Data mining
Data mining is the process of extracting and discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems.[1] Data mining is an interdisciplinary subfield of computer science and statistics with an overall goal of extracting information (with intelligent methods) from a data set and transforming the information into a comprehensible structure for further use.[1][2][3][4] Data mining is the analysis step of the "knowledge discovery in databases" process, or KDD.[5] Aside from the raw analysis step, it also involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating.[1]
| Part of a series on |
| Machine learning and data mining |
|---|
 |
The term "data mining" is a misnomer because the goal is the extraction of patterns and knowledge from large amounts of data, not the extraction (mining) of data itself.[6] It also is a buzzword[7] and is frequently applied to any form of large-scale data or information processing (collection, extraction, warehousing, analysis, and statistics) as well as any application of computer decision support system, including artificial intelligence (e.g., machine learning) and business intelligence. The book Data Mining: Practical Machine Learning Tools and Techniques with Java[8] (which covers mostly machine learning material) was originally to be named Practical Machine Learning, and the term data mining was only added for marketing reasons.[9] Often the more general terms (large scale) data analysis and analytics—or, when referring to actual methods, artificial intelligence and machine learning—are more appropriate.
The actual data mining task is the semi-automatic or automatic analysis of large quantities of data to extract previously unknown, interesting patterns such as groups of data records (cluster analysis), unusual records (anomaly detection), and dependencies (association rule mining, sequential pattern mining). This usually involves using database techniques such as spatial indices. These patterns can then be seen as a kind of summary of the input data, and may be used in further analysis or, for example, in machine learning and predictive analytics. For example, the data mining step might identify multiple groups in the data, which can then be used to obtain more accurate prediction results by a decision support system. Neither the data collection, data preparation, nor result interpretation and reporting is part of the data mining step, although they do belong to the overall KDD process as additional steps.
The difference between data analysis and data mining is that data analysis is used to test models and hypotheses on the dataset, e.g., analyzing the effectiveness of a marketing campaign, regardless of the amount of data. In contrast, data mining uses machine learning and statistical models to uncover clandestine or hidden patterns in a large volume of data.[10]
The related terms data dredging, data fishing, and data snooping refer to the use of data mining methods to sample parts of a larger population data set that are (or may be) too small for reliable statistical inferences to be made about the validity of any patterns discovered. These methods can, however, be used in creating new hypotheses to test against the larger data populations.
Etymology
In the 1960s, statisticians and economists used terms like data fishing or data dredging to refer to what they considered the bad practice of analyzing data without an a-priori hypothesis. The term "data mining" was used in a similarly critical way by economist Michael Lovell in an article published in the Review of Economic Studies in 1983.[11][12] Lovell indicates that the practice "masquerades under a variety of aliases, ranging from "experimentation" (positive) to "fishing" or "snooping" (negative).
The term data mining appeared around 1990 in the database community, with generally positive connotations. For a short time in 1980s, the phrase "database mining"™, was used, but since it was trademarked by HNC, a San Diego-based company, to pitch their Database Mining Workstation;[13] researchers consequently turned to data mining. Other terms used include data archaeology, information harvesting, information discovery, knowledge extraction, etc. Gregory Piatetsky-Shapiro coined the term "knowledge discovery in databases" for the first workshop on the same topic (KDD-1989) and this term became more popular in the AI and machine learning communities. However, the term data mining became more popular in the business and press communities.[14] Currently, the terms data mining and knowledge discovery are used interchangeably.
Background
The manual extraction of patterns from data has occurred for centuries. Early methods of identifying patterns in data include Bayes' theorem (1700s) and regression analysis (1800s).[15] The proliferation, ubiquity and increasing power of computer technology have dramatically increased data collection, storage, and manipulation ability. As data sets have grown in size and complexity, direct "hands-on" data analysis has increasingly been augmented with indirect, automated data processing, aided by other discoveries in computer science, specially in the field of machine learning, such as neural networks, cluster analysis, genetic algorithms (1950s), decision trees and decision rules (1960s), and support vector machines (1990s). Data mining is the process of applying these methods with the intention of uncovering hidden patterns.[16] in large data sets. It bridges the gap from applied statistics and artificial intelligence (which usually provide the mathematical background) to database management by exploiting the way data is stored and indexed in databases to execute the actual learning and discovery algorithms more efficiently, allowing such methods to be applied to ever-larger data sets.
Process
The knowledge discovery in databases (KDD) process is commonly defined with the stages:
- Selection
- Pre-processing
- Transformation
- Data mining
- Interpretation/evaluation.[5]
It exists, however, in many variations on this theme, such as the Cross-industry standard process for data mining (CRISP-DM) which defines six phases:
- Business understanding
- Data understanding
- Data preparation
- Modeling
- Evaluation
- Deployment
or a simplified process such as (1) Pre-processing, (2) Data Mining, and (3) Results Validation.
Polls conducted in 2002, 2004, 2007 and 2014 show that the CRISP-DM methodology is the leading methodology used by data miners.[17] The only other data mining standard named in these polls was SEMMA. However, 3–4 times as many people reported using CRISP-DM. Several teams of researchers have published reviews of data mining process models,[18] and Azevedo and Santos conducted a comparison of CRISP-DM and SEMMA in 2008.[19]
Pre-processing
Before data mining algorithms can be used, a target data set must be assembled. As data mining can only uncover patterns actually present in the data, the target data set must be large enough to contain these patterns while remaining concise enough to be mined within an acceptable time limit. A common source for data is a data mart or data warehouse. Pre-processing is essential to analyze the multivariate data sets before data mining. The target set is then cleaned. Data cleaning removes the observations containing noise and those with missing data.
Data mining
Data mining involves six common classes of tasks:[5]
- Anomaly detection (outlier/change/deviation detection) – The identification of unusual data records, that might be interesting or data errors that require further investigation due to being out of standard range.
- Association rule learning (dependency modeling) – Searches for relationships between variables. For example, a supermarket might gather data on customer purchasing habits. Using association rule learning, the supermarket can determine which products are frequently bought together and use this information for marketing purposes. This is sometimes referred to as market basket analysis.
- Clustering – is the task of discovering groups and structures in the data that are in some way or another "similar", without using known structures in the data.
- Classification – is the task of generalizing known structure to apply to new data. For example, an e-mail program might attempt to classify an e-mail as "legitimate" or as "spam".
- Regression – attempts to find a function that models the data with the least error that is, for estimating the relationships among data or datasets.
- Summarization – providing a more compact representation of the data set, including visualization and report generation.
Results validation
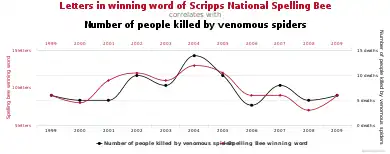
Data mining can unintentionally be misused, producing results that appear to be significant but which do not actually predict future behavior and cannot be reproduced on a new sample of data, therefore bearing little use. This is sometimes caused by investigating too many hypotheses and not performing proper statistical hypothesis testing. A simple version of this problem in machine learning is known as overfitting, but the same problem can arise at different phases of the process and thus a train/test split—when applicable at all—may not be sufficient to prevent this from happening.[20]
The final step of knowledge discovery from data is to verify that the patterns produced by the data mining algorithms occur in the wider data set. Not all patterns found by the algorithms are necessarily valid. It is common for data mining algorithms to find patterns in the training set which are not present in the general data set. This is called overfitting. To overcome this, the evaluation uses a test set of data on which the data mining algorithm was not trained. The learned patterns are applied to this test set, and the resulting output is compared to the desired output. For example, a data mining algorithm trying to distinguish "spam" from "legitimate" e-mails would be trained on a training set of sample e-mails. Once trained, the learned patterns would be applied to the test set of e-mails on which it had not been trained. The accuracy of the patterns can then be measured from how many e-mails they correctly classify. Several statistical methods may be used to evaluate the algorithm, such as ROC curves.
If the learned patterns do not meet the desired standards, it is necessary to re-evaluate and change the pre-processing and data mining steps. If the learned patterns do meet the desired standards, then the final step is to interpret the learned patterns and turn them into knowledge.
Research
The premier professional body in the field is the Association for Computing Machinery's (ACM) Special Interest Group (SIG) on Knowledge Discovery and Data Mining (SIGKDD).[21][22] Since 1989, this ACM SIG has hosted an annual international conference and published its proceedings,[23] and since 1999 it has published a biannual academic journal titled "SIGKDD Explorations".[24]
Computer science conferences on data mining include:
- CIKM Conference – ACM Conference on Information and Knowledge Management
- European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases
- KDD Conference – ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Data mining topics are also present in many data management/database conferences such as the ICDE Conference, SIGMOD Conference and International Conference on Very Large Data Bases.
Standards
There have been some efforts to define standards for the data mining process, for example, the 1999 European Cross Industry Standard Process for Data Mining (CRISP-DM 1.0) and the 2004 Java Data Mining standard (JDM 1.0). Development on successors to these processes (CRISP-DM 2.0 and JDM 2.0) was active in 2006 but has stalled since. JDM 2.0 was withdrawn without reaching a final draft.
For exchanging the extracted models—in particular for use in predictive analytics—the key standard is the Predictive Model Markup Language (PMML), which is an XML-based language developed by the Data Mining Group (DMG) and supported as exchange format by many data mining applications. As the name suggests, it only covers prediction models, a particular data mining task of high importance to business applications. However, extensions to cover (for example) subspace clustering have been proposed independently of the DMG.[25]
Notable uses
Data mining is used wherever there is digital data available. Notable examples of data mining can be found throughout business, medicine, science, finance, construction, and surveillance.[26]
Privacy concerns and ethics
While the term "data mining" itself may have no ethical implications, it is often associated with the mining of information in relation to user behavior (ethical and otherwise).[27]
The ways in which data mining can be used can in some cases and contexts raise questions regarding privacy, legality, and ethics.[28] In particular, data mining government or commercial data sets for national security or law enforcement purposes, such as in the Total Information Awareness Program or in ADVISE, has raised privacy concerns.[29][30]
Data mining requires data preparation which uncovers information or patterns which compromise confidentiality and privacy obligations. A common way for this to occur is through data aggregation. Data aggregation involves combining data together (possibly from various sources) in a way that facilitates analysis (but that also might make identification of private, individual-level data deducible or otherwise apparent).[31] This is not data mining per se, but a result of the preparation of data before—and for the purposes of—the analysis. The threat to an individual's privacy comes into play when the data, once compiled, cause the data miner, or anyone who has access to the newly compiled data set, to be able to identify specific individuals, especially when the data were originally anonymous.[32]
It is recommended to be aware of the following before data are collected:[31]
- The purpose of the data collection and any (known) data mining projects.
- How the data will be used.
- Who will be able to mine the data and use the data and their derivatives.
- The status of security surrounding access to the data.
- How collected data can be updated.
Data may also be modified so as to become anonymous, so that individuals may not readily be identified.[31] However, even "anonymized" data sets can potentially contain enough information to allow identification of individuals, as occurred when journalists were able to find several individuals based on a set of search histories that were inadvertently released by AOL.[33]
The inadvertent revelation of personally identifiable information leading to the provider violates Fair Information Practices. This indiscretion can cause financial, emotional, or bodily harm to the indicated individual. In one instance of privacy violation, the patrons of Walgreens filed a lawsuit against the company in 2011 for selling prescription information to data mining companies who in turn provided the data to pharmaceutical companies.[34]
Situation in Europe
Europe has rather strong privacy laws, and efforts are underway to further strengthen the rights of the consumers. However, the U.S.–E.U. Safe Harbor Principles, developed between 1998 and 2000, currently effectively expose European users to privacy exploitation by U.S. companies. As a consequence of Edward Snowden's global surveillance disclosure, there has been increased discussion to revoke this agreement, as in particular the data will be fully exposed to the National Security Agency, and attempts to reach an agreement with the United States have failed.[35]
In the United Kingdom in particular there have been cases of corporations using data mining as a way to target certain groups of customers forcing them to pay unfairly high prices. These groups tend to be people of lower socio-economic status who are not savvy to the ways they can be exploited in digital market places.[36]
Situation in the United States
In the United States, privacy concerns have been addressed by the US Congress via the passage of regulatory controls such as the Health Insurance Portability and Accountability Act (HIPAA). The HIPAA requires individuals to give their "informed consent" regarding information they provide and its intended present and future uses. According to an article in Biotech Business Week, "'[i]n practice, HIPAA may not offer any greater protection than the longstanding regulations in the research arena,' says the AAHC. More importantly, the rule's goal of protection through informed consent is approach a level of incomprehensibility to average individuals."[37] This underscores the necessity for data anonymity in data aggregation and mining practices.
U.S. information privacy legislation such as HIPAA and the Family Educational Rights and Privacy Act (FERPA) applies only to the specific areas that each such law addresses. The use of data mining by the majority of businesses in the U.S. is not controlled by any legislation.
Copyright law
Situation in Europe
Under European copyright database laws, the mining of in-copyright works (such as by web mining) without the permission of the copyright owner is not legal. Where a database is pure data in Europe, it may be that there is no copyright—but database rights may exist, so data mining becomes subject to intellectual property owners' rights that are protected by the Database Directive. On the recommendation of the Hargreaves review, this led to the UK government to amend its copyright law in 2014 to allow content mining as a limitation and exception.[38] The UK was the second country in the world to do so after Japan, which introduced an exception in 2009 for data mining. However, due to the restriction of the Information Society Directive (2001), the UK exception only allows content mining for non-commercial purposes. UK copyright law also does not allow this provision to be overridden by contractual terms and conditions. Since 2020 also Switzerland has been regulating data mining by allowing it in the research field under certain conditions laid down by art. 24d of the Swiss Copyright Act. This new article entered into force on 1 April 2020.[39]
The European Commission facilitated stakeholder discussion on text and data mining in 2013, under the title of Licences for Europe.[40] The focus on the solution to this legal issue, such as licensing rather than limitations and exceptions, led to representatives of universities, researchers, libraries, civil society groups and open access publishers to leave the stakeholder dialogue in May 2013.[41]
Situation in the United States
US copyright law, and in particular its provision for fair use, upholds the legality of content mining in America, and other fair use countries such as Israel, Taiwan and South Korea. As content mining is transformative, that is it does not supplant the original work, it is viewed as being lawful under fair use. For example, as part of the Google Book settlement the presiding judge on the case ruled that Google's digitization project of in-copyright books was lawful, in part because of the transformative uses that the digitization project displayed—one being text and data mining.[42]
Software
Free open-source data mining software and applications
The following applications are available under free/open-source licenses. Public access to application source code is also available.
- Carrot2: Text and search results clustering framework.
- Chemicalize.org: A chemical structure miner and web search engine.
- ELKI: A university research project with advanced cluster analysis and outlier detection methods written in the Java language.
- GATE: a natural language processing and language engineering tool.
- KNIME: The Konstanz Information Miner, a user-friendly and comprehensive data analytics framework.
- Massive Online Analysis (MOA): a real-time big data stream mining with concept drift tool in the Java programming language.
- MEPX: cross-platform tool for regression and classification problems based on a Genetic Programming variant.
- mlpack: a collection of ready-to-use machine learning algorithms written in the C++ language.
- NLTK (Natural Language Toolkit): A suite of libraries and programs for symbolic and statistical natural language processing (NLP) for the Python language.
- OpenNN: Open neural networks library.
- Orange: A component-based data mining and machine learning software suite written in the Python language.
- PSPP: Data mining and statistics software under the GNU Project similar to SPSS
- R: A programming language and software environment for statistical computing, data mining, and graphics. It is part of the GNU Project.
- scikit-learn: An open-source machine learning library for the Python programming language;
- Torch: An open-source deep learning library for the Lua programming language and scientific computing framework with wide support for machine learning algorithms.
- UIMA: The UIMA (Unstructured Information Management Architecture) is a component framework for analyzing unstructured content such as text, audio and video – originally developed by IBM.
- Weka: A suite of machine learning software applications written in the Java programming language.
Proprietary data-mining software and applications
The following applications are available under proprietary licenses.
- Angoss KnowledgeSTUDIO: data mining tool
- LIONsolver: an integrated software application for data mining, business intelligence, and modeling that implements the Learning and Intelligent OptimizatioN (LION) approach.
- PolyAnalyst: data and text mining software by Megaputer Intelligence.
- Microsoft Analysis Services: data mining software provided by Microsoft.
- NetOwl: suite of multilingual text and entity analytics products that enable data mining.
- Oracle Data Mining: data mining software by Oracle Corporation.
- PSeven: platform for automation of engineering simulation and analysis, multidisciplinary optimization and data mining provided by DATADVANCE.
- Qlucore Omics Explorer: data mining software.
- RapidMiner: An environment for machine learning and data mining experiments.
- SAS Enterprise Miner: data mining software provided by the SAS Institute.
- SPSS Modeler: data mining software provided by IBM.
- STATISTICA Data Miner: data mining software provided by StatSoft.
- Tanagra: Visualisation-oriented data mining software, also for teaching.
- Vertica: data mining software provided by Hewlett-Packard.
- Google Cloud Platform: automated custom ML models managed by Google.
- Amazon SageMaker: managed service provided by Amazon for creating & productionising custom ML models.
See also
- Methods
- Agent mining
- Anomaly/outlier/change detection
- Association rule learning
- Bayesian networks
- Classification
- Cluster analysis
- Decision trees
- Ensemble learning
- Factor analysis
- Genetic algorithms
- Intention mining
- Learning classifier system
- Multilinear subspace learning
- Neural networks
- Regression analysis
- Sequence mining
- Structured data analysis
- Support vector machines
- Text mining
- Time series analysis
- Application domains
- Application examples
- Related topics
For more information about extracting information out of data (as opposed to analyzing data), see:
- Other resources
References
- "Data Mining Curriculum". ACM SIGKDD. 2006-04-30. Archived from the original on 2013-10-14. Retrieved 2014-01-27.
- Clifton, Christopher (2010). "Encyclopædia Britannica: Definition of Data Mining". Archived from the original on 2011-02-05. Retrieved 2010-12-09.
- Hastie, Trevor; Tibshirani, Robert; Friedman, Jerome (2009). "The Elements of Statistical Learning: Data Mining, Inference, and Prediction". Archived from the original on 2009-11-10. Retrieved 2012-08-07.
- Han, Jaiwei; Kamber, Micheline; Pei, Jian (2011). Data Mining: Concepts and Techniques (3rd ed.). Morgan Kaufmann. ISBN 978-0-12-381479-1.
- Fayyad, Usama; Piatetsky-Shapiro, Gregory; Smyth, Padhraic (1996). "From Data Mining to Knowledge Discovery in Databases" (PDF). Archived (PDF) from the original on 2022-10-09. Retrieved 17 December 2008.
- Han, Jiawei; Kamber, Micheline (2001). Data mining: concepts and techniques. Morgan Kaufmann. p. 5. ISBN 978-1-55860-489-6.
Thus, data mining should have been more appropriately named "knowledge mining from data," which is unfortunately somewhat long
- OKAIRP 2005 Fall Conference, Arizona State University Archived 2014-02-01 at the Wayback Machine
- Witten, Ian H.; Frank, Eibe; Hall, Mark A. (2011). Data Mining: Practical Machine Learning Tools and Techniques (3 ed.). Elsevier. ISBN 978-0-12-374856-0.
- Bouckaert, Remco R.; Frank, Eibe; Hall, Mark A.; Holmes, Geoffrey; Pfahringer, Bernhard; Reutemann, Peter; Witten, Ian H. (2010). "WEKA Experiences with a Java open-source project". Journal of Machine Learning Research. 11: 2533–2541.
the original title, "Practical machine learning", was changed ... The term "data mining" was [added] primarily for marketing reasons.
- Olson, D. L. (2007). Data mining in business services. Service Business, 1(3), 181–193. doi:10.1007/s11628-006-0014-7
- Lovell, Michael C. (1983). "Data Mining". The Review of Economics and Statistics. 65 (1): 1–12. doi:10.2307/1924403. JSTOR 1924403.
- Charemza, Wojciech W.; Deadman, Derek F. (1992). "Data Mining". New Directions in Econometric Practice. Aldershot: Edward Elgar. pp. 14–31. ISBN 1-85278-461-X.
- Mena, Jesús (2011). Machine Learning Forensics for Law Enforcement, Security, and Intelligence. Boca Raton, FL: CRC Press (Taylor & Francis Group). ISBN 978-1-4398-6069-4.
- Piatetsky-Shapiro, Gregory; Parker, Gary (2011). "Lesson: Data Mining, and Knowledge Discovery: An Introduction". Introduction to Data Mining. KD Nuggets. Archived from the original on 30 August 2012. Retrieved 30 August 2012.
- Coenen, Frans (2011-02-07). "Data mining: past, present and future". The Knowledge Engineering Review. 26 (1): 25–29. doi:10.1017/S0269888910000378. ISSN 0269-8889. S2CID 6487637. Archived from the original on 2023-07-02. Retrieved 2021-09-04.
- Kantardzic, Mehmed (2003). Data Mining: Concepts, Models, Methods, and Algorithms. John Wiley & Sons. ISBN 978-0-471-22852-3. OCLC 50055336.
- Gregory Piatetsky-Shapiro (2002) KDnuggets Methodology Poll Archived 2017-01-16 at the Wayback Machine, Gregory Piatetsky-Shapiro (2004) KDnuggets Methodology Poll Archived 2017-02-08 at the Wayback Machine, Gregory Piatetsky-Shapiro (2007) KDnuggets Methodology Poll Archived 2012-11-17 at the Wayback Machine, Gregory Piatetsky-Shapiro (2014) KDnuggets Methodology Poll Archived 2016-08-01 at the Wayback Machine
- Lukasz Kurgan and Petr Musilek: "A survey of Knowledge Discovery and Data Mining process models" Archived 2013-05-26 at the Wayback Machine. The Knowledge Engineering Review. Volume 21 Issue 1, March 2006, pp 1–24, Cambridge University Press, New York, doi:10.1017/S0269888906000737
- Azevedo, A. and Santos, M. F. KDD, SEMMA and CRISP-DM: a parallel overview Archived 2013-01-09 at the Wayback Machine. In Proceedings of the IADIS European Conference on Data Mining 2008, pp 182–185.
- Hawkins, Douglas M (2004). "The problem of overfitting". Journal of Chemical Information and Computer Sciences. 44 (1): 1–12. doi:10.1021/ci0342472. PMID 14741005.
- "Microsoft Academic Search: Top conferences in data mining". Microsoft Academic Search. Archived from the original on 2014-11-19. Retrieved 2014-06-13.
- "Google Scholar: Top publications - Data Mining & Analysis". Google Scholar. Archived from the original on 2023-02-10. Retrieved 2022-06-11.
- Proceedings Archived 2010-04-30 at the Wayback Machine, International Conferences on Knowledge Discovery and Data Mining, ACM, New York.
- SIGKDD Explorations Archived 2010-07-29 at the Wayback Machine, ACM, New York.
- Günnemann, Stephan; Kremer, Hardy; Seidl, Thomas (2011). "An extension of the PMML standard to subspace clustering models". Proceedings of the 2011 workshop on Predictive markup language modeling. p. 48. doi:10.1145/2023598.2023605. ISBN 978-1-4503-0837-3. S2CID 14967969.
- Yan, Hang; Yang, Nan; Peng, Yi; Ren, Yitian (2020-11-01). "Data mining in the construction industry: Present status, opportunities, and future trends". Automation in Construction. 119: 103331. doi:10.1016/j.autcon.2020.103331. ISSN 0926-5805.
- Seltzer, William (2005). "The Promise and Pitfalls of Data Mining: Ethical Issues" (PDF). ASA Section on Government Statistics. American Statistical Association. Archived (PDF) from the original on 2022-10-09.
- Pitts, Chip (15 March 2007). "The End of Illegal Domestic Spying? Don't Count on It". Washington Spectator. Archived from the original on 2007-11-28.
- Taipale, Kim A. (15 December 2003). "Data Mining and Domestic Security: Connecting the Dots to Make Sense of Data". Columbia Science and Technology Law Review. 5 (2). OCLC 45263753. SSRN 546782. Archived from the original on 5 November 2014. Retrieved 21 April 2004.
- Resig, John. "A Framework for Mining Instant Messaging Services" (PDF). Archived (PDF) from the original on 2022-10-09. Retrieved 16 March 2018.
- Think Before You Dig: Privacy Implications of Data Mining & Aggregation Archived 2008-12-17 at the Wayback Machine, NASCIO Research Brief, September 2004
- Ohm, Paul. "Don't Build a Database of Ruin". Harvard Business Review.
- AOL search data identified individuals Archived 2010-01-06 at the Wayback Machine, SecurityFocus, August 2006
- Kshetri, Nir (2014). "Big data's impact on privacy, security and consumer welfare" (PDF). Telecommunications Policy. 38 (11): 1134–1145. doi:10.1016/j.telpol.2014.10.002. Archived (PDF) from the original on 2018-06-19. Retrieved 2018-04-20.
- Weiss, Martin A.; Archick, Kristin (19 May 2016). "U.S.–E.U. Data Privacy: From Safe Harbor to Privacy Shield". Washington, D.C. Congressional Research Service. p. 6. R44257. Archived from the original (PDF) on 9 April 2020. Retrieved 9 April 2020.
On October 6, 2015, the CJEU ... issued a decision that invalidated Safe Harbor (effective immediately), as currently implemented.
- Parker, George (2018-09-30). "UK companies targeted for using big data to exploit customers". Financial Times. Archived from the original on 2022-12-10. Retrieved 2022-12-04.
- Biotech Business Week Editors (June 30, 2008); BIOMEDICINE; HIPAA Privacy Rule Impedes Biomedical Research, Biotech Business Week, retrieved 17 November 2009 from LexisNexis Academic
- UK Researchers Given Data Mining Right Under New UK Copyright Laws. Archived June 9, 2014, at the Wayback Machine Out-Law.com. Retrieved 14 November 2014
- "Fedlex". Archived from the original on 2021-12-16. Retrieved 2021-12-16.
- "Licences for Europe – Structured Stakeholder Dialogue 2013". European Commission. Archived from the original on 23 March 2013. Retrieved 14 November 2014.
- "Text and Data Mining:Its importance and the need for change in Europe". Association of European Research Libraries. Archived from the original on 29 November 2014. Retrieved 14 November 2014.
- "Judge grants summary judgment in favor of Google Books – a fair use victory". Lexology.com. Antonelli Law Ltd. 19 November 2013. Archived from the original on 29 November 2014. Retrieved 14 November 2014.
Further reading
- Cabena, Peter; Hadjnian, Pablo; Stadler, Rolf; Verhees, Jaap; Zanasi, Alessandro (1997); Discovering Data Mining: From Concept to Implementation, Prentice Hall, ISBN 0-13-743980-6
- M.S. Chen, J. Han, P.S. Yu (1996) "Data mining: an overview from a database perspective Archived 2016-03-03 at the Wayback Machine". Knowledge and data Engineering, IEEE Transactions on 8 (6), 866–883
- Feldman, Ronen; Sanger, James (2007); The Text Mining Handbook, Cambridge University Press, ISBN 978-0-521-83657-9
- Guo, Yike; and Grossman, Robert (editors) (1999); High Performance Data Mining: Scaling Algorithms, Applications and Systems, Kluwer Academic Publishers
- Han, Jiawei, Micheline Kamber, and Jian Pei. Data mining: concepts and techniques. Morgan kaufmann, 2006.
- Hastie, Trevor, Tibshirani, Robert and Friedman, Jerome (2001); The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Springer, ISBN 0-387-95284-5
- Liu, Bing (2007, 2011); Web Data Mining: Exploring Hyperlinks, Contents and Usage Data, Springer, ISBN 3-540-37881-2
- Murphy, Chris (16 May 2011). "Is Data Mining Free Speech?". InformationWeek: 12.
- Nisbet, Robert; Elder, John; Miner, Gary (2009); Handbook of Statistical Analysis & Data Mining Applications, Academic Press/Elsevier, ISBN 978-0-12-374765-5
- Poncelet, Pascal; Masseglia, Florent; and Teisseire, Maguelonne (editors) (October 2007); "Data Mining Patterns: New Methods and Applications", Information Science Reference, ISBN 978-1-59904-162-9
- Tan, Pang-Ning; Steinbach, Michael; and Kumar, Vipin (2005); Introduction to Data Mining, ISBN 0-321-32136-7
- Theodoridis, Sergios; and Koutroumbas, Konstantinos (2009); Pattern Recognition, 4th Edition, Academic Press, ISBN 978-1-59749-272-0
- Weiss, Sholom M.; and Indurkhya, Nitin (1998); Predictive Data Mining, Morgan Kaufmann
- Witten, Ian H.; Frank, Eibe; Hall, Mark A. (30 January 2011). Data Mining: Practical Machine Learning Tools and Techniques (3 ed.). Elsevier. ISBN 978-0-12-374856-0. (See also Free Weka software)
- Ye, Nong (2003); The Handbook of Data Mining, Mahwah, NJ: Lawrence Erlbaum
