الشجرة الرقمية
في علوم الكمبيوتر، يُطلق على trie أيضًا اسم الشجرة الرقمية أو شجرة البادئة ، وهو نوع من شجرة البحث، وهي بنية بيانات شجرة تُستخدم لتحديد موقع مفاتيح معينة من داخل مجموعة. وغالبًا ما تكون هذه المفاتيح عبارة عن سلاسل، ومع روابط بين العقد لا يتم تعريفها بواسطة المفتاح بأكمله، ولكن بواسطة الأحرف الفردية. ومن أجل الوصول إلى مفتاح (لاستعادة قيمته أو تغييره أو إزالته)، يتم اجتياز الثلاثي في العمق أولاً، باتباع الروابط بين العقد، والتي تمثل كل حرف في المفتاح.
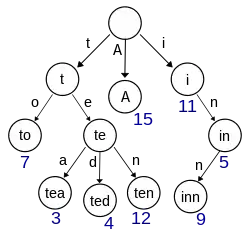
وعلى عكس شجرة البحث الثنائية، لا تخزن العقد الموجودة في المثلث المفتاح المرتبط بها. بدلاً من ذلك، يحدد موضع العقدة في المثلث المفتاح الذي يرتبط به. يوزع هذا قيمة كل مفتاح عبر بنية البيانات، ويعني أنه ليس بالضرورة أن يكون لكل عقدة مفتاح مرتبط.
وجميع توابع العقدة لديهم بادئة مشتركة للسلسلة المرتبطة بالعقدة الأصلية، والجذر مرتبط بالسلسلة الفارغة. حيث يمكن إنجاز مهمة تخزين البيانات التي يمكن الوصول إليها من خلال بادئتها بطريقة محسّنة للذاكرة من خلال استخدام شجرة الجذر.
وعلى الرغم من إمكانية تحديد المحاولات بسلاسل الأحرف، إلا أنه لا يلزم أن تكون كذلك. ويمكن تكييف نفس الخوارزميات للقوائم المرتبة من أي نوع أساسي، مثل تبديل الأرقام أو الأشكال. وعلى وجه الخصوص، يتم تمييز ثلاثي أحادي البتات على البتات الفردية التي تشكل قطعة من البيانات الثنائية ذات الطول الثابت، مثل رقم صحيح أو عنوان الذاكرة.
التاريخ وأصل الكلمة والنطق
تم وصف فكرة Trie لتمثيل مجموعة من الأوتار لأول مرة بشكل تجريدي بواسطة Axel Thue في عام 1912.[1] وتم وصف المحاولات لأول مرة في سياق الكمبيوتر بواسطة René de la Briandais عام 1959.[2] وقد وصفت هذه الفكرة بشكل مستقل في عام 1960 من قبل ادوارد فريدكين، [3] الذي صاغ مصطلح TRIE، لفظ أنه /ˈtriː/ (باسم «شجرة»)، بعد المقطع الأوسط من استرجاعها. [4][5] ومع ذلك، مؤلفين آخرين تنطق /ˈtraɪ/ (بأنها «محاولة»)، وفي محاولة لتمييزه لفظيا من «شجرة».[6]
التطبيقات
تمثيل القاموس
وتتضمن التطبيقات الشائعة للمحاولات تخزين نص تنبؤي أو قاموس إكمال تلقائي وتنفيذ خوارزميات مطابقة تقريبية، [7] مثل تلك المستخدمة في برامج التدقيق الإملائي والواصلة.[8] وتستفيد هذه التطبيقات من قدرة trie على البحث عن الإدخالات وإدراجها وحذفها بسرعة. ومع ذلك، إذا كان تخزين كلمات القاموس هو كل ما هو مطلوب (أي ليست هناك حاجة لتخزين البيانات الوصفية المرتبطة بكل كلمة)، فإن الحد الأدنى من آلية الحالة المحدودة الحتمية (DAFSA) أو شجرة الجذر ستستخدم مساحة تخزين أقل من ثلاثي. وذلك لأن DAFSAs وأشجار الجذر يمكن أن تضغط على فروع متطابقة من trie والتي تتوافق مع نفس اللواحق (أو الأجزاء) من الكلمات المختلفة المخزنة.
استبدال هياكل البيانات الأخرى
استبدال جداول التجزئة
يمكن استعمال trie لاستبدال جدول التجزئة، والذي يتمتع بالمزايا التالية عليه:
- ويكون البحث عن البيانات في trie أسرع في أسوأ الحالات، O (m) time (حيث m هو طول سلسلة البحث)، مقارنة بجدول التجزئة غير الكامل. يمكن أن يحتوي جدول التجزئة غير الكامل على تصادمات رئيسية. اصطدام المفاتيح هو تعيين وظيفة التجزئة لمفاتيح مختلفة لنفس الموضع في جدول التجزئة. أسرع سرعة بحث في جدول تجزئة غير كامل هي وقت O (N) ، ولكن عادةً ما تكون O (1)، مع وقت O (m) الذي يقضيه في تقييم التجزئة.
- لا توجد اصطدامات بين مفاتيح مختلفة في ثلاثي.
- تعتبر الحاويات الموجودة في مثلث، والتي تشبه حاويات جدول التجزئة التي تخزن تصادمات المفاتيح، ضرورية فقط إذا كان مفتاح واحد مرتبطًا بأكثر من قيمة واحدة.
- ليست هناك حاجة لتوفير وظيفة تجزئة أو لتغيير وظائف التجزئة حيث تتم إضافة المزيد من المفاتيح إلى ثلاثي.
- يمكن أن يوفر Trie ترتيبًا أبجديًا للإدخالات حسب المفتاح.
ومع ذلك، فإن الشجرة الرقمية أيضًا لها بعض العيوب مقارنة بجدول التجزئة:
- ويمكن أن يكون البحث Trie أبطأ من البحث في جدول التجزئة، خاصة إذا تم الوصول إلى البيانات مباشرة على محرك الأقراص الثابتة أو بعض أجهزة التخزين الثانوية الأخرى حيث يكون وقت الوصول العشوائي مرتفعًا مقارنة بالذاكرة الرئيسية.[9]
- ويمكن أن تؤدي بعض المفاتيح، مثل أرقام الفاصلة العائمة، إلى سلاسل طويلة وبادئات غير ذات معنى بشكل خاص. ومع ذلك، يمكن لثلاثي أحادي الاتجاه التعامل مع أرقام الفاصلة العائمة ذات التنسيق الفردي والمزدوج IEEE القياسي.
- ويمكن أن تتطلب بعض المحاولات مساحة أكبر من جدول التجزئة، حيث يمكن تخصيص الذاكرة لكل حرف في سلسلة البحث، بدلاً من جزء واحد من الذاكرة للإدخال بأكمله، كما هو الحال في معظم جداول التجزئة.
تمثيل DFSA
ويمكن النظر إلى الشجرة الرقمية على أنها إنسان آلي محدد ومحدود على شكل شجرة. حيث يتم إنشاء كل لغة منتهية من قبل trie automaton ، ويمكن ضغط كل شجرة رقمية في حالة آلية منتهية حتمية غير دورية.
الخوارزميات
الشجرة الرقمية عبارة عن شجرة من العقد التي تدعم عمليات البحث والإدراج. يُرجع البحث قيمة سلسلة المفاتيح، ويقوم «إدراج» بإدراج سلسلة (المفتاح) وقيمة في المثلث. يتم تشغيل كل من Insert and Find في O(m) time ، حيث m هو طول المفتاح.
ويمكن استخدام فئة عقدة بسيطة لتمثيل العقد في المثلث:
ولاحظ أن children عبارة عن قاموس من الأحرف لأبناء العقدة؛ ويقال أن العقدة «الطرفية» هي التي تمثل سلسلة كاملة. </br>و يمكن البحث عن قيمة trie على النحو التالي:
ويمكن استخدام تعديلات طفيفة في هذا الروتين
- وللتحقق مما إذا كانت هناك أي كلمة في الشجرة الرقمية تبدأ ببادئة معينة (انظر § الإكمال التلقائي)، و
- ولإرجاع العقدة الأعمق المقابلة لبادئة معينة لسلسلة معينة.
وتتم عملية الإدراج عن طريق السير في المثلث وفقًا للسلسلة المراد إدخالها، ثم إلحاق عقد جديدة لاحقة السلسلة غير المضمنة في الشجرة الرقمية:
ويمكن أن يتم حذف مفتاح بطريقة بطيئة (عن طريق مسح القيمة الموجودة داخل العقدة المقابلة لمفتاح)، أو بشغف عن طريق تنظيف أي عقد رئيسية لم تعد ضرورية. ويتم وصف الحذف الشديد في الرمز الخاطئ هنا:[10]
الإكمال التلقائي
يمكن استخدام الشجرة الرقمية لإرجاع قائمة مفاتيح ببادئة معينة. يمكن أيضًا تعديل هذا للسماح بأحرف البدل في البحث عن البادئة.[11]
الفرز
ويمكن إجراء الفرز المعجمي لمجموعة من المفاتيح من خلال بناء ثلاثي منها، ومع فرز الأطفال لكل عقدة بطريقة معجمية، واجتيازها بالترتيب المسبق، وطباعة أي قيم في العقد الداخلية أو في العقد الورقية.[12] هذه الخوارزمية هي شكل من أشكال فرز الجذر.[13]
الشجرة الرقمية هي بنية البيانات الأساسية لـ Burstsort ، والتي كانت (في عام 2007) أسرع خوارزمية لفرز السلسلة المعروفة نظرًا لاستخدامها الفعال لذاكرة التخزين المؤقت. [14] الآن هناك أسرع.[15]
البحث عن نص كامل
يمكن استعمال نوع خاص من الشجرة الرقمية، يسمى شجرة اللاحقة، لفهرسة جميع اللواحق في النص من أجل إجراء عمليات بحث سريعة عن النص الكامل.
استراتيجيات التنفيذ
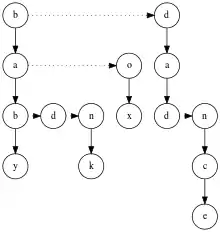
وهناك عدة طرق لتمثيل المحاولات تتوافق مع المقايضات المختلفة بين استخدام الذاكرة وسرعة العمليات.و النموذج الأساسي هو مجموعة متصلة من العقد، حيث تحتوي كل عقدة على مجموعة من المؤشرات الفرعية، واحدة لكل رمز في الأبجدية (لذلك بالنسبة للأبجدية الإنجليزية، يمكن للمرء تخزين 26 مؤشرًا فرعيًا وللحروف الأبجدية من البايت، 256 مؤشرات). هذا بسيط ولكنه مضيعة للذاكرة: باستخدام أبجدية البايت (الحجم 256) ومؤشرات رباعية البايت، تتطلب كل عقدة كيلوبايت من التخزين، وعندما يكون هناك القليل من التداخل في بادئات السلاسل، فإن عدد العقد المطلوبة هو تقريبًا الطول المجمع للسلاسل المخزنة. [2] :341 بعبارة أخرى، العقد الموجودة بالقرب من أسفل الشجرة تميل إلى أن يكون لديها عدد قليل من الأطفال وهناك العديد منهم، لذا فإن الهيكل يهدر مساحة تخزين المؤشرات الفارغة.[16]
ويمكن التخفيف من مشكلة التخزين من خلال تقنية تنفيذ تسمى الاختزال الأبجدي ، حيث يتم إعادة تفسير السلاسل الأصلية على أنها سلاسل أطول على أبجدية أصغر. على سبيل المثال، ويمكن بدلاً من ذلك اعتبار n 2n وحدات من أربع بتات وتخزينها في ثلاثي مع ستة عشر مؤشرًا لكل عقدة. وتحتاج عمليات البحث إلى زيارة ضعف عدد العقد في أسوأ الحالات، ولكن متطلبات التخزين تنخفض بمقدار ثمانية أضعاف. [2] :347–352
ويمثل التنفيذ البديل العقدة على أنها ثلاثية(symbol, child, next) ويربط أبناء العقدة معًا كقائمة مرتبطة منفردة:child إلى الطفل الأول للعقدة،next الطفل التالي للعقدة الأصلية.[17][18] ويمكن أيضًا تمثيل مجموعة الأطفال كشجرة بحث ثنائية؛ أحد الأمثلة على هذه الفكرة هو شجرة البحث الثلاثية التي طورها بنتلي وسيدجويك. [2] :353
بديل آخر لتجنب استخدام مصفوفة من 256 مؤشر (ASCII)، كما هو مقترح سابقًا، وهو تخزين المصفوفة الأبجدية كصورة نقطية من 256 بت تمثل أبجدية ASCII ، مما يقلل بشكل كبير من حجم العقد.[19]
الشجرة الرقمية Bitwise
تتشابه الشجرة الرقمية Bitwise إلى حد كبير مع الشجرة الرقمية العادية المستند إلى الأحرف فيما عدا أنه يتم استخدام البتات الفردية لاجتياز ما يصبح بشكل فعال شكلاً من أشكال الشجرة الثنائية. وبشكل عام، تستخدم التطبيقات تعليمات خاصة لوحدة المعالجة المركزية للعثور بسرعة كبيرة على أول مجموعة بت في مفتاح طول ثابت (على سبيل المثال، GCC's __builtin_clz() جوهري).و تُستخدم هذه القيمة بعد ذلك لفهرسة جدول 32 أو 64 إدخالًا يشير إلى العنصر الأول في ثلاثي أحادي مع هذا العدد من البتات الصفرية البادئة. يبدأ البحث بعد ذلك باختبار كل بت تالٍ في المفتاح واختيار child[0] أو child[1] مناسب حتى يتم العثور على العنصر.
وعلى الرغم من أن هذه العملية قد تبدو بطيئة، إلا أنها ذات ذاكرة تخزين مؤقت محلية للغاية وقابلة للتوازي بدرجة كبيرة نظرًا لنقص تبعيات التسجيل، وبالتالي فهي تتمتع في الواقع بأداء ممتاز على وحدات المعالجة المركزية الحديثة ذات التنفيذ خارج الترتيب.و تعمل الشجرة ذات اللون الأحمر والأسود على سبيل المثال بشكل أفضل على الورق، ولكنها غير ملائمة بدرجة كبيرة لذاكرة التخزين المؤقت وتتسبب في العديد من خطوط الأنابيب وأكشاك TLB على وحدات المعالجة المركزية الحديثة مما يجعل هذه الخوارزمية مرتبطة بزمن استجابة الذاكرة بدلاً من سرعة وحدة المعالجة المركزية. وبالمقارنة، نادرًا ما يصل ثلاثي أحادي إلى الذاكرة، وعندما يفعل ذلك، فإنه يفعل ذلك للقراءة فقط، وبالتالي يتجنب الحمل الزائد لاتساق ذاكرة التخزين المؤقت SMP. ومن ثم، فقد أصبحت الخوارزمية المختارة بشكل متزايد للكود الذي يؤدي العديد من عمليات الإدراج والحذف السريعة، مثل مخصصات الذاكرة (على سبيل المثال، الإصدارات الحديثة من مُخصص دوج ليا الشهير (dlmalloc) وأحفاده).و أسوأ حالة لخطوات البحث هي نفس وحدات البت المستخدمة لفهرسة الصناديق في الشجرة.[20]
وبدلاً من ذلك، يمكن أن يشير المصطلح «bitwise الشجرة الرقمية» بشكل عام إلى بنية شجرة ثنائية تحمل قيمًا صحيحة، وترتيبها حسب بادئتها الثنائية. مثال على ذلك هو trie سريع x .
شجرات الضغط الرقمية
يمكن أن يؤدي ضغط الشجرة الرقمية ودمج الفروع المشتركة في بعض الأحيان إلى مكاسب كبيرة في الأداء. حيث يعمل هذا بشكل أفضل في ظل الظروف التالية:
- الشجرة الرقمية (في الغالب) ثابتة، بحيث لا يلزم إدخال مفتاح أو حذفه (على سبيل المثال، بعد الإنشاء بالجملة للشجرة الرقمية).
- هناك حاجة لعمليات البحث فقط.
- لا يتم ترميز الشجرة الرقمية بواسطة البيانات الخاصة بالعقدة، أو أن بيانات العقد شائعة.[21]
- تكون المجموعة الإجمالية للمفاتيح المخزنة قليلة جدًا ضمن مساحة التمثيل الخاصة بها (لذا فإن الضغط يؤتي ثماره).
وعلى سبيل المثال، يمكن استخدامه لتمثيل مجموعات البت المتفرقة؛ على سبيل المثال، مجموعات فرعية من مجموعة قابلة للعد وثابتة أكبر بكثير. في مثل هذه الحالة، يتم تحديد الشجرة الرقمية بواسطة موضع عنصر البت داخل المجموعة الكاملة. ويتم إنشاء المفتاح من سلسلة البتات اللازمة لتشفير الموضع المتكامل لكل عنصر.و مثل هذه المحاولات لها شكل سيئ للغاية مع العديد من الفروع المفقودة. بعد اكتشاف تكرار الأنماط الشائعة أو ملء الفجوات غير المستخدمة، ويمكن تخزين العقد الورقية الفريدة (سلاسل البت) وضغطها بسهولة، مما يقلل من الحجم الكلي للثلاثي.
ويتم استخدام هذا الضغط أيضًا في تنفيذ جداول البحث السريع المتنوعة لاسترداد خصائص أحرف Unicode. ويمكن أن تشمل هذه الجداول حالة على رسم الخرائط (على سبيل المثال، ل اليوناني إلكتروني بي، من Π لπ)، أو جداول البحث تطبيع الجمع بين القاعدة والجمع بين الحروف (مثل أ- علامة تشكيل في الألمانية، ä، أو دالت - patah - dagesh - أولي في الكتاب المقدس العبرية،דַּ֫ بالنسبة لمثل هذه التطبيقات، يكون التمثيل مشابهًا لتحويل جدول كبير جدًا أحادي البعد ومتفرق (على سبيل المثال، نقاط رمز Unicode) إلى مصفوفة متعددة الأبعاد لمجموعاتها، ثم استخدام الإحداثيات في المصفوفة الفائقة كمفتاح سلسلة لملف غير مضغوط تري لتمثيل الشخصية الناتجة. سيتكون الضغط بعد ذلك من اكتشاف ودمج الأعمدة المشتركة داخل المصفوفة الفائقة لضغط البعد الأخير في المفتاح. على سبيل المثال، لتجنب تخزين نقطة رمز Unicode الكاملة متعددة البايت لكل عنصر يشكل عمود مصفوفة، يمكن استغلال مجموعات نقاط الكود المتشابهة. يخزن كل بُعد من أبعاد المصفوفة الفائقة موضع البداية للبعد التالي، بحيث يتم تخزين الإزاحة فقط (عادةً بايت واحد). المتجه الناتج هو نفسه قابل للضغط عندما يكون متناثرًا أيضًا، لذلك يمكن ضغط كل بُعد (مرتبط بمستوى طبقة في المثلث) بشكل منفصل .
وتدعم بعض التطبيقات ضغط البيانات هذا في المحاولات المتفرقة الديناميكية وتسمح بعمليات الإدراج والحذف في المحاولات المضغوطة. ومع ذلك، فإن هذا عادةً ما يكون له تكلفة كبيرة عند الحاجة إلى تقسيم أو دمج الأجزاء المضغوطة.و يجب إجراء بعض المفاضلة بين ضغط البيانات وسرعة التحديث. تتمثل الإستراتيجية النموذجية في تحديد نطاق عمليات البحث العامة لمقارنة الفروع الشائعة في تجربة متفرقة.[بحاجة لمصدر]
وقد تبدو نتيجة هذا الضغط مشابهة لمحاولة تحويل الشجرة الرقمية إلى رسم بياني لا دوري موجه (DAG)، لأن التحويل العكسي من DAG إلى مثلث يكون واضحًا وممكنًا دائمًا. ومع ذلك، يتم تحديد شكل DAG من خلال شكل المفتاح المختار لفهرسة العقد، مما يؤدي بدوره إلى تقييد الضغط المحتمل .
وهنالك إستراتيجية ضغط أخرى هي «تفكيك» بنية البيانات في مصفوفة بايت واحد.[22] هذا الأسلوب يلغي الحاجة إلى مؤشرات العقدة، مما يقلل بشكل كبير من متطلبات الذاكرة. وهذا بدوره يسمح بتعيين الذاكرة واستخدام الذاكرة الظاهرية لتحميل البيانات بكفاءة من القرص.
وهنالك نهج آخر هو «حزم» الشجرة الرقمية .[8] يصف Liang تنفيذًا فعالًا لمساحة الشجرة الرقمية معبأ متناثر مطبق على الواصلة التلقائية، حيث يمكن تشذير أحفاد كل عقدة في الذاكرة.
الذاكرة الخارجية للشجرة الرقمية
العديد من المتغيرات الثلاثية مناسبة للاحتفاظ بمجموعات من السلاسل في الذاكرة الخارجية، بما في ذلك أشجار اللواحق.و قد تم اقتراح توليفة من الشجرة الرقمية وب- الشجرة الرقمية، تسمى ب- الشجرة الرقمية لهذه المهمة؛ مقارنةً بأشجار اللاحقة، فهي محدودة في العمليات المدعومة ولكنها أيضًا أكثر إحكاما، أثناء إجراء عمليات التحديث بشكل أسرع.[23]
انظر أيضًا
المراجع
- Thue, Axel (1912)، "Über die gegenseitige Lage gleicher Teile gewisser Zeichenreihen"، Skrifter udgivne af Videnskabs-Selskabet i Christiania، 1912 (1): 1–67. Cited by Knuth.
- Brass, Peter (2008)، Advanced Data Structures، Cambridge University Press، ص. 336.
- Edward Fredkin (1960)، "Trie Memory"، Communications of the ACM، 3 (9): 490–499، doi:10.1145/367390.367400.
- Black, Paul E. (16 نوفمبر 2009)، "trie"، Dictionary of Algorithms and Data Structures، المعهد الوطني للمعايير والتقنية، مؤرشف من الأصل في 29 أبريل 2011.
- Franklin Mark Liang، Word Hy-phen-a-tion By Com-put-er (PDF) (Doctor of Philosophy thesis)، Stanford University، مؤرشف من الأصل (PDF) في 10 مارس 2021.
- Knuth, Donald (1997)، "6.3: Digital Searching"، The Art of Computer Programming Volume 3: Sorting and Searching (ط. 2nd)، Addison-Wesley، ص. 492، ISBN 0-201-89685-0.
- Aho, Alfred V.؛ Corasick, Margaret J. (يونيو 1975)، "Efficient String Matching: An Aid to Bibliographic Search"، Communications of the ACM، 18 (6): 333–340، doi:10.1145/360825.360855، مؤرشف من الأصل (PDF) في 22 أبريل 2021.
- Franklin Mark Liang، Word Hy-phen-a-tion By Com-put-er (PDF) (Doctor of Philosophy thesis)، Stanford University، مؤرشف من الأصل (PDF) في 10 مارس 2021.Franklin Mark Liang (1983). Word Hy-phen-a-tion By Com-put-er (PDF) (Doctor of Philosophy thesis). Stanford University. Archived (PDF) from the original on 2005-11-11. Retrieved 2010-03-28.
- Edward Fredkin (1960)، "Trie Memory"، Communications of the ACM، 3 (9): 490–499، doi:10.1145/367390.367400.Edward Fredkin (1960). "Trie Memory". Communications of the ACM. 3 (9): 490–499. doi:10.1145/367390.367400.
- Sedgewick, Robert؛ Wayne, Kevin (12 يونيو 2020)، "Tries"، algs4.cs.princeton.edu، مؤرشف من الأصل في 28 يناير 2021، اطلع عليه بتاريخ 11 أغسطس 2020.
- Sedgewick, Robert؛ Wayne, Kevin (12 يونيو 2020)، "Tries"، algs4.cs.princeton.edu، مؤرشف من الأصل في 28 يناير 2021، اطلع عليه بتاريخ 11 أغسطس 2020.Sedgewick, Robert; Wayne, Kevin (June 12, 2020). "Tries". algs4.cs.princeton.edu. Retrieved 2020-08-11.
- Kärkkäinen, Juha، "Lecture 2" (PDF)، جامعة هلسنكي، مؤرشف من الأصل (PDF) في 08 مارس 2021،
The preorder of the nodes in a trie is the same as the lexicographical order of the strings they represent assuming the children of a node are ordered by the edge labels.
- Kallis, Rafael (2018)، "The Adaptive Radix Tree (Report #14-708-887)" (PDF)، University of Zurich: Department of Informatics, Research Publications، مؤرشف من الأصل (PDF) في 08 مارس 2021.
- Ranjan Sinha and Justin Zobel and David Ring (فبراير 2006)، "Cache-Efficient String Sorting Using Copying" (PDF)، ACM Journal of Experimental Algorithmics، 11: 1–32، doi:10.1145/1187436.1187439، مؤرشف من الأصل (PDF) في 08 مارس 2021.
- J. Kärkkäinen and T. Rantala (2008)، "Engineering Radix Sort for Strings"، في A. Amir and A. Turpin and A. Moffat (المحرر)، String Processing and Information Retrieval, Proc. SPIRE، Lecture Notes in Computer Science، Springer، ج. 5280، ص. 3–14، doi:10.1007/978-3-540-89097-3_3.
- Allison, Lloyd، "Tries"، مؤرشف من الأصل في 24 فبراير 2021، اطلع عليه بتاريخ 18 فبراير 2014.
- Allison, Lloyd، "Tries"، مؤرشف من الأصل في 24 فبراير 2021، اطلع عليه بتاريخ 18 فبراير 2014.Allison, Lloyd. "Tries". Retrieved 18 February 2014.
- Sahni, Sartaj، "Tries"، Data Structures, Algorithms, & Applications in Java، University of Florida، مؤرشف من الأصل في 08 مارس 2021، اطلع عليه بتاريخ 18 فبراير 2014.
- Bellekens, Xavier (2014)، "A Highly-Efficient Memory-Compression Scheme for GPU-Accelerated Intrusion Detection Systems"، Proceedings of the 7th International Conference on Security of Information and Networks - SIN '14، Glasgow, Scotland, UK: ACM، ص. 302:302–302:309، arXiv:1704.02272، doi:10.1145/2659651.2659723، ISBN 978-1-4503-3033-6.
- Lee, Doug، "A Memory Allocator"، مؤرشف من الأصل في 02 نوفمبر 2020، اطلع عليه بتاريخ 01 ديسمبر 2019. HTTP for Source Code. Binary Trie is described in Version 2.8.6, Section "Overlaid data structures", Structure "malloc_tree_chunk".
- Jan Daciuk؛ Stoyan Mihov؛ Bruce W. Watson؛ Richard E. Watson (2000)، "Incremental Construction of Minimal Acyclic Finite-State Automata"، Association for Computational Linguistics، 26: 3–16، arXiv:cs/0007009، doi:10.1162/089120100561601، مؤرشف من الأصل في 30 سبتمبر 2011، اطلع عليه بتاريخ 28 مايو 2009،
This paper presents a method for direct building of minimal acyclic finite states automaton which recognizes a given finite list of words in lexicographical order. Our approach is to construct a minimal automaton in a single phase by adding new strings one by one and minimizing the resulting automaton on-the-fly
Alt URL - Ulrich Germann؛ Eric Joanis؛ Samuel Larkin (2009)، "Tightly packed tries: how to fit large models into memory, and make them load fast, too" (PDF)، ACL Workshops: Proceedings of the Workshop on Software Engineering, Testing, and Quality Assurance for Natural Language Processing، Association for Computational Linguistics، ص. 31–39، مؤرشف من الأصل (PDF) في 23 نوفمبر 2018،
We present Tightly Packed Tries (TPTs), a compact implementation of read-only, compressed trie structures with fast on-demand paging and short load times. We demonstrate the benefits of TPTs for storing n-gram back-off language models and phrase tables for statistical machine translation. Encoded as TPTs, these databases require less space than flat text file representations of the same data compressed with the gzip utility. At the same time, they can be mapped into memory quickly and be searched directly in time linear in the length of the key, without the need to decompress the entire file. The overhead for local decompression during search is marginal.
- Askitis, Nikolas؛ Zobel, Justin (2008)، "B-tries for Disk-based String Management" (PDF)، VLDB Journal: 1–26، ISSN 1066-8888، مؤرشف من الأصل (PDF) في 25 فبراير 2021.
روابط خارجية
 بوابة برمجة الحاسوب
بوابة برمجة الحاسوب بوابة تقنية المعلومات
بوابة تقنية المعلومات بوابة علم الحاسوب
بوابة علم الحاسوب بوابة قاعدة بيانات
بوابة قاعدة بيانات