Failure rate
Failure rate is the frequency with which an engineered system or component fails, expressed in failures per unit of time. It is usually denoted by the Greek letter λ (lambda) and is often used in reliability engineering.
The failure rate of a system usually depends on time, with the rate varying over the life cycle of the system. For example, an automobile's failure rate in its fifth year of service may be many times greater than its failure rate during its first year of service. One does not expect to replace an exhaust pipe, overhaul the brakes, or have major transmission problems in a new vehicle.
In practice, the mean time between failures (MTBF, 1/λ) is often reported instead of the failure rate. This is valid and useful if the failure rate may be assumed constant – often used for complex units / systems, electronics – and is a general agreement in some reliability standards (Military and Aerospace). It does in this case only relate to the flat region of the bathtub curve, which is also called the "useful life period". Because of this, it is incorrect to extrapolate MTBF to give an estimate of the service lifetime of a component, which will typically be much less than suggested by the MTBF due to the much higher failure rates in the "end-of-life wearout" part of the "bathtub curve".
The reason for the preferred use for MTBF numbers is that the use of large positive numbers (such as 2000 hours) is more intuitive and easier to remember than very small numbers (such as 0.0005 per hour).
The MTBF is an important system parameter in systems where failure rate needs to be managed, in particular for safety systems. The MTBF appears frequently in the engineering design requirements, and governs frequency of required system maintenance and inspections. In special processes called renewal processes, where the time to recover from failure can be neglected and the likelihood of failure remains constant with respect to time, the failure rate is simply the multiplicative inverse of the MTBF (1/λ).
A similar ratio used in the transport industries, especially in railways and trucking is "mean distance between failures", a variation which attempts to correlate actual loaded distances to similar reliability needs and practices.
Failure rates are important factors in the insurance, finance, commerce and regulatory industries and fundamental to the design of safe systems in a wide variety of applications.
Failure rate data
Failure rate data can be obtained in several ways. The most common means are:
- Estimation
- From field failure rate reports, statistical analysis techniques can be used to estimate failure rates. For accurate failure rates the analyst must have a good understanding of equipment operation, procedures for data collection, the key environmental variables impacting failure rates, how the equipment is used at the system level, and how the failure data will be used by system designers.
- Historical data about the device or system under consideration
- Many organizations maintain internal databases of failure information on the devices or systems that they produce, which can be used to calculate failure rates for those devices or systems. For new devices or systems, the historical data for similar devices or systems can serve as a useful estimate.
- Government and commercial failure rate data
- Handbooks of failure rate data for various components are available from government and commercial sources. MIL-HDBK-217F, Reliability Prediction of Electronic Equipment, is a military standard that provides failure rate data for many military electronic components. Several failure rate data sources are available commercially that focus on commercial components, including some non-electronic components.
- Prediction
- Time lag is one of the serious drawbacks of all failure rate estimations. Often by the time the failure rate data are available, the devices under study have become obsolete. Due to this drawback, failure-rate prediction methods have been developed. These methods may be used on newly-designed devices to predict the device's failure rates and failure modes. Two approaches have become well known, Cycle Testing and FMEDA.
- Life Testing
- The most accurate source of data is to test samples of the actual devices or systems in order to generate failure data. This is often prohibitively expensive or impractical, so that the previous data sources are often used instead.
- Cycle Testing
- Mechanical movement is the predominant failure mechanism causing mechanical and electromechanical devices to wear out. For many devices, the wear-out failure point is measured by the number of cycles performed before the device fails, and can be discovered by cycle testing. In cycle testing, a device is cycled as rapidly as practical until it fails. When a collection of these devices are tested, the test will run until 10% of the units fail dangerously.
- FMEDA
- Failure modes, effects, and diagnostic analysis (FMEDA) is a systematic analysis technique to obtain subsystem / product level failure rates, failure modes and design strength. The FMEDA technique considers:
- All components of a design,
- The functionality of each component,
- The failure modes of each component,
- The effect of each component failure mode on the product functionality,
- The ability of any automatic diagnostics to detect the failure,
- The design strength (de-rating, safety factors) and
- The operational profile (environmental stress factors).
Given a component database calibrated with field failure data that is reasonably accurate[1] , the method can predict product level failure rate and failure mode data for a given application. The predictions have been shown to be more accurate[2] than field warranty return analysis or even typical field failure analysis given that these methods depend on reports that typically do not have sufficient detail information in failure records.[3]
Failure rate in the discrete sense
The failure rate can be defined as the following:
- The total number of failures within an item population, divided by the total time expended by that population, during a particular measurement interval under stated conditions. (MacDiarmid, et al.)
Although the failure rate, , is often thought of as the probability that a failure occurs in a specified interval given no failure before time , it is not actually a probability because it can exceed 1. Erroneous expression of the failure rate in % could result in incorrect perception of the measure, especially if it would be measured from repairable systems and multiple systems with non-constant failure rates or different operation times. It can be defined with the aid of the reliability function, also called the survival function, , the probability of no failure before time .



- , where is the time to (first) failure distribution (i.e. the failure density function).



over a time interval = from (or ) to . Note that this is a conditional probability, where the condition is that no failure has occurred before time . Hence the in the denominator.





Hazard rate and ROCOF (rate of occurrence of failures) are often incorrectly seen as the same and equal to the failure rate. To clarify; the more promptly items are repaired, the sooner they will break again, so the higher the ROCOF. The hazard rate is however independent of the time to repair and of the logistic delay time.
Failure rate in the continuous sense


Calculating the failure rate for ever smaller intervals of time results in the hazard function (also called hazard rate), . This becomes the instantaneous failure rate or we say instantaneous hazard rate as approaches to zero:

A continuous failure rate depends on the existence of a failure distribution, , which is a cumulative distribution function that describes the probability of failure (at least) up to and including time t,


where is the failure time. The failure distribution function is the integral of the failure density function, f(t),


The hazard function can be defined now as

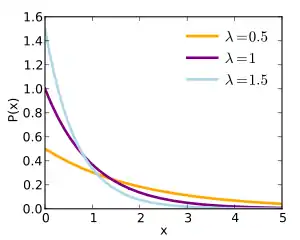
Many probability distributions can be used to model the failure distribution (see List of important probability distributions). A common model is the exponential failure distribution,

which is based on the exponential density function. The hazard rate function for this is:

Thus, for an exponential failure distribution, the hazard rate is a constant with respect to time (that is, the distribution is "memory-less"). For other distributions, such as a Weibull distribution or a log-normal distribution, the hazard function may not be constant with respect to time. For some such as the deterministic distribution it is monotonic increasing (analogous to "wearing out"), for others such as the Pareto distribution it is monotonic decreasing (analogous to "burning in"), while for many it is not monotonic.
Solving the differential equation

for , it can be shown that

Decreasing failure rate
A decreasing failure rate (DFR) describes a phenomenon where the probability of an event in a fixed time interval in the future decreases over time. A decreasing failure rate can describe a period of "infant mortality" where earlier failures are eliminated or corrected[4] and corresponds to the situation where λ(t) is a decreasing function.
Mixtures of DFR variables are DFR.[5] Mixtures of exponentially distributed random variables are hyperexponentially distributed.
Renewal processes
For a renewal process with DFR renewal function, inter-renewal times are concave.[5][6] Brown conjectured the converse, that DFR is also necessary for the inter-renewal times to be concave,[7] however it has been shown that this conjecture holds neither in the discrete case[6] nor in the continuous case.[8]
Applications
Increasing failure rate is an intuitive concept caused by components wearing out. Decreasing failure rate describes a system which improves with age.[9] Decreasing failure rates have been found in the lifetimes of spacecraft, Baker and Baker commenting that "those spacecraft that last, last on and on."[10][11] The reliability of aircraft air conditioning systems were individually found to have an exponential distribution, and thus in the pooled population a DFR.[9]
Coefficient of variation
When the failure rate is decreasing the coefficient of variation is ⩾ 1, and when the failure rate is increasing the coefficient of variation is ⩽ 1.[12] Note that this result only holds when the failure rate is defined for all t ⩾ 0[13] and that the converse result (coefficient of variation determining nature of failure rate) does not hold.
Units
Failure rates can be expressed using any measure of time, but hours is the most common unit in practice. Other units, such as miles, revolutions, etc., can also be used in place of "time" units.
Failure rates are often expressed in engineering notation as failures per million, or 10−6, especially for individual components, since their failure rates are often very low.
The Failures In Time (FIT) rate of a device is the number of failures that can be expected in one billion (109) device-hours of operation.[14] (E.g. 1000 devices for 1 million hours, or 1 million devices for 1000 hours each, or some other combination.) This term is used particularly by the semiconductor industry.
The relationship of FIT to MTBF may be expressed as: MTBF = 1,000,000,000 x 1/FIT.
Additivity
Under certain engineering assumptions (e.g. besides the above assumptions for a constant failure rate, the assumption that the considered system has no relevant redundancies), the failure rate for a complex system is simply the sum of the individual failure rates of its components, as long as the units are consistent, e.g. failures per million hours. This permits testing of individual components or subsystems, whose failure rates are then added to obtain the total system failure rate.[15][16]
Adding "redundant" components to eliminate a single point of failure improves the mission failure rate, but makes the series failure rate (also called the logistics failure rate) worse—the extra components improve the mean time between critical failures (MTBCF), even though the mean time before something fails is worse.[17]
Example
Suppose it is desired to estimate the failure rate of a certain component. A test can be performed to estimate its failure rate. Ten identical components are each tested until they either fail or reach 1000 hours, at which time the test is terminated for that component. (The level of statistical confidence is not considered in this example.) The results are as follows:
Estimated failure rate is

or 799.8 failures for every million hours of operation.
See also
- Annualized failure rate
- Burn-in
- Failure
- Failure mode
- Failure modes, effects, and diagnostic analysis
- Force of mortality
- Frequency of exceedance
- Reliability engineering
- Reliability theory
- Reliability theory of aging and longevity
- Survival analysis
- Weibull distribution
References
- Electrical & Mechanical Component Reliability Handbook. exida. 2006.
- Goble, William M.; Iwan van Beurden (2014). Combining field failure data with new instrument design margins to predict failure rates for SIS Verification. Proceedings of the 2014 International Symposium - BEYOND REGULATORY COMPLIANCE, MAKING SAFETY SECOND NATURE, Hilton College Station-Conference Center, College Station, Texas.
- W. M. Goble, "Field Failure Data – the Good, the Bad and the Ugly," exida, Sellersville, PA
- Finkelstein, Maxim (2008). "Introduction". Failure Rate Modelling for Reliability and Risk. Springer Series in Reliability Engineering. pp. 1–84. doi:10.1007/978-1-84800-986-8_1. ISBN 978-1-84800-985-1.
- Brown, M. (1980). "Bounds, Inequalities, and Monotonicity Properties for Some Specialized Renewal Processes". The Annals of Probability. 8 (2): 227–240. doi:10.1214/aop/1176994773. JSTOR 2243267.
- Shanthikumar, J. G. (1988). "DFR Property of First-Passage Times and its Preservation Under Geometric Compounding". The Annals of Probability. 16 (1): 397–406. doi:10.1214/aop/1176991910. JSTOR 2243910.
- Brown, M. (1981). "Further Monotonicity Properties for Specialized Renewal Processes". The Annals of Probability. 9 (5): 891–895. doi:10.1214/aop/1176994317. JSTOR 2243747.
- Yu, Y. (2011). "Concave renewal functions do not imply DFR interrenewal times". Journal of Applied Probability. 48 (2): 583–588. arXiv:1009.2463. doi:10.1239/jap/1308662647. S2CID 26570923.
- Proschan, F. (1963). "Theoretical Explanation of Observed Decreasing Failure Rate". Technometrics. 5 (3): 375–383. doi:10.1080/00401706.1963.10490105. JSTOR 1266340.
- Baker, J. C.; Baker, G. A. S. . (1980). "Impact of the space environment on spacecraft lifetimes". Journal of Spacecraft and Rockets. 17 (5): 479. Bibcode:1980JSpRo..17..479B. doi:10.2514/3.28040.
- Saleh, Joseph Homer; Castet, Jean-François (2011). "On Time, Reliability, and Spacecraft". Spacecraft Reliability and Multi-State Failures. p. 1. doi:10.1002/9781119994077.ch1. ISBN 9781119994077.
- Wierman, A.; Bansal, N.; Harchol-Balter, M. (2004). "A note on comparing response times in the M/GI/1/FB and M/GI/1/PS queues" (PDF). Operations Research Letters. 32: 73–76. doi:10.1016/S0167-6377(03)00061-0.
- Gautam, Natarajan (2012). Analysis of Queues: Methods and Applications. CRC Press. p. 703. ISBN 978-1439806586.
- Xin Li; Michael C. Huang; Kai Shen; Lingkun Chu. "A Realistic Evaluation of Memory Hardware Errors and Software System Susceptibility". 2010. p. 6.
- "Reliability Basics". 2010.
- Vita Faraci. "Calculating Failure Rates of Series/Parallel Networks". 2006.
- "Mission Reliability and Logistics Reliability: A Design Paradox".
Further reading
- Goble, William M. (2018), Safety Instrumented System Design: Techniques and Design Verification, Research Triangle Park, NC 27709: International Society of Automation
{{citation}}: CS1 maint: location (link) - Blanchard, Benjamin S. (1992). Logistics Engineering and Management (Fourth ed.). Englewood Cliffs, New Jersey: Prentice-Hall. pp. 26–32. ISBN 0135241170.
- Ebeling, Charles E. (1997). An Introduction to Reliability and Maintainability Engineering. Boston: McGraw-Hill. pp. 23–32. ISBN 0070188521.
- Federal Standard 1037C
- Kapur, K. C.; Lamberson, L. R. (1977). Reliability in Engineering Design. New York: John Wiley & Sons. pp. 8–30. ISBN 0471511919.
- Knowles, D. I. (1995). "Should We Move Away From 'Acceptable Failure Rate'?". Communications in Reliability Maintainability and Supportability. International RMS Committee, USA. 2 (1): 23.
- MacDiarmid, Preston; Morris, Seymour; et al. (n.d.). Reliability Toolkit (Commercial Practices ed.). Rome, New York: Reliability Analysis Center and Rome Laboratory. pp. 35–39.
- Modarres, M.; Kaminskiy, M.; Krivtsov, V. (2010). Reliability Engineering and Risk Analysis: A Practical Guide (2nd ed.). CRC Press. ISBN 9780849392474.
- Mondro, Mitchell J. (June 2002). "Approximation of Mean Time Between Failure When a System has Periodic Maintenance" (PDF). IEEE Transactions on Reliability. 51 (2): 166–167. doi:10.1109/TR.2002.1011521.
- Rausand, M.; Hoyland, A. (2004). System Reliability Theory; Models, Statistical methods, and Applications. New York: John Wiley & Sons. ISBN 047147133X.
- Turner, T.; Hockley, C.; Burdaky, R. (1997). The Customer Needs A Maintenance-Free Operating Period. 1997 Avionics Conference and Exhibition, No. 97-0819, P. 2.2. Leatherhead, Surrey, UK: ERA Technology Ltd.
- U.S. Department of Defense, (1991) Military Handbook, “Reliability Prediction of Electronic Equipment, MIL-HDBK-217F, 2
External links
- Bathtub curve issues, ASQC
- Fault Tolerant Computing in Industrial Automation by Hubert Kirrmann, ABB Research Center, Switzerland
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||