Simplification de textes
La simplification de textes (TS) est une opération utilisée en traitement automatique du langage naturel pour modifier, augmenter, classifier ou traiter autrement un corpus existant de texte lisible pour l'homme de telle manière que la grammaire et la structure de la prose soit considérablement simplifiée, tandis que la signification fondamentale et l'information restent les mêmes. La simplification de textes est un domaine de recherche important, le langage humain habituel contenant des constructions composées complexes qui ne sont pas facilement traitées automatiquement. Une approche récente consiste à simplifier automatiquement le texte en le convertissant en anglais de base - Basic English; qui a un vocabulaire de seulement 1,000 mots qui sont également utilisés pour décrire dans les notes de bas de page la signification de 30 000 mots du Dictionnaire de base de la science.[1]
Pour les articles homonymes, voir Simplification.
Généralités
Pourquoi simplifier des textes ?
Des phrases longues et compliquées posent des problèmes divers à de nombreuses technologies du langage naturel.
Par exemple, dans la décomposition analytique, quand des phrases deviennent syntaxiquement plus complexes, le nombre d'analyseurs s'accroît, et il y a une plus grande probabilité d'avoir une analyse erronée. Dans la traduction automatique, des phrases compliquées mènent à une ambiguïté accrue et des traductions potentiellement insatisfaisantes.
Des phrases compliquées peuvent aussi conduire à des confusions dans les livres d'assemblage, les manuels d'utilisation ou les livres de maintenance des équipements complexes.
Définition
Simplification de Texte : processus impliquant la simplification syntaxique ou lexicale d'un texte et un résultat sous forme d'un texte cohérent.
Les simplifications lexicale et syntaxique sont définies comme suit :
- Simplification lexicale : processus réduisant la complexité lexicale d'un texte tout en conservant son sens et le contenu des informations.
- Simplification syntaxique : processus réduisant la complexité syntaxique d'un texte tout en conservant son sens et le contenu des informations.
Exemple
La première phrase contient deux clauses relative et un syntagme verbal conjoint. Un TS système vise à simplifier la première phrase ; le résultat obtenu se décompose en quatre phrases.
- Also contributing to the firmness in copper, the analyst noted, was a report by Chicago purchasing agents, which precedes the full purchasing agents report that is due out today and gives an indication of what the full report might hold.
- Also contributing to the firmness in copper, the analyst noted, was a report by Chicago purchasing agents. The Chicago report precedes the full purchasing agents report. The Chicago report gives an indication of what the full report might hold. The full report is due out today.
Méthode de simplification lexicale
Méthode de projet PSET[2]
Cette méthode est utilisée pour traiter les textes anglais.
Elle parcourt les mots dans l'ordre décroissant de difficulté, l'exécution des opérations se succédant ainsi sur chaque mot :
- Analyse de la morphologie du mot. par exemple publicised = publicise + ed.
- La nature grammaticale du mot sera connue et donc une requête peut être faite sur WordNet. Ici, le terme de requête est (publicise, verb).
- La « difficulté » des synonymes retournés pour chaque mot est évaluée et le mot le plus simple est choisi. Dans notre exemple, "air " serait choisi.
- Le mot choisi reçoit l'inflexion du mot qu'il va remplacer. Donc "air + ed" produit "aired".
- Le cas échéant, le déterminant "a/an " est corrigé. Donc "a publicised event" devient "an aired event".
Cette méthode ne réalise pas la désambiguisation lexicale (WSD : Word Sense Disambiguation) et elle s'appuie aussi sur la disponibilité de WordNet et une base de données psycholinguistiques, ce qui signifie qu'elle n'est pas disponible pour tous les langues.
Méthodo de Belder & Deschacht[3]
Cette méthode est beaucoup plus évolutive en d'autres langues et réalise une forme de WSD.
Étant donné un mot, on génère d'abord deux ensembles de mots alternatifs. Un ensemble est obtenu à partir d'un dictionnaire des synonymes (ou WordNet, si disponible), et l'autre est généré par le modèle Latent Words Language (LWLM). Pour chaque mot dans l'intersection de ces ensembles, on génère une probabilité qu'il est un bon mot de remplacement, tel que défini par .

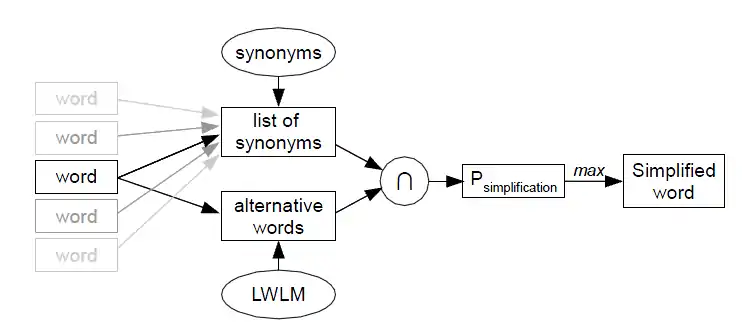
- Le modèle Latent Words Language :
LWLM modélise les langues en termes de mots consécutifs ainsi que la signification contextuelle des mots comme des variables latentes dans un réseau bayésien.
Dans une phase d'apprentissage, le modèle apprend pour chaque mot un ensemble probabiliste de synonymes et mots relatifs à partir d'un large corpus d'apprentissage non étiqueté.
Pendant la « phase d'inférence », le modèle est appliqué à un texte inédit et estime pour chaque mot les synonymes de ce mot qui sont pertinents dans ce contexte particulier.
Les mots latents aider à résoudre le problème de parcimonie rencontré avec N-gramme traditionnel modèle, conduisant à un modèle de langue de qualité supérieure, en termes de réduction de la perplexité sur des textes inédits.
- Modélisation de la facilité de mots:
La probabilité pour qu'un nouveau mot soit un bon remplaçant pour le mot d'origine dans le texte est inspiré par la probabilité , défini comme suit:



La probabilité qu'un nouveau mot corresponde toujours au contexte est déduit du modèle LWLM, qui indique quels remplaçants sont plus susceptibles de s'appliquer que d'autres. Le second facteur à estimer est de déterminer si un mot est facile à comprendre ou non. Il peut être instancié de plusieurs façons, selon la disponibilité des ressources.
Méthode de Simplification syntaxique
Méthode de Chandrasekar et al.
Les objectifs de la simplification de texte selon Chandrasekar et al sont en grande partie de réduire la longueur des phrases comme une étape de prétraitement pour un analyseur. Ils traitent la simplification en deux étapes : "analyse" suivie d'une "transformation".
- Dans leur première approche (Chandrasekar et al., 1996) [4] on traite manuellement les règles de simplification. Par exemple :
V W:NP, X:REL_PRON Y, Z. V W Z. W Y.

Qui peut se lire comme «si une phrase se compose d'un texte V suivi par un syntagme nominal W, un pronom relatif X et une séquence de mots Y enfermés dans des virgules et une séquence de mots Z, alors la clause intégrée peut être transformé en une nouvelle phrase avec W comme syntagme nominal objet". Cette règle peut, par exemple, être utilisé pour effectuer des simplifications suivantes :
John, who was the CEO of a company, played golf.

John played golf. John was the CEO of a company.
Dans la pratique, les règles linéaire de Filtrage par motif comme celui traité manuellement ci-dessus ne fonctionnent pas très bien. Par exemple, pour simplifier :
A friend from London, who was the CEO of a company, played golf, usually on Sundays.
Il est nécessaire de décider si la clause relative se rattache à un friend ou à London et si la clause se termine sur company ou golf. Et si un analyseur est utilisé pour résoudre ces ambiguïtés (comme dans leur deuxième approche résumée ci-dessous), l'utilisation prévue de la simplification de texte comme un préprocesseur à un analyseur est plus difficile à justifier.
- Dans la deuxième approche (Chandrasekar et Srinivas, 1997) [5], on utilise le programme pour apprendre les règles de simplification à partir d'un corpus aligné des phrases et leur formes simplifiées traitées manuellement.
Les phrases originales et simplifiées sont analysées à l'aide d'une Lightweight Dependency Analyser (LDA) (Srinivas, 1997) qui a agi sur la sortie d'un supertagger (Joshi et Srinivas, 1994). Ces analyseurs sont chunked à syntagmes.
les règles de simplification sont induites d'une comparaison entre les structures des analyseurs chunked de la texte original et simplifiée traitée manuelle.
L'algorithme d'apprentissage travaillé en sous-arbres aplatissants qui sont les mêmes sur les deux côtés de la règle, il remplace les chaînes de mots identiques avec des variables, et puis calcul les transformations arbre arbres pour obtenir des règles en termes de ces variables.
Méthode de projet PSET [6]
Pour la Simplification syntaxique, le projet PSET a à peu près suivi l'approche de Chandrasekar et al. PSET utilise un analyseur probabiliste LR (Briscoe et Carroll, 1995) pour l'étape de l'analyse et le Filtrage par motif utilisant l'unification de règles traitée manuelle sur les arbres de syntagme-constructeur pour l'étape de transformation.
Ici est un exemple :
(S (?a) (S (?b) (S (?c) ) ) ) (?a) (?c)
Le côté gauche de cette règle unifie les structures de la forme représentée à la figure ci-dessous :
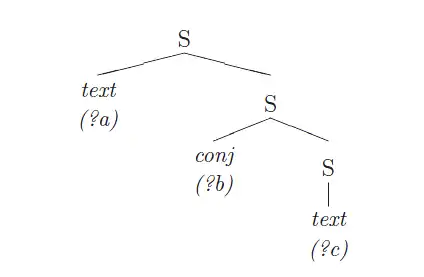
La règle supprime simplement la conjonction (?b) et construit des nouvelles phrases de (?a) et (?c) . Cette règle peut être utilisée, par exemple, d'effectuer des simplifications suivantes :
The proceedings are unfair and any punishment from the guild would be unjustified.
The proceedings are unfair. Any punishment from the guild would be unjustified.
Bibliographie
- « Simplish Simplification and Summarization Tool », The Goodwill Consortium (consulté le )
- Devlin. 1999. Simplifying natural language text for aphasic readers. Ph.D. Dissertation. University of Sunderland. UK.
- Lexical Simplification, Jan De Belder, Koen Deschacht et Marie-Francine Moens.
- Raman Chandrasekar, Christine Doran, et Bangalore Srinivas. 1996. Motivations and Methods for Text Simplification. In Proceedings of the 16th International Conference on Computational Linguistics (COLING ’96), Copenhagen, Denmark. pages 1041–1044.
- Bangalore Srinivas. 1997. Complexity of Lexical Descriptions and its Relevance to Partial Parsing. Ph.D. thesis, University of Pennsylyania, Philadelphia, PA.
- Devlin and J. Tait. 1998. The use of a psy cholinguistic database in the simplification of text for aphasic readers. In J. Nerbonne. Linguistic Databases. Lecture Notes. Stanford. USA. CSLI Publications.
En savoir plus
- Readability Assessment for Text Simplification, Cassini Sandra Aluisio, Lucia Specia, Caroline Gasperin et Carolina Scarton.
- Simplifying Text for Language-Impaired Readers, John Carroll, Yvonne Canning, Guido Minnen, Siobhan Devlin, Darren Pearce, et John Tait.
- Extract-based summarization with simplification, Partha Lal et Stefan Ruger.
- Text Simplification for Children, Jan De Belder et Marie-Francine Moens.
- Syntactic simplification and text cohesion, Advaith Siddharthan.
- Automatic Induction of Rules for Text Simplification, R. Chandrasekar et B. Srinivas
- Text Simplification for Information-Seeking Applications, Beata Beigman Klebanov, Kevin Knight, et Daniel Marcu.
Voir aussi
(en) Cet article contient des extraits de la Free On-line Dictionary of Computing qui autorise l'utilisation de son contenu sous licence GFDL.
 Portail de la linguistique
Portail de la linguistique  Portail de l’informatique
Portail de l’informatique