Complement component 1q
| C1q domain | |||||||||
|---|---|---|---|---|---|---|---|---|---|
 crystal structure of a collagen viii nc1 domain trimer | |||||||||
| Identifiers | |||||||||
| Symbol | C1q | ||||||||
| Pfam | PF00386 | ||||||||
| Pfam clan | CL0100 | ||||||||
| InterPro | IPR001073 | ||||||||
| PROSITE | PDOC00857 | ||||||||
| SCOP2 | 1c28 / SCOPe / SUPFAM | ||||||||
| |||||||||
| complement component 1, q subcomponent, A chain | |||||||
|---|---|---|---|---|---|---|---|
| Identifiers | |||||||
| Symbol | C1QA | ||||||
| NCBI gene | 712 | ||||||
| HGNC | 1241 | ||||||
| OMIM | 120550 | ||||||
| RefSeq | NM_015991 | ||||||
| UniProt | P02745 | ||||||
| Other data | |||||||
| Locus | Chr. 1 p36.3-34.1 | ||||||
| |||||||
| complement component 1, q subcomponent, B chain | |||||||
|---|---|---|---|---|---|---|---|
| Identifiers | |||||||
| Symbol | C1QB | ||||||
| NCBI gene | 713 | ||||||
| HGNC | 1242 | ||||||
| OMIM | 120570 | ||||||
| RefSeq | NM_000491 | ||||||
| UniProt | P02746 | ||||||
| Other data | |||||||
| Locus | Chr. 1 p36.3-34.1 | ||||||
| |||||||
| complement component 1, q subcomponent, C chain | |||||||
|---|---|---|---|---|---|---|---|
| Identifiers | |||||||
| Symbol | C1QC | ||||||
| Alt. symbols | C1QG | ||||||
| NCBI gene | 714 | ||||||
| HGNC | 1245 | ||||||
| OMIM | 120575 | ||||||
| RefSeq | NM_172369 | ||||||
| UniProt | P02747 | ||||||
| Other data | |||||||
| Locus | Chr. 1 p36.11 | ||||||
| |||||||
The complement component 1q (or simply C1q) is a protein complex involved in the complement system, which is part of the innate immune system. C1q together with C1r and C1s form the C1 complex.
Antibodies of the adaptive immune system can bind antigen, forming an antigen-antibody complex. When C1q binds antigen-antibody complexes, the C1 complex becomes activated. Activation of the C1 complex initiates the classical complement pathway of the complement system. The antibodies IgM and all IgG subclasses except IgG4 are able to initiate the complement system.
Structure
C1q is a 400 kDa protein formed from 18 peptide chains in 3 subunits of 6. Each 6 peptide subunit consists of a Y-shaped pair of triple peptide helices joined at the stem and ending in a globular non-helical head.
The 80-amino acid helical component of each triple peptide contain many Gly-X-Y sequences, where X and Y are proline, isoleucine, or hydroxylysine; they, therefore, strongly resemble collagen fibrils.
C1q chains A, B and C
C1q is composed of 18 polypeptide chains: six A-chains, six B-chains, and six C-chains. Each chain contains a collagen-like region located near the N terminus and a C-terminal globular region. The A-, B-, and C-chains are arranged in the order A-C-B on chromosome 1.[1]
Domain
The C1q domain is a conserved protein domain. C1q is a subunit of the C1 enzyme complex that activates the serum complement system. C1q comprises 6 A, 6 B and 6 C chains. These share the same topology, each possessing a small, globular N-terminal domain, a collagen-like Gly/Pro-rich central region, and a conserved C-terminal region, the C1q domain.[2] The C1q protein is produced in collagen-producing cells and shows sequence and structural similarity to collagens VIII and X.[3][4]
Function
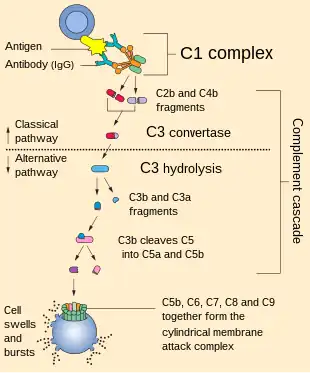
It is assumed that the globular ends are the sites for multivalent attachment to the complement fixing sites in immune complexed immunoglobulin. Patients suffering from Lupus erythematosus often have deficient expression of C1q. Genetic deficiency of C1q is extremely rare (approximately 75 known cases) although the majority (>90%) of those suffer from SLE.
C1q associates with C1r and C1s in order to yield the C1 complex (C1qr2s2), the first component of the serum complement system. Deficiency of C1q has been associated with lupus erythematosus and glomerulonephritis.[1]
It is potentially multivalent for attachment to the complement fixation sites of immunoglobulin. The sites are on the CH2 domain of IgG and, it is thought, on the CH4 domain of IgM. IgG4 cannot bind C1q, but the other three IgG types can.
The appropriate peptide sequence of the complement fixing site might become exposed following complexing of the immunoglobulin, or the sites might always be available, but might require multiple attachment by C1q with critical geometry in order to achieve the necessary avidity.
References
- 1 2 "Entrez Gene: C1QA complement component 1, q subcomponent, A chain".
- ↑ Sellar GC, Blake DJ, Reid KB (March 1991). "Characterization and organization of the genes encoding the A-, B- and C-chains of human complement subcomponent C1q. The complete derived amino acid sequence of human C1q". Biochem. J. 274 (2): 481–90. doi:10.1042/bj2740481. PMC 1150164. PMID 1706597.
- ↑ Petry F, Reid KB, Loos M (November 1989). "Molecular cloning and characterization of the complementary DNA coding for the B-chain of murine Clq". FEBS Lett. 258 (1): 89–93. doi:10.1016/0014-5793(89)81622-9. PMID 2591537.
- ↑ Muragaki Y, Jacenko O, Apte S, Mattei MG, Ninomiya Y, Olsen BR (April 1991). "The alpha 2(VIII) collagen gene. A novel member of the short chain collagen family located on the human chromosome 1". J. Biol. Chem. 266 (12): 7721–7. doi:10.1016/S0021-9258(20)89508-8. PMID 2019595.
Further reading
- C1q: structure, function, and receptors. Kishore U1, Reid KB. Immunopharmacology. 2000 Aug;49(1-2):159-70.
- Functional Complement C1q Abnormality Leads to Impaired Immune Complexes and Apoptotic Cell Clearance.
- Deciphering the fine details of C1 assembly and activation mechanisms: “mission impossible”? - detailed diagrams
External links
- Complement+C1q at the US National Library of Medicine Medical Subject Headings (MeSH)