Feature (computer vision)
In computer vision and image processing, a feature is a piece of information about the content of an image; typically about whether a certain region of the image has certain properties. Features may be specific structures in the image such as points, edges or objects. Features may also be the result of a general neighborhood operation or feature detection applied to the image. Other examples of features are related to motion in image sequences, or to shapes defined in terms of curves or boundaries between different image regions.
| Feature detection |
|---|
| Edge detection |
| Corner detection |
| Blob detection |
| Ridge detection |
| Hough transform |
| Structure tensor |
| Affine invariant feature detection |
| Feature description |
| Scale space |
| Part of a series on |
| Machine learning and data mining |
|---|
 |
More broadly a feature is any piece of information which is relevant for solving the computational task related to a certain application. This is the same sense as feature in machine learning and pattern recognition generally, though image processing has a very sophisticated collection of features. The feature concept is very general and the choice of features in a particular computer vision system may be highly dependent on the specific problem at hand.
Definition
There is no universal or exact definition of what constitutes a feature, and the exact definition often depends on the problem or the type of application. Nevertheless, a feature is typically defined as an "interesting" part of an image, and features are used as a starting point for many computer vision algorithms.
Since features are used as the starting point and main primitives for subsequent algorithms, the overall algorithm will often only be as good as its feature detector. Consequently, the desirable property for a feature detector is repeatability: whether or not the same feature will be detected in two or more different images of the same scene.
Feature detection is a low-level image processing operation. That is, it is usually performed as the first operation on an image, and examines every pixel to see if there is a feature present at that pixel. If this is part of a larger algorithm, then the algorithm will typically only examine the image in the region of the features. As a built-in pre-requisite to feature detection, the input image is usually smoothed by a Gaussian kernel in a scale-space representation and one or several feature images are computed, often expressed in terms of local image derivative operations.
Occasionally, when feature detection is computationally expensive and there are time constraints, a higher level algorithm may be used to guide the feature detection stage, so that only certain parts of the image are searched for features.
There are many computer vision algorithms that use feature detection as the initial step, so as a result, a very large number of feature detectors have been developed. These vary widely in the kinds of feature detected, the computational complexity and the repeatability.
When features are defined in terms of local neighborhood operations applied to an image, a procedure commonly referred to as feature extraction, one can distinguish between feature detection approaches that produce local decisions whether there is a feature of a given type at a given image point or not, and those who produce non-binary data as result. The distinction becomes relevant when the resulting detected features are relatively sparse. Although local decisions are made, the output from a feature detection step does not need to be a binary image. The result is often represented in terms of sets of (connected or unconnected) coordinates of the image points where features have been detected, sometimes with subpixel accuracy.
When feature extraction is done without local decision making, the result is often referred to as a feature image. Consequently, a feature image can be seen as an image in the sense that it is a function of the same spatial (or temporal) variables as the original image, but where the pixel values hold information about image features instead of intensity or color. This means that a feature image can be processed in a similar way as an ordinary image generated by an image sensor. Feature images are also often computed as integrated step in algorithms for feature detection.
Feature vectors and feature spaces
In some applications, it is not sufficient to extract only one type of feature to obtain the relevant information from the image data. Instead two or more different features are extracted, resulting in two or more feature descriptors at each image point. A common practice is to organize the information provided by all these descriptors as the elements of one single vector, commonly referred to as a feature vector. The set of all possible feature vectors constitutes a feature space.[1]
A common example of feature vectors appears when each image point is to be classified as belonging to a specific class. Assuming that each image point has a corresponding feature vector based on a suitable set of features, meaning that each class is well separated in the corresponding feature space, the classification of each image point can be done using standard classification method.
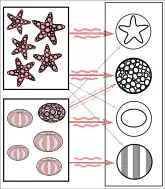

In reality, textures and outlines would not be represented by single nodes, but rather by associated weight patterns of multiple nodes.
Another and related example occurs when neural network-based processing is applied to images. The input data fed to the neural network is often given in terms of a feature vector from each image point, where the vector is constructed from several different features extracted from the image data. During a learning phase, the network can itself find which combinations of different features are useful for solving the problem at hand.
Types
Edges
Edges are points where there is a boundary (or an edge) between two image regions. In general, an edge can be of almost arbitrary shape, and may include junctions. In practice, edges are usually defined as sets of points in the image which have a strong gradient magnitude. Furthermore, some common algorithms will then chain high gradient points together to form a more complete description of an edge. These algorithms usually place some constraints on the properties of an edge, such as shape, smoothness, and gradient value.
Locally, edges have a one-dimensional structure.
Corners / interest points
The terms corners and interest points are used somewhat interchangeably and refer to point-like features in an image, which have a local two dimensional structure. The name "Corner" arose since early algorithms first performed edge detection, and then analysed the edges to find rapid changes in direction (corners). These algorithms were then developed so that explicit edge detection was no longer required, for instance by looking for high levels of curvature in the image gradient. It was then noticed that the so-called corners were also being detected on parts of the image which were not corners in the traditional sense (for instance a small bright spot on a dark background may be detected). These points are frequently known as interest points, but the term "corner" is used by tradition.
Blobs / regions of interest points
Blobs provide a complementary description of image structures in terms of regions, as opposed to corners that are more point-like. Nevertheless, blob descriptors may often contain a preferred point (a local maximum of an operator response or a center of gravity) which means that many blob detectors may also be regarded as interest point operators. Blob detectors can detect areas in an image which are too smooth to be detected by a corner detector.
Consider shrinking an image and then performing corner detection. The detector will respond to points which are sharp in the shrunk image, but may be smooth in the original image. It is at this point that the difference between a corner detector and a blob detector becomes somewhat vague. To a large extent, this distinction can be remedied by including an appropriate notion of scale. Nevertheless, due to their response properties to different types of image structures at different scales, the LoG and DoH blob detectors are also mentioned in the article on corner detection.
Ridges
For elongated objects, the notion of ridges is a natural tool. A ridge descriptor computed from a grey-level image can be seen as a generalization of a medial axis. From a practical viewpoint, a ridge can be thought of as a one-dimensional curve that represents an axis of symmetry, and in addition has an attribute of local ridge width associated with each ridge point. Unfortunately, however, it is algorithmically harder to extract ridge features from general classes of grey-level images than edge-, corner- or blob features. Nevertheless, ridge descriptors are frequently used for road extraction in aerial images and for extracting blood vessels in medical images—see ridge detection.
Detection

Feature detection includes methods for computing abstractions of image information and making local decisions at every image point whether there is an image feature of a given type at that point or not. The resulting features will be subsets of the image domain, often in the form of isolated points, continuous curves or connected regions.
The extraction of features are sometimes made over several scalings. One of these methods is the scale-invariant feature transform (SIFT).
| Feature detector | Edge | Corner | Blob | Ridge |
|---|---|---|---|---|
| Canny[3] | Yes | No | No | No |
| Sobel | Yes | No | No | No |
| Harris & Stephens / Plessey[4] | Yes | Yes | No | No |
| SUSAN[5] | Yes | Yes | No | No |
| Shi & Tomasi[6] | No | Yes | No | No |
| Level curve curvature[7] | No | Yes | No | No |
| FAST[8] | No | Yes | Yes | No |
| Laplacian of Gaussian[7] | No | Yes | Yes | No |
| Difference of Gaussians[9][10] | No | Yes | Yes | No |
| Determinant of Hessian[7] | No | Yes | Yes | No |
| Hessian strength feature measures[11][12] | No | Yes | Yes | No |
| MSER[13] | No | No | Yes | No |
| Principal curvature ridges[14][15][16] | No | No | No | Yes |
| Grey-level blobs[17] | No | No | Yes | No |
Extraction
Once features have been detected, a local image patch around the feature can be extracted. This extraction may involve quite considerable amounts of image processing. The result is known as a feature descriptor or feature vector. Among the approaches that are used to feature description, one can mention N-jets and local histograms (see scale-invariant feature transform for one example of a local histogram descriptor). In addition to such attribute information, the feature detection step by itself may also provide complementary attributes, such as the edge orientation and gradient magnitude in edge detection and the polarity and the strength of the blob in blob detection.
Low-level
Curvature
- Edge direction, changing intensity, autocorrelation.
Image motion
- Motion detection. Area based, differential approach. Optical flow.
Shape based
- Thresholding
- Blob extraction
- Template matching
- Hough transform
- Lines
- Circles/ellipses
- Arbitrary shapes (generalized Hough transform)
- Works with any parameterizable feature (class variables, cluster detection, etc..)
- Generalised Hough transform
Flexible methods
- Deformable, parameterized shapes
- Active contours (snakes)
Representation
A specific image feature, defined in terms of a specific structure in the image data, can often be represented in different ways. For example, an edge can be represented as a boolean variable in each image point that describes whether an edge is present at that point. Alternatively, we can instead use a representation which provides a certainty measure instead of a boolean statement of the edge's existence and combine this with information about the orientation of the edge. Similarly, the color of a specific region can either be represented in terms of the average color (three scalars) or a color histogram (three functions).
When a computer vision system or computer vision algorithm is designed the choice of feature representation can be a critical issue. In some cases, a higher level of detail in the description of a feature may be necessary for solving the problem, but this comes at the cost of having to deal with more data and more demanding processing. Below, some of the factors which are relevant for choosing a suitable representation are discussed. In this discussion, an instance of a feature representation is referred to as a feature descriptor, or simply descriptor.
Certainty or confidence
Two examples of image features are local edge orientation and local velocity in an image sequence. In the case of orientation, the value of this feature may be more or less undefined if more than one edge are present in the corresponding neighborhood. Local velocity is undefined if the corresponding image region does not contain any spatial variation. As a consequence of this observation, it may be relevant to use a feature representation which includes a measure of certainty or confidence related to the statement about the feature value. Otherwise, it is a typical situation that the same descriptor is used to represent feature values of low certainty and feature values close to zero, with a resulting ambiguity in the interpretation of this descriptor. Depending on the application, such an ambiguity may or may not be acceptable.
In particular, if a featured image will be used in subsequent processing, it may be a good idea to employ a feature representation that includes information about certainty or confidence. This enables a new feature descriptor to be computed from several descriptors, for example computed at the same image point but at different scales, or from different but neighboring points, in terms of a weighted average where the weights are derived from the corresponding certainties. In the simplest case, the corresponding computation can be implemented as a low-pass filtering of the featured image. The resulting feature image will, in general, be more stable to noise.
Averageability
In addition to having certainty measures included in the representation, the representation of the corresponding feature values may itself be suitable for an averaging operation or not. Most feature representations can be averaged in practice, but only in certain cases can the resulting descriptor be given a correct interpretation in terms of a feature value. Such representations are referred to as averageable.
For example, if the orientation of an edge is represented in terms of an angle, this representation must have a discontinuity where the angle wraps from its maximal value to its minimal value. Consequently, it can happen that two similar orientations are represented by angles which have a mean that does not lie close to either of the original angles and, hence, this representation is not averageable. There are other representations of edge orientation, such as the structure tensor, which are averageable.
Another example relates to motion, where in some cases only the normal velocity relative to some edge can be extracted. If two such features have been extracted and they can be assumed to refer to same true velocity, this velocity is not given as the average of the normal velocity vectors. Hence, normal velocity vectors are not averageable. Instead, there are other representations of motions, using matrices or tensors, that give the true velocity in terms of an average operation of the normal velocity descriptors.
Matching
Features detected in each image can be matched across multiple images to establish corresponding features such as corresponding points.
The algorithm is based on comparing and analyzing point correspondences between the reference image and the target image. If any part of the cluttered scene shares correspondences greater than the threshold, that part of the cluttered scene image is targeted and considered to include the reference object there.[18]
See also
References
- Scott E Umbaugh (27 January 2005). Computer Imaging: Digital Image Analysis and Processing. CRC Press. ISBN 978-0-8493-2919-7.
- Ferrie, C., & Kaiser, S. (2019). Neural Networks for Babies. Sourcebooks. ISBN 1492671207.
{{cite book}}: CS1 maint: multiple names: authors list (link) - Canny, J. (1986). "A Computational Approach To Edge Detection". IEEE Transactions on Pattern Analysis and Machine Intelligence. 8 (6): 679–714. doi:10.1109/TPAMI.1986.4767851. PMID 21869365. S2CID 13284142.
- C. Harris; M. Stephens (1988). "A combined corner and edge detector" (PDF). Proceedings of the 4th Alvey Vision Conference. pp. 147–151.
- S. M. Smith; J. M. Brady (May 1997). "SUSAN - a new approach to low level image processing". International Journal of Computer Vision. 23 (1): 45–78. doi:10.1023/A:1007963824710. S2CID 15033310.
- J. Shi; C. Tomasi (June 1994). "Good Features to Track". 9th IEEE Conference on Computer Vision and Pattern Recognition. Springer.
- T. Lindeberg (1998). "Feature detection with automatic scale selection" (abstract). International Journal of Computer Vision. 30 (2): 77–116. doi:10.1023/A:1008045108935. S2CID 723210.
- E. Rosten; T. Drummond (2006). "Machine learning for high-speed corner detection". European Conference on Computer Vision. Springer. pp. 430–443. CiteSeerX 10.1.1.60.3991. doi:10.1007/11744023_34.
- J. L. Crowley and A. C. Parker, "A Representation for Shape Based on Peaks and Ridges in the Difference of Low Pass Transform", IEEE Transactions on PAMI, PAMI 6 (2), pp. 156–170, March 1984.
- D. Lowe (2004). "Distinctive Image Features from Scale-Invariant Keypoints". International Journal of Computer Vision. 60 (2): 91. CiteSeerX 10.1.1.73.2924. doi:10.1023/B:VISI.0000029664.99615.94. S2CID 221242327.
- T. Lindeberg "Scale selection properties of generalized scale-space interest point detectors", Journal of Mathematical Imaging and Vision, Volume 46, Issue 2, pages 177-210, 2013.
- T. Lindeberg ``Image matching using generalized scale-space interest points", Journal of Mathematical Imaging and Vision, volume 52, number 1, pages 3-36, 2015.
- J. Matas; O. Chum; M. Urban; T. Pajdla (2002). "Robust wide baseline stereo from maximally stable extremum regions" (PDF). British Machine Vision Conference. pp. 384–393.
- R. Haralick, "Ridges and Valleys on Digital Images", Computer Vision, Graphics, and Image Processing vol. 22, no. 10, pp. 28–38, Apr. 1983.
- D. Eberly, R. Gardner, B. Morse, S. Pizer, C. Scharlach, Ridges for image analysis, Journal of Mathematical Imaging and Vision, v. 4 n. 4, pp. 353–373, Dec. 1994.
- T. Lindeberg (1998). "Edge detection and ridge detection with automatic scale selection" (abstract). International Journal of Computer Vision. 30 (2): 117–154. doi:10.1023/A:1008097225773. S2CID 207658261.
- T. Lindeberg (1993). "Detecting Salient Blob-Like Image Structures and Their Scales with a Scale-Space Primal Sketch: A Method for Focus-of-Attention" (abstract). International Journal of Computer Vision. 11 (3): 283–318. doi:10.1007/BF01469346. S2CID 11998035.
- "Object Detection in a Cluttered Scene Using Point Feature Matching - MATLAB & Simulink". www.mathworks.com. Retrieved 2019-07-06.
Further reading
- T. Lindeberg (2009). "Scale-space". In Benjamin Wah (ed.). Encyclopedia of Computer Science and Engineering. Vol. IV. John Wiley and Sons. pp. 2495–2504. doi:10.1002/9780470050118.ecse609. ISBN 978-0470050118. (summary and review of a number of feature detectors formulated based on a scale-space operations)