Multiple instruction, multiple data
In computing, multiple instruction, multiple data (MIMD) is a technique employed to achieve parallelism. Machines using MIMD have a number of processors that function asynchronously and independently. At any time, different processors may be executing different instructions on different pieces of data.
| Flynn's taxonomy |
|---|
| Single data stream |
| Multiple data streams |
| SIMD Subcategories[1] |
| See also |
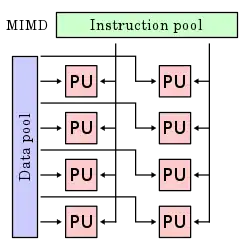
MIMD architectures may be used in a number of application areas such as computer-aided design/computer-aided manufacturing, simulation, modeling, and as communication switches. MIMD machines can be of either shared memory or distributed memory categories. These classifications are based on how MIMD processors access memory. Shared memory machines may be of the bus-based, extended, or hierarchical type. Distributed memory machines may have hypercube or mesh interconnection schemes.
Examples
An example of MIMD system is Intel Xeon Phi, descended from Larrabee microarchitecture.[2] These processors have multiple processing cores (up to 61 as of 2015) that can execute different instructions on different data.
Most parallel computers, as of 2013, are MIMD systems.[3]
Shared memory model
In shared memory model the processors are all connected to a "globally available" memory, via either software or hardware means. The operating system usually maintains its memory coherence.[4]
From a programmer's point of view, this memory model is better understood than the distributed memory model. Another advantage is that memory coherence is managed by the operating system and not the written program. Two known disadvantages are: scalability beyond thirty-two processors is difficult, and the shared memory model is less flexible than the distributed memory model.[4]
There are many examples of shared memory (multiprocessors): UMA (uniform memory access), COMA (cache-only memory access).[5]
Bus-based
MIMD machines with shared memory have processors which share a common, central memory. In the simplest form, all processors are attached to a bus which connects them to memory. This means that every machine with shared memory shares a specific CM, common bus system for all the clients.
For example, if we consider a bus with clients A, B, C connected on one side and P, Q, R connected on the opposite side, any one of the clients will communicate with the other by means of the bus interface between them.
Hierarchical
MIMD machines with hierarchical shared memory use a hierarchy of buses (as, for example, in a "fat tree") to give processors access to each other's memory. Processors on different boards may communicate through inter-nodal buses. Buses support communication between boards. With this type of architecture, the machine may support over nine thousand processors.
Distributed memory
In distributed memory MIMD (multiple instruction, multiple data) machines, each processor has its own individual memory location. Each processor has no direct knowledge about other processor's memory. For data to be shared, it must be passed from one processor to another as a message. Since there is no shared memory, contention is not as great a problem with these machines. It is not economically feasible to connect a large number of processors directly to each other. A way to avoid this multitude of direct connections is to connect each processor to just a few others. This type of design can be inefficient because of the added time required to pass a message from one processor to another along the message path. The amount of time required for processors to perform simple message routing can be substantial. Systems were designed to reduce this time loss and hypercube and mesh are among two of the popular interconnection schemes.
Examples of distributed memory (multiple computers) include MPP (massively parallel processors), COW (clusters of workstations) and NUMA (non-uniform memory access). The former is complex and expensive: Many super-computers coupled by broad-band networks. Examples include hypercube and mesh interconnections. COW is the "home-made" version for a fraction of the price.[5]
Hypercube interconnection network
In an MIMD distributed memory machine with a hypercube system interconnection network containing four processors, a processor and a memory module are placed at each vertex of a square. The diameter of the system is the minimum number of steps it takes for one processor to send a message to the processor that is the farthest away. So, for example, the diameter of a 2-cube is 2. In a hypercube system with eight processors and each processor and memory module being placed in the vertex of a cube, the diameter is 3. In general, a system that contains 2^N processors with each processor directly connected to N other processors, the diameter of the system is N. One disadvantage of a hypercube system is that it must be configured in powers of two, so a machine must be built that could potentially have many more processors than is really needed for the application.
Mesh interconnection network
In an MIMD distributed memory machine with a mesh interconnection network, processors are placed in a two-dimensional grid. Each processor is connected to its four immediate neighbors. Wrap around connections may be provided at the edges of the mesh. One advantage of the mesh interconnection network over the hypercube is that the mesh system need not be configured in powers of two. A disadvantage is that the diameter of the mesh network is greater than the hypercube for systems with more than four processors.
References
- Flynn, Michael J. (September 1972). "Some Computer Organizations and Their Effectiveness" (PDF). IEEE Transactions on Computers. C-21 (9): 948–960. doi:10.1109/TC.1972.5009071.
- "The Perils of Parallel: Larrabee vs. Nvidia, MIMD vs. SIMD". 19 September 2008.
- "MIMD | Intel® Developer Zone". Archived from the original on 2013-10-16. Retrieved 2013-10-16.
- Ibaroudene, Djaffer. "Parallel Processing, EG6370G: Chapter 1, Motivation and History." Lecture Slides. St Mary's University, San Antonio, Texas. Spring 2008.
- Andrew S. Tanenbaum (1997). Structured Computer Organization (4 ed.). Prentice-Hall. pp. 559–585. ISBN 978-0130959904. Archived from the original on 2013-12-01. Retrieved 2013-03-15.
| General | |
|---|---|
| Levels | |
| Multithreading |
|
| Theory | |
| Elements | |
| Coordination | |
| Programming | |
| Hardware | |
| APIs | |
| Problems | |
| |