Sequence database
In the field of bioinformatics, a sequence database is a type of biological database that is composed of a large collection of computerized ("digital") nucleic acid sequences, protein sequences, or other polymer sequences stored on a computer. The UniProt database is an example of a protein sequence database. As of 2013 it contained over 40 million sequences and is growing at an exponential rate.[1] Historically, sequences were published in paper form, but as the number of sequences grew, this storage method became unsustainable.
Search
Searching in a sequence database involves looking for similarities between a genomic/protein sequence and a query string and, finding the sequence in the database that "best" matches the target sequence (based on criteria which vary depending on the search method). The number of matches/hits is used to formulate a score that determines the similarity between the sequence query and the sequences in the sequence database.[2] The main goal is to have a good balance between the two criteria.
History
1950
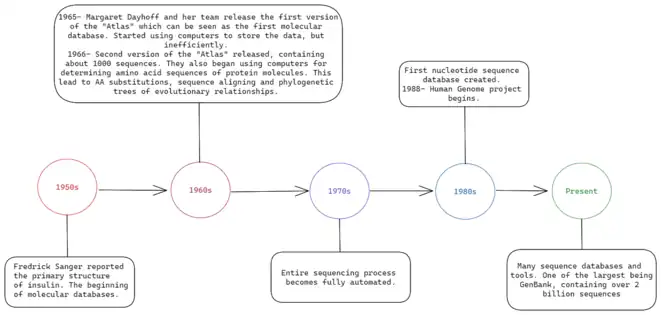
The need for sequence databases originated in 1950 when Fredrick Sanger reported the primary structure of insulin. He won his second Nobel Prize for creating methods for sequencing nucleic acids, and his comparative approach is what sparked other protein biochemists to begin collecting amino acid sequences. Thus marking the beginning of molecular databases.[3]
1960
In 1965 Margaret Dayhoff and her team at the National Biomedical Research Foundation (NBRF) published "The Atlas of Protein Sequence and Structure". They put all know protein sequences in the Atlas, even unpublished material. This can be seen as the first attempt to create a molecular database. They made use of the newly computerized (1964) Medical Literature Analysis and Retrieval System (MEDLARS) at the National Institutes of Health (NIH). The team used computers to store the data but had to manually type and proofread each sequence, which had a high cost in time and money.[3]
In 1966 the team released the second edition of the Atlas, double the size of the first. It contained about 1000 sequences, and this time was coined as an information explosion. The National Biomedical Research Foundation (NBRF) was on the cutting edge of utilizing computers for medicine and biology at this time. Dayhoff and her team made use of their facilities for determining amino acid sequences of protein molecules in mainframe computers. The number of discovered sequences continued to grow allowing for a deeper comparative analysis of proteins than ever before. This led to many developments such as, probabilistic models of amino acid substitutions, sequence aligning and phylogenetic trees of evolutionary relationships of proteins.[3]
1970
Entire sequencing process became fully automated.[3]
1980
The first nucleotide sequence database was created. Previously known as the European Molecular Biology Laboratory (EMBL) Nucleotide Sequence Data Library (now known as European Nucleotide archive). Human Genome Project began in 1988. The project's goal was sequence and map all the genes in a human which required the capability to create and utilize a large sequence database.[4]
Present day
We now have many sequence databases, tools for using them and easy access to them. One of the largest being GenBank which contains over 2 billion sequences.[3]
Timeline
Current issues
Storage & redundancy
Records in sequence databases are deposited from a wide range of sources, from individual researchers to large genome sequencing centers. As a result, the sequences themselves, and especially the biological annotations attached to these sequences, may vary in quality. There is much redundancy, as multiple labs may submit numerous sequences that are identical, or nearly identical, to others in the databases.[5]
Many annotations of the sequences are based not on laboratory experiments, but on the results of sequence similarity searches for previously annotated sequences. Once a sequence has been annotated based on similarity to others, and itself deposited in the database, it can also become the basis for future annotations. This can lead to a transitive annotation problem because there may be several such annotation transfers by sequence similarity between a particular database record and actual wet lab experimental information.[6] Therefore, care must be taken when interpreting the annotation data from sequence databases.
Scoring methods
Most of the current database search algorithms rank alignment by a score, which is usually a particular scoring system.[7] The solution towards solving this issue is found by making a variety of scoring systems available to suit to the specific problem.
Alignment statistics
When using a searching algorithm we often produce an ordered list which can often carry a lack of biological significance.[8]
References
- Cochrane, G.; Karsch-Mizrachi, I.; Nakamura, Y. (23 November 2010). "The International Nucleotide Sequence Database Collaboration". Nucleic Acids Research. 39 (Database): D15–D18. doi:10.1093/nar/gkq1150. PMC 3013722. PMID 21106499.
- Sung, Wing-Kin (2010). Algorithms in bioinformatics : a practical introduction. Boca Raton: Chapman & Hall/CRC Press. p. 109. ISBN 9781420070330.
- Hagen, Joel B. (2011), Hamacher, Michael; Eisenacher, Martin; Stephan, Christian (eds.), "The Origin and Early Reception of Sequence Databases", Data Mining in Proteomics: From Standards to Applications, Methods in Molecular Biology, Totowa, NJ: Humana Press, vol. 696, pp. 61–77, doi:10.1007/978-1-60761-987-1_4, ISBN 978-1-60761-987-1, PMID 21063941, retrieved 5 May 2022
- "History < EMBL-EBI". www.ebi.ac.uk. Retrieved 5 May 2022.
- Sikic, K.; Carugo, O. (2010). "Protein sequence redundancy reduction: comparison of various method". Bioinformation. 5 (6): 234–9. doi:10.6026/97320630005234. PMC 3055704. PMID 21364823.
- Iliopoulos, I.; Tsoka, S.; Andrade, MA.; Enright, AJ.; Carroll, M.; Poullet, P.; Promponas, V.; Liakopoulos, T.; et al. (April 2003). "Evaluation of annotation strategies using an entire genome sequence". Bioinformatics. 19 (6): 717–26. doi:10.1093/bioinformatics/btg077. PMID 12691983.
- Altschul, Stephen; Boguski, Mark; Gish, Warren; Wootton, John (1994). "Issues in searching molecular sequence databases" (PDF). Nature Genetics. Nature Publishing Group. 6 (2): 119–129. doi:10.1038/ng0294-119. PMID 8162065. S2CID 270160.
- Altschul, Stephen; Boguski, Mark; Gish, Warren; Wootton, John (1994). "Issues in searching molecular sequence databases" (PDF). Nature Genetics. Nature Publishing Group. 6 (2): 119–129. doi:10.1038/ng0294-119. PMID 8162065. S2CID 270160.
External links
- European Bioinformatics Institute databases
- NCBI completely sequenced genomes
- Stanford Saccharomyces Genome Database
- Protein, the NIH protein database, a collection of sequences from several sources, including translations from annotated coding regions in GenBank, RefSeq and TPA, as well as records from SwissProt, PIR, PRF, and PDB