquel cas cet octet sera interprété comme tel au sein même des chaînes codées en UTF-8) ;
- la manière de trouver une sous-chaîne est identique.
Fiabilité
Il s'agit d'un codage auto-synchronisant (en lisant un seul octet on sait si c'est le premier d'un caractère ou non).
- Il est possible, depuis n'importe quelle position dans un texte codé, de remonter au premier octet de la séquence en lisant une toute petite quantité d'octets antérieurs, soit au maximum 3 octets, ou de trouver facilement le début de la séquence suivante, là encore en ne sautant qu'au maximum 3 octets) ;
- une séquence décrivant un caractère n'apparaît jamais dans une séquence plus longue décrivant un autre caractère (comme c'est le cas de Shift-JIS) ;
- il n'existe pas de code « d'échappement » changeant l'interprétation (comme caractères) de la suite d'une séquence d'octets.
Inconvénients
Taille variable
Les points de code sont représentés en UTF-8 par des séquences d'octets de taille variable (de même qu'en UTF-16), ce qui rend certaines opérations sur les chaînes de points de code plus compliquées : le calcul du nombre de points de code ; le positionnement à une distance donnée (exprimée en nombre de points de code) dans un fichier texte et en règle générale toute opération nécessitant l'accès au point de code de position N dans une chaîne.
Une taille variable des caractères d'une chaine empêche l'exploitation d'algorithmes efficaces en matière de comparaisons de chaines, telles que l'algorithme de Knuth-Morris-Pratt et pénalise donc fortement les traitements de données en masse comme dans l'exploitation des bases de données. Ce problème est toutefois davantage lié aux aspects de normalisation que de codage.
Efficacité
Pour les langues utilisant beaucoup de caractères extérieurs à US-ASCII, UTF-8 occupe sensiblement plus d'espace. Par exemple, les idéogrammes courants employés dans les textes de langues asiatiques comme le chinois ou le japonais (kanji, par exemple) utilisent 3 octets en UTF-8 contre 2 octets en UTF-16.
De manière générale, les écritures employant beaucoup de points de code de valeur égale ou supérieure à U+0800 occupent plus de mémoire que s'ils étaient codés avec UTF-16 (UTF-32 sera plus efficace uniquement pour les textes utilisant majoritairement des écritures anciennes ou rares codées hors du plan multilingue de base, c'est-à-dire à partir de U+10000, mais il peut aussi s'avérer utile localement dans certains traitements pour simplifier les algorithmes, car les caractères y ont toujours une taille fixe, la conversion des données d'entrée ou de sortie depuis ou vers UTF-8 ou UTF-16 étant triviale).
Séquences invalides
Par son système de codage, il était éventuellement possible de représenter un code de différentes manières en UTF-8, ce qui pouvait poser un problème de sécurité : un programme mal écrit peut accepter un certain nombre de représentations UTF-8, normalement invalides selon la RFC 3629[8] et dans les spécifications (maintenant équivalentes entre elles) publiées par l'ISO 10646 et Unicode ; mais ce n'était pas le cas selon la spécification originale, qui permettait de les convertir comme un seul et même caractère.
Ainsi, un logiciel détectant certaines chaînes de caractères (pour prévenir les injections SQL, par exemple) pouvait échouer dans sa tâche (ce n'est plus le cas si la conformité du codage avec la définition stricte et normalisée d'UTF-8 est vérifiée avant toute chose).
Prenons un exemple tiré d'un cas réel de virus attaquant des serveurs HTTP du Web en 2001 ((en)Crypto-Gram: July 15, 2000 Microsoft IIS and PWS Extended Unicode Directory Traversal Vulnerability Microsoft IIS 4.0/5.0 Web Directory Traversal Vulnerability). Une séquence à détecter pourrait être « /../ » représentée en ASCII (a fortiori en UTF-8) par les octets « 2F 2E 2E 2F » en notation hexadécimale. Cependant, une manière malformée de coder cette chaîne en UTF-8 serait « 2F C0 AE 2E 2F », appelée aussi en anglais overlong form (forme superlongue). Si le logiciel n'est pas soigneusement écrit pour rejeter cette chaîne, en la mettant par exemple sous forme canonique, une brèche potentielle de sécurité est ouverte. Cette attaque est appelée directory traversal.
Les logiciels acceptant du texte codé en UTF-8 ont été blindés pour rejeter systématiquement ces formes longues car non conformes à la norme : soit le texte entier est rejeté ; mais parfois les séquences invalides sont remplacées par un caractère de substitution (généralement U+FFFD si l'application accepte et traite ce caractère normalement ; parfois un point d'interrogation ou le caractère de contrôle de substitution SUB U+001A de l'ASCII, qui peuvent poser d'autres problèmes de compatibilité) ; moins souvent, ces séquences interdites sont éliminées silencieusement (ce qui est très peu recommandé).
Caractère nul
UTF-8 ne peut représenter le caractère de contrôle nul (U+0000) qu'avec un seul octet nul, ce qui pose des problèmes de compatibilité avec le traitement de chaînes qui ne codifient pas séparément leur longueur effective car cet octet nul ne représente alors aucun caractère mais la fin de chaîne (cas très courant en langage C ou C++ et dans les API des systèmes d'exploitation). Si un caractère nul doit être stocké dans un texte sur de tels systèmes, il sera nécessaire de recourir à un système d'échappement, spécifique de ce langage ou système avant de coder en UTF-8 le texte ainsi transformé. En pratique, aucun texte valide ne devrait contenir ce caractère. Une autre solution est d'utiliser une des séquences interdites dans le codage UTF-8 standard afin de coder le caractère par cette séquence ; mais le texte ainsi codé ne sera pas conforme au codage UTF-8 standard, même si le codage ainsi modifié reste un format de transformation universelle conforme (qui ne doit cependant pas être désigné comme « UTF-8 »). Voir la section ci-dessous relative aux variantes non standards basées sur UTF-8.
Représentation dans les SGBD
L'utilisation d'UTF-8, comme de tout codage à pas variable, dans une base de données pose de multiples problèmes de performances.
Les opérations de comparaisons (=, >, <, BETWEEN, LIKE...), de tri (ORDER BY), de regroupement (GROUP BY), comme les opérations de dédoublonnement (DISTINCT) reposant sur la sémantique des informations, sont impossibles à gérer directement en UTF-8.
En effet, pour des chaînes de caractères comportant le même nombre de lettres (par exemple CHAR(8)), le nombre d'octets pouvant être différent (du fait notamment des caractères diacritiques : accents, ligatures...), les algorithmes utilisés doivent, pour la plupart, effectuer un alignement avant de pouvoir opérer, ce qui induit un surcoût de traitement non négligeable.
Par exemple le SGBD MySQL/MariaDB a choisi de représenter les caractères des chaînes présentées comme UTF-8 en utilisant systématiquement 3 octets par caractère. Les conséquences sont les suivantes : triplement du volume des données et division par trois de la longueur potentielle des clefs d'index par rapport au codage ASCII, et allongement des temps d'exécution pour les comparaisons, les tris, les regroupements ou le dédoublonnement. La chaîne est restituée en final sous la forme UTF-8 après un nettoyage des octets inutiles.
D'autres SGBD comme Microsoft SQL Server ont choisi de compresser le support de l'UTF-8 en intercalant les caractères supplémentaires dans un codage à 2 octets, basé sur l'UNICODE en profitant des emplacements laissés vides par la spécification. L'effort supplémentaire pour la traduction en UTF-8 ne se situe qu'au recodage des caractères codés sur 2 octets et à l'expansion de ceux codés sur 3.
Histoire
UTF-8 a été inventé par Kenneth Thompson lors d'un dîner avec Rob Pike aux alentours de [11]. Appelé alors FSS-UTF, il a été immédiatement utilisé dans le système d'exploitation Plan 9 sur lequel ils travaillaient. Une contrainte à résoudre était de coder les caractères nul et '/' comme en ASCII et qu'aucun octet codant un autre caractère n'ait le même code. Ainsi les systèmes d'exploitation UNIX pouvaient continuer à rechercher ces deux caractères dans une chaîne sans adaptation logicielle.
FSS-UTF a fait l'objet d'un standard préliminaire X/Open de 1993[12] qui fut proposé à l'ISO. Cette dernière l'adopta dans le cadre de la norme ISO/CEI 10646 sous le nom d'abord d'UTF-2, puis finalement UTF-8.
Évolution des usages
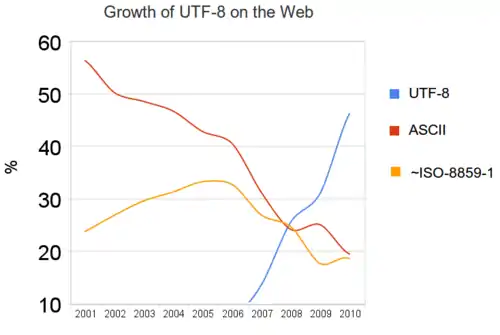
| Graphe indiquant l'utilisation d'UTF-8 (bleu clair) dépassant les principaux autres codages de caractères de texte sur le Web. Vers 2010 la prévalence d'UTF-8 était de l'ordre de 50%, mais en 2016, elle était plutôt de 90%. |
| Statistiques reflétant les technologies utilisées sur les sites web déterminées à partir de techniques de reconnaissances de différents motifs, y compris éléments HTML, tags HTML spécifiques (comme le tag « generator meta », le code JavaScript, le code CSS, la structure des URL du site, les liens hors site, les entêtes HTTP par exemple les cookies, les réponses HTTP à certaines requêtes comme la compression.
Statistiques basée sur un échantillon des 10 premiers millions de sites web selon Alexa[15]. Le total n'arrive pas à 100% car certains serveurs utilisent plusieurs technologies. |
| Source w3techs[16] |
Restrictions successives
Le codage original FSS-UTF était destiné à remplacer le codage multi-octets UTF-1 initialement proposé par l'ISO 10646. Ce codage initialement permissif, permettait plusieurs représentations binaires pour le même caractère (cela a été interdit dans la version normalisée dans la RFC publiée par le Consortium X/Open, et approuvé par Kenneth Thompson).
De plus il pouvait (dans une version préliminaire non retenue) coder tous les caractères dont la valeur de point de code comprenait jusqu'à 32 bits en définissant un huitième type d'octet (dans des séquences comprenant jusqu'à 6 octets), au lieu des 7 types d'octets finalement retenus pour ne coder (dans des séquences comprenant aussi jusqu'à 6 octets) que les points de code jusqu'à 31 bits dans la version initiale d'UTF-8 (publiée par le Consortium X/Open sous le nom FSS-UTF, puis proposé par le comité technique d'ISO 10646 comme la proposition « UTF-2 » alors encore en concurrence avec la proposition « UTF-1 », jusqu'à ce que la proposition UTF-2 soit retenue et adopte le nom UTF-8 déjà retenu et utilisé dans X/Open et Plan 9).
Ce codage UTF-8 a été restreint encore lorsque Unicode et ISO 10646 sont convenus de n'allouer des caractères que dans les 17 premiers plans afin de maintenir indéfiniment la compatibilité avec UTF-16 (sans devoir le modifier), en restreignant les séquences jusqu'à 4 octets seulement et en n'utilisant que les 5 premiers des 7 types d'octets (ce qui a nécessité de définir comme invalides de nouvelles valeurs d'octet et certaines séquences d'octets pourtant valides individuellement).
Prise en charge
L'IETF exige maintenant qu'UTF-8 soit pris en charge par défaut (et non pas simplement supporté en tant qu'extension) par tous les nouveaux protocoles de communication d'Internet (publiés dans ses RFC numérotées) qui échangent du texte (les plus anciens protocoles n'ont toutefois pas été modifiés pour rendre ce support obligatoire, mais seulement étendus si possible, pour le supporter de façon optionnelle, si cela produit des incompatibilités ou introduit de nouveaux risques de sécurité : c'est le cas de protocoles Internet très utilisés comme DNS, HTTP, FTP, Telnet et de HTML dans ses versions initiales alors pas encore standardisés par le W3C et l'ISO).
Il est devenu incontournable, notamment dans les principaux logiciels de communication du web et aujourd'hui les systèmes d'exploitation :
- Navigateurs web : la prise en charge d'UTF-8 commença à être répandue à partir de 1998.
- Les anciens navigateurs web ne supportant pas UTF-8 affichent tout de même correctement les 127 premiers caractères ASCII ;
- Netscape Navigator supporte UTF-8 à partir de sa version 4 (juin 1997) ;
- Microsoft Internet Explorer supporte UTF-8 à partir de sa version 4 (octobre 1997) pour Microsoft Windows et pour Mac OS (janvier 1998) ;
- Les navigateurs basés sur le moteur de rendu Gecko (1998) supportent UTF-8 : Mozilla, Mozilla Firefox, SeaMonkey, etc.
- Opera supporte UTF-8 à partir de sa version 6 (novembre 2001) ;
- Konqueror supporte UTF-8 ;
- Safari sur Macintosh et Windows supporte UTF-8 ;
- OmniWeb sur Macintosh supporte UTF-8 ;
- Chrome de Google supporte UTF-8.
- Fichiers et noms de fichiers : de plus en plus courant sur les systèmes de fichiers GNU/Linux et Unix, mais pas très bien supporté sous les anciennes versions de Windows (antérieures à Windows 2000 et Windows XP, lesquels peuvent maintenant les prendre en charge sans difficulté puisque le support d'UTF-8 est maintenant totalement intégré au système, en plus d'UTF-16 présent depuis les premières versions de Windows NT et de l'API système Win32).
- Noter que le système de fichiers FAT historique de MS-DOS et Windows a été étendu depuis Window NT 4 et Windows XP pour prendre en charge UTF-16 (pour une meilleure compatibilité avec NTFS) et non UTF-8 (mais cette transformation est équivalente et transparente aux applications) avec quelques restrictions sur les caractères autorisés ou considérés comme équivalents (de telles exceptions ou restrictions existent aussi sur tous les systèmes de fichiers pour GNU/Linux, Unix, Mac OS X et d'autres systèmes, y compris les systèmes de fichiers distribués sur Internet comme HTTP/WebDAV).
- Client de messagerie : tous les logiciels de messagerie utilisés aujourd'hui supportent UTF-8.
- Apple Mail ;
- Thunderbird ;
- Windows Mail ;
- Microsoft Outlook ;
- Lotus Notes ;
- Novell GroupWise ;
- etc.
Extensions ou variantes non standards
Toutefois, des variantes d'UTF-8 (basées sur les possibilités de codage de la version initiale non restreinte) ont continué à être utilisées (notamment dans l'implémentation de la sérialisation des chaînes Java) pour permettre de coder sous forme d'un échappement multioctets certains caractères ASCII réservés normalement codés sur un seul octet (par exemple le caractère nul).
De plus, certains systèmes utilisent des chaînes de caractères non restreints : par exemple, Java (et d'autres langages y compris des bibliothèques de manipulation de chaînes en C, PHP, Perl, etc.) représentent les caractères avec des unités de codage sur 16 bits (ce qui permet de stocker les chaînes en utilisant le codage UTF-16, mais sans les contraintes de validité imposées par UTF-16 concernant les valeurs interdites et l'appariement dans l'ordre des « demi-codets » ou surrogates) ; dans ce cas, les unités de codage sont traitées comme des valeurs binaires et il est nécessaire de les sérialiser de façon individuelle (indépendamment de leur interprétation possible comme caractères ou comme demi-points de code). Dans ce cas, chaque unité de codage 16 bits qui représente un « caractère » (non-contraint) est sérialisé sous forme de séquences comprenant jusqu'à 3 octets chacune, et certains octets interdits par l'implémentation (par exemple les caractères nuls ou la barre de fraction « / » dans un système de fichiers ou d'autres caractères codés sur un octet dans d'autres protocoles) sont codés sous forme de séquences d'échappement à deux octets dont aucun n'est nul, en utilisant simplement le principe de codage de la première spécification de FSS-UTF (avant celle qui a été retenue par le Consortium X/Open dans sa RFC initiale où ces échappements étaient spécifiquement interdits et le sont restés).
Avant l'adoption de la proposition UTF-2 retenue pour UTF-8, il a également existé une variante UTF-1, où les codages multiples étaient impossibles, mais cela nécessitait un codage/décodage plus difficile, devant prendre en compte la position de chaque octet et utilisant un certain nombre de valeurs « magiques ».
Ces extensions ou variantes ne doivent pas être appelées « UTF-8 ».
Extension obsolète d'UTF-8 définie initialement dans une RFC
Avant l'accord survenu entre l'ISO/IEC et Unicode, il a existé une définition (aujourd'hui obsolète) permettant de coder (selon le même principe) des points de code comptant jusqu'à 31 bits significatifs (jusqu'à U-7FFFFFFFFFFFF) en utilisant des séquences comptant jusqu'à 6 octets. Cette définition reposait sur une ancienne RFC publiée par l'IETF, aujourd'hui obsolète (incompatible et non conforme aux versions actuelles des standards Unicode et ISO/IEC 10646).
L'accord entre les deux organismes de normalisation a interdit toute utilisation valide des points de code supérieurs à U+10FFFF (soit 17 plans de points de code) pour les échanges entre systèmes compatibles. Par conséquent, les octets préfixes de l'UTF-8 ne peuvent plus être supérieurs à 0xF4 en hexadécimal. L'octet préfixe 0xF4 ne peut être utilisé que pour coder (sur 4 octets) les points de code du 17eet dernier plan valide (U+100000 à U+10FFFF), ce qui impose désormais une restriction sur la valeur du 2e octet, mais permet une interopérabilité avec les standards de codage UTF-16. L'accord s'applique également à la définition actuelle de l'UTF-32, lui aussi modifié pour interdire l'utilisation de plus de 17 plans de points de code.
Cependant il peut exister des systèmes utilisant une telle extension de l'UTF-8 (ou de l'UTF-32) de façon interne et privée, mais qui n'est pas destinée aux échanges de textes standards entre systèmes interopérables. Ce type de codage est plutôt destiné à une utilisation intermédiaire nécessaire aux traitements internes dans certaines bibliothèques de code ou des formats de fichiers ou sérialisation spécifiques souhaitant encapsuler de façon universelle autre chose que du texte (par exemple des objets binaires, du code exécutable, des images, des marques spéciales, des métadonnées, des jeux de caractères privés ou non encore normalisés et faisant l'objet de tests ou d'évaluation au sein d'un groupe limité d'utilisateurs utilisant un accord privé spécifique entre eux, etc.).
Variante standardisée
Une de ces variantes non standards a fait cependant l'objet d'une standardisation ultérieure (en tant qu'alternative à UTF-16 et utilisant des paires de « demi-codets » codés chacun sur 3 octets ; soit 6 octets en tout au lieu de 4 avec UTF-8) : voir CESU-8.
Avec l'UTF-8 normalisé actuel (et aussi le codage UTF-32 normalisé actuel), le codage des « demi-codets » isolés est désormais interdit, comme il l'est aussi avec le codage CESU-8 (où les demi-codets doivent former des paires valides, avec un demi-codet fort codé sur 3 octets obligatoirement suivi d'un demi-codet faible codé sur 3 octets, pour coder les points de code standards des 16 plans supplémentaires hors du plan multilingue de base).
Le codage CESU-8 standard est donc totalement interopérable avec les codages UTF-8 (même s'il doit obligatoirement être explicitement identifié de façon différente), UTF-16 et UTF-32 des normes et standards actuels de l'ISO/IEC 10646 et d'Unicode.
Cependant des variantes privées autorisent le codage de demi-codets isolés au sein de bibiothèques spécifiques qui ne tiennent pas compte de la restriction sur leur utilisation en paires conformes au standard CESU-8. De telles extensions d'usage local (ou faisant l'objet d'un accord privé) ne doivent pas être identifiées comme CESU-8 dans les échanges interopérables de textes standards.
Exemple de variante utilisée en Java
Par exemple, les API d'intégration des machines virtuelles Java (pour JNI, Java Native Interface ou pour la sérialisation des classes précompilées), qui permettent d'échanger les chaînes Java non contraintes sous forme de séquences d'octets (afin de les manipuler, utiliser ou produire par du code natif, ou pour le stockage sous forme de fichier natif codés en suites d'octets), sont suffixées par « UTFChars » ou « UTF », mais ce codage propre à Java n'est pas UTF-8 (La documentation de Sun la désigne comme modified UTF, mais certains documents plus anciens relatifs à JNI désignent encore ce codage incorrectement sous le nom UTF-8[17], ce qui a produit des anomalies de comportement de certaines bibliothèques natives JNI, notamment avec les API systèmes d'anciennes plateformes natives qui ne supportent pas nativement les codages de caractères sur plus de 8 bits), car :
- le caractère nul, présent en tant que tel dans une chaîne Java, est codé sous forme de deux octets non nuls (et non un seul octet nul utilisé pour indiquer la fin de séquence) ;
- les demi-codets (en anglais surrogates, assignés entre U+D000 à U+D7FF) peuvent être codés librement, dans un ordre quelconque, de même que les points de code interdits normalement pour le codage de caractère (par exemple U+FFFF ou U+FFFE) : aucun test de validité n'est demandé ;
- les séquences d'octets plus longues (sur 4 octets pour représenter les caractères hors du plan multilingue de base) normalisées et valides dans UTF-8 ne sont pas reconnues par la machine virtuelle dans ses API basées sur modified UTF (ce qui déclenche des exceptions lors de la conversion demandée par le code natif de la chaîne 8 bits vers une chaîne Java gérée par la machine virtuelle) : il faut alors recoder les caractères hors du plan de base (et codés sur 4 octets en UTF-8) sous la forme de deux séquences de 3 octets en modified UTF, une pour chaque surrogate (comme dans le codage CESU-8) et la conformité des chaînes Java avec Unicode doit être vérifiée et les exceptions gérées ;
- les chaînes Java (de la classe système String) et le type numéral char sont utilisés aussi pour le stockage (sous forme compacte, non modifiable et partageable) de données binaires quelconques (pas seulement du texte), et peuvent aussi être manipulées dans d'autres codages que l'UTF-16 (la seule contrainte étant que les unités de codage individuelles ne doivent pas dépasser 16 bits et doivent être de valeur positive, le bit de poids fort n'étant pas évalué comme un bit de signe).
En conséquence :
- les applications écrites en pur Java (sans code natif) et qui nécessitent l'implémentation de contraintes de codage pour être conformes à Unicode pour le texte doivent le demander explicitement et utiliser un des filtres de codage fournis (pour UTF-8, comme aussi pour UTF-16), ou construire et utiliser des classes basées sur la classe String et le type numéral char ;
- un texte UTF-8 valide (et manipulé en code natif dans des chaînes sans caractères nuls) nécessite un prétraitement avant de pouvoir être transmis à la machine virtuelle Java via JNI ; notamment, toute séquence codée sur 4 octets (pour un caractère hors du plan de base) doit être transcodée en deux séquences de 3 octets avec l'interface JNI à codage des chaînes sur 8 bits, ou en deux demi-codets simplement en recodant le texte en UTF-16 standard (avec l'interface JNI à codage des chaines sur 16-bits, utilisant une longueur de chaîne codée dans un champ séparé et admettant donc le codet nul à 16 bits au sein de ce texte) ;
- les chaînes obtenues depuis une machine virtuelle Java via les interfaces dites UTF de JNI (où le texte est codé en chaînes d'octets terminées par un octet nul) nécessitent un prétraitement de contrôle de validité ou de filtrage dans le code natif, avant de pouvoir être utilisées comme du texte UTF-8 valide (il faut détecter les occurrences du caractère nul codé en deux octets et, si ce caractère est acceptable par le code natif, le transcoder en un seul octet ; il faut vérifier dans le code natif l'appariement correct des demi-codets, codés chacun sur 3 octets, et les filtrer si ces séquences ne sont pas refusées comme invalides, puis transcoder toute paire valide de demi-codets en une seule séquence de 4 octets seulement et non deux séquences de 3 octets).
Ces traitements peuvent être inefficaces pour l'interfaçage de grosses quantités de texte car ils demandent l'allocation de tampons mémoire supplémentaires pour s'interfacer ensuite dans le code natif avec des interfaces système ou réseau qui n'acceptent que l'UTF-8 standard.
Cependant JNI fournit aussi une API binaire plus efficace permettant d'utiliser UTF-16 directement, capable de s'interfacer directement avec les protocoles réseau et les interfaces système (par exemple les API Windows) qui supportent l'UTF-16, sans nécessiter aucune allocation mémoire supplémentaire pour le transcodage (seule la vérification de conformité peut être nécessaire, principalement pour vérifier dans le texte codé l'appariement correct des demi-codets ou surrogate, que Java (comme aussi d'autres langages de programmation) permet de manipuler sans restriction de validité dans ses propres chaînes de caractères non destinées au stockage des seuls textes conformes à l'UCS). Cette API binaire est supportée sur tous les systèmes où Java a été porté, même ceux dont le système d'exploitation n'offre pas d'API de texte Unicode (la prise en charge pouvant se faire dans l'application native hôte ou en utilisant les bibliothèques standard fournies avec la machine virtuelle Java ou d'autres bibliothèques natives indépendantes.
Notes et références
- https://www.unicode.org/L2/Historical/wg20-n193-fss-utf.pdf.
- « Usage of character encodings for websites », sur W3Techs (consulté le ).
- « Usage of character encodings for websites », sur W3Techs (consulté le 13 septembre 2016).
- (en) « Usage Statistics of Character Encodings for Websites, December 2017 », sur w3techs.com (consulté le )
- « Usage Survey of Character Encodings broken down by Ranking », sur w3techs.com (consulté le ).
- (en) Request for comments no 2044.
- (en) Request for comments no 2279.
- (en) Request for comments no 3629.
- Cependant sur cette page retraçant l’histoire du codage UTF-8 avant 1996 il est dit : « UTF-8 encoded characters may theoretically be up to six bytes long », faisant par là référence à l’ensemble des valeurs possibles (plus de deux milliards, codées sur 31 bits au maximum) dans l’édition initiale (aujourd'hui obsolète) de la norme ISO/CEI 10646, cf. section Restrictions successives.
- (en) UTF-8 and Unicode FAQ : « pour des raisons de sécurité, un programme qui décode des caractères au format UTF-8 ne doit pas accepter les séquences UTF-8 qui sont plus longues que nécessaire pour coder ces caractères. Il risquerait d’abuser d’un test de sous-chaîne, qui ne regarderait que les codages les plus courts. ».
- Histoire de la création d’UTF-8 - par Rob Pike.
- File System Safe UCS Transformation Format (FSS-UTF).
- (en) Mark Davis, « Unicode nearing 50% of the web », Official Google Blog, Google, (consulté le ).
- (en) Erik van der Poel, « utf-8 Growth On The Web (response) », sur W3C Blog, W3C, (consulté le ).
- w3techs.com/faq.
- https://w3techs.com/technologies/history_overview/character_encoding/ms/y.
- http://java.sun.com/docs/books/jni/html/types.html#58973.
Voir aussi
Articles connexes
- UTF-16, UTF-32, CESU-8
- Unicode, ISO/CEI 10646
- ISO/CEI 646
- ISO/CEI 8859, ISO/CEI 8859-1
- Analyse syntaxique
- Demi-zone haute d’indirection
- Demi-zone basse d’indirection
- Arabe – formes de présentation – A (2e partie)
- Caractères spéciaux
- Fins de plans supplémentaires : plan multilingue complémentaire, plan idéographique complémentaire, plan 3, plan 4, plan 5, plan 6, plan 7, plan 8, plan 9, plan 10, plan 11, plan 12, plan 13, plan complémentaire spécialisé, zone supplémentaire A à usage privé, zone supplémentaire B à usage privé
Liens externes
- (fr) Formulaire de conversion UTF-8, UTF-16, UTF-32
- (fr) Conformité - Traduction du Standard Unicode en français [PDF]
- (en) The Unicode Consortium, The Unicode Standard, Version 6.0.0, Mountain View (Californie, États-Unis), (ISBN 978-1-936213-01-6, présentation en ligne, lire en ligne), chap. 3 (« Conformance »), pp. 88–100.
- (en) RFC 3629[1] - UTF-8, a transformation format of ISO 10646, novembre 2003 (standard, totalement compatible avec Unicode) :
- (en) RFC 2279[2] - UTF-8, a transformation format of ISO 10646, (ancienne révision, obsolète) ;
- (en) RFC 2044[3] - UTF-8, a transformation format of Unicode and ISO 10646, (version initiale approuvée par l'IETF, obsolète) ;
- (en) Papier original sur UTF-8, de Rob Pike et Ken Thompson (informatif, obsolète) [PDF].
- (en) RFC 2277[4] - IETF policy on character sets and languages, .
- (en) Histoire de la création d'UTF-8, par Rob Pike.
- (en) (en) UTF-8 Everywhere Manifesto, (lire en ligne)
 Portail de l’informatique
Portail de l’informatique  Portail de l’écriture
Portail de l’écriture