Generative adversarial network
A generative adversarial network (GAN) is a class of machine learning frameworks designed by Ian Goodfellow and his colleagues in June 2014.[1] Two neural networks contest with each other in the form of a zero-sum game, where one agent's gain is another agent's loss.
| Part of a series on |
| Machine learning and data mining |
|---|
 |
Given a training set, this technique learns to generate new data with the same statistics as the training set. For example, a GAN trained on photographs can generate new photographs that look at least superficially authentic to human observers, having many realistic characteristics. Though originally proposed as a form of generative model for unsupervised learning, GANs have also proved useful for semi-supervised learning,[2] fully supervised learning,[3] and reinforcement learning.[4]
The core idea of a GAN is based on the "indirect" training through the discriminator, another neural network that can tell how "realistic" the input seems, which itself is also being updated dynamically.[5] This means that the generator is not trained to minimize the distance to a specific image, but rather to fool the discriminator. This enables the model to learn in an unsupervised manner.
GANs are similar to mimicry in evolutionary biology, with an evolutionary arms race between both networks.
Definition
Mathematical
The original GAN is defined as the following game:[1]
Each probability space defines a GAN game.
There are 2 players: generator and discriminator.
The generator's strategy set is , the set of all probability measures on .
The discriminator's strategy set is the set of Markov kernels , where is the set of probability measures on .
The GAN game is a zero-sum game, with objective function
The generator aims to minimize the objective, and the discriminator aims to maximize the objective.








The generator's task is to approach , that is, to match its own output distribution as closely as possible to the reference distribution. The discriminator's task is to output a value close to 1 when the input appears to be from the reference distribution, and to output a value close to 0 when the input looks like it came from the generator distribution.

In practice
The generative network generates candidates while the discriminative network evaluates them.[1] The contest operates in terms of data distributions. Typically, the generative network learns to map from a latent space to a data distribution of interest, while the discriminative network distinguishes candidates produced by the generator from the true data distribution. The generative network's training objective is to increase the error rate of the discriminative network (i.e., "fool" the discriminator network by producing novel candidates that the discriminator thinks are not synthesized (are part of the true data distribution)).[1][6]
A known dataset serves as the initial training data for the discriminator. Training involves presenting it with samples from the training dataset until it achieves acceptable accuracy. The generator is trained based on whether it succeeds in fooling the discriminator. Typically, the generator is seeded with randomized input that is sampled from a predefined latent space (e.g. a multivariate normal distribution). Thereafter, candidates synthesized by the generator are evaluated by the discriminator. Independent backpropagation procedures are applied to both networks so that the generator produces better samples, while the discriminator becomes more skilled at flagging synthetic samples.[7] When used for image generation, the generator is typically a deconvolutional neural network, and the discriminator is a convolutional neural network.
Relation to other statistical machine learning methods
GANs are implicit generative models,[8] which means that they do not explicitly model the likelihood function nor provide a means for finding the latent variable corresponding to a given sample, unlike alternatives such as flow-based generative model.
Compared to fully visible belief networks such as WaveNet and PixelRNN and autoregressive models in general, GANs can generate one complete sample in one pass, rather than multiple passes through the network.
Compared to Boltzmann machines and nonlinear ICA, there is no restriction on the type of function used by the network.
Since neural networks are universal approximators, GANs are asymptotically consistent. Variational autoencoders might be universal approximators, but it is not proven as of 2017.[9]
Mathematical properties
Measure-theoretic considerations
This section provides some of the mathematical theory behind these methods.
In modern probability theory based on measure theory, a probability space also needs to be equipped with a σ-algebra. As a result, a more rigorous definition of the GAN game would make the following changes:
Each probability space defines a GAN game.
The generator's strategy set is , the set of all probability measures on the measure-space .
The discriminator's strategy set is the set of Markov kernels , where is the Borel σ-algebra on .





Since issues of measurability never arise in practice, we will not concern them further.
Choice of the strategy set
In the most generic version of the GAN game described above, the strategy set for the discriminator contains all Markov kernels , and the strategy set for the generator contains arbitrary probability distributions on .

However, as shown below, the optimal discriminator strategy against any is deterministic, thus there is no loss of generality in restricting the discriminator's strategies to deterministic functions . In most applications, is a deep neural network function.


As for the generator, while could theoretically be any computable probability distribution, in practice, it is usually implemented as a pushforward: . That is, start with a random variable , where is a probability distribution that is easy to compute (such as the uniform distribution, or the Gaussian distribution), then define a function . Then the distribution is the distribution of .





Consequently, the generator's strategy is usually defined as just , leaving implicit. In this formalism, the GAN game objective is


Generative reparametrization
The GAN architecture has two main components. One is casting optimization into a game, of form , which is different from the usual kind of optimization, of form . The other is the decomposition of into , which can be understood as a reparametrization trick.



To see its significance, one must compare GAN with previous methods for learning generative models, which were plagued with "intractable probabilistic computations that arise in maximum likelihood estimation and related strategies".[1]
At the same time, Kingma and Welling[10] and Rezende et al.[11] developed the same idea of reparametrization into a general stochastic backpropagation method. Among its first applications was the variational autoencoder.
Move order and strategic equilibria
In the original paper, as well as most subsequent papers, it is usually assumed that the generator moves first, and the discriminator moves second, thus giving the following minimax game:

If both the generator's and the discriminator's strategy sets are spanned by a finite number of strategies, then by the minimax theorem,

that is, the move order does not matter.
However, since the strategy sets are both not finitely spanned, the minimax theorem does not apply, and the idea of an "equilibrium" becomes delicate. To wit, there are the following different concepts of equilibrium:
- Equilibrium when generator moves first, and discriminator moves second:
- Equilibrium when discriminator moves first, and generator moves second:
- Nash equilibrium , which is stable under simultaneous move order:




For general games, these equilibria do not have to agree, or even to exist. For the original GAN game, these equilibria all exist, and are all equal. However, for more general GAN games, these do not necessarily exist, or agree.[12]
Main theorems for GAN game
The original GAN paper proved the following two theorems:[1]
Theorem (the optimal discriminator computes the Jensen–Shannon divergence) — For any fixed generator strategy , let the optimal reply be , then


where the derivative is the Radon–Nikodym derivative, and is the Jensen–Shannon divergence.

By Jensen's inequality,

and similarly for the other term. So the optimal reply can be deterministic. Define the function be , such that . So we have


We want to take their density functions, so define a base-measure , which then allows us to take the Radon-Nikodym derivatives


with .

With those, we have

The integrand is just the negative cross-entropy between two binary random variables, defined by and . We can write it as , where is the binary entropy function. And so





So the optimal strategy for the discriminator is , with


after routine calculation.
Interpretation: For any fixed generator strategy , the optimal discriminator keeps track of the likelihood ratio between the reference distribution and the generator distribution.

where is the logistic function. In particular, if the prior probability for an image to come from the reference distribution is equal to , then is just the posterior probability that came from the reference distribution:




Theorem (the unique equilibrium point) — For any GAN game, there exists , that is both a sequential equilibrium and a Nash equilibrium:


That is, the generator perfectly mimics the reference, and the discriminator outputs deterministically on all inputs.
From previous proposition,

For any fixed discriminator strategy , any concentrated on the set


is an optimal strategy for the generator. Thus

By Jensen's inequality, the discriminator can only improve by playing the deterministic strategy of always playing . Thus


By Jensen's inequality, it is upper-bounded by

Now push the upper bound:

The upper bound is actually reached by , thus


Finally, to check that it's a Nash equilibrium.
When ,


which is maximized by always.

When , any strategy is optimal for the generator.

Training and evaluating GAN
Unstable convergence
While the GAN game has a unique global equilibrium point when both the generator and discriminator have access to their entire strategy sets, the equilibrium is no longer guaranteed when they have a restricted strategy set.[12]
In practice, the generator has access only to measures of form , where is a function computed by a neural network with parameters , and is an easily sampled distribution, such as the uniform or normal distribution. Similarly, the discriminator has access only to functions of form , a function computed by a neural network with parameters . These restricted strategy sets take up a vanishingly small proportion of their entire strategy sets.[13]





Further, even if an equilibrium still exists, it can only be found by searching in the high-dimensional space of all possible neural network functions. The standard strategy of using gradient descent to find the equilibrium often does not work for GAN, and often the game "collapses" into one of several failure modes.
Mode collapse
GANs often suffer from mode collapse where they fail to generalize properly, missing entire modes from the input data. For example, a GAN trained on the MNIST dataset containing many samples of each digit might only generate pictures of digit 0. This was named in the first paper as the "Helvetica scenario".
One way this can happen is if the generator learns too fast compared to the discriminator. If the discriminator is held constant, then the optimal generator would only output elements of .[14] So for example, if during GAN training for generating MNIST dataset, for a few epochs, the discriminator somehow prefers the digit 0 slightly more than other digits, the generator may seize the opportunity to generate only digit 0, then be unable to escape the local minimum after the discriminator improves.

Some researchers perceive the root problem to be a weak discriminative network that fails to notice the pattern of omission, while others assign blame to a bad choice of objective function. Many solutions have been proposed, but it is still an open problem.[15][16]
Even the state-of-the-art architecture, BigGAN (2019), could not avoid mode collapse. The authors resorted to "allowing collapse to occur at the later stages of training, by which time a model is sufficiently trained to achieve good results".[17]
Two time-scale update rule
The two time-scale update rule (TTUR) is proposed to make GAN convergence more stable by making the learning rate of the generator lower than that of the discriminator. The authors argued that the generator should move slower than the discriminator, so that it does not "drive the discriminator steadily into new regions without capturing its gathered information".
They proved that a general class of games that included the GAN game, when trained under TTUR, "converges under mild assumptions to a stationary local Nash equilibrium".[18]
They also proposed using the Adam stochastic optimization[19] to avoid mode collapse, as well as the Fréchet inception distance for evaluating GAN performances.
Vanishing gradient
Conversely, if the discriminator learns too fast compared to the generator, then the discriminator could almost perfectly distinguish . In such case, the generator could be stuck with a very high loss no matter which direction it changes its , meaning that the gradient would be close to zero. In such case, the generator cannot learn, a case of the vanishing gradient problem.[13]


Intuitively speaking, the discriminator is too good, and since the generator cannot take any small step (only small steps are considered in gradient descent) to improve its payoff, it does not even try.
One important method for solving this problem is the Wasserstein GAN.
Evaluation
GANs are usually evaluated by Inception score (IS), which measures how varied the generator's outputs are (as classified by a image classifier, usually Inception-v3), or Fréchet inception distance (FID), which measures how similar the generator's outputs are to a reference set (as classified by a learned image featurizer, such as Inception-v3 without its final layer). Many papers that propose new GAN architectures for image generation report how their architectures break the state of the art on FID or IS.
Another evaluation method is the Learned Perceptual Image Patch Similarity (LPIPS), which starts with a learned image featurizer , and finetunes it by supervised learning on a set of , where is an image, is a perturbed version of it, and is how much they differ, as reported by human subjects. The model is finetuned so that it can approximate . This finetuned model is then used to define .[20]






Other evaluation methods are reviewed in.[21]
Variants
There is a veritable zoo of GAN variants.[22] Some of the most prominent are as follows:
Conditional GAN
Conditional GANs are similar to standard GANs except they allow the model to conditionally generate samples based on additional information. For example, if we want to generate a cat face given a dog picture, we could use a conditional GAN
The generator in a GAN game generates , a probability distribution on the probability space . This leads to the idea of a conditional GAN, where instead of generating one probability distribution on , the generator generates a different probability distribution on , for each given class label .


For example, for generating images that look like ImageNet, the generator should be able to generate a picture of cat when given the class label "cat".
In the original paper,[1] the authors noted that GAN can be trivially extended to conditional GAN by providing the labels to both the generator and the discriminator.
Concretely, the conditional GAN game is just the GAN game with class labels provided:

where is a probability distribution over classes, is the probability distribution of real images of class , and the probability distribution of images generated by the generator when given class label .


In 2017, a conditional GAN learned to generate 1000 image classes of ImageNet.[23]
GANs with alternative architectures
The GAN game is a general framework and can be run with any reasonable parametrization of the generator and discriminator . In the original paper, the authors demonstrated it using multilayer perceptron networks and convolutional neural networks. Many alternative architectures have been tried.
Deep convolutional GAN (DCGAN):[24] For both generator and discriminator, uses only deep networks consisting entirely of convolution-deconvolution layers, that is, fully convolutional networks.[25]
Self-attention GAN (SAGAN):[26] Starts with the DCGAN, then adds residually-connected standard self-attention modules to the generator and discriminator.
Transformer GAN (TransGAN):[27] Uses the pure transformer architecture for both the generator and discriminator, entirely devoid of convolution-deconvolution layers.
Flow-GAN:[28] Uses flow-based generative model for the generator, allowing efficient computation of the likelihood function.
GANs with alternative objectives
Many GAN variants are merely obtained by changing the loss functions for the generator and discriminator.
Original GAN:
We recast the original GAN objective into a form more convenient for comparison:

Original GAN, non-saturating loss:
This objective for generator was recommended in the original paper for faster convergence.[1]

The effect of using this objective is analyzed in Section 2.2.2 of.[29]
Original GAN, maximum likelihood:

where is the logistic function. When the discriminator is optimal, the generator gradient is the same as in maximum likelihood estimation, even though GAN cannot perform maximum likelihood estimation itself.[30][31] Hinge loss GAN:[32]


Least squares GAN:[33]


where are parameters to be chosen. The authors recommended .


Wasserstein GAN (WGAN)
The Wasserstein GAN modifies the GAN game at two points:
- The discriminator's strategy set is the set of measurable functions of type with bounded Lipschitz norm: , where is a fixed positive constant.
- The objective is




One of its purposes is to solve the problem of mode collapse (see above).[13] The authors claim "In no experiment did we see evidence of mode collapse for the WGAN algorithm".
InfoGAN
In conditional GAN, the generator receives both a noise vector and a label , and produces an image . The discriminator receives image-label pairs , and computes .




When the training dataset is unlabeled, conditional GAN does not work directly.
The idea of InfoGAN is to decree that every latent vector in the latent space can be decomposed as : an incompressible noise part , and an informative label part , and encourage the generator to comply with the decree, by encouraging it to maximize , the mutual information between and , while making no demands on the mutual information between .


Unfortunately, is intractable in general, The key idea of InfoGAN is Variational Mutual Information Maximization:[34] indirectly maximize it by maximizing a lower bound

where ranges over all Markov kernels of type . The InfoGAN game is defined as follows:[35]


Three probability spaces define an InfoGAN game:
- , the space of reference images.
- , the fixed random noise generator.
- , the fixed random information generator.
There are 3 players in 2 teams: generator, Q, and discriminator. The generator and Q are on one team, and the discriminator on the other team.
The objective function is
where is the original GAN game objective, and Generator-Q team aims to minimize the objective, and discriminator aims to maximize it:







Bidirectional GAN (BiGAN)
The standard GAN generator is a function of type , that is, it is a mapping from a latent space to the image space . This can be understood as a "decoding" process, whereby every latent vector is a code for an image , and the generator performs the decoding. This naturally leads to the idea of training another network that performs "encoding", creating an autoencoder out of the encoder-generator pair.





Already in the original paper,[1] the authors noted that "Learned approximate inference can be performed by training an auxiliary network to predict given ". The bidirectional GAN architecture performs exactly this.[36]
The BiGAN is defined as follows:
Two probability spaces define a BiGAN game:
- , the space of reference images.
- , the latent space.
There are 3 players in 2 teams: generator, encoder, and discriminator. The generator and encoder are on one team, and the discriminator on the other team.
The generator's strategies are functions , and the encoder's strategies are functions . The discriminator's strategies are functions .
The objective function is
Generator-encoder team aims to minimize the objective, and discriminator aims to maximize it:





In the paper, they gave a more abstract definition of the objective as:

where is the probability distribution on obtained by pushing forward via , and is the probability distribution on obtained by pushing forward via .






Applications of bidirectional models include semi-supervised learning,[37] interpretable machine learning,[38] and neural machine translation.[39]
Variational autoencoder GAN (VAEGAN)
Variational autoencoders (VAEs) are unsupervised models that learn a probabilistic latent representation of their inputs. VAEs consist of an encoder and decoder. The encoder maps high dimensional data into a low dimensional space where it can be represented using a simple parametric function. The decoder then reconstructs the original data back into its high dimensional space. The decoder uses variational inference to approximate the posterior over the latent variables.
Adversarial autoencoder
CycleGAN
CycleGAN is an architecture for performing translations between two domains, such as between photos of horses and photos of zebras, or photos of night cities and photos of day cities.
The CycleGAN game is defined as follows:[41]
There are two probability spaces , corresponding to the two domains needed for translations fore-and-back.
There are 4 players in 2 teams: generators , and discriminators .
The objective function is
where is a positive adjustable parameter, is the GAN game objective, and is the cycle consistency loss:
The generators aim to minimize the objective, and the discriminators aim to maximize it:









Unlike previous work like pix2pix,[42] which requires paired training data, cycleGAN requires no paired data. For example, to train a pix2pix model to turn a summer scenery photo to winter scenery photo and back, the dataset must contain pairs of the same place in summer and winter, shot at the same angle; cycleGAN would only need a set of summer scenery photos, and an unrelated set of winter scenery photos.
BigGAN
The BigGAN is essentially a self-attention GAN trained on a large scale (up to 80 million parameters) to generate large images of ImageNet (up to 512 x 512 resolution), with numerous engineering tricks to make it converge.[17][43]
Invertible data augmentation
When there is insufficient training data, the reference distribution cannot be well-approximated by the empirical distribution given by the training dataset. In such cases, data augmentation can be applied, to allow training GAN on smaller datasets. Naïve data augmentation, however, brings its problems.

Consider the original GAN game, slightly reformulated as follows:
Now we use data augmentation by randomly sampling semantic-preserving transforms and applying them to the dataset, to obtain the reformulated GAN game:


This is equivalent to a GAN game with a different distribution , sampled by , with . For example, if is the distribution of images in ImageNet, and samples identity-transform with probability 0.5, and horizontal-reflection with probability 0.5, then is the distribution of images in ImageNet and horizontally-reflected ImageNet, combined.




The result of such training would be a generator that mimics . For example, it would generate images that look like they are randomly cropped, if the data augmentation uses random cropping.
The solution is to apply data augmentation to both generated and real images:

The authors demonstrated high-quality generation using just 100-picture-large datasets.[44]
The StyleGAN-2-ADA paper points out a further point on data augmentation: it must be invertible.[45] Continue with the example of generating ImageNet pictures. If the data augmentation is "randomly rotate the picture by 0, 90, 180, 270 degrees with equal probability", then there is no way for the generator to know which is the true orientation: Consider two generators , such that for any latent , the generated image is a 90-degree rotation of . They would have exactly the same expected loss, and so neither is preferred over the other.


The solution is to only use invertible data augmentation: instead of "randomly rotate the picture by 0, 90, 180, 270 degrees with equal probability", use "randomly rotate the picture by 90, 180, 270 degrees with 0.1 probability, and keep the picture as it is with 0.7 probability". This way, the generator is still rewarded to keep images oriented the same way as un-augmented ImageNet pictures.
Abstractly, the effect of randomly sampling transformations from the distribution is to define a Markov kernel . Then, the data-augmented GAN game pushes the generator to find some , such that



where is the Markov kernel convolution. A data-augmentation method is defined to be invertible if its Markov kernel satisfies



Immediately by definition, we see that composing multiple invertible data-augmentation methods results in yet another invertible method. Also by definition, if the data-augmentation method is invertible, then using it in a GAN game does not change the optimal strategy for the generator, which is still .

There are two prototypical examples of invertible Markov kernels:
Discrete case: Invertible stochastic matrices, when is finite.
For example, if is the set of four images of an arrow, pointing in 4 directions, and the data augmentation is "randomly rotate the picture by 90, 180, 270 degrees with probability , and keep the picture as it is with probability ", then the Markov kernel can be represented as a stochastic matrix:




and is an invertible kernel iff is an invertible matrix, that is, .


Continuous case: The gaussian kernel, when for some .


For example, if is the space of 256x256 images, and the data-augmentation method is "generate a gaussian noise , then add to the image", then is just convolution by the density function of . This is invertible, because convolution by a gaussian is just convolution by the heat kernel, so given any , the convolved distribution can be obtained by heating up precisely according to , then wait for time . With that, we can recover by running the heat equation backwards in time for .









More examples of invertible data augmentations are found in the paper.[45]
SinGAN
SinGAN pushes data augmentation to the limit, by using only a single image as training data and performing data augmentation on it. The GAN architecture is adapted to this training method by using a multi-scale pipeline.
The generator is decomposed into a pyramid of generators , with the lowest one generating the image at the lowest resolution, then the generated image is scaled up to , and fed to the next level to generate an image at a higher resolution, and so on. The discriminator is decomposed into a pyramid as well.[46]




StyleGAN series
The StyleGAN family is a series of architectures pubilshed by Nvidia's research division.
Progressive GAN
Progressive GAN[47] is a method for training GAN for large-scale image generation stably, by growing a GAN generator from small to large scale in a pyramidal fashion. Like SinGAN, it decomposes the generator as, and the discriminator as .

During training, at first only are used in a GAN game to generate 4x4 images. Then are added to reach the second stage of GAN game, to generate 8x8 images, and so on, until we reach a GAN game to generate 1024x1024 images.


To avoid shock between stages of the GAN game, each new layer is "blended in" (Figure 2 of the paper[47]). For example, this is how the second stage GAN game starts:
- Just before, the GAN game consists of the pair generating and discriminating 4x4 images.
- Just after, the GAN game consists of the pair generating and discriminating 8x8 images. Here, the functions are image up- and down-sampling functions, and is a blend-in factor (much like an alpha in image composing) that smoothly glides from 0 to 1.



StyleGAN-1
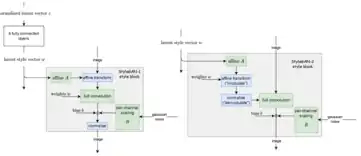
StyleGAN-1 is designed as a combination of Progressive GAN with neural style transfer.[48]
The key architectural choice of StyleGAN-1 is a progressive growth mechanism, similar to Progressive GAN. Each generated image starts as a constant array, and repeatedly passed through style blocks. Each style block applies a "style latent vector" via affine transform ("adaptive instance normalization"), similar to how neural style transfer uses Gramian matrix. It then adds noise, and normalize (subtract the mean, then divide by the variance).

At training time, usually only one style latent vector is used per image generated, but sometimes two ("mixing regularization") in order to encourage each style block to independently perform its stylization without expecting help from other style blocks (since they might receive an entirely different style latent vector).
After training, multiple style latent vectors can be fed into each style block. Those fed to the lower layers control the large-scale styles, and those fed to the higher layers control the fine-detail styles.
Style-mixing between two images can be performed as well. First, run a gradient descent to find such that . This is called "projecting an image back to style latent space". Then, can be fed to the lower style blocks, and to the higher style blocks, to generate a composite image that has the large-scale style of , and the fine-detail style of . Multiple images can also be composed this way.




StyleGAN-2
StyleGAN-2 improves upon StyleGAN-1, by using the style latent vector to transform the convolution layer's weights instead, thus solving the "blob" problem.[49]
This was updated by the StyleGAN-2-ADA ("ADA" stands for "adaptive"),[45] which uses invertible data augmentation as described above. It also tunes the amount of data augmentation applied by starting at zero, and gradually increasing it until an "overfitting heuristic" reaches a target level, thus the name "adaptive".
StyleGAN-3
StyleGAN-3[50] improves upon StyleGAN-2 by solving the "texture sticking" problem, which can be seen in the official videos.[51] They analyzed the problem by the Nyquist–Shannon sampling theorem, and argued that the layers in the generator learned to exploit the high-frequency signal in the pixels they operate upon.
To solve this, they proposed imposing strict lowpass filters between each generator's layers, so that the generator is forced to operate on the pixels in a way faithful to the continuous signals they represent, rather than operate on them as merely discrete signals. They further imposed rotational and translational invariance by using more signal filters. The resulting StyleGAN-3 is able to solve the texture sticking problem, as well as generating images that rotate and translate smoothly.
Applications
GAN applications have increased rapidly.[52]
Fashion, art and advertising

GANs can be used to generate art; The Verge wrote in March 2019 that "The images created by GANs have become the defining look of contemporary AI art."[54] GANs can also be used to inpaint photographs[55] or create photos of imaginary fashion models, with no need to hire a model, photographer or makeup artist, or pay for a studio and transportation.[56] GANs have also been used for virtual shadow generation.[57]
Science
GANs can improve astronomical images[58] and simulate gravitational lensing for dark matter research.[59][60][61] They were used in 2019 to successfully model the distribution of dark matter in a particular direction in space and to predict the gravitational lensing that will occur.[62][63]
GANs have been proposed as a fast and accurate way of modeling high energy jet formation[64] and modeling showers through calorimeters of high-energy physics experiments.[65][66][67][68] GANs have also been trained to accurately approximate bottlenecks in computationally expensive simulations of particle physics experiments. Applications in the context of present and proposed CERN experiments have demonstrated the potential of these methods for accelerating simulation and/or improving simulation fidelity.[69][70]
Video games
In 2018, GANs reached the video game modding community, as a method of up-scaling low-resolution 2D textures in old video games by recreating them in 4k or higher resolutions via image training, and then down-sampling them to fit the game's native resolution (with results resembling the supersampling method of anti-aliasing).[71] With proper training, GANs provide a clearer and sharper 2D texture image magnitudes higher in quality than the original, while fully retaining the original's level of details, colors, etc. Known examples of extensive GAN usage include Final Fantasy VIII, Final Fantasy IX, Resident Evil REmake HD Remaster, and Max Payne.
AI generated video
Artificial intelligence art for video uses AI to generate video from text as Text-to-Video model[72]
Audio synthesis
Generative audio refers to the creation of audio files from databases of audio clips. This technology differs from AI voices such as Apple's Siri or Amazon's Alexa, which use a collection of fragments that are stitched together on demand.
Concerns about malicious applications


Concerns have been raised about the potential use of GAN-based human image synthesis for sinister purposes, e.g., to produce fake, possibly incriminating, photographs and videos.[74] GANs can be used to generate unique, realistic profile photos of people who do not exist, in order to automate creation of fake social media profiles.[75]
In 2019 the state of California considered[76] and passed on October 3, 2019, the bill AB-602, which bans the use of human image synthesis technologies to make fake pornography without the consent of the people depicted, and bill AB-730, which prohibits distribution of manipulated videos of a political candidate within 60 days of an election. Both bills were authored by Assembly member Marc Berman and signed by Governor Gavin Newsom. The laws went into effect in 2020.[77]
DARPA's Media Forensics program studies ways to counteract fake media, including fake media produced using GANs.[78]
Transfer learning
State-of-art transfer learning research use GANs to enforce the alignment of the latent feature space, such as in deep reinforcement learning.[79] This works by feeding the embeddings of the source and target task to the discriminator which tries to guess the context. The resulting loss is then (inversely) backpropagated through the encoder.
Miscellaneous applications
GAN can be used to detect glaucomatous images helping the early diagnosis which is essential to avoid partial or total loss of vision.[80]
GANs that produce photorealistic images can be used to visualize interior design, industrial design, shoes,[81] bags, and clothing items or items for computer games' scenes. Such networks were reported to be used by Facebook.[82]
GANs have been used to create forensic facial reconstructions of deceased historical figures.[83]
GANs can reconstruct 3D models of objects from images,[84] generate novel objects as 3D point clouds,[85] and model patterns of motion in video.[86]
GANs can be used to age face photographs to show how an individual's appearance might change with age.[87]
GANs can be used for data augmentation, eg. to improve DNN classifier[88]
GANs can also be used to inpaint missing features in maps, transfer map styles in cartography[89] or augment street view imagery.[90]
Relevance feedback on GANs can be used to generate images and replace image search systems.[91]
A variation of the GANs is used in training a network to generate optimal control inputs to nonlinear dynamical systems. Where the discriminatory network is known as a critic that checks the optimality of the solution and the generative network is known as an Adaptive network that generates the optimal control. The critic and adaptive network train each other to approximate a nonlinear optimal control.[92]
GANs have been used to visualize the effect that climate change will have on specific houses.[93]
A GAN model called Speech2Face can reconstruct an image of a person's face after listening to their voice.[94]
In 2016 GANs were used to generate new molecules for a variety of protein targets implicated in cancer, inflammation, and fibrosis. In 2019 GAN-generated molecules were validated experimentally all the way into mice.[95][96]
Whereas the majority of GAN applications are in image processing, the work has also been done with time-series data. For example, recurrent GANs (R-GANs) have been used to generate energy data for machine learning.[97]
History
The most direct inspiration for GANs was noise-contrastive estimation,[98] which uses the same loss function as GANs and which Goodfellow studied during his PhD in 2010–2014.
Other people had similar ideas but did not develop them similarly. An idea involving adversarial networks was published in a 2010 blog post by Olli Niemitalo.[99] This idea was never implemented and did not involve stochasticity in the generator and thus was not a generative model. It is now known as a conditional GAN or cGAN.[100] An idea similar to GANs was used to model animal behavior by Li, Gauci and Gross in 2013.[101]
Adversarial machine learning has other uses besides generative modeling and can be applied to models other than neural networks. In control theory, adversarial learning based on neural networks was used in 2006 to train robust controllers in a game theoretic sense, by alternating the iterations between a minimizer policy, the controller, and a maximizer policy, the disturbance.[102][103]
In 2017, a GAN was used for image enhancement focusing on realistic textures rather than pixel-accuracy, producing a higher image quality at high magnification.[104] In 2017, the first faces were generated.[105] These were exhibited in February 2018 at the Grand Palais.[106][107] Faces generated by StyleGAN[108] in 2019 drew comparisons with Deepfakes.[109][110][111]
Beginning in 2017, GAN technology began to make its presence felt in the fine arts arena with the appearance of a newly developed implementation which was said to have crossed the threshold of being able to generate unique and appealing abstract paintings, and thus dubbed a "CAN", for "creative adversarial network".[112] A GAN system was used to create the 2018 painting Edmond de Belamy, which sold for US$432,500.[113] An early 2019 article by members of the original CAN team discussed further progress with that system, and gave consideration as well to the overall prospects for an AI-enabled art.[114]
In May 2019, researchers at Samsung demonstrated a GAN-based system that produces videos of a person speaking, given only a single photo of that person.[115]
In August 2019, a large dataset consisting of 12,197 MIDI songs each with paired lyrics and melody alignment was created for neural melody generation from lyrics using conditional GAN-LSTM (refer to sources at GitHub AI Melody Generation from Lyrics).[116]
In May 2020, Nvidia researchers taught an AI system (termed "GameGAN") to recreate the game of Pac-Man simply by watching it being played.[117][118]
References
- Goodfellow, Ian; Pouget-Abadie, Jean; Mirza, Mehdi; Xu, Bing; Warde-Farley, David; Ozair, Sherjil; Courville, Aaron; Bengio, Yoshua (2014). Generative Adversarial Nets (PDF). Proceedings of the International Conference on Neural Information Processing Systems (NIPS 2014). pp. 2672–2680.
- Salimans, Tim; Goodfellow, Ian; Zaremba, Wojciech; Cheung, Vicki; Radford, Alec; Chen, Xi (2016). "Improved Techniques for Training GANs". arXiv:1606.03498 [cs.LG].
- Isola, Phillip; Zhu, Jun-Yan; Zhou, Tinghui; Efros, Alexei (2017). "Image-to-Image Translation with Conditional Adversarial Nets". Computer Vision and Pattern Recognition.
- Ho, Jonathon; Ermon, Stefano (2016). "Generative Adversarial Imitation Learning". Advances in Neural Information Processing Systems. 29: 4565–4573. arXiv:1606.03476. Bibcode:2016arXiv160603476H.
- "Vanilla GAN (GANs in computer vision: Introduction to generative learning)". theaisummer.com. AI Summer. April 10, 2020. Archived from the original on June 3, 2020. Retrieved September 20, 2020.
- Luc, Pauline; Couprie, Camille; Chintala, Soumith; Verbeek, Jakob (November 25, 2016). "Semantic Segmentation using Adversarial Networks". NIPS Workshop on Adversarial Training, Dec, Barcelona, Spain. 2016. arXiv:1611.08408. Bibcode:2016arXiv161108408L.
- Andrej Karpathy; Pieter Abbeel; Greg Brockman; Peter Chen; Vicki Cheung; Rocky Duan; Ian Goodfellow; Durk Kingma; Jonathan Ho; Rein Houthooft; Tim Salimans; John Schulman; Ilya Sutskever; Wojciech Zaremba, Generative Models, OpenAI, retrieved April 7, 2016
- Mohamed, Shakir; Lakshminarayanan, Balaji (2016). "Learning in Implicit Generative Models". arXiv:1610.03483 [stat.ML].
- Goodfellow, Ian (April 3, 2017). "NIPS 2016 Tutorial: Generative Adversarial Networks". arXiv:1701.00160 [cs.LG].
- Kingma, Diederik P.; Welling, Max (May 1, 2014). "Auto-Encoding Variational Bayes". arXiv:1312.6114 [stat.ML].
- Rezende, Danilo Jimenez; Mohamed, Shakir; Wierstra, Daan (June 18, 2014). "Stochastic Backpropagation and Approximate Inference in Deep Generative Models". International Conference on Machine Learning. PMLR: 1278–1286. arXiv:1401.4082.
- Farnia, Farzan; Ozdaglar, Asuman (November 21, 2020). "Do GANs always have Nash equilibria?". International Conference on Machine Learning. PMLR: 3029–3039.
- Weng, Lilian (April 18, 2019). "From GAN to WGAN". arXiv:1904.08994 [cs.LG].
- "r/MachineLearning - Comment by u/ian_goodfellow on "[R] [1701.07875] Wasserstein GAN". reddit. Retrieved July 15, 2022.
- Lin, Zinan; et al. (December 2018). PacGAN: the power of two samples in generative adversarial networks. 32nd International Conference on Neural Information Processing Systems. pp. 1505–1514. arXiv:1712.04086.
- Mescheder, Lars; Geiger, Andreas; Nowozin, Sebastian (July 31, 2018). "Which Training Methods for GANs do actually Converge?". arXiv:1801.04406 [cs.LG].
- Brock, Andrew; Donahue, Jeff; Simonyan, Karen (September 1, 2018). Large Scale GAN Training for High Fidelity Natural Image Synthesis. International Conference on Learning Representations 2019.
- Heusel, Martin; Ramsauer, Hubert; Unterthiner, Thomas; Nessler, Bernhard; Hochreiter, Sepp (2017). "GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium". Advances in Neural Information Processing Systems. Curran Associates, Inc. 30. arXiv:1706.08500.
- Kingma, Diederik P.; Ba, Jimmy (January 29, 2017). "Adam: A Method for Stochastic Optimization". arXiv:1412.6980 [cs.LG].
- Zhang, Richard; Isola, Phillip; Efros, Alexei A.; Shechtman, Eli; Wang, Oliver (2018). "The Unreasonable Effectiveness of Deep Features as a Perceptual Metric". pp. 586–595. arXiv:1801.03924 [cs.CV].
- Borji, Ali (February 1, 2019). "Pros and cons of GAN evaluation measures". Computer Vision and Image Understanding. 179: 41–65. arXiv:1802.03446. doi:10.1016/j.cviu.2018.10.009. ISSN 1077-3142. S2CID 3627712.
- Hindupur, Avinash (July 15, 2022), The GAN Zoo, retrieved July 15, 2022
- Odena, Augustus; Olah, Christopher; Shlens, Jonathon (July 17, 2017). "Conditional Image Synthesis with Auxiliary Classifier GANs". International Conference on Machine Learning. PMLR: 2642–2651. arXiv:1610.09585.
- Radford, Alec; Metz, Luke; Chintala, Soumith (2016). "Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks". ICLR. S2CID 11758569.
- Long, Jonathan; Shelhamer, Evan; Darrell, Trevor (2015). "Fully Convolutional Networks for Semantic Segmentation": 3431–3440.
{{cite journal}}: Cite journal requires|journal=(help) - Zhang, Han; Goodfellow, Ian; Metaxas, Dimitris; Odena, Augustus (May 24, 2019). "Self-Attention Generative Adversarial Networks". International Conference on Machine Learning. PMLR: 7354–7363.
- Jiang, Yifan; Chang, Shiyu; Wang, Zhangyang (December 8, 2021). "TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up". arXiv:2102.07074 [cs.CV].
- Grover, Aditya; Dhar, Manik; Ermon, Stefano (May 1, 2017). "Flow-GAN: Combining Maximum Likelihood and Adversarial Learning in Generative Models". arXiv:1705.08868 [cs.LG].
- Arjovsky, Martin; Bottou, Léon (January 1, 2017). "Towards Principled Methods for Training Generative Adversarial Networks". arXiv:1701.04862 [stat.ML].
- Goodfellow, Ian J. (December 1, 2014). "On distinguishability criteria for estimating generative models". arXiv:1412.6515 [stat.ML].
- Goodfellow, Ian (August 31, 2016). "Generative Adversarial Networks (GANs), Presentation at Berkeley Artificial Intelligence Lab" (PDF). Archived (PDF) from the original on May 8, 2022.
- Lim, Jae Hyun; Ye, Jong Chul (May 8, 2017). "Geometric GAN". arXiv:1705.02894 [stat.ML].
- Mao, Xudong; Li, Qing; Xie, Haoran; Lau, Raymond Y. K.; Wang, Zhen; Paul Smolley, Stephen (2017). "Least Squares Generative Adversarial Networks": 2794–2802.
{{cite journal}}: Cite journal requires|journal=(help) - Barber, David; Agakov, Felix (December 9, 2003). "The IM algorithm: a variational approach to Information Maximization". Proceedings of the 16th International Conference on Neural Information Processing Systems. NIPS'03. Cambridge, MA, USA: MIT Press: 201–208.
- Chen, Xi; Duan, Yan; Houthooft, Rein; Schulman, John; Sutskever, Ilya; Abbeel, Pieter (2016). "InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets". Advances in Neural Information Processing Systems. Curran Associates, Inc. 29. arXiv:1606.03657.
- Donahue, Jeff; Krähenbühl, Philipp; Darrell, Trevor (2016). "Adversarial Feature Learning". arXiv:1605.09782 [cs.LG].
- Dumoulin, Vincent; Belghazi, Ishmael; Poole, Ben; Mastropietro, Olivier; Arjovsky, Alex; Courville, Aaron (2016). "Adversarially Learned Inference". arXiv:1606.00704 [stat.ML].
- Xi Chen; Yan Duan; Rein Houthooft; John Schulman; Ilya Sutskever; Pieter Abeel (2016). "InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets". arXiv:1606.03657 [cs.LG].
- Zhirui Zhang; Shujie Liu; Mu Li; Ming Zhou; Enhong Chen (October 2018). "Bidirectional Generative Adversarial Networks for Neural Machine Translation" (PDF). pp. 190–199.
- Makhzani, Alireza; Shlens, Jonathon; Jaitly, Navdeep; Goodfellow, Ian; Frey, Brendan (2016). "Adversarial Autoencoders". arXiv:1511.05644 [cs.LG].
- Zhu, Jun-Yan; Park, Taesung; Isola, Phillip; Efros, Alexei A. (2017). "Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks". pp. 2223–2232. arXiv:1703.10593 [cs.CV].
- Isola, Phillip; Zhu, Jun-Yan; Zhou, Tinghui; Efros, Alexei A. (2017). "Image-To-Image Translation With Conditional Adversarial Networks". pp. 1125–1134. arXiv:1611.07004 [cs.CV].
- Brownlee, Jason (August 22, 2019). "A Gentle Introduction to BigGAN the Big Generative Adversarial Network". Machine Learning Mastery. Retrieved July 15, 2022.
- Shengyu, Zhao; Zhijian, Liu; Ji, Lin; Jun-Yan, Zhu; Song, Han (2020). "Differentiable Augmentation for Data-Efficient GAN Training". Advances in Neural Information Processing Systems. 33. arXiv:2006.10738.
- Tero, Karras; Miika, Aittala; Janne, Hellsten; Samuli, Laine; Jaakko, Lehtinen; Timo, Aila (2020). "Training Generative Adversarial Networks with Limited Data". Advances in Neural Information Processing Systems. 33.
- Shaham, Tamar Rott; Dekel, Tali; Michaeli, Tomer (October 2019). "SinGAN: Learning a Generative Model From a Single Natural Image". 2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE: 4569–4579. arXiv:1905.01164. doi:10.1109/iccv.2019.00467. ISBN 978-1-7281-4803-8. S2CID 145052179.
- Karras, Tero; Aila, Timo; Laine, Samuli; Lehtinen, Jaakko (October 1, 2017). "Progressive Growing of GANs for Improved Quality, Stability, and Variation". arXiv:1710.10196 [cs.NE].
- Karras, Tero; Laine, Samuli; Aila, Timo (June 2019). "A Style-Based Generator Architecture for Generative Adversarial Networks". 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE: 4396–4405. arXiv:1812.04948. doi:10.1109/cvpr.2019.00453. ISBN 978-1-7281-3293-8. S2CID 54482423.
- Karras, Tero; Laine, Samuli; Aittala, Miika; Hellsten, Janne; Lehtinen, Jaakko; Aila, Timo (June 2020). "Analyzing and Improving the Image Quality of StyleGAN". 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE: 8107–8116. arXiv:1912.04958. doi:10.1109/cvpr42600.2020.00813. ISBN 978-1-7281-7168-5. S2CID 209202273.
- Timo, Karras, Tero Aittala, Miika Laine, Samuli Härkönen, Erik Hellsten, Janne Lehtinen, Jaakko Aila (June 23, 2021). Alias-Free Generative Adversarial Networks. OCLC 1269560084.
- Karras, Tero; Aittala, Miika; Laine, Samuli; Härkönen, Erik; Hellsten, Janne; Lehtinen, Jaakko; Aila, Timo. "Alias-Free Generative Adversarial Networks (StyleGAN3)". nvlabs.github.io. Retrieved July 16, 2022.
- Caesar, Holger (March 1, 2019), A list of papers on Generative Adversarial (Neural) Networks: nightrome/really-awesome-gan, retrieved March 2, 2019
- Robertson, Adi (February 21, 2022). "The US Copyright Office says an AI can't copyright its art". The Verge. Retrieved February 24, 2022.
- Vincent, James (March 5, 2019). "A never-ending stream of AI art goes up for auction". The Verge. Retrieved June 13, 2020.
- Yu, Jiahui, et al. "Generative image inpainting with contextual attention." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
- Wong, Ceecee. "The Rise of AI Supermodels". CDO Trends.
- Taif, K.; Ugail, H.; Mehmood, I. (2020). "Cast Shadow Generation Using Generative Adversarial Networks". Computational Science – Iccs 2020. Lecture Notes in Computer Science. 12141: 481–495. doi:10.1007/978-3-030-50426-7_36. ISBN 978-3-030-50425-0. PMC 7302543.
- Schawinski, Kevin; Zhang, Ce; Zhang, Hantian; Fowler, Lucas; Santhanam, Gokula Krishnan (February 1, 2017). "Generative Adversarial Networks recover features in astrophysical images of galaxies beyond the deconvolution limit". Monthly Notices of the Royal Astronomical Society: Letters. 467 (1): L110–L114. arXiv:1702.00403. Bibcode:2017MNRAS.467L.110S. doi:10.1093/mnrasl/slx008. S2CID 7213940.
- Kincade, Kathy. "Researchers Train a Neural Network to Study Dark Matter". R&D Magazine.
- Kincade, Kathy (May 16, 2019). "CosmoGAN: Training a neural network to study dark matter". Phys.org.
- "Training a neural network to study dark matter". Science Daily. May 16, 2019.
- at 06:13, Katyanna Quach 20 May 2019. "Cosmoboffins use neural networks to build dark matter maps the easy way". www.theregister.co.uk. Retrieved May 20, 2019.
- Mustafa, Mustafa; Bard, Deborah; Bhimji, Wahid; Lukić, Zarija; Al-Rfou, Rami; Kratochvil, Jan M. (May 6, 2019). "CosmoGAN: creating high-fidelity weak lensing convergence maps using Generative Adversarial Networks". Computational Astrophysics and Cosmology. 6 (1): 1. arXiv:1706.02390. Bibcode:2019ComAC...6....1M. doi:10.1186/s40668-019-0029-9. ISSN 2197-7909. S2CID 126034204.
- Paganini, Michela; de Oliveira, Luke; Nachman, Benjamin (2017). "Learning Particle Physics by Example: Location-Aware Generative Adversarial Networks for Physics Synthesis". Computing and Software for Big Science. 1: 4. arXiv:1701.05927. Bibcode:2017arXiv170105927D. doi:10.1007/s41781-017-0004-6. S2CID 88514467.
- Paganini, Michela; de Oliveira, Luke; Nachman, Benjamin (2018). "Accelerating Science with Generative Adversarial Networks: An Application to 3D Particle Showers in Multi-Layer Calorimeters". Physical Review Letters. 120 (4): 042003. arXiv:1705.02355. Bibcode:2018PhRvL.120d2003P. doi:10.1103/PhysRevLett.120.042003. PMID 29437460. S2CID 3330974.
- Paganini, Michela; de Oliveira, Luke; Nachman, Benjamin (2018). "CaloGAN: Simulating 3D High Energy Particle Showers in Multi-Layer Electromagnetic Calorimeters with Generative Adversarial Networks". Phys. Rev. D. 97 (1): 014021. arXiv:1712.10321. Bibcode:2018PhRvD..97a4021P. doi:10.1103/PhysRevD.97.014021. S2CID 41265836.
- Erdmann, Martin; Glombitza, Jonas; Quast, Thorben (2019). "Precise Simulation of Electromagnetic Calorimeter Showers Using a Wasserstein Generative Adversarial Network". Computing and Software for Big Science. 3: 4. arXiv:1807.01954. doi:10.1007/s41781-018-0019-7. S2CID 54216502.
- Musella, Pasquale; Pandolfi, Francesco (2018). "Fast and Accurate Simulation of Particle Detectors Using Generative Adversarial Networks". Computing and Software for Big Science. 2: 8. arXiv:1805.00850. Bibcode:2018arXiv180500850M. doi:10.1007/s41781-018-0015-y. S2CID 119474793.
- "Deep generative models for fast shower simulation in ATLAS". 2018.
- SHiP, Collaboration (2019). "Fast simulation of muons produced at the SHiP experiment using Generative Adversarial Networks". Journal of Instrumentation. 14 (11): P11028. arXiv:1909.04451. Bibcode:2019JInst..14P1028A. doi:10.1088/1748-0221/14/11/P11028. S2CID 202542604.
- Tang, Xiaoou; Qiao, Yu; Loy, Chen Change; Dong, Chao; Liu, Yihao; Gu, Jinjin; Wu, Shixiang; Yu, Ke; Wang, Xintao (September 1, 2018). "ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks". arXiv:1809.00219. Bibcode:2018arXiv180900219W.
- Narain, Rohit (December 29, 2021). "Smart Video Generation from Text Using Deep Neural Networks". Retrieved October 13, 2022.
- "Fake news: you ain't seen nothing yet". The Economist. July 2017. Retrieved July 1, 2017.
- msmash (February 14, 2019). "'This Person Does Not Exist' Website Uses AI To Create Realistic Yet Horrifying Faces". Slashdot. Retrieved February 16, 2019.
- Doyle, Michael (May 16, 2019). "John Beasley lives on Saddlehorse Drive in Evansville. Or does he?". Courier and Press.
- Targett, Ed (May 16, 2019). "California moves closer to making deepfake pornography illegal". Computer Business Review.
- Mihalcik, Carrie (October 4, 2019). "California laws seek to crack down on deepfakes in politics and porn". cnet.com. CNET. Retrieved October 13, 2019.
- Knight, Will (August 7, 2018). "The Defense Department has produced the first tools for catching deepfakes". MIT Technology Review.
- Li, Bonnie; François-Lavet, Vincent; Doan, Thang; Pineau, Joelle (February 14, 2021). "Domain Adversarial Reinforcement Learning". arXiv:2102.07097 [cs.LG].
- Bisneto, Tomaz Ribeiro Viana; de Carvalho Filho, Antonio Oseas; Magalhães, Deborah Maria Vieira (February 2020). "Generative adversarial network and texture features applied to automatic glaucoma detection". Applied Soft Computing. 90: 106165. doi:10.1016/j.asoc.2020.106165. S2CID 214571484.
- Wei, Jerry (July 3, 2019). "Generating Shoe Designs with Machine Learning". Medium. Retrieved November 6, 2019.
- Greenemeier, Larry (June 20, 2016). "When Will Computers Have Common Sense? Ask Facebook". Scientific American. Retrieved July 31, 2016.
- Reconstruction of the Roman Emperors: Interview with Daniel Voshart, retrieved June 3, 2022
- "3D Generative Adversarial Network". 3dgan.csail.mit.edu.
- Achlioptas, Panos; Diamanti, Olga; Mitliagkas, Ioannis; Guibas, Leonidas (2018). "Learning Representations and Generative Models for 3D Point Clouds". arXiv:1707.02392 [cs.CV].
- Vondrick, Carl; Pirsiavash, Hamed; Torralba, Antonio (2016). "Generating Videos with Scene Dynamics". carlvondrick.com. arXiv:1609.02612. Bibcode:2016arXiv160902612V.
- Antipov, Grigory; Baccouche, Moez; Dugelay, Jean-Luc (2017). "Face Aging With Conditional Generative Adversarial Networks". arXiv:1702.01983 [cs.CV].
- Feltus, Christophe (December 2021). "LogicGAN–based Data Augmentation Approach to Improve Adversarial Attack DNN Classifiers". Proceedings of the 2021 International Conference on Computational Science and Computational Intelligence (CSCI): 180–185. doi:10.1109/CSCI54926.2021.00011. ISBN 978-1-6654-5841-2. S2CID 249929238.
- Kang, Yuhao; Gao, Song; Roth, Rob (2019). "Transferring Multiscale Map Styles Using Generative Adversarial Networks". International Journal of Cartography. 5 (2–3): 115–141. arXiv:1905.02200. Bibcode:2019arXiv190502200K. doi:10.1080/23729333.2019.1615729. S2CID 146808465.
- Wijnands, Jasper; Nice, Kerry; Thompson, Jason; Zhao, Haifeng; Stevenson, Mark (2019). "Streetscape augmentation using generative adversarial networks: Insights related to health and wellbeing". Sustainable Cities and Society. 49: 101602. arXiv:1905.06464. Bibcode:2019arXiv190506464W. doi:10.1016/j.scs.2019.101602. S2CID 155100183.
- Ukkonen, Antti; Joona, Pyry; Ruotsalo, Tuukka (2020). "Generating Images Instead of Retrieving Them: Relevance Feedback on Generative Adversarial Networks". Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval: 1329–1338. doi:10.1145/3397271.3401129. hdl:10138/328471. ISBN 9781450380164. S2CID 220730163.
- Padhi, Radhakant; Unnikrishnan, Nishant (2006). "A single network adaptive critic (SNAC) architecture for optimal control synthesis for a class of nonlinear systems". Neural Networks. 19 (10): 1648–1660. doi:10.1016/j.neunet.2006.08.010. PMID 17045458.
- "AI can show us the ravages of climate change". MIT Technology Review. May 16, 2019.
- Christian, Jon (May 28, 2019). "ASTOUNDING AI GUESSES WHAT YOU LOOK LIKE BASED ON YOUR VOICE". Futurism.
- Zhavoronkov, Alex (2019). "Deep learning enables rapid identification of potent DDR1 kinase inhibitors". Nature Biotechnology. 37 (9): 1038–1040. doi:10.1038/s41587-019-0224-x. PMID 31477924. S2CID 201716327.
- Barber, Gregory. "A Molecule Designed By AI Exhibits 'Druglike' Qualities". Wired.
- Mohammad Navid Fekri; Ananda Mohon Ghosh; Katarina Grolinger (2020). "Generating Energy Data for Machine Learning with Recurrent Generative Adversarial Networks". Energies. 13 (1): 130. doi:10.3390/en13010130.
- Gutmann, Michael; Hyvärinen, Aapo. "Noise-Contrastive Estimation" (PDF). International Conference on AI and Statistics.
- Niemitalo, Olli (February 24, 2010). "A method for training artificial neural networks to generate missing data within a variable context". Internet Archive (Wayback Machine). Archived from the original on March 12, 2012. Retrieved February 22, 2019.
- "GANs were invented in 2010?". reddit r/MachineLearning. 2019. Retrieved May 28, 2019.
- Li, Wei; Gauci, Melvin; Gross, Roderich (July 6, 2013). "Proceeding of the fifteenth annual conference on Genetic and evolutionary computation conference - GECCO '13". Proceedings of the 15th Annual Conference on Genetic and Evolutionary Computation (GECCO 2013). Amsterdam, The Netherlands: ACM. pp. 223–230. doi:10.1145/2463372.2465801. ISBN 9781450319638.
- Abu-Khalaf, Murad; Lewis, Frank L.; Huang, Jie (July 1, 2008). "Neurodynamic Programming and Zero-Sum Games for Constrained Control Systems". IEEE Transactions on Neural Networks. 19 (7): 1243–1252. doi:10.1109/TNN.2008.2000204. S2CID 15680448.
- Abu-Khalaf, Murad; Lewis, Frank L.; Huang, Jie (December 1, 2006). "Policy Iterations on the Hamilton–Jacobi–Isaacs Equation for H∞ State Feedback Control With Input Saturation". IEEE Transactions on Automatic Control. doi:10.1109/TAC.2006.884959. S2CID 1338976.
- Sajjadi, Mehdi S. M.; Schölkopf, Bernhard; Hirsch, Michael (December 23, 2016). "EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis". arXiv:1612.07919 [cs.CV].
- "This Person Does Not Exist: Neither Will Anything Eventually with AI". March 20, 2019.
- "ARTificial Intelligence enters the History of Art". December 28, 2018.
- Tom Février (February 17, 2019). "Le scandale de l'intelligence ARTificielle".
- "StyleGAN: Official TensorFlow Implementation". March 2, 2019 – via GitHub.
- Paez, Danny (February 13, 2019). "This Person Does Not Exist Is the Best One-Off Website of 2019". Retrieved February 16, 2019.
- Beschizza, Rob (February 15, 2019). "This Person Does Not Exist". Boing-Boing. Retrieved February 16, 2019.
- Horev, Rani (December 26, 2018). "Style-based GANs – Generating and Tuning Realistic Artificial Faces". Lyrn.AI. Archived from the original on November 5, 2020. Retrieved February 16, 2019.
- Elgammal, Ahmed; Liu, Bingchen; Elhoseiny, Mohamed; Mazzone, Marian (2017). "CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms". arXiv:1706.07068 [cs.AI].
- Cohn, Gabe (October 25, 2018). "AI Art at Christie's Sells for $432,500". The New York Times.
- Mazzone, Marian; Ahmed Elgammal (February 21, 2019). "Art, Creativity, and the Potential of Artificial Intelligence". Arts. 8: 26. doi:10.3390/arts8010026.
- Kulp, Patrick (May 23, 2019). "Samsung's AI Lab Can Create Fake Video Footage From a Single Headshot". AdWeek.
- Yu, Yi; Canales, Simon (2021). "Conditional LSTM-GAN for Melody Generation from Lyrics". ACM Transactions on Multimedia Computing, Communications, and Applications. 17: 1–20. arXiv:1908.05551. doi:10.1145/3424116. ISSN 1551-6857. S2CID 199668828.
- "Nvidia's AI recreates Pac-Man from scratch just by watching it being played". The Verge. May 22, 2020.
- Seung Wook Kim; Zhou, Yuhao; Philion, Jonah; Torralba, Antonio; Fidler, Sanja (2020). "Learning to Simulate Dynamic Environments with GameGAN". arXiv:2005.12126 [cs.CV].
External links
- Knight, Will. "5 Big Predictions for Artificial Intelligence in 2017". MIT Technology Review. Retrieved January 5, 2017.
- Karras, Tero; Laine, Samuli; Aila, Timo (2018). "A Style-Based Generator Architecture for Generative Adversarial Networks". arXiv:1812.04948 [cs.NE].
- This Person Does Not Exist – photorealistic images of people who do not exist, generated by StyleGAN
- This Cat Does Not Exist – photorealistic images of cats who do not exist, generated by StyleGAN
- Wang, Zhengwei; She, Qi; Ward, Tomas E. (2019). "Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy". arXiv:1906.01529 [cs.LG].
Differentiable computing | |||||||
|---|---|---|---|---|---|---|---|
| General |
| ||||||
| Concepts |
| ||||||
| Programming languages | |||||||
| Application | |||||||
| Hardware | |||||||
| Software library |
| ||||||
| Implementation |
| ||||||
| People |
| ||||||
| Organizations |
| ||||||
| Architectures |
| ||||||
| |||||||