Radix tree
In computer science, a radix tree (also radix trie or compact prefix tree or compressed trie) is a data structure that represents a space-optimized trie (prefix tree) in which each node that is the only child is merged with its parent. The result is that the number of children of every internal node is at most the radix r of the radix tree, where r is a positive integer and a power x of 2, having x ≥ 1. Unlike regular trees, edges can be labeled with sequences of elements as well as single elements. This makes radix trees much more efficient for small sets (especially if the strings are long) and for sets of strings that share long prefixes.
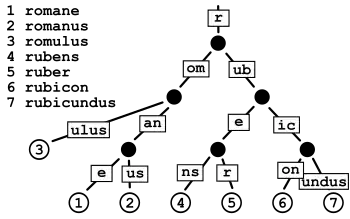
Unlike regular trees (where whole keys are compared en masse from their beginning up to the point of inequality), the key at each node is compared chunk-of-bits by chunk-of-bits, where the quantity of bits in that chunk at that node is the radix r of the radix trie. When r is 2, the radix trie is binary (i.e., compare that node's 1-bit portion of the key), which minimizes sparseness at the expense of maximizing trie depth—i.e., maximizing up to conflation of nondiverging bit-strings in the key. When r ≥ 4 is a power of 2, then the radix trie is an r-ary trie, which lessens the depth of the radix trie at the expense of potential sparseness.
As an optimization, edge labels can be stored in constant size by using two pointers to a string (for the first and last elements).[1]
Note that although the examples in this article show strings as sequences of characters, the type of the string elements can be chosen arbitrarily; for example, as a bit or byte of the string representation when using multibyte character encodings or Unicode.
Applications
Radix trees are useful for constructing associative arrays with keys that can be expressed as strings. They find particular application in the area of IP routing,[2][3][4] where the ability to contain large ranges of values with a few exceptions is particularly suited to the hierarchical organization of IP addresses.[5] They are also used for inverted indexes of text documents in information retrieval.
Operations
Radix trees support insertion, deletion, and searching operations. Insertion adds a new string to the trie while trying to minimize the amount of data stored. Deletion removes a string from the trie. Searching operations include (but are not necessarily limited to) exact lookup, find predecessor, find successor, and find all strings with a prefix. All of these operations are O(k) where k is the maximum length of all strings in the set, where length is measured in the quantity of bits equal to the radix of the radix trie.
Lookup
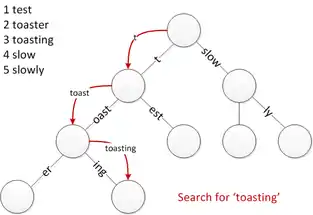
The lookup operation determines if a string exists in a trie. Most operations modify this approach in some way to handle their specific tasks. For instance, the node where a string terminates may be of importance. This operation is similar to tries except that some edges consume multiple elements.
The following pseudo code assumes that these methods and members exist.
Edge
- Node targetNode
- string label
Node
- Array of Edges edges
- function isLeaf()
function lookup(string x)
{
// Begin at the root with no elements found
Node traverseNode := root;
int elementsFound := 0;
// Traverse until a leaf is found or it is not possible to continue
while (traverseNode != null && !traverseNode.isLeaf() && elementsFound < x.length)
{
// Get the next edge to explore based on the elements not yet found in x
Edge nextEdge := select edge
from traverseNode.edges
where edge.label is a prefix of x.suffix(elementsFound)
// x.suffix(elementsFound) returns the last (x.length - elementsFound) elements of x
// Was an edge found?
if (nextEdge != null)
{
// Set the next node to explore
traverseNode := nextEdge.targetNode;
// Increment elements found based on the label stored at the edge
elementsFound += nextEdge.label.length;
}
else
{
// Terminate loop
traverseNode := null;
}
}
// A match is found if we arrive at a leaf node and have used up exactly x.length elements
return (traverseNode != null && traverseNode.isLeaf() && elementsFound == x.length);
}
Insertion
To insert a string, we search the tree until we can make no further progress. At this point we either add a new outgoing edge labeled with all remaining elements in the input string, or if there is already an outgoing edge sharing a prefix with the remaining input string, we split it into two edges (the first labeled with the common prefix) and proceed. This splitting step ensures that no node has more children than there are possible string elements.
Several cases of insertion are shown below, though more may exist. Note that r simply represents the root. It is assumed that edges can be labelled with empty strings to terminate strings where necessary and that the root has no incoming edge. (The lookup algorithm described above will not work when using empty-string edges.)
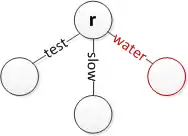 Insert 'water' at the root
Insert 'water' at the root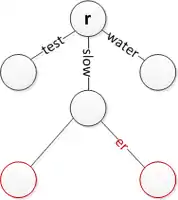 Insert 'slower' while keeping 'slow'
Insert 'slower' while keeping 'slow'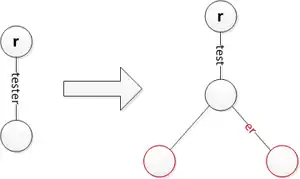 Insert 'test' which is a prefix of 'tester'
Insert 'test' which is a prefix of 'tester'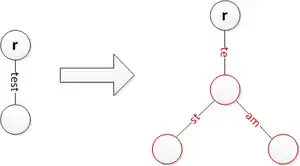 Insert 'team' while splitting 'test' and creating a new edge label 'st'
Insert 'team' while splitting 'test' and creating a new edge label 'st'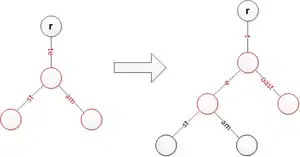 Insert 'toast' while splitting 'te' and moving previous strings a level lower
Insert 'toast' while splitting 'te' and moving previous strings a level lower
Deletion
To delete a string x from a tree, we first locate the leaf representing x. Then, assuming x exists, we remove the corresponding leaf node. If the parent of our leaf node has only one other child, then that child's incoming label is appended to the parent's incoming label and the child is removed.
Additional operations
- Find all strings with common prefix: Returns an array of strings that begin with the same prefix.
- Find predecessor: Locates the largest string less than a given string, by lexicographic order.
- Find successor: Locates the smallest string greater than a given string, by lexicographic order.
History
The datastructure was invented in 1968 by Donald R. Morrison,[6] with whom it is primarily associated, and by Gernot Gwehenberger.[7]
Donald Knuth, pages 498-500 in Volume III of The Art of Computer Programming, calls these "Patricia's trees", presumably after the acronym in the title of Morrison's paper: "PATRICIA - Practical Algorithm to Retrieve Information Coded in Alphanumeric". Today, Patricia tries are seen as radix trees with radix equals 2, which means that each bit of the key is compared individually and each node is a two-way (i.e., left versus right) branch.
Comparison to other data structures
(In the following comparisons, it is assumed that the keys are of length k and the data structure contains n members.)
Unlike balanced trees, radix trees permit lookup, insertion, and deletion in O(k) time rather than O(log n). This does not seem like an advantage, since normally k ≥ log n, but in a balanced tree every comparison is a string comparison requiring O(k) worst-case time, many of which are slow in practice due to long common prefixes (in the case where comparisons begin at the start of the string). In a trie, all comparisons require constant time, but it takes m comparisons to look up a string of length m. Radix trees can perform these operations with fewer comparisons, and require many fewer nodes.
Radix trees also share the disadvantages of tries, however: as they can only be applied to strings of elements or elements with an efficiently reversible mapping to strings, they lack the full generality of balanced search trees, which apply to any data type with a total ordering. A reversible mapping to strings can be used to produce the required total ordering for balanced search trees, but not the other way around. This can also be problematic if a data type only provides a comparison operation, but not a (de)serialization operation.
Hash tables are commonly said to have expected O(1) insertion and deletion times, but this is only true when considering computation of the hash of the key to be a constant-time operation. When hashing the key is taken into account, hash tables have expected O(k) insertion and deletion times, but may take longer in the worst case depending on how collisions are handled. Radix trees have worst-case O(k) insertion and deletion. The successor/predecessor operations of radix trees are also not implemented by hash tables.
Variants
A common extension of radix trees uses two colors of nodes, 'black' and 'white'. To check if a given string is stored in the tree, the search starts from the top and follows the edges of the input string until no further progress can be made. If the search string is consumed and the final node is a black node, the search has failed; if it is white, the search has succeeded. This enables us to add a large range of strings with a common prefix to the tree, using white nodes, then remove a small set of "exceptions" in a space-efficient manner by inserting them using black nodes.
The HAT-trie is a cache-conscious data structure based on radix trees that offers efficient string storage and retrieval, and ordered iterations. Performance, with respect to both time and space, is comparable to the cache-conscious hashtable.[8][9]
A PATRICIA trie is a special variant of the radix 2 (binary) trie, in which rather than explicitly store every bit of every key, the nodes store only the position of the first bit which differentiates two sub-trees. During traversal the algorithm examines the indexed bit of the search key and chooses the left or right sub-tree as appropriate. Notable features of the PATRICIA trie include that the trie only requires one node to be inserted for every unique key stored, making PATRICIA much more compact than a standard binary trie. Also, since the actual keys are no longer explicitly stored it is necessary to perform one full key comparison on the indexed record in order to confirm a match. In this respect PATRICIA bears a certain resemblance to indexing using a hash table.[6]
The adaptive radix tree is a radix tree variant that integrates adaptive node sizes to the radix tree. One major drawback of the usual radix trees is the use of space, because it uses a constant node size in every level. The major difference between the radix tree and the adaptive radix tree is its variable size for each node based on the number of child elements, which grows while adding new entries. Hence, the adaptive radix tree leads to a better use of space without reducing its speed.[10][11][12]
A common practice is to relax the criteria of disallowing parents with only one child in situations where the parent represents a valid key in the data set. This variant of radix tree achieves a higher space efficiency than the one which only allows internal nodes with at least two children.[13]
See also
References
- Morin, Patrick. "Data Structures for Strings" (PDF). Retrieved 15 April 2012.
- "rtfree(9)". www.freebsd.org. Retrieved 2016-10-23.
- The Regents of the University of California (1993). "/sys/net/radix.c". BSD Cross Reference. NetBSD. Retrieved 2019-07-25.
Routines to build and maintain radix trees for routing lookups.
- "Lockless, atomic and generic Radix/Patricia trees". NetBSD. 2011.
- Knizhnik, Konstantin. "Patricia Tries: A Better Index For Prefix Searches", Dr. Dobb's Journal, June, 2008.
- Morrison, Donald R. PATRICIA -- Practical Algorithm to Retrieve Information Coded in Alphanumeric
- G. Gwehenberger, Anwendung einer binären Verweiskettenmethode beim Aufbau von Listen. Elektronische Rechenanlagen 10 (1968), pp. 223–226
- Askitis, Nikolas; Sinha, Ranjan (2007). HAT-trie: A Cache-conscious Trie-based Data Structure for Strings. pp. 97–105. ISBN 978-1-920682-43-9.
{{cite book}}:|journal=ignored (help) - Askitis, Nikolas; Sinha, Ranjan (October 2010). "Engineering scalable, cache and space efficient tries for strings". The VLDB Journal. 19 (5): 633–660. doi:10.1007/s00778-010-0183-9. S2CID 432572.
- Kemper, Alfons; Eickler, André (2013). Datenbanksysteme, Eine Einführung. Vol. 9. Oldenbourg. pp. 604–605. ISBN 978-3-486-72139-3.
- "armon/libart: Adaptive Radix Trees implemented in C". GitHub. Retrieved 17 September 2014.
- Viktor Leis; et al. (2013). "The adaptive radix tree: ARTful indexing for main-memory databases". 2013 IEEE 29th International Conference on Data Engineering (ICDE). pp. 38–49. doi:10.1109/ICDE.2013.6544812. ISBN 978-1-4673-4910-9. S2CID 14030601.
{{cite book}}: CS1 maint: date and year (link) - Can a node of Radix tree which represents a valid key have one child?
External links
- Algorithms and Data Structures Research & Reference Material: PATRICIA, by Lloyd Allison, Monash University
- Patricia Tree, NIST Dictionary of Algorithms and Data Structures
- Crit-bit trees, by Daniel J. Bernstein
- Radix Tree API in the Linux Kernel, by Jonathan Corbet
- Kart (key alteration radix tree), by Paul Jarc
- The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases, by Viktor Leis, Alfons Kemper, Thomas Neumann, Technical University of Munich
Implementations
- FreeBSD Implementation, used for paging, forwarding and other things.
- Linux Kernel Implementation, used for the page cache, among other things.
- GNU C++ Standard library has a trie implementation
- Java implementation of Concurrent Radix Tree, by Niall Gallagher
- C# implementation of a Radix Tree
- Practical Algorithm Template Library, a C++ library on PATRICIA tries (VC++ >=2003, GCC G++ 3.x), by Roman S. Klyujkov
- Patricia Trie C++ template class implementation, by Radu Gruian
- Haskell standard library implementation "based on big-endian patricia trees". Web-browsable source code.
- Patricia Trie implementation in Java, by Roger Kapsi and Sam Berlin
- Crit-bit trees forked from C code by Daniel J. Bernstein
- Patricia Trie implementation in C, in libcprops
- Patricia Trees : efficient sets and maps over integers in OCaml, by Jean-Christophe Filliâtre
- Radix DB (Patricia trie) implementation in C, by G. B. Versiani
- Libart - Adaptive Radix Trees implemented in C, by Armon Dadgar with other contributors (Open Source, BSD 3-clause license)
- Nim implementation of a crit-bit tree
- rax, a radix tree implementation in ANSI C by Salvatore Sanfilippo (the creator of REDIS)