Range query (computer science)
In computer science, the range query problem consists of efficiently answering several queries regarding a given interval of elements within an array. For example, a common task, known as range minimum query, is finding the smallest value inside a given range within a list of numbers.
Definition
Given a function that accepts an array, a range query on an array takes two indices and and returns the result of when applied to the subarray . For example, for a function that returns the sum of all values in an array, the range query returns the sum of all values in the range .


![{\displaystyle a=[a_{1},..,a_{n}]}](../I/bfee703d5e0d7590624b9986d976da72c40a24c5.svg)


![{\displaystyle [a_{l},\ldots ,a_{r}]}](../I/157d202c2620fc802ce03c494d1a334f8b16b86d.svg)


![{\displaystyle [l,r]}](../I/be45874f852a2b7bfa2df52888aaec6919238623.svg)
Solutions
Prefix sum array
Range sum queries may be answered in constant time and linear space by pre-computing an array p of same length as the input such that for every index i, the element is the sum of the first i elements of a. Any query may then be computed as follows:


This strategy may be extended to any other binary operation whose inverse function is well-defined and easily computable.[1] It can also be extended to two-dimensional arrays with a similar pre-processing.[2]

Dynamic range queries
A more difficult subset of the problem consists of executing range queries on dynamic data; that is, data that may mutate between each query. In order to efficiently update array values, more sophisticated data structures like the segment tree are necessary.
Examples
Semigroup operators
When the function of interest in a range query is a semigroup operator, the notion of is not always defined, so the strategy in the previous section does not work. Andrew Yao showed[3] that there exists an efficient solution for range queries that involve semigroup operators. He proved that for any constant c, a pre-processing of time and space allows to answer range queries on lists where f is a semigroup operator in time, where is a certain functional inverse of the Ackermann function.



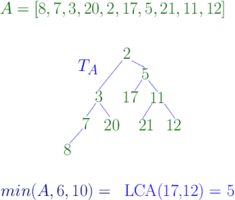
There are some semigroup operators that admit slightly better solutions. For instance when . Assume then returns the index of the minimum element of . Then denotes the corresponding minimum range query. There are several data structures that allow to answer a range minimum query in time using a pre-processing of time and space . One such solution is based on the equivalence between this problem and the lowest common ancestor problem.


![\min(A[1..n])](../I/5d8d8530388e1ea988fb99d8f397d2fbccedc00b.svg)
![A[1..n]](../I/77350b7b7a24749675609a440314e0ab8aded3d5.svg)



The Cartesian tree of an array has as root and as left and right subtrees the Cartesian tree of and the Cartesian tree of respectively. A range minimum query is the lowest common ancestor in of and . Because the lowest common ancestor can be solved in constant time using a pre-processing of time and space , range minimum query can as well. The solution when is analogous. Cartesian trees can be constructed in linear time.

![A[1,n]](../I/26e95238b8e5487bf83e4597fd94fd2831564c31.svg)

![A[1,i-1]](../I/8c7c5431a1ca2535ca64328560c47ae54d772e6d.svg)
![A[i+1,n]](../I/f89bc10f9412e7c652cb45be7ba08b8dd03bc579.svg)



Mode
The mode of an array is the element that appears the most in it. For instance the mode of is 4. In case of a tie, any of the most frequent elements might be picked as the mode. A range mode query consists in pre-processing such that we can find the mode in any range of . Several data structures have been devised to solve this problem, we summarize some of the results in the following table.[1]
![{\displaystyle a=[4,5,6,7,4]}](../I/1422132e3bddcf0e4b61dc53bf1b0970b51c7577.svg)
| Space | Query Time | Restrictions |
|---|---|---|




Recently Jørgensen et al. proved a lower bound on the cell-probe model of for any data structure that uses S cells.[4]

Median
This particular case is of special interest since finding the median has several applications.[5] On the other hand, the median problem, a special case of the selection problem, is solvable in O(n), using the median of medians algorithm.[6] However its generalization through range median queries is recent.[7] A range median query where A,i and j have the usual meanings returns the median element of . Equivalently, should return the element of of rank . Range median queries cannot be solved by following any of the previous methods discussed above including Yao's approach for semigroup operators.[8]

![A[i,j]](../I/c1a9bfca6057f52b4e5c3844ecd704962b7e426c.svg)

There have been studied two variants of this problem, the offline version, where all the k queries of interest are given in a batch, and a version where all the pre-processing is done up front. The offline version can be solved with time and space.


The following pseudocode of the quickselect algorithm shows how to find the element of rank r in an unsorted array of distinct elements, to find the range medians we set .[7]

rangeMedian(A, i, j, r) {
if A.length() == 1
return A[1]
if A.low is undefined then
m = median(A)
A.low = [e in A | e <= m]
A.high = [e in A | e > m ]
calculate t the number of elements of A[i, j] that belong to A.low
if r <= t then
return rangeMedian(A.low, i, j, r)
else
return rangeMedian(A.high, i, j, r-t)
}
Procedure rangeMedian partitions A, using A's median, into two arrays A.low and A.high, where the former contains
the elements of A that are less than or equal to the median m and the latter the rest of the elements of A. If we know that the number of elements of that
end up in A.low is t and this number is bigger than r then we should keep looking for the element of rank r in A.low; otherwise we should look for the element of rank in A.high. To find t, it is enough to find the maximum index such that is in A.low and the maximum index such that
is in A.high. Then . The total cost for any query, without considering the partitioning part, is since at most recursion calls are done and only a constant number of operations are performed in each of them (to get the value of t fractional cascading should be used).
If a linear algorithm to find the medians is used, the total cost of pre-processing for k range median queries is . The algorithm can also be modified to solve the online version of the problem.[7]








Majority
Finding frequent elements in a given set of items is one of the most important tasks in data mining. Finding frequent elements might be a difficult task to achieve when most items have similar frequencies. Therefore, it might be more beneficial if some threshold of significance was used for detecting such items. One of the most famous algorithms for finding the majority of an array was proposed by Boyer and Moore [9] which is also known as the Boyer–Moore majority vote algorithm. Boyer and Moore proposed an algorithm to find the majority element of a string (if it has one) in time and using space. In the context of Boyer and Moore’s work and generally speaking, a majority element in a set of items (for example string or an array) is one whose number of instances is more than half of the size of that set. Few years later, Misra and Gries [10] proposed a more general version of Boyer and Moore's algorithm using comparisons to find all items in an array whose relative frequencies are greater than some threshold . A range -majority query is one that, given a subrange of a data structure (for example an array) of size , returns the set of all distinct items that appear more than (or in some publications equal to) times in that given range. In different structures that support range -majority queries, can be either static (specified during pre-processing) or dynamic (specified at query time). Many of such approaches are based on the fact that, regardless of the size of the range, for a given there could be at most distinct candidates with relative frequencies at least . By verifying each of these candidates in constant time, query time is achieved. A range -majority query is decomposable [11] in the sense that a -majority in a range with partitions and must be a -majority in either or . Due to this decomposability, some data structures answer -majority queries on one-dimensional arrays by finding the Lowest common ancestor (LCA) of the endpoints of the query range in a Range tree and validating two sets of candidates (of size ) from each endpoint to the lowest common ancestor in constant time resulting in query time.









Two-dimensional arrays
Gagie et al.[12] proposed a data structure that supports range -majority queries on an array . For each query in this data structure a threshold and a rectangular range are specified, and the set of all elements that have relative frequencies (inside that rectangular range) greater than or equal to are returned as the output. This data structure supports dynamic thresholds (specified at query time) and a pre-processing threshold based on which it is constructed. During the pre-processing, a set of vertical and horizontal intervals are built on the array. Together, a vertical and a horizontal interval form a block. Each block is part of a superblock nine times bigger than itself (three times the size of the block's horizontal interval and three times the size of its vertical one). For each block a set of candidates (with elements at most) is stored which consists of elements that have relative frequencies at least (the pre-processing threshold as mentioned above) in its respective superblock. These elements are stored in non-increasing order according to their frequencies and it is easy to see that, any element that has a relative frequency at least in a block must appear its set of candidates. Each -majority query is first answered by finding the query block, or the biggest block that is contained in the provided query rectangle in time. For the obtained query block, the first candidates are returned (without being verified) in time, so this process might return some false positives. Many other data structures (as discussed below) have proposed methods for verifying each candidate in constant time and thus maintaining the query time while returning no false positives. The cases in which the query block is smaller than are handled by storing different instances of this data structure of the following form:











where is the pre-processing threshold of the -th instance. Thus, for query blocks smaller than the -th instance is queried. As mentioned above, this data structure has query time and requires bits of space by storing a Huffman-encoded copy of it (note the factor and also see Huffman coding).





One-dimensional arrays
Chan et al.[13] proposed a data structure that given a one-dimensional array, a subrange of (specified at query time) and a threshold (specified at query time), is able to return the list of all -majorities in time requiring words of space. To answer such queries, Chan et al.[13] begin by noting that there exists a data structure capable of returning the top-k most frequent items in a range in time requiring words of space. For a one-dimensional array , let a one-sided top-k range query to be of form . For a maximal range of ranges in which the frequency of a distinct element in remains unchanged (and equal to ), a horizontal line segment is constructed. The -interval of this line segment corresponds to and it has a -value equal to . Since adding each element to changes the frequency of exactly one distinct element, the aforementioned process creates line segments. Moreover, for a vertical line all horizonal line segments intersecting it are sorted according to their frequencies. Note that, each horizontal line segment with -interval corresponds to exactly one distinct element in , such that . A top-k query can then be answered by shooting a vertical ray and reporting the first horizontal line segments that intersect it (remember from above that these line line segments are already sorted according to their frequencies) in time.


![{\displaystyle A[0,..,n-1]}](../I/dfc1406a5a7e793427efd083d225a262cbc78276.svg)
![{\displaystyle A[0..i]{\text{ for }}0\leq i\leq n-1}](../I/3e90a91ed0626f9431dda46d96a853290496a044.svg)
![{\displaystyle A[0..i]{\text{ through }}A[0..j]}](../I/6672bb208b95f79f092bdbdccbd5a4514a773ba4.svg)


![{\displaystyle [i,j]}](../I/fff46b0cabba9dd4a48696b0d6f85eb38192a021.svg)


![{\displaystyle [\ell ,r]}](../I/232f352c1ef21293496af1e63a46ae9c8fbff472.svg)
![{\displaystyle A[\ell ]=e}](../I/92a275dc6aff7cfc7a7c604dbfdf62cf54fabbfa.svg)

Chan et al.[13] first construct a range tree in which each branching node stores one copy of the data structure described above for one-sided range top-k queries and each leaf represents an element from . The top-k data structure at each node is constructed based on the values existing in the subtrees of that node and is meant to answer one-sided range top-k queries. Please note that for a one-dimensional array , a range tree can be constructed by dividing into two halves and recursing on both halves; therefore, each node of the resulting range tree represents a range. It can also be seen that this range tree requires words of space, because there are levels and each level has nodes. Moreover, since at each level of a range tree all nodes have a total of elements of at their subtrees and since there are levels, the space complexity of this range tree is .




Using this structure, a range -majority query on with is answered as follows. First, the lowest common ancestor (LCA) of leaf nodes and is found in constant time. Note that there exists a data structure requiring bits of space that is capable of answering the LCA queries in time.[14] Let denote the LCA of and , using and according to the decomposability of range -majority queries (as described above and in [11]), the two-sided range query can be converted into two one-sided range top-k queries (from to and ). These two one-sided range top-k queries return the top-() most frequent elements in each of their respective ranges in time. These frequent elements make up the set of candidates for -majorities in in which there are candidates some of which might be false positives. Each candidate is then assessed in constant time using a linear-space data structure (as described in Lemma 3 in [15]) that is able to determine in time whether or not a given subrange of an array contains at least instances of a particular element .
![{\displaystyle A[i..j]}](../I/58d6653220c78627b4b8eb63a9c4ea12d0907ae7.svg)
![{\displaystyle A[0..n-1]}](../I/b737ac95f85366049c16de06fca7a3a3cd138f9d.svg)





Tree paths
Gagie et al.[16] proposed a data structure which supports queries such that, given two nodes and in a tree, are able to report the list of elements that have a greater relative frequency than on the path from to . More formally, let be a labelled tree in which each node has a label from an alphabet of size . Let denote the label of node in . Let denote the unique path from to in in which middle nodes are listed in the order they are visited. Given , and a fixed (specified during pre-processing) threshold , a query must return the set of all labels that appear more than times in .




![{\displaystyle label(u)\in [1,\dots ,\sigma ]}](../I/f1d838758aed0aa9fdc99ed3a861c9b6a24ca231.svg)



To construct this data structure, first nodes are marked. This can be done by marking any node that has distance at least from the bottom of the three (height) and whose depth is divisible by . After doing this, it can be observed that the distance between each node and its nearest marked ancestor is less than . For a marked node , different sequences (paths towards the root) are stored,






for where returns the label of the direct parent of node . Put another way, for each marked node, the set of all paths with a power of two length (plus one for the node itself) towards the root is stored. Moreover, for each , the set of all majority candidates are stored. More specifically, contains the set of all -majorities in or labels that appear more than times in . It is easy to see that the set of candidates can have at most distinct labels for each . Gagie et al.[16] then note that the set of all -majorities in the path from any marked node to one of its ancestors is included in some (Lemma 2 in [16]) since the length of is equal to thus there exists a for whose length is between where is the distance between x and z. The existence of such implies that a -majority in the path from to must be a -majority in , and thus must appear in . It is easy to see that this data structure require words of space, because as mentioned above in the construction phase nodes are marked and for each marked node some candidate sets are stored. By definition, for each marked node of such sets are stores, each of which contains candidates. Therefore, this data structure requires words of space. Please note that each node also stores which is equal to the number of instances of on the path from to the root of , this does not increase the space complexity since it only adds a constant number of words per node.













Each query between two nodes and can be answered by using the decomposability property (as explained above) of range -majority queries and by breaking the query path between and into four subpaths. Let be the lowest common ancestor of and , with and being the nearest marked ancestors of and respectively. The path from to is decomposed into the paths from and to and respectively (the size of these paths are smaller than by definition, all of which are considered as candidates), and the paths from and to (by finding the suitable as explained above and considering all of its labels as candidates). Please note that, boundary nodes have to be handled accordingly so that all of these subpaths are disjoint and from all of them a set of candidates is derived. Each of these candidates is then verified using a combination of the query which returns the lowest ancestor of node that has label and the fields of each node. On a -bit RAM and an alphabet of size , the query can be answered in time whilst having linear space requirements.[17] Therefore, verifying each of the candidates in time results in total query time for returning the set of all -majorities on the path from to .




Related problems
All the problems described above have been studied for higher dimensions as well as their dynamic versions. On the other hand, range queries might be extended to other data structures like trees,[8] such as the level ancestor problem. A similar family of problems are orthogonal range queries, also known as counting queries.
References
- Krizanc, Danny; Morin, Pat; Smid, Michiel H. M. (2003). "Range Mode and Range Median Queries on Lists and Trees". ISAAC: 517–526. arXiv:cs/0307034. Bibcode:2003cs........7034K.
- Meng, He; Munro, J. Ian; Nicholson, Patrick K. (2011). "Dynamic Range Selection in Linear Space". ISAAC: 160–169. arXiv:1106.5076.
- Yao, A. C (1982). "Space-Time Tradeoff for Answering Range Queries". E 14th Annual ACM Symposium on the Theory of Computing: 128–136.
- Greve, M; J{\o}rgensen, A.; Larsen, K.; Truelsen, J. (2010). "Cell probe lower bounds and approximations for range mode". Automata, Languages and Programming: 605–616.
- Har-Peled, Sariel; Muthukrishnan, S. (2008). "Range Medians". ESA: 503–514.
- Blum, M.; Floyd, R. W.; Pratt, V. R.; Rivest, R. L.; Tarjan, R. E. (August 1973). "Time bounds for selection" (PDF). Journal of Computer and System Sciences. 7 (4): 448–461. doi:10.1016/S0022-0000(73)80033-9.
- Beat, Gfeller; Sanders, Peter (2009). "Towards Optimal Range Medians". Icalp (1): 475–486. arXiv:0901.1761.
- Bose, P; Kranakis, E.; Morin, P.; Tang, Y. (2005). "Approximate range mode and range median queries". In Proceedings of the 22nd Symposium on Theoretical Aspects of Computer Science (STACS 2005), Volume 3404 of Lecture Notes in ComputerScience: 377–388.
- Boyer, Robert S.; Moore, J. Strother (1991), MJRTY—A Fast Majority Vote Algorithm, Automated Reasoning Series, vol. 1, Dordrecht: Springer Netherlands, pp. 105–117, doi:10.1007/978-94-011-3488-0_5, ISBN 978-94-010-5542-0, retrieved 2021-12-18
- Misra, J.; Gries, David (November 1982). "Finding repeated elements". Science of Computer Programming. 2 (2): 143–152. doi:10.1016/0167-6423(82)90012-0. ISSN 0167-6423.
- Karpiński, Marek. Searching for frequent colors in rectangles. OCLC 277046650.
- Gagie, Travis; He, Meng; Munro, J. Ian; Nicholson, Patrick K. (2011), "Finding Frequent Elements in Compressed 2D Arrays and Strings", String Processing and Information Retrieval, Berlin, Heidelberg: Springer Berlin Heidelberg, pp. 295–300, doi:10.1007/978-3-642-24583-1_29, ISBN 978-3-642-24582-4, retrieved 2021-12-18
- Chan, Timothy M.; Durocher, Stephane; Skala, Matthew; Wilkinson, Bryan T. (2012), "Linear-Space Data Structures for Range Minority Query in Arrays", Algorithm Theory – SWAT 2012, Berlin, Heidelberg: Springer Berlin Heidelberg, pp. 295–306, doi:10.1007/978-3-642-31155-0_26, ISBN 978-3-642-31154-3, retrieved 2021-12-20
- Sadakane, Kunihiko; Navarro, Gonzalo (2010-01-17). "Fully-Functional Succinct Trees". Proceedings of the Twenty-First Annual ACM-SIAM Symposium on Discrete Algorithms. Philadelphia, PA: Society for Industrial and Applied Mathematics: 134–149. doi:10.1137/1.9781611973075.13. ISBN 978-0-89871-701-3. S2CID 3189222.
- Chan, Timothy M.; Durocher, Stephane; Larsen, Kasper Green; Morrison, Jason; Wilkinson, Bryan T. (2013-03-08). "Linear-Space Data Structures for Range Mode Query in Arrays". Theory of Computing Systems. 55 (4): 719–741. doi:10.1007/s00224-013-9455-2. ISSN 1432-4350. S2CID 253747004.
- Gagie, Travis; He, Meng; Navarro, Gonzalo; Ochoa, Carlos (September 2020). "Tree path majority data structures". Theoretical Computer Science. 833: 107–119. doi:10.1016/j.tcs.2020.05.039. ISSN 0304-3975.
- He, Meng; Munro, J. Ian; Zhou, Gelin (2014-07-08). "A Framework for Succinct Labeled Ordinal Trees over Large Alphabets". Algorithmica. 70 (4): 696–717. doi:10.1007/s00453-014-9894-4. ISSN 0178-4617. S2CID 253977813.