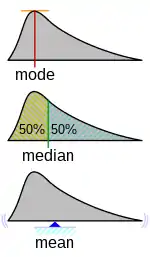
Median
In statistics and probability theory, the median is the value separating the higher half from the lower half of a data sample, a population, or a probability distribution. For a data set, it may be thought of as "the middle" value. The basic feature of the median in describing data compared to the mean (often simply described as the "average") is that it is not skewed by a small proportion of extremely large or small values, and therefore provides a better representation of a "typical" value. Median income, for example, may be a better way to suggest what a "typical" income is, because income distribution can be very skewed. The median is of central importance in robust statistics, as it is the most resistant statistic, having a breakdown point of 50%: so long as no more than half the data are contaminated, the median is not an arbitrarily large or small result.

Finite data set of numbers
The median of a finite list of numbers is the "middle" number, when those numbers are listed in order from smallest to greatest.
If the data set has an odd number of observations, the middle one is selected. For example, the following list of seven numbers,
- 1, 3, 3, 6, 7, 8, 9
has the median of 6, which is the fourth value.
If the data set has an even number of observations, there is no distinct middle value and the median is usually defined to be the arithmetic mean of the two middle values.[1][2] For example, this data set of 8 numbers
- 1, 2, 3, 4, 5, 6, 8, 9
has a median value of 4.5, that is . (In more technical terms, this interprets the median as the fully trimmed mid-range).

In general, with this convention, the median can be defined as follows: For a data set of elements, ordered from smallest to greatest,


- if is odd,
- if is even,


| Type | Description | Example | Result |
|---|---|---|---|
| Midrange | Midway point between the minimum and the maximum of a data set | 1, 2, 2, 3, 4, 7, 9 | 5 |
| Arithmetic mean | Sum of values of a data set divided by number of values: | (1 + 2 + 2 + 3 + 4 + 7 + 9) / 7 | 4 |
| Median | Middle value separating the greater and lesser halves of a data set | 1, 2, 2, 3, 4, 7, 9 | 3 |
| Mode | Most frequent value in a data set | 1, 2, 2, 3, 4, 7, 9 | 2 |

Formal definition
Formally, a median of a population is any value such that at least half of the population is less than or equal to the proposed median and at least half is greater than or equal to the proposed median. As seen above, medians may not be unique. If each set contains less than half the population, then some of the population is exactly equal to the unique median.
The median is well-defined for any ordered (one-dimensional) data, and is independent of any distance metric. The median can thus be applied to classes which are ranked but not numerical (e.g. working out a median grade when students are graded from A to F), although the result might be halfway between classes if there is an even number of cases.
A geometric median, on the other hand, is defined in any number of dimensions. A related concept, in which the outcome is forced to correspond to a member of the sample, is the medoid.
There is no widely accepted standard notation for the median, but some authors represent the median of a variable x either as x͂ or as μ1/2[1] sometimes also M.[3][4] In any of these cases, the use of these or other symbols for the median needs to be explicitly defined when they are introduced.
The median is a special case of other ways of summarizing the typical values associated with a statistical distribution: it is the 2nd quartile, 5th decile, and 50th percentile.
Uses
The median can be used as a measure of location when one attaches reduced importance to extreme values, typically because a distribution is skewed, extreme values are not known, or outliers are untrustworthy, i.e., may be measurement/transcription errors.
For example, consider the multiset
- 1, 2, 2, 2, 3, 14.
The median is 2 in this case, as is the mode, and it might be seen as a better indication of the center than the arithmetic mean of 4, which is larger than all but one of the values. However, the widely cited empirical relationship that the mean is shifted "further into the tail" of a distribution than the median is not generally true. At most, one can say that the two statistics cannot be "too far" apart; see § Inequality relating means and medians below.[5]
As a median is based on the middle data in a set, it is not necessary to know the value of extreme results in order to calculate it. For example, in a psychology test investigating the time needed to solve a problem, if a small number of people failed to solve the problem at all in the given time a median can still be calculated.[6]
Because the median is simple to understand and easy to calculate, while also a robust approximation to the mean, the median is a popular summary statistic in descriptive statistics. In this context, there are several choices for a measure of variability: the range, the interquartile range, the mean absolute deviation, and the median absolute deviation.
For practical purposes, different measures of location and dispersion are often compared on the basis of how well the corresponding population values can be estimated from a sample of data. The median, estimated using the sample median, has good properties in this regard. While it is not usually optimal if a given population distribution is assumed, its properties are always reasonably good. For example, a comparison of the efficiency of candidate estimators shows that the sample mean is more statistically efficient when — and only when — data is uncontaminated by data from heavy-tailed distributions or from mixtures of distributions. Even then, the median has a 64% efficiency compared to the minimum-variance mean (for large normal samples), which is to say the variance of the median will be ~50% greater than the variance of the mean.[7][8]
Probability distributions
For any real-valued probability distribution with cumulative distribution function F, a median is defined as any real number m that satisfies the inequalities

An equivalent phrasing uses a random variable X distributed according to F:

Note that this definition does not require X to have an absolutely continuous distribution (which has a probability density function f), nor does it require a discrete one. In the former case, the inequalities can be upgraded to equality: a median satisfies

Any probability distribution on R has at least one median, but in pathological cases there may be more than one median: if F is constant 1/2 on an interval (so that f=0 there), then any value of that interval is a median.
Medians of particular distributions
The medians of certain types of distributions can be easily calculated from their parameters; furthermore, they exist even for some distributions lacking a well-defined mean, such as the Cauchy distribution:
- The median of a symmetric unimodal distribution coincides with the mode.
- The median of a symmetric distribution which possesses a mean μ also takes the value μ.
- The median of a normal distribution with mean μ and variance σ2 is μ. In fact, for a normal distribution, mean = median = mode.
- The median of a uniform distribution in the interval [a, b] is (a + b) / 2, which is also the mean.
- The median of a Cauchy distribution with location parameter x0 and scale parameter y is x0, the location parameter.
- The median of a power law distribution x−a, with exponent a > 1 is 21/(a − 1)xmin, where xmin is the minimum value for which the power law holds[10]
- The median of an exponential distribution with rate parameter λ is the natural logarithm of 2 divided by the rate parameter: λ−1ln 2.
- The median of a Weibull distribution with shape parameter k and scale parameter λ is λ(ln 2)1/k.
Properties
Optimality property
The mean absolute error of a real variable c with respect to the random variable X is

Provided that the probability distribution of X is such that the above expectation exists, then m is a median of X if and only if m is a minimizer of the mean absolute error with respect to X.[11] In particular, m is a sample median if and only if m minimizes the arithmetic mean of the absolute deviations.[12]
More generally, a median is defined as a minimum of

as discussed below in the section on multivariate medians (specifically, the spatial median).
This optimization-based definition of the median is useful in statistical data-analysis, for example, in k-medians clustering.
Inequality relating means and medians

If the distribution has finite variance, then the distance between the median and the mean is bounded by one standard deviation.


This bound was proved by Book and Sher in 1979 for discrete samples,[13] and more generally by Page and Murty in 1982.[14] In a comment on a subsequent proof by O'Cinneide,[15] Mallows in 1991 presented a compact proof that uses Jensen's inequality twice,[16] as follows. Using |·| for the absolute value, we have

The first and third inequalities come from Jensen's inequality applied to the absolute-value function and the square function, which are each convex. The second inequality comes from the fact that a median minimizes the absolute deviation function .

Mallows' proof can be generalized to obtain a multivariate version of the inequality[17] simply by replacing the absolute value with a norm:

where m is a spatial median, that is, a minimizer of the function The spatial median is unique when the data-set's dimension is two or more.[18][19]

An alternative proof uses the one-sided Chebyshev inequality; it appears in an inequality on location and scale parameters. This formula also follows directly from Cantelli's inequality.[20]
Unimodal distributions
For the case of unimodal distributions, one can achieve a sharper bound on the distance between the median and the mean:
- .[21]

A similar relation holds between the median and the mode:

if n is odd, {\displaystyle \mathrm {median} (x)=x_{(n+1)/2}} if n is even, {\displaystyle \mathrm {median} (x)={\frac {x_{(n/2)}+x_{((n/2)+1)}}{2}}}
Jensen's inequality for medians
Jensen's inequality states that for any random variable X with a finite expectation E[X] and for any convex function f

This inequality generalizes to the median as well. We say a function f: R → R is a C function if, for any t,

is a closed interval (allowing the degenerate cases of a single point or an empty set). Every convex function is a C function, but the reverse does not hold. If f is a C function, then

If the medians are not unique, the statement holds for the corresponding suprema.[22]
Medians for samples
Efficient computation of the sample median
Even though comparison-sorting n items requires Ω(n log n) operations, selection algorithms can compute the kth-smallest of n items with only Θ(n) operations. This includes the median, which is the n/2th order statistic (or for an even number of samples, the arithmetic mean of the two middle order statistics).[23]
Selection algorithms still have the downside of requiring Ω(n) memory, that is, they need to have the full sample (or a linear-sized portion of it) in memory. Because this, as well as the linear time requirement, can be prohibitive, several estimation procedures for the median have been developed. A simple one is the median of three rule, which estimates the median as the median of a three-element subsample; this is commonly used as a subroutine in the quicksort sorting algorithm, which uses an estimate of its input's median. A more robust estimator is Tukey's ninther, which is the median of three rule applied with limited recursion:[24] if A is the sample laid out as an array, and
- med3(A) = median(A[1], A[n/2], A[n]),
then
- ninther(A) = med3(med3(A[1 ... 1/3n]), med3(A[1/3n ... 2/3n]), med3(A[2/3n ... n]))
The remedian is an estimator for the median that requires linear time but sub-linear memory, operating in a single pass over the sample.[25]
Sampling distribution
The distributions of both the sample mean and the sample median were determined by Laplace.[26] The distribution of the sample median from a population with a density function is asymptotically normal with mean and variance[27]



where is the median of and is the sample size. A modern proof follows below. Laplace's result is now understood as a special case of the asymptotic distribution of arbitrary quantiles.
For normal samples, the density is , thus for large samples the variance of the median equals [7] (See also section #Efficiency below.)


Derivation of the asymptotic distribution
We take the sample size to be an odd number and assume our variable continuous; the formula for the case of discrete variables is given below in § Empirical local density. The sample can be summarized as "below median", "at median", and "above median", which corresponds to a trinomial distribution with probabilities , and . For a continuous variable, the probability of multiple sample values being exactly equal to the median is 0, so one can calculate the density of at the point directly from the trinomial distribution:





- .

Now we introduce the beta function. For integer arguments and , this can be expressed as . Also, recall that . Using these relationships and setting both and equal to allows the last expression to be written as






Hence the density function of the median is a symmetric beta distribution pushed forward by . Its mean, as we would expect, is 0.5 and its variance is . By the chain rule, the corresponding variance of the sample median is


- .

The additional 2 is negligible in the limit.
Empirical local density
In practice, the functions and are often not known or assumed. However, they can be estimated from an observed frequency distribution. In this section, we give an example. Consider the following table, representing a sample of 3,800 (discrete-valued) observations:

| v | 0 | 0.5 | 1 | 1.5 | 2 | 2.5 | 3 | 3.5 | 4 | 4.5 | 5 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| f(v) | 0.000 | 0.008 | 0.010 | 0.013 | 0.083 | 0.108 | 0.328 | 0.220 | 0.202 | 0.023 | 0.005 |
| F(v) | 0.000 | 0.008 | 0.018 | 0.031 | 0.114 | 0.222 | 0.550 | 0.770 | 0.972 | 0.995 | 1.000 |
Because the observations are discrete-valued, constructing the exact distribution of the median is not an immediate translation of the above expression for ; one may (and typically does) have multiple instances of the median in one's sample. So we must sum over all these possibilities:


Here, i is the number of points strictly less than the median and k the number strictly greater.
Using these preliminaries, it is possible to investigate the effect of sample size on the standard errors of the mean and median. The observed mean is 3.16, the observed raw median is 3 and the observed interpolated median is 3.174. The following table gives some comparison statistics.
Sample size Statistic | 3 | 9 | 15 | 21 |
|---|---|---|---|---|
| Expected value of median | 3.198 | 3.191 | 3.174 | 3.161 |
| Standard error of median (above formula) | 0.482 | 0.305 | 0.257 | 0.239 |
| Standard error of median (asymptotic approximation) | 0.879 | 0.508 | 0.393 | 0.332 |
| Standard error of mean | 0.421 | 0.243 | 0.188 | 0.159 |
The expected value of the median falls slightly as sample size increases while, as would be expected, the standard errors of both the median and the mean are proportionate to the inverse square root of the sample size. The asymptotic approximation errs on the side of caution by overestimating the standard error.
Estimation of variance from sample data
The value of —the asymptotic value of where is the population median—has been studied by several authors. The standard "delete one" jackknife method produces inconsistent results.[28] An alternative—the "delete k" method—where grows with the sample size has been shown to be asymptotically consistent.[29] This method may be computationally expensive for large data sets. A bootstrap estimate is known to be consistent,[30] but converges very slowly (order of ).[31] Other methods have been proposed but their behavior may differ between large and small samples.[32]





Efficiency
The efficiency of the sample median, measured as the ratio of the variance of the mean to the variance of the median, depends on the sample size and on the underlying population distribution. For a sample of size from the normal distribution, the efficiency for large N is

The efficiency tends to as tends to infinity.


In other words, the relative variance of the median will be , or 57% greater than the variance of the mean – the relative standard error of the median will be , or 25% greater than the standard error of the mean, (see also section #Sampling distribution above.).[33]



Other estimators
For univariate distributions that are symmetric about one median, the Hodges–Lehmann estimator is a robust and highly efficient estimator of the population median.[34]
If data is represented by a statistical model specifying a particular family of probability distributions, then estimates of the median can be obtained by fitting that family of probability distributions to the data and calculating the theoretical median of the fitted distribution. Pareto interpolation is an application of this when the population is assumed to have a Pareto distribution.
Multivariate median
Previously, this article discussed the univariate median, when the sample or population had one-dimension. When the dimension is two or higher, there are multiple concepts that extend the definition of the univariate median; each such multivariate median agrees with the univariate median when the dimension is exactly one.[34][35][36][37]
Marginal median
The marginal median is defined for vectors defined with respect to a fixed set of coordinates. A marginal median is defined to be the vector whose components are univariate medians. The marginal median is easy to compute, and its properties were studied by Puri and Sen.[34][38]
Geometric median
The geometric median of a discrete set of sample points in a Euclidean space is the[lower-alpha 1] point minimizing the sum of distances to the sample points.


In contrast to the marginal median, the geometric median is equivariant with respect to Euclidean similarity transformations such as translations and rotations.
Median in all directions
If the marginal medians for all coordinate systems coincide, then their common location may be termed the "median in all directions".[40] This concept is relevant to voting theory on account of the median voter theorem. When it exists, the median in all directions coincides with the geometric median (at least for discrete distributions).
Centerpoint
An alternative generalization of the median in higher dimensions is the centerpoint.
Other median-related concepts
Interpolated median
When dealing with a discrete variable, it is sometimes useful to regard the observed values as being midpoints of underlying continuous intervals. An example of this is a Likert scale, on which opinions or preferences are expressed on a scale with a set number of possible responses. If the scale consists of the positive integers, an observation of 3 might be regarded as representing the interval from 2.50 to 3.50. It is possible to estimate the median of the underlying variable. If, say, 22% of the observations are of value 2 or below and 55.0% are of 3 or below (so 33% have the value 3), then the median is 3 since the median is the smallest value of for which is greater than a half. But the interpolated median is somewhere between 2.50 and 3.50. First we add half of the interval width to the median to get the upper bound of the median interval. Then we subtract that proportion of the interval width which equals the proportion of the 33% which lies above the 50% mark. In other words, we split up the interval width pro rata to the numbers of observations. In this case, the 33% is split into 28% below the median and 5% above it so we subtract 5/33 of the interval width from the upper bound of 3.50 to give an interpolated median of 3.35. More formally, if the values are known, the interpolated median can be calculated from



Alternatively, if in an observed sample there are scores above the median category, scores in it and scores below it then the interpolated median is given by



Pseudo-median
For univariate distributions that are symmetric about one median, the Hodges–Lehmann estimator is a robust and highly efficient estimator of the population median; for non-symmetric distributions, the Hodges–Lehmann estimator is a robust and highly efficient estimator of the population pseudo-median, which is the median of a symmetrized distribution and which is close to the population median.[41] The Hodges–Lehmann estimator has been generalized to multivariate distributions.[42]
Variants of regression
The Theil–Sen estimator is a method for robust linear regression based on finding medians of slopes.[43]
Median filter
The median filter is an important tool of image processing, that can effectively remove any salt and pepper noise from grayscale images.
Cluster analysis
In cluster analysis, the k-medians clustering algorithm provides a way of defining clusters, in which the criterion of maximising the distance between cluster-means that is used in k-means clustering, is replaced by maximising the distance between cluster-medians.
Median–median line
This is a method of robust regression. The idea dates back to Wald in 1940 who suggested dividing a set of bivariate data into two halves depending on the value of the independent parameter : a left half with values less than the median and a right half with values greater than the median.[44] He suggested taking the means of the dependent and independent variables of the left and the right halves and estimating the slope of the line joining these two points. The line could then be adjusted to fit the majority of the points in the data set.

Nair and Shrivastava in 1942 suggested a similar idea but instead advocated dividing the sample into three equal parts before calculating the means of the subsamples.[45] Brown and Mood in 1951 proposed the idea of using the medians of two subsamples rather the means.[46] Tukey combined these ideas and recommended dividing the sample into three equal size subsamples and estimating the line based on the medians of the subsamples.[47]
Median-unbiased estimators
Any mean-unbiased estimator minimizes the risk (expected loss) with respect to the squared-error loss function, as observed by Gauss. A median-unbiased estimator minimizes the risk with respect to the absolute-deviation loss function, as observed by Laplace. Other loss functions are used in statistical theory, particularly in robust statistics.
The theory of median-unbiased estimators was revived by George W. Brown in 1947:[48]
An estimate of a one-dimensional parameter θ will be said to be median-unbiased if, for fixed θ, the median of the distribution of the estimate is at the value θ; i.e., the estimate underestimates just as often as it overestimates. This requirement seems for most purposes to accomplish as much as the mean-unbiased requirement and has the additional property that it is invariant under one-to-one transformation.
— page 584
Further properties of median-unbiased estimators have been reported.[49][50][51][52] Median-unbiased estimators are invariant under one-to-one transformations.
There are methods of constructing median-unbiased estimators that are optimal (in a sense analogous to the minimum-variance property for mean-unbiased estimators). Such constructions exist for probability distributions having monotone likelihood-functions.[53][54] One such procedure is an analogue of the Rao–Blackwell procedure for mean-unbiased estimators: The procedure holds for a smaller class of probability distributions than does the Rao—Blackwell procedure but for a larger class of loss functions.[55]
History
Scientific researchers in the ancient near east appear not to have used summary statistics altogether, instead choosing values that offered maximal consistency with a broader theory that integrated a wide variety of phenomena.[56] Within the Mediterranean (and, later, European) scholarly community, statistics like the mean are fundamentally a medieval and early modern development. (The history of the median outside Europe and its predecessors remains relatively unstudied.)
The idea of the median appeared in the 6th century in the Talmud, in order to fairly analyze divergent appraisals.[57][58] However, the concept did not spread to the broader scientific community.
Instead, the closest ancestor of the modern median is the mid-range, invented by Al-Biruni.[59]: 31 [60] Transmission of Al-Biruni's work to later scholars is unclear. Al-Biruni applied his technique to assaying metals, but, after he published his work, most assayers still adopted the most unfavorable value from their results, lest they appear to cheat.[59]: 35–8 However, increased navigation at sea during the Age of Discovery meant that ship's navigators increasingly had to attempt to determine latitude in unfavorable weather against hostile shores, leading to renewed interest in summary statistics. Whether rediscovered or independently invented, the mid-range is recommended to nautical navigators in Harriot's "Instructions for Raleigh's Voyage to Guiana, 1595".[59]: 45–8
The idea of the median may have first appeared in Edward Wright's 1599 book Certaine Errors in Navigation on a section about compass navigation. Wright was reluctant to discard measured values, and may have felt that the median — incorporating a greater proportion of the dataset than the mid-range — was more likely to be correct. However, Wright did not give examples of his technique's use, making it hard to verify that he described the modern notion of median.[56][60][lower-alpha 2] The median (in the context of probability) certainly appeared in the correspondence of Christiaan Huygens, but as an example of a statistic that was inappropriate for actuarial practice.[56]
The earliest recommendation of the median dates to 1757, when Roger Joseph Boscovich developed a regression method based on the L1 norm and therefore implicitly on the median.[56][61] In 1774, Laplace made this desire explicit: he suggested the median be used as the standard estimator of the value of a posterior PDF. The specific criterion was to minimize the expected magnitude of the error; where is the estimate and is the true value. To this end, Laplace determined the distributions of both the sample mean and the sample median in the early 1800s.[26][62] However, a decade later, Gauss and Legendre developed the least squares method, which minimizes to obtain the mean. Within the context of regression, Gauss and Legendre's innovation offers vastly easier computation. Consequently, Laplaces' proposal was generally rejected until the rise of computing devices 150 years later (and is still a relatively uncommon algorithm).[63]



Antoine Augustin Cournot in 1843 was the first[64] to use the term median (valeur médiane) for the value that divides a probability distribution into two equal halves. Gustav Theodor Fechner used the median (Centralwerth) in sociological and psychological phenomena.[65] It had earlier been used only in astronomy and related fields. Gustav Fechner popularized the median into the formal analysis of data, although it had been used previously by Laplace,[65] and the median appeared in a textbook by F. Y. Edgeworth.[66] Francis Galton used the English term median in 1881,[67][68] having earlier used the terms middle-most value in 1869, and the medium in 1880.[69][70]
Statisticians encouraged the use of medians intensely throughout the 19th century for its intuitive clarity and ease of manual computation. However, the notion of median does not lend itself to the theory of higher moments as well as the arithmetic mean does, and is much harder to compute by computer. As a result, the median was steadily supplanted as a notion of generic average by the arithmetic mean during the 20th century.[56][60]
See also
- Absolute deviation
- Bias of an estimator
- Central tendency
- Concentration of measure for Lipschitz functions
- Median graph
- Median of medians – Algorithm to calculate the approximate median in linear time
- Median search
- Median slope
- Median voter theory
- Medoids – Generalization of the median in higher dimensions
Notes
References
- Weisstein, Eric W. "Statistical Median". MathWorld.
- Simon, Laura J.; "Descriptive statistics" Archived 2010-07-30 at the Wayback Machine, Statistical Education Resource Kit, Pennsylvania State Department of Statistics
- David J. Sheskin (27 August 2003). Handbook of Parametric and Nonparametric Statistical Procedures (Third ed.). CRC Press. pp. 7–. ISBN 978-1-4200-3626-8. Retrieved 25 February 2013.
- Derek Bissell (1994). Statistical Methods for Spc and Tqm. CRC Press. pp. 26–. ISBN 978-0-412-39440-9. Retrieved 25 February 2013.
- Paul T. von Hippel (2005). "Mean, Median, and Skew: Correcting a Textbook Rule". Journal of Statistics Education. 13 (2). Archived from the original on 2008-10-14. Retrieved 2015-06-18.
- Robson, Colin (1994). Experiment, Design and Statistics in Psychology. Penguin. pp. 42–45. ISBN 0-14-017648-9.
- Williams, D. (2001). Weighing the Odds. Cambridge University Press. p. 165. ISBN 052100618X.
- Maindonald, John; Braun, W. John (2010-05-06). Data Analysis and Graphics Using R: An Example-Based Approach. Cambridge University Press. p. 104. ISBN 978-1-139-48667-5.
- "AP Statistics Review - Density Curves and the Normal Distributions". Archived from the original on 8 April 2015. Retrieved 16 March 2015.
- Newman, Mark EJ. "Power laws, Pareto distributions and Zipf's law." Contemporary physics 46.5 (2005): 323–351.
- Stroock, Daniel (2011). Probability Theory. Cambridge University Press. pp. 43. ISBN 978-0-521-13250-3.
- André Nicolas (https://math.stackexchange.com/users/6312/andr%c3%a9-nicolas), The Median Minimizes the Sum of Absolute Deviations (The $ {L}_{1} $ Norm), URL (version: 2012-02-25): https://math.stackexchange.com/q/113336
- Stephen A. Book; Lawrence Sher (1979). "How close are the mean and the median?". The Two-Year College Mathematics Journal. 10 (3): 202–204. doi:10.2307/3026748. JSTOR 3026748. Retrieved 12 March 2022.
- Warren Page; Vedula N. Murty (1982). "Nearness Relations Among Measures of Central Tendency and Dispersion: Part 1". The Two-Year College Mathematics Journal. 13 (5): 315–327. doi:10.1080/00494925.1982.11972639 (inactive 31 July 2022). Retrieved 12 March 2022.
{{cite journal}}: CS1 maint: DOI inactive as of July 2022 (link) - O'Cinneide, Colm Art (1990). "The mean is within one standard deviation of any median". The American Statistician. 44 (4): 292–293. doi:10.1080/00031305.1990.10475743. Retrieved 12 March 2022.
- Mallows, Colin (August 1991). "Another comment on O'Cinneide". The American Statistician. 45 (3): 257. doi:10.1080/00031305.1991.10475815.
- Piché, Robert (2012). Random Vectors and Random Sequences. Lambert Academic Publishing. ISBN 978-3659211966.
- Kemperman, Johannes H. B. (1987). Dodge, Yadolah (ed.). "The median of a finite measure on a Banach space: Statistical data analysis based on the L1-norm and related methods". Papers from the First International Conference Held at Neuchâtel, August 31–September 4, 1987. Amsterdam: North-Holland Publishing Co.: 217–230. MR 0949228.
- Milasevic, Philip; Ducharme, Gilles R. (1987). "Uniqueness of the spatial median". Annals of Statistics. 15 (3): 1332–1333. doi:10.1214/aos/1176350511. MR 0902264.
- K.Van Steen Notes on probability and statistics
- Basu, S.; Dasgupta, A. (1997). "The Mean, Median, and Mode of Unimodal Distributions:A Characterization". Theory of Probability and Its Applications. 41 (2): 210–223. doi:10.1137/S0040585X97975447. S2CID 54593178.
- Merkle, M. (2005). "Jensen's inequality for medians". Statistics & Probability Letters. 71 (3): 277–281. doi:10.1016/j.spl.2004.11.010.
- Alfred V. Aho and John E. Hopcroft and Jeffrey D. Ullman (1974). The Design and Analysis of Computer Algorithms. Reading/MA: Addison-Wesley. ISBN 0-201-00029-6. Here: Section 3.6 "Order Statistics", p.97-99, in particular Algorithm 3.6 and Theorem 3.9.
- Bentley, Jon L.; McIlroy, M. Douglas (1993). "Engineering a sort function". Software: Practice and Experience. 23 (11): 1249–1265. doi:10.1002/spe.4380231105. S2CID 8822797.
- Rousseeuw, Peter J.; Bassett, Gilbert W. Jr. (1990). "The remedian: a robust averaging method for large data sets" (PDF). J. Amer. Statist. Assoc. 85 (409): 97–104. doi:10.1080/01621459.1990.10475311.
- Stigler, Stephen (December 1973). "Studies in the History of Probability and Statistics. XXXII: Laplace, Fisher and the Discovery of the Concept of Sufficiency". Biometrika. 60 (3): 439–445. doi:10.1093/biomet/60.3.439. JSTOR 2334992. MR 0326872.
- Rider, Paul R. (1960). "Variance of the median of small samples from several special populations". J. Amer. Statist. Assoc. 55 (289): 148–150. doi:10.1080/01621459.1960.10482056.
- Efron, B. (1982). The Jackknife, the Bootstrap and other Resampling Plans. Philadelphia: SIAM. ISBN 0898711797.
- Shao, J.; Wu, C. F. (1989). "A General Theory for Jackknife Variance Estimation". Ann. Stat. 17 (3): 1176–1197. doi:10.1214/aos/1176347263. JSTOR 2241717.
- Efron, B. (1979). "Bootstrap Methods: Another Look at the Jackknife". Ann. Stat. 7 (1): 1–26. doi:10.1214/aos/1176344552. JSTOR 2958830.
- Hall, P.; Martin, M. A. (1988). "Exact Convergence Rate of Bootstrap Quantile Variance Estimator". Probab Theory Related Fields. 80 (2): 261–268. doi:10.1007/BF00356105. S2CID 119701556.
- Jiménez-Gamero, M. D.; Munoz-García, J.; Pino-Mejías, R. (2004). "Reduced bootstrap for the median". Statistica Sinica. 14 (4): 1179–1198.
- Maindonald, John; John Braun, W. (2010-05-06). Data Analysis and Graphics Using R: An Example-Based Approach. ISBN 9781139486675.
- Hettmansperger, Thomas P.; McKean, Joseph W. (1998). Robust nonparametric statistical methods. Kendall's Library of Statistics. Vol. 5. London: Edward Arnold. ISBN 0-340-54937-8. MR 1604954.
- Small, Christopher G. "A survey of multidimensional medians." International Statistical Review/Revue Internationale de Statistique (1990): 263–277. doi:10.2307/1403809 JSTOR 1403809
- Niinimaa, A., and H. Oja. "Multivariate median." Encyclopedia of statistical sciences (1999).
- Mosler, Karl. Multivariate Dispersion, Central Regions, and Depth: The Lift Zonoid Approach. Vol. 165. Springer Science & Business Media, 2012.
- Puri, Madan L.; Sen, Pranab K.; Nonparametric Methods in Multivariate Analysis, John Wiley & Sons, New York, NY, 1971. (Reprinted by Krieger Publishing)
- Vardi, Yehuda; Zhang, Cun-Hui (2000). "The multivariate L1-median and associated data depth". Proceedings of the National Academy of Sciences of the United States of America. 97 (4): 1423–1426 (electronic). Bibcode:2000PNAS...97.1423V. doi:10.1073/pnas.97.4.1423. MR 1740461. PMC 26449. PMID 10677477.
- Davis, Otto A.; DeGroot, Morris H.; Hinich, Melvin J. (January 1972). "Social Preference Orderings and Majority Rule" (PDF). Econometrica. 40 (1): 147–157. doi:10.2307/1909727. JSTOR 1909727. The authors, working in a topic in which uniqueness is assumed, actually use the expression "unique median in all directions".
- Pratt, William K.; Cooper, Ted J.; Kabir, Ihtisham (1985-07-11). Corbett, Francis J (ed.). "Pseudomedian Filter". Architectures and Algorithms for Digital Image Processing II. 0534: 34. Bibcode:1985SPIE..534...34P. doi:10.1117/12.946562. S2CID 173183609.
- Oja, Hannu (2010). Multivariate nonparametric methods with R: An approach based on spatial signs and ranks. Lecture Notes in Statistics. Vol. 199. New York, NY: Springer. pp. xiv+232. doi:10.1007/978-1-4419-0468-3. ISBN 978-1-4419-0467-6. MR 2598854.
- Wilcox, Rand R. (2001), "Theil–Sen estimator", Fundamentals of Modern Statistical Methods: Substantially Improving Power and Accuracy, Springer-Verlag, pp. 207–210, ISBN 978-0-387-95157-7.
- Wald, A. (1940). "The Fitting of Straight Lines if Both Variables are Subject to Error" (PDF). Annals of Mathematical Statistics. 11 (3): 282–300. doi:10.1214/aoms/1177731868. JSTOR 2235677.
- Nair, K. R.; Shrivastava, M. P. (1942). "On a Simple Method of Curve Fitting". Sankhyā: The Indian Journal of Statistics. 6 (2): 121–132. JSTOR 25047749.
- Brown, G. W.; Mood, A. M. (1951). "On Median Tests for Linear Hypotheses". Proc Second Berkeley Symposium on Mathematical Statistics and Probability. Berkeley, CA: University of California Press. pp. 159–166. Zbl 0045.08606.
- Tukey, J. W. (1977). Exploratory Data Analysis. Reading, MA: Addison-Wesley. ISBN 0201076160.
- Brown, George W. (1947). "On Small-Sample Estimation". Annals of Mathematical Statistics. 18 (4): 582–585. doi:10.1214/aoms/1177730349. JSTOR 2236236.
- Lehmann, Erich L. (1951). "A General Concept of Unbiasedness". Annals of Mathematical Statistics. 22 (4): 587–592. doi:10.1214/aoms/1177729549. JSTOR 2236928.
- Birnbaum, Allan (1961). "A Unified Theory of Estimation, I". Annals of Mathematical Statistics. 32 (1): 112–135. doi:10.1214/aoms/1177705145. JSTOR 2237612.
- van der Vaart, H. Robert (1961). "Some Extensions of the Idea of Bias". Annals of Mathematical Statistics. 32 (2): 436–447. doi:10.1214/aoms/1177705051. JSTOR 2237754. MR 0125674.
- Pfanzagl, Johann; with the assistance of R. Hamböker (1994). Parametric Statistical Theory. Walter de Gruyter. ISBN 3-11-013863-8. MR 1291393.
- Pfanzagl, Johann. "On optimal median unbiased estimators in the presence of nuisance parameters." The Annals of Statistics (1979): 187–193.
- Brown, L. D.; Cohen, Arthur; Strawderman, W. E. (1976). "A Complete Class Theorem for Strict Monotone Likelihood Ratio With Applications". Ann. Statist. 4 (4): 712–722. doi:10.1214/aos/1176343543.
- Page; Brown, L. D.; Cohen, Arthur; Strawderman, W. E. (1976). "A Complete Class Theorem for Strict Monotone Likelihood Ratio With Applications". Ann. Statist. 4 (4): 712–722. doi:10.1214/aos/1176343543.
- Bakker, Arthur; Gravemeijer, Koeno P. E. (2006-06-01). "An Historical Phenomenology of Mean and Median". Educational Studies in Mathematics. 62 (2): 149–168. doi:10.1007/s10649-006-7099-8. ISSN 1573-0816. S2CID 143708116.
- Adler, Dan (31 December 2014). "Talmud and Modern Economics". Jewish American and Israeli Issues. Archived from the original on 6 December 2015. Retrieved 22 February 2020.
- Modern Economic Theory in the Talmud by Yisrael Aumann
- Eisenhart, Churchill (24 August 1971). The Development of the Concept of the Best Mean of a Set of Measurements from Antiquity to the Present Day (PDF) (Speech). 131st Annual Meeting of the American Statistical Association. Colorado State University.
- "How the Average Triumphed Over the Median". Priceonomics. 5 April 2016. Retrieved 2020-02-23.
- Stigler, S. M. (1986). The History of Statistics: The Measurement of Uncertainty Before 1900. Harvard University Press. ISBN 0674403401.
- Laplace PS de (1818) Deuxième supplément à la Théorie Analytique des Probabilités, Paris, Courcier
- Jaynes, E.T. (2007). Probability theory : the logic of science (5. print. ed.). Cambridge [u.a.]: Cambridge Univ. Press. p. 172. ISBN 978-0-521-59271-0.
- Howarth, Richard (2017). Dictionary of Mathematical Geosciences: With Historical Notes. Springer. p. 374.
- Keynes, J.M. (1921) A Treatise on Probability. Pt II Ch XVII §5 (p 201) (2006 reprint, Cosimo Classics, ISBN 9781596055308 : multiple other reprints)
- Stigler, Stephen M. (2002). Statistics on the Table: The History of Statistical Concepts and Methods. Harvard University Press. pp. 105–7. ISBN 978-0-674-00979-0.
- Galton F (1881) "Report of the Anthropometric Committee" pp 245–260. Report of the 51st Meeting of the British Association for the Advancement of Science
- David, H. A. (1995). "First (?) Occurrence of Common Terms in Mathematical Statistics". The American Statistician. 49 (2): 121–133. doi:10.2307/2684625. ISSN 0003-1305. JSTOR 2684625.
- encyclopediaofmath.org
- personal.psu.edu
External links
- "Median (in statistics)", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Median as a weighted arithmetic mean of all Sample Observations
- On-line calculator
- Calculating the median
- A problem involving the mean, the median, and the mode.
- Weisstein, Eric W. "Statistical Median". MathWorld.
- Python script for Median computations and income inequality metrics
- Fast Computation of the Median by Successive Binning
- 'Mean, median, mode and skewness', A tutorial devised for first-year psychology students at Oxford University, based on a worked example.
- The Complex SAT Math Problem Even the College Board Got Wrong: Andrew Daniels in Popular Mechanics
This article incorporates material from Median of a distribution on PlanetMath, which is licensed under the Creative Commons Attribution/Share-Alike License.
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||