Reverse pharmacology

In the field of drug discovery, reverse pharmacology [1][2][3] also known as target-based drug discovery (TDD),[4] a hypothesis is first made that modulation of the activity of a specific protein target will have beneficial therapeutic effects. Screening of chemical libraries of small molecules is then used to identify compounds that bind with high affinity to the target. The hits from these screens are then used as starting points for drug discovery. This method became popular after the sequencing of the human genome which allowed rapid cloning and synthesis of large quantities of purified proteins. This method is the most widely used in drug discovery today.[5] Differently than the classical (forward) pharmacology, with the reverse pharmacology approach in vivo efficacy of identified active (lead) compounds is usually performed in the final drug discovery stages.
Reverse pharmacology or target-based pharmacology, is a process of drug development where identity of a molecular target (receptor, enzyme, protein, etc) drives compound screening. Classical pharmacology involves determining the functional activity of a compound through in vitro and in vivo models. Once the activity of compound is found, the compounds ligands are identified, purified, and synthesized and go through biological screening assays. The most selective and potent drug is then further screened for toxicity and efficacy. Classical pharmacology can be time consuming and expensive. Reverse pharmacology was first established in the 70's by Dir Ram Nath Chopra and Gannath Sen.[6] Reverse pharmacology, in contrast, takes potential drug compounds, designed specifically to targets (receptors, enzyme, proteins, etc) involved in disorders or diseases. Binding assays are used to identify the molecular target. The compound then undergoes animal functional studies to show the desired effect. Compounds identified through reverse pharmacology are thought to increase efficacy. The goal of reverse pharmacology is to utilize disease pathology in order to identify specific and targetable elements that novel compounds can be modeled from.
Reverse vaccinology
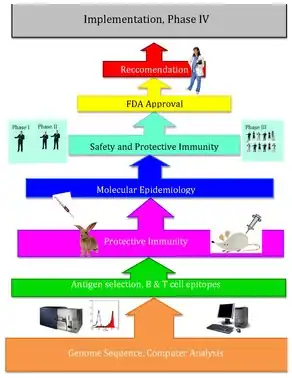
A subcategory of reverse pharmacology, reverse vaccinology is a computational approach for discovery of vaccines through utilization of the genome. Traditionally vaccines have been developed through the isolation, inactivation, and re-injection of viruses. Conventional vaccinology is both time consuming and limited to antigens that are able to be purified for testing.[7]
Rino Rappuoli and the J. Craig Venter Institute used reverse vaccinology to develop a vaccine against Serogroup B meningococcus.[8] Vaccines utilizing reverse vaccinology tend to have better selectivity; reducing side effects. These vaccines can increase immunity of multiple strains by incorporating multiple proteins.[9]
The reverse vaccinology approach uses the genome sequence of the pathogen itself. Researchers are able to determine the all of the protein antigens that a pathogen can express. Reverse vaccinology begins with the genomic sequence of the pathogen and computer prediction of candidates for vaccines. Scientists use computational analysis to obtain the genome of the virus which allows for the determination of proteins that are secreted during viral infection. Through the secreted proteins, scientists are then able to identify and purify the virus, allowing further research consisting of immunizing laboratory animals. The elicited immune response is studied and are used for identification of a vaccine.[10] Conventional vaccinology differs from reverse vaccinology in that the proteins purified from a cultured pathogen are used as candidates for a vaccine.[11]
Applications of reverse vaccinology
Diseases such as Malaria, Tuberculosis, and Syphilis have fully been sequences and lists of all possible genes can be accessed.
Group B Menigococcus
Group B Menigococcus is the first application of reverse vaccinology. The polysaccharide that was used to develop early vaccines was poorly immunogenic and caused autoimmunity. A vaccine needed to be made against the surface exposed proteins and were able to be folded within the outer membrane. Rino Rappuoli and the J. Craig Venter Institute were able to screen DNA fragments for genes that coded surface exposed and exported proteins. These proteins were purified and used to immunize mice. 25 of 85 surface proteins were shown to produce antibodies. These proteins were the basis of the vaccine against Group B Menigococcus.[7]
Limits to reverse vaccinology
The goal of a vaccine is protective immunity against a pathogen. Vaccinology relies on the availability of databases that can predict whether the candidates can provide protective immunity against the pathogen. Lack of knowledge surrounding vaccine immunology and effects of mutations down the line, it is hard to predict protective immunity. Another limitation of reverse vaccinology is the identification antigens that are not proteins.
Reverse vaccinology tools and applications
More than 4000 viral genomes have been identified.[10] Reverse vaccinology heavily uses bioinformatics to analyze and obtain vast viral genomes.
NERVE
New Enhanced Reverse Vaccinology Environment (NERVE) is a reverse vaccinology software that imports pathogen protein sequences and predicts biological sequences. This software predicts the sub-cellular localization, adhesion probability, topology, human sequence similarity, and conservation of these proteins. NERVE uses four criteria to predict potential vaccine candidates: proteins that do not lie in the cytoplasm, proteins with 2 or less transmembrane helices, a probability of adhesion >0.46 and proteins that have low similarity to human proteins.[12]
Vaxign
Vaxign was the first vaccine design program for reverse vaccinology and vaccine development. It uses both external and internal tools and programs to predict vaccine targets. Users input amino acids from proteins are genomes and is able to predict subcellular localization, transmembrane domains, adhesion probability, protein conservation among genomes, exclusion of nonpathogenic strains, comparison of proteins and host, prediction of binding to MHC class I and II, and analysis of the protein function.
Vaxign has two broad methods of vaccine design: "General" and "Specific" Methods. Within "General Methods" users can further choose to search under Vaxign Query or Dynamic Vaxign Analysis. Vaxign Query allows the users to search precomputed results for around 300 genomes. Users are able to choose genomes for vaccine targets based on desired parameters or protein sequences. The Dynamic Vaxign Analysis has users input protein sequences and set up parameters. This analytical tool uses the automatic Vaxign pipeline.[14] This pipeline includes predictions for sublocation, adhesion, epitope binding to MCH class I and class II, and similarity to the host genome sequences.
Under the "Specific Methods", users have the option of Vaxitop and Vaxign-ML. Vaxitop makes predictions on vaccine epitopes based on reverse vaccinology.[15] Vaxitop specifically predicts the binding to MHC Class and II. Vaxitop allows users to perform a genome whide query for different MHC host species. Vaxign-ML uses machine learning to produce vaccine candidates.[16]
EpiVax and iVAX Toolkit
EpiVax is a private company, based in Providence, RI, that uses in silico, in vitro, and in vivo applications to design new vaccines. EpiVax created the iVAX Toolkit, an in silico platform that allows users to identify and predict epitopes for vaccine development.[17]
iVAX is a computational vaccine design program that encompasses epitope mapping, antigen selection, and immunogen design. This toolkit uses immunoinformatics algorithms to identify candidate antigens and select for conserved T cell epitopes, eliminating epitopes from regulatory T cells. iVAX has a collection of tools such as Conservatrix, EpiMatrix, ClustiMer, and EpiAssembler. Vaccine design begins with searching for MHC class I and II ligands. EpiMatrix performs this initial search by parsing and evaluating each input sequence for binding efficacy. The program removes low quality binders to curate personalized predictions. These epitopes can be further analyzed for clusters using ClustiMer. Users can find cross-strain, conserved epitopes using Conservatrix.[18] This toolkit integrates in silico and ex vivo/in vitro technology to allow vaccine developers to access toxicity, efficacy, and performance of vaccines.

Reverse pharmacognosy
Pharmacognosy is a multi disciplinary science that studies the applications of natural compounds. Pharmacognosy is derived from the Greek pharmakon, meaning drug or recipe, and gnosis, meaning knowledge. Pharmacognosy is not limited to the natural compound application in therapeutics, but can also include cosmetics, agricultures, and dyes. Conventional pharmacognosy utilizes traditional knowledge of living organisms to find new bioactive molecules. Conventional pharmacognosy begins with using ethopharmacological data to select plants. Once these plants are selected, extracts of these plants are made and tested in biological assays. If an extract is biologically active, the extracts are fractionated and retested multiple times to identify the molecules responsible for the activity.
Reverse Pharmacognosy attempts to use the knowledge generated from pharmacognosy to introduce new therapeutic activities of natural products. Molecules are first selected based on criteria (eg. structure, chemical family, activity). Next, the selected compounds are used to identify potential targets. Compounds can have a variety of different targets in metabolic pathways. This information gives insight on potential off-target effects and synergetic applications. "Inverse screening" involves identifying new properties for the selected compounds. Predicted interaction partners can be validated using in vitro binding assays or virtual screenings.[19]
Summary
Selection of Molecules
The first step in reverse pharmacognosy is the selection of natural compounds. Criteria can be applied depending on the compound is proposed for: structural criteria, molecules from the same chemical family, compounds with drug-like properties, etc. Natural product databases can also be helpful for compound selection.
Target Identification and Discovery of Activities
The second step in reverse pharmacognosy is identifying the target which will bind to the selected compounds. There can be many targets that a ligand can interact with, these interactions can illicit either negative or favorable effects, so it is important to identify all possible interactions. Researchers at this step commonly use "inverse screening" where they screen proteins which will potentially bind their molecules. Predictions about selectivity and synergy can be calculated which cannot be achieved through classical docking.
Biological Assays and Organism Associated Activities
While virtual screening are fairly accurate at predicting the biological activities of compounds and their proteins, these interactions can only be confirmed through in vitro biological assays. in vivo models of biological activities are needed to confirm that there is the same biological properties from the in vitro experiments.
Activity Optimization
Derivatives of natural products may be more potent, less toxic, more accessible from the compounds that were originally probed. Database of active extracts and metabolites can assist with this optimization.[6]
Reverse pharmacognosy tools and applications
Both chemoinformatics and inverse screening tools and target databases utilize reverse pharmacognosy.
Greenpharma's reverse pharmacognosy platform
Greenpharma is a French R&D company created in 2000 who supplies tailored products and services in the life sciences. They focus on natural substances and their platform consists of five components: analytical chemistry, lab scale extractions, chemoinformatics, organic/bio synthesis, and cosmetic formulations. Greenpharma offers three compound libraries for reverse pharmacognosy needs: Greenpharma Natural Compound Library (GPNCL), Greenpharma Ligand Library (LIGENDO), and Greenpharma Plant Extract Library (GPEL).[20]
The GPNCL is a collection of 150,000 natural compound structures for lead discovery. This library also has access to 30 million compounds from Ambinter. This library does not include amino acids, peptides, nucleic acids, or long fatty acid chains. They also have continuous stock of compounds at >90% purity. The GPNCL provides the physico-chemical properties and phytochemistry of each of their compounds for researchers.[20]
LIGENDO is a library source of natural, pure compounds for chemogenomics and biological pathway hopping. This library is composed of 400 human endogenous ligands. Compounds are given in microplates of 80 and data is supplied in the database with compound name, structure, implied metabolic pathway, physico-chemical properties, and protein partners.[20]
GPEL is a plant extract library that combines botany, pharmacology, and pharmacognosy to present a wide range of possible extracts. The library is suitable for a high throughput screening which 80 extracts on each microplate for 20 plants. Greenpharma provides 4 different polarity solvent fractions. Information on the plant family, genus, species, and organ data is also provided.[20]
Selnergy
Selnergy is a virtual high throughput screening platform that allows users to explore interactions chemogenomics. It contains a database of 10,000 protein structures, sectioned by their biological properties. This platforms allows for in silico profiling of ligand and ligand-protein interactions. It allows the user to predict the selectivity and synergy between candidate compounds and their protein targets.[21]
Potential use in traditional systems of medicine
Current drug discovery entails the identification of drug targets in disease pathology, large iterations of chemical compounds to discover drug candidates and performing biological assays to test for toxicity, potency, and efficacy. This traditional approach is often considered costly and time consuming. Much of the world relies on traditional systems of medicine (TSM): Ayurveda, traditional Chinese medicine (TCM), etc. While these therapies are popular in non-western countries, their evidence of therapeutic benefits are seen as incomplete in western societies. Reverse pharmacology began as a way to study Ayurvedic plants chemically and clinically. The issue with studying Ayurvedic plants is that there was no defined approach in quantifying its benefits. The study of their herbal therapies can be investigated using reverse pharmacology.
Target identification and characterization
Proteins that are thought to be critical in pathogenesis are identified. These protein structures and their predicted function can be analyzed through bioinformatics. This enables the identification of candidate ligands. Receptor/ ligand interactions are often identified through high throughput screenings.[22]

High throughput screening
High throughput screening is method in drug discovery that allows scientists to conduct pharmacological tests. In regards to reverse pharmacology, this process is utilized for the identification of compounds involved in a pathophysiology pathway.

Molecular docking
Molecular docking is an in silico method used in drug discovery to identify novel compounds of interest. It has the ability to predict the binding conformation of small molecule ligands to their binding site. Docking was first introduced in the 1970s, and allows researchers the ability to predict interactions between the target and potential ligands.[23]
Molecular docking is currently used for the prediction of targets for compounds, prediction of adverse drug reactions, polypharmaoclogy, virtual screenings, and drug repositioning. Virtual screening using molecular docking utilizes large collections of synthesized and designed molecules to find macromolecule binding sites. Curated molecules are scored based on their binding energies and other parameters.[24]
Ligand-Based approaches are used to identify suitable protein conformations for the docking screenings. This approach can also be used to confirm the prediction from the docking screenings. Researchers can use the similarity between the predicted binding confirmation and the experimental conformation when the ligand is crystalized with the protein. Molecular dynamics (MD) and binding free energy estimations are both structure based approaches, often used in combination. Residue flexibility and conformational changes can be evaluated through molecular dynamics. It can be used to determine the stability of different protein conformations. The use of artificial intelligence and statistical methods are new in the molecular docking pipeline.[23] These methods can utilize publicly available information on the structural, chemical and activity of compounds for better predictions.
Molecular Docking Programs
DOCK
DOCK was the first docking software, created in the 1980's. DOCK uses an algorithm that searches potential binding modes. DOCK can superimpose the ligand onto the binding pocket and finds the lowest energy binding conformation. In the newer versions, the algorithm can perform both rigid and flexible docking.[25]
MORDOR
MOlecular Recognition with a Driven dynamics OptimizeR (MORDOR) is a docking software designed for accurate docking predictions. In experimental observations, a ligand can affect the conformation of a receptor. MORDOR takes this into consideration and allows for induced fit; the simulation moves with the ligand. The ligand is also able to explore the different possible binding pockets. The software uses DOCK to perform rigid docking to reduce the size of the library. After curating a smaller library, MODOR is used. MORDOR uses a "dummy sphere" to move along the receptor to identify different binding pockets. The result is an energy map with all known binding pockets.[26]
AMBER

Assisted Model Building with Energy Refinement (AMBER) was created in 2002 by developers at the University of California, San Francisco. AMBER refers to a set of "force fields" that simulate biomolecules and refers to the software package that simulated a family of force fields for molecular dynamics. "Force fields" are the parameters of the bonds, angles, dihedrals, and atom types within the system.[27] The suite allows users to complete full molecular dynamics simulations with water or Born solvent models.
| Database Name | Information |
|---|---|
| Protein Data Bank | Structure of proteins |
| Uniprot | Protein sequence and functional information |
| Therapeutic Target Database | Therapeutic protein and nucleic acid targets, disease, disease pathway information, drugs |
| sc-PDB | Proteins, ligands, binding sites |
| Potential Drug Target Database | Binding structures, disease, biological activity |
| Drug Bank | Drug and drug targets |
| PubChem | Structure and activity of chemicals |
| ChEMBL | Drug-like compounds |
| Drug Adverse Reaction Target Database (DART) | Targets associated with ADR |
| Drug Induced Toxicity Related Protein Database (DITROP) | Targets associated with toxicity |
Reverse docking

Reverse docking, or inverse docking, is an in silico method to find proteins targets to a specific ligand.[23] Much like regular docking methods, ligand-target conformations are scored and ranked based on preset parameters.[28] Large and properly constructed databases need to be created with target structures. These databases also need to define the binding sites for each proteins. There are multiple reverse docking tools that use a variety of databases and can be used in identifying targets and potential off-target interactions. The problem with efficacy of reverse docking comes from high computational time and lack of databases for target structures.[29]
Reverse docking programs
INVDOCK
INVDOCK was the first reverse docking tool, created in 2001. This software aligns ligands to the binding site and binding conformations are analyzed using energy minimization. INVDOCK can be used to identify unknown and secondary targets of drugs, leads, etc. It can also predict the ADME of targets.[30] One of the limitations of INVDOCK is the lack of optimization; users input a threshold binding energy and once the ligand is positioned successfully, within the binding energy threshold, the program moves on. There is no optimization for multiple low energy conformations.
TarFisDock
TarFisDock was first developed in 2006 and is a tool that ranks targets using an in-house database, Potential Drug Target Database (PDTD).[31] This tool calculates the binding energy of targets and their ligands. Users input their small molecule to be tested and TarFisDock searches for proteins using docking techniques. Viable targets are usually contained in the top 2,5, or 10% of its rankings.
idTarget
idTarget is a web based docking tool that allows for multiple binding sites of a protein to be identified.[31] This tool uses all the protein structures within the Protein Data Bank (PDB). This tool is also able to determine off targets of compounds.
Challenges with molecular docking
Molecular is a powerful took for visualization of ligand-target interactions. Molecular docking does not always correctly predict the binding modes due to the algorithms being estimations. Flexibility of binding sites and molecules can cause false binding sites that do not exist in experimental observation. Accurate prediction of binding is limited by size of both the ligand and receptor and knowledge surrounding the receptor. There are also problems with the scoring functions of virtual docking platforms. Commonly these scoring functions are based on binding affinity estimations. Entropy, atom randomization, binding flexibility are the most challenging issues related to predicting the binding affinity.[32]
Orphan receptors
Orphan receptors are protein receptors that are activated by unknown ligands. Though the ligands for these receptors are unknown, their structures are often similar to already identified receptors. Orphan receptors generally are apart of two distinct receptor families: nuclear receptors and G protein coupled receptors (GPCR). Nuclear receptors are cytosolic proteins that act as transcription factors once activated. GPCRs are seven transmembrane receptors that activate G proteins which signal transduce down stream effector proteins.There are more than 700 genes that code for GPCRs. It is thought that of these 700 genes, around half code for sensory receptors and the remaining may have viability as potential drug targets. Currently, more than 200 ligands for these GPCRs have been identified, leaving around 150 receptors orphaned. It is important to develop a suitable assay to successfully identify ligands.[33]
Currently, receptor sequences can be cloned and their structural information determined. These structures can be compared to GPCRs with known ligands; receptor activity can be predicted if an orphan receptor has significant homology to a receptor with known ligands. Further functional identification is done using functional assays.[34] Commonly, the cDNA of the GPCR of interest is expressed in relevant cell lines and used as bait to determine endogenous ligands.
The first GPCRs to be deorphanized were the serotonin 1A receptor (5-HT1A) and the D2 dopamine receptors. It is thought that there are more GPCRs than known potential ligands; these receptors bind to characterized ligands.[35]
Orphan GPCRs are categorized into three classes: Class A, Class B (adhesion GPCRs) , and Class C. Class A orphans have preliminary evidence for an endogenous ligand that has been published and linked to a disease. Class G, or adhesion, GPCRs are identified based on their extracellular region. The N terminal shares similar homology with adhesive domains. Class C orphans do not have a known endogenous ligand.[36]
| GPR3 | GPR4 | GPR6 | GPR15 | GPR17 | GPR17 | GPR20 |
| GPR22 | GPR26 | GPR31 | GPR35 | GPR37 | GPR37 | GPR39 |
| GPR50 | GPR63 | GPR68 | GPR75 | GPR84 | GPR84 | GPR87 |
| GPR88 | GPR132 | GPR161 | GPR183 | LGR4 | LGR4 | LGR5 |
| LGR6 | MAS1 | MRGPRX1 | MRGPRX2 | P2RY10 | P2RY10 | TAAR2 |
| ADGRA1 | ADGRB3 | ADGRD2 | ADGRE5 | ADGRF5 | ADGRG5 | ADGRL3 |
| ADGRA2 | CELSR1/ADGRC1 | ADGRE1 | ADGRF1 | ADGRG1 | ADGRG6 | ADGRL4 |
| ADGRA3 | CELSR2/ADGRC2 | ADGRE2 | ADGRF2 | ADGRG2 | ADGRG7 | ADGRV1 |
| ADGRB1 | CELSR3/ADGRC3 | ADGRE3 | ADGRF3 | ADGRG3 | ADGRL1 | |
| ADGRB2 | ADGRD1 | ADGRE4P | ADGRF4 | ADGRG4 | ADGRL2 |
| GRP156 | GPRC5B |
| GPR158 | GPRC5C |
| GPR179 | GPRC5D |
| GPRC5A | GPRC6 receptor |
Functional assays for identifying orphaned GPCRs
Bioluminescent energy transfer (BRET)
Generation of assays are important for "deorphanizing" these receptors. β-arrestin has been used to deorphanize GPCRs. Measuring the recruitment of β-arrestin can provide insight into the internalization of GPCRs. Once the GPCR becomes activated and phosphorylated, β-arrestin is recruited to the cell surface. Researchers have created a chimeric β-arrestin attached to green fluorescent protein (GFP) so that it can be tracked throughout the cell. Activation of a GPCR is indicated by the chimeric β-arrestin being compartmentalized. This technique has been utilized for the deorphanization of Drosophila neuropeptide receptors.[33]
Adaption of pheromone receptor pathway
This assays is useful in identifying the specificity of G protein coupling to the orphan receptor. Chimeric G protein are used to enable to Saccharomyces cerevisiae G-Protein, Gpa1, linked signaling through the MAPKinase cascade. This assay give low background due lack of endogenous GPCR background.[33]
Bead-based screening with Xenopus melanophores
Peptide receptors are receptors that binds to multiple peptides or signaling proteins. Many of these receptors have been implicated in diseases. Using combinatorial chemistry, GPCRs that respond to peptide ligands may be able to be identified. Beads of potential ligand peptides are first pooled so that each pool would have the same first amino acid. "Lawns" containing melanophores are transfected with peptide multiple receptor sets. These were groups of both receptors with known ligands and receptors that were orphaned. The beads are spread on the "lawn" and GPCR activation is determined through pigment translocation, which is dependent on G protein signaling. The peptides on these beads can then be sequenced for further assays.[33]
Pharmacochaperone screening assay
A pharmacochaperone is a drug that acts as a chaperone for a protein. These chaperones assist with the folding/ unfolding and assembly/disassembly of macromolecule structures. Pharmacochaperones correct the folding of misfolded and unfolded proteins, allowing them to be correctly routed in the cel's system. The pharmacochaperone screening assay exploits pharmacochaperones, small molecules that allow for the trafficking of receptors to the plasma membrane, to identify ligands. A point mutation is introduced which causes the receptor to be retained in the endoplasmic reticulum. As a result, molecules that act as chaperones will bring the receptor to the surface. These molecules are coupled with a beta-galactosidase reporter system for identification.[40]
Identification of orexin


Orexins are neuropeptides, important for their role in energy homeostasis and regulate sleep/wakefulness. Takeshi Sakurai and their lab were able to identify orexin-A and orexin-B, two endogenous ligands for two orphan GPCRs. Their lab identified orexin peptides that were able to express orexin-1 receptor (OX1R). This receptor has high affinity for orexin-A. the second receptor, orexin-2 (OX2R) binds both orexin-A and B at the same affinity. They used 50 transfectant cell lines, expressing multiple orphan GPCR cDNA. Cells were challenged with high performance liquid chromatography (HPLC) fractions and monitored for signal transduction.[41]
See also
References
- ↑ Takenaka T (Sep 2001). "Classical vs reverse pharmacology in drug discovery". BJU International. 88 Suppl 2: 7–10, discussion 49–50. doi:10.1111/j.1464-410X.2001.00112.x. PMID 11589663.
- ↑ Lazo JS (Apr 2008). "Rear-view mirrors and crystal balls: a brief reflection on drug discovery". Molecular Interventions. 8 (2): 60–3. doi:10.1124/mi.8.2.1. PMID 18403648.
- ↑ Bachmann KA, Hacker MP, Messer W (2009). Pharmacology Principles and Practice. Amsterdam: Elsevier/Academic Press. p. 576. ISBN 978-0-12-369521-5.
- ↑ Lee JA, Uhlik MT, Moxham CM, Tomandl D, Sall DJ (May 2012). "Modern phenotypic drug discovery is a viable, neoclassic pharma strategy". Journal of Medicinal Chemistry. 55 (10): 4527–38. doi:10.1021/jm201649s. PMID 22409666.
- ↑ Swinney DC, Anthony J (Jul 2011). "How were new medicines discovered?". Nature Reviews. Drug Discovery. 10 (7): 507–19. doi:10.1038/nrd3480. PMID 21701501. S2CID 19171881.
- 1 2 Blondeau, S.; Do, Q.T.; Scior, T.; Bernard, P.; Morin-Allory, L. (2010-05-01). "Reverse Pharmacognosy: Another Way to Harness the Generosity of Nature". Current Pharmaceutical Design. 16 (15): 1682–1696. doi:10.2174/138161210791164036. ISSN 1381-6128. PMID 20222859.
- 1 2 Rappuoli, Rino (2000). "Reverse vaccinology". Current Opinion in Microbiology. 3 (5): 445–450. doi:10.1016/S1369-5274(00)00119-3. PMID 11050440 – via Elseiver Science Ltd.
- ↑ Sette, Alessandro; Rappuoli, Rino (October 2010). "Reverse Vaccinology: Developing Vaccines in the Era of Genomics". Immunity. 33 (4): 530–541. doi:10.1016/j.immuni.2010.09.017. PMC 3320742. PMID 21029963.
- ↑ Hansson, Marianne; Nygren, Per-Åke; Ståhl, Stefan (2000-10-01). "Design and production of recombinant subunit vaccines". Biotechnology and Applied Biochemistry. 32 (2): 95–107. doi:10.1042/ba20000034. ISSN 0885-4513. PMID 11001870. S2CID 19091795.
- 1 2 Bruno, Luca; Cortese, Mirko; Rappuoli, Rino; Merola, Marcello (2015-04-01). "Lessons from Reverse Vaccinology for viral vaccine design". Current Opinion in Virology. Viral pathogenesis • Preventive and therapeutic vaccines. 11: 89–97. doi:10.1016/j.coviro.2015.03.001. ISSN 1879-6257. PMID 25829256.
- ↑ Heinson, A. I.; Woelk, C. H.; Newell, M.-L. (2015-03-01). "The promise of reverse vaccinology". International Health. 7 (2): 85–89. doi:10.1093/inthealth/ihv002. ISSN 1876-3413. PMID 25733557.
- ↑ Dalsass, Mattia; Brozzi, Alessandro; Medini, Duccio; Rappuoli, Rino (2019-02-14). "Comparison of Open-Source Reverse Vaccinology Programs for Bacterial Vaccine Antigen Discovery". Frontiers in Immunology. 10: 113. doi:10.3389/fimmu.2019.00113. ISSN 1664-3224. PMC 6382693. PMID 30837982.
- ↑ He, Yongqun; Xiang, Zuoshuang; Mobley, Harry L. T. (2010). "Vaxign: The First Web-Based Vaccine Design Program for Reverse Vaccinology and Applications for Vaccine Development". Journal of Biomedicine and Biotechnology. 2010: 297505. doi:10.1155/2010/297505. ISSN 1110-7243. PMC 2910479. PMID 20671958.
- ↑ Xiang, Z; He, Y (2009). "Vaxign: a web-based vaccine target design program for reverse vaccinology". Procedia in Vaccinology. 1: 23–29. doi:10.1016/j.provac.2009.07.005.
- ↑ He, Yongqun; Xiang, Zuoshuang; Mobley, Harry L. T. (2010). "Vaxign: the first web-based vaccine design program for reverse vaccinology and applications for vaccine development". Journal of Biomedicine & Biotechnology. 2010: 297505. doi:10.1155/2010/297505. ISSN 1110-7251. PMC 2910479. PMID 20671958.
- ↑ Ong, Edison; Wang, Haihe; Wong, Mei U.; Seetharaman, Meenakshi; Valdez, Ninotchka; He, Yongqun (2020-05-01). "Vaxign-ML: supervised machine learning reverse vaccinology model for improved prediction of bacterial protective antigens". Bioinformatics (Oxford, England). 36 (10): 3185–3191. doi:10.1093/bioinformatics/btaa119. ISSN 1367-4811. PMC 7214037. PMID 32096826.
- ↑ De Groot, Anne S.; Jesdale, Bill M.; Szu, Evan; Schafer, James R.; Chicz, Roman M.; Deocampo, Greg (May 1997). "An Interactive Web Site Providing Major Histocompatibility Ligand Predictions: Application to HIV Research". AIDS Research and Human Retroviruses. 13 (7): 529–531. doi:10.1089/aid.1997.13.529. ISSN 0889-2229. PMID 9135870.
- ↑ Moise, Leonard; Gutierrez, Andres; Kibria, Farzana; Martin, Rebecca; Tassone, Ryan; Liu, Rui; Terry, Frances; Martin, Bill; De Groot, Anne S (2015-09-02). "iVAX: An integrated toolkit for the selection and optimization of antigens and the design of epitope-driven vaccines". Human Vaccines & Immunotherapeutics. 11 (9): 2312–2321. doi:10.1080/21645515.2015.1061159. ISSN 2164-5515. PMC 4635942. PMID 26155959.
- ↑ Do, Quoc-Tuan; Bernard, Philippe (2006), "Reverse pharmacognosy: a new concept for accelerating natural drug discovery", Lead Molecules from Natural Products - Discovery and New Trends, Advances in Phytomedicine, Elsevier, vol. 2, pp. 1–20, doi:10.1016/s1572-557x(05)02001-5, ISBN 9780444516190, retrieved 2021-11-28
- 1 2 3 4 "Compound Librairies". Greenpharma. Retrieved 2021-11-27.
- ↑ "Drug discovery". Greenpharma. Retrieved 2021-11-28.
- ↑ Takenaka, T. (September 2001). "Classical vs reverse pharmacology in drug discovery". BJU International. 88: 7–10. doi:10.1111/j.1464-410X.2001.00112.x. PMID 11589663. S2CID 30711746.
- 1 2 3 Pinzi, Luca; Rastelli, Giulio (2019-09-04). "Molecular Docking: Shifting Paradigms in Drug Discovery". International Journal of Molecular Sciences. 20 (18): 4331. doi:10.3390/ijms20184331. ISSN 1422-0067. PMC 6769923. PMID 31487867.
- ↑ Kumar, Shivani; Kumar, Suresh (2019), "Molecular Docking: A Structure-Based Approach for Drug Repurposing", In Silico Drug Design, Elsevier, pp. 161–189, doi:10.1016/b978-0-12-816125-8.00006-7, ISBN 9780128161258, S2CID 104470250, retrieved 2021-11-28
- ↑ "Overview of DOCK". dock.compbio.ucsf.edu. Retrieved 2021-11-28.
- ↑ "Christophe&Genia Guilbert web's page". mondale.ucsf.edu. Retrieved 2021-11-28.
- ↑ D.A. Case, H.M. Aktulga, K. Belfon, I.Y. Ben-Shalom, S.R. Brozell, D.S. Cerutti, T.E. Cheatham, III, G.A. Cisneros, V.W.D. Cruzeiro, T.A. Darden, R.E. Duke, G. Giambasu, M.K. Gilson, H. Gohlke, A.W. Goetz, R. Harris, S. Izadi, S.A. Izmailov, C. Jin, K. Kasavajhala, M.C. Kaymak, E. King, A. Kovalenko, T. Kurtzman, T.S. Lee, S. LeGrand, P. Li, C. Lin, J. Liu, T. Luchko, R. Luo, M. Machado, V. Man, M. Manathunga, K.M. Merz, Y. Miao, O. Mikhailovskii, G. Monard, H. Nguyen, K.A. O’Hearn, A. Onufriev, F. Pan, S. Pantano, R. Qi, A. Rahnamoun, D.R. Roe, A. Roitberg, C. Sagui, S. Schott-Verdugo, J. Shen, C.L. Simmerling, N.R. Skrynnikov, J. Smith, J. Swails, R.C. Walker, J. Wang, H. Wei, R.M. Wolf, X. Wu, Y. Xue, D.M. York, S. Zhao, and P.A. Kollman (2021), Amber 2021, University of California, San Francisco.
- ↑ Kharkar, Prashant S; Warrier, Sona; Gaud, Ram S (March 2014). "Reverse docking: a powerful tool for drug repositioning and drug rescue". Future Medicinal Chemistry. 6 (3): 333–342. doi:10.4155/fmc.13.207. ISSN 1756-8919. PMID 24575968.
- ↑ Lee, Aeri; Lee, Kyoungyeul; Kim, Dongsup (2016-07-02). "Using reverse docking for target identification and its applications for drug discovery". Expert Opinion on Drug Discovery. 11 (7): 707–715. doi:10.1080/17460441.2016.1190706. ISSN 1746-0441. PMID 27186904. S2CID 35165729.
- ↑ "Bioinformatics & Drug Design group [BIDD]". bidd.group. Retrieved 2021-11-28.
- 1 2 Lee, Aeri; Lee, Kyoungyeul; Kim, Dongsup (June 2016). "Using reverse docking for target identification and its applications for drug discovery". Expert Opinion on Drug Discovery. 11 (7): 707–715. doi:10.1080/17460441.2016.1190706. ISSN 1746-0441. PMID 27186904. S2CID 35165729.
- ↑ Saikia, Surovi; Bordoloi, Manobjyoti (2019-03-05). "Molecular Docking: Challenges, Advances and its Use in Drug Discovery Perspective". Current Drug Targets. 20 (5): 501–521. doi:10.2174/1389450119666181022153016. PMID 30360733. S2CID 53095334.
- 1 2 3 4 Tropsha, A.; Wang, S. X. (2007), Bourne, H.; Horuk, R.; Kuhnke, J.; Michel, H. (eds.), "QSAR Modeling of GPCR Ligands: Methodologies and Examples of Applications", GPCRs: From Deorphanization to Lead Structure Identification, Berlin, Heidelberg: Springer Berlin Heidelberg, vol. 2006/2, no. 2, pp. 49–74, doi:10.1007/2789_2006_003, ISBN 978-3-540-48981-8, PMID 17703577, retrieved 2021-12-07
- ↑ Kutzleb, Christian; Busmann, Annette; Wendland, Martin; Maronde, Erik (2005-06-01). "Discovery of Novel Regulatory Peptides by Reverse Pharmacology: Spotlight on Chemerin and the RF-amide Peptides Metastin and QRFP". Current Protein & Peptide Science. 6 (3): 265–278. doi:10.2174/1389203054065419. ISSN 1389-2037. PMID 15974952.
- ↑ Civelli, Olivier; Saito, Yumiko; Wang, Zhiwei; Nothacker, Hans-Peter; Reinscheid, Rainer K. (2006-06-01). "Orphan GPCRs and their ligands". Pharmacology & Therapeutics. New Developments in Receptor Pharmacology. 110 (3): 525–532. doi:10.1016/j.pharmthera.2005.10.001. ISSN 0163-7258.
- ↑ doi:10.1111/bph.14748
- ↑ Vanderheyden, Patrick; Tirupula, Kalyan; Thomas, Walter G.; Storjohann, Laura; Stoddart, Leigh; Spindel, Eliot; Spedding, Michael; Sharman, Joanna L.; Pin, Jean-Philippe; Pawson, Adam J.; Neubig, Richard; Mpamhanga, Chido; Monaghan, Amy E.; Liew, Wen Chiy; Kostenis, Evi; Karnik, Sadashiva; Jensen, Robert T.; Holliday, Nick; Harmar, Anthony; Eguchi, Satoru; Dhanachandra Singh, Khuraijam; Davenport, Anthony P.; Bonner, Tom I.; Benya, Richard V.; Benson, Helen E.; Battey, Jim; Alexander, Stephen P.H. (2020). "Class a Orphans (Version 2020.5) in the IUPHAR/BPS Guide to Pharmacology Database". IUPHAR/BPS Guide to Pharmacology Cite. 2020 (5). doi:10.2218/gtopdb/F16/2020.5. S2CID 228927632.
- ↑ Xu, Lei; Wolfrum, Uwe; Ushkaryov, Yuri; Stacey, Martin; Singer, Kathleen; Schiöth, Helgi; Schöneberg, Torsten; Prömel, Simone; Piao, Xianhua; Monk, Kelly; Martinelli, David C.; Lin, Hsi-Hsien; Le Duc, Diana; Langenhan, Tobias; Krishnan, Arunkumar; Knapp, Barbara; Kirchhoff, Christiane; Heyne, Henrike; Harty, Breanne; Hamann, Jörg; Formstone, Caroline; Cappallo-Obermann, Heike; Bonner, Tom I.; Aust, Gabriela; Arac-Ozkan, Demet (2019). "Adhesion Class GPCRS (Version 2019.4) in the IUPHAR/BPS Guide to Pharmacology Database". IUPHAR/BPS Guide to Pharmacology Cite. 2019 (4). doi:10.2218/gtopdb/F17/2019.4. S2CID 203707503.
- ↑ Shoback, Dolores; Conigrave, Arthur; Brown, Edward M.; Bräuner-Osborne, Hans; Bikle, Daniel (2019). "Class C Orphans (Version 2019.4) in the IUPHAR/BPS Guide to Pharmacology Database". IUPHAR/BPS Guide to Pharmacology Cite. 2019 (4). doi:10.2218/gtopdb/F18/2019.4. S2CID 203705510.
- ↑ Morfa, Camilo J.; Bassoni, Daniel; Szabo, Andras; McAnally, Danielle; Sharir, Haleli; Hood, Becky L.; Vasile, Stefan; Wehrman, Tom; Lamerdin, Jane; Smith, Layton H. (October 2018). "A Pharmacochaperone-Based High-Throughput Screening Assay for the Discovery of Chemical Probes of Orphan Receptors". ASSAY and Drug Development Technologies. 16 (7): 384–396. doi:10.1089/adt.2018.868. ISSN 1540-658X. PMC 6207161. PMID 30251873.
- ↑ Mieda, M (2002-06-01). "Sleep, feeding, and neuropeptides: roles of orexins and orexin receptors". Current Opinion in Neurobiology. 12 (3): 339–345. doi:10.1016/s0959-4388(02)00331-8. ISSN 0959-4388. PMID 12049942. S2CID 35147196.