R*-tree
In data processing R*-trees are a variant of R-trees used for indexing spatial information. R*-trees have slightly higher construction cost than standard R-trees, as the data may need to be reinserted; but the resulting tree will usually have a better query performance. Like the standard R-tree, it can store both point and spatial data. It was proposed by Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider, and Bernhard Seeger in 1990.[1]
| R*-tree | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Invented | 1990 | ||||||||||||
| Invented by | Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider, and Bernhard Seeger | ||||||||||||
| Time complexity in big O notation | |||||||||||||
| |||||||||||||
Difference between R*-trees and R-trees

Minimization of both coverage and overlap is crucial to the performance of R-trees. Overlap means that, on data query or insertion, more than one branch of the tree needs to be expanded (due to the way data is being split in regions which may overlap). A minimized coverage improves pruning performance, allowing exclusion of whole pages from search more often, in particular for negative range queries. The R*-tree attempts to reduce both, using a combination of a revised node split algorithm and the concept of forced reinsertion at node overflow. This is based on the observation that R-tree structures are highly susceptible to the order in which their entries are inserted, so an insertion-built (rather than bulk-loaded) structure is likely to be sub-optimal. Deletion and reinsertion of entries allows them to "find" a place in the tree that may be more appropriate than their original location.
When a node overflows, a portion of its entries are removed from the node and reinserted into the tree. (In order to avoid an indefinite cascade of reinsertions caused by subsequent node overflow, the reinsertion routine may be called only once in each level of the tree when inserting any one new entry.) This has the effect of producing more well-clustered groups of entries in nodes, reducing node coverage. Furthermore, actual node splits are often postponed, causing average node occupancy to rise. Re-insertion can be seen as a method of incremental tree optimization triggered on node overflow.
Performance
- Improved split heuristic produces pages that are more rectangular and thus better for many applications.
- Reinsertion method optimizes the existing tree but increases complexity.
- Efficiently supports point and spatial data at the same time.
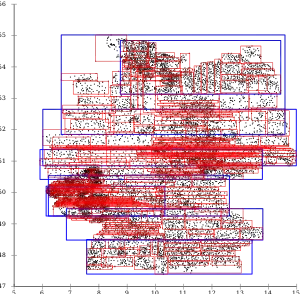 R-Tree with Guttman quadratic split.[2]
R-Tree with Guttman quadratic split.[2]
There are many pages that extend from east to west all over Germany, and pages overlap a lot. This is not beneficial for most applications, that often only need a small rectangular area that intersects with many slices.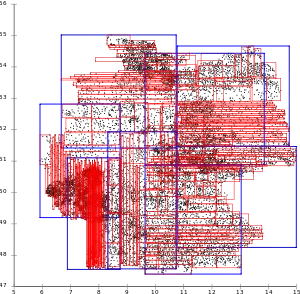 R-Tree with Ang-Tan linear split.[3]
R-Tree with Ang-Tan linear split.[3]
While the slices do not extend as far as with Guttman, the slicing problem affects almost every leaf page. Leaf pages overlap little, but directory pages do.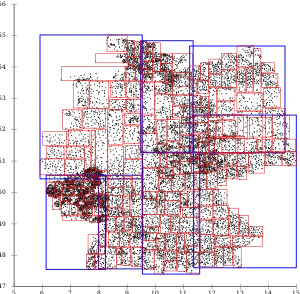 R*-tree topological split.[1]
R*-tree topological split.[1]
The pages overlap very little since the R*-tree tries to minimize page overlap, and the reinsertions further optimized the tree. The split strategy also does not prefer slices, so the resulting pages are much more useful for common map applications.
Algorithm and complexity
- The R*-tree uses the same algorithm as the regular R-tree for query and delete operations.
- When inserting, the R*-tree uses a combined strategy. For leaf nodes, overlap is minimized, while for inner nodes, enlargement and area are minimized.
- When splitting, the R*-tree uses a topological split that chooses a split axis based on perimeter, then minimizes overlap.
- In addition to an improved split strategy, the R*-tree also tries to avoid splits by reinserting objects and subtrees into the tree, inspired by the concept of balancing a B-tree.
Worst case query and delete complexity are thus identical to the R-Tree. The insertion strategy to the R*-tree is with more complex than the linear split strategy () of the R-tree, but less complex than the quadratic split strategy () for a page size of objects and has little impact on the total complexity. The total insert complexity is still comparable to the R-tree: reinsertions affect at most one branch of the tree and thus reinsertions, comparable to performing a split on a regular R-tree. So, on overall, the complexity of the R*-tree is the same as that of a regular R-tree.





An implementation of the full algorithm must address many corner cases and tie situations not discussed here.
References
- Beckmann, N.; Kriegel, H. P.; Schneider, R.; Seeger, B. (1990). "The R*-tree: an efficient and robust access method for points and rectangles". Proceedings of the 1990 ACM SIGMOD international conference on Management of data - SIGMOD '90 (PDF). p. 322. doi:10.1145/93597.98741. ISBN 0897913655.
- Guttman, A. (1984). "R-Trees: A Dynamic Index Structure for Spatial Searching". Proceedings of the 1984 ACM SIGMOD international conference on Management of data - SIGMOD '84 (PDF). p. 47. doi:10.1145/602259.602266. ISBN 0897911288.
- Ang, C. H.; Tan, T. C. (1997). "New linear node splitting algorithm for R-trees". In Scholl, Michel; Voisard, Agnès (eds.). Proceedings of the 5th International Symposium on Advances in Spatial Databases (SSD '97), Berlin, Germany, July 15–18, 1997. Lecture Notes in Computer Science. Vol. 1262. Springer. pp. 337–349. doi:10.1007/3-540-63238-7_38.
External links
 Media related to R*-tree at Wikimedia Commons
Media related to R*-tree at Wikimedia Commons