Alphabet
An alphabet is a standardized set of basic written symbols or graphemes (called letters) that represent the phonemes of certain spoken languages.[2] Not all writing systems represent language in this way; in a syllabary, each character represents a syllable, for instance, and logographic systems use characters to represent words, morphemes, or other semantic units.[3][4]


The first fully phonemic script, the Proto-Canaanite script, later known as the Phoenician alphabet, is considered to be the first alphabet and is the ancestor of most modern alphabets, including Arabic, Cyrillic, Greek, Hebrew, Latin, and possibly Brahmic.[5][6] It was created by Semitic-speaking workers and slaves in the Sinai Peninsula (as the Proto-Sinaitic script), by selecting a small number of hieroglyphs commonly seen in their Egyptian surroundings to describe the sounds, as opposed to the semantic values, of the Canaanite language.[7][8] However, Peter T. Daniels distinguishes an abugida, or alphasyllabary, a set of graphemes that represent consonantal base letters that diacritics modify to represent vowels (as in Devanagari and other South Asian scripts), an abjad, in which letters predominantly or exclusively represent consonants (as in the original Phoenician, Hebrew or Arabic), and an "alphabet", a set of graphemes that represent both consonants and vowels. In this narrow sense of the word, the first true alphabet was the Greek alphabet,[9][10] which was based on the earlier Phoenician alphabet.
Of the dozens of alphabets in use today, the most popular is the Latin alphabet,[11] which was derived from the Greek alphabet, and which is now used by many languages worldwide, often with the addition of extra letters or diacritical marks. While most alphabets have letters composed of lines (linear writing), there are also exceptions such as the alphabets used in Braille. The Khmer alphabet (for Khmer) is the longest, with 74 letters.[12]
Alphabets are usually associated with a standard ordering of letters. This makes them useful for purposes of collation, specifically by allowing words to be sorted in alphabetical order. It also means that their letters can be used as an alternative method of "numbering" ordered items, in such contexts as numbered lists and number placements.
Etymology
The English word alphabet came into Middle English from the Late Latin word alphabetum, which in turn originated in the Greek ἀλφάβητος (alphabētos), was made from the first two letters, alpha (α) and beta (β).[13] The names for the Greek letters came from the first two letters of the Phoenician alphabet; aleph, which also meant ox, and bet, which also meant house.
Sometimes, like in the alphabet song in English, the term "ABCs" is used instead of the word "alphabet." "Knowing one's ABCs" is used as a metaphor for knowing the basics about anything.
History

Ancient Northeast African and Middle Eastern scripts
The history of the alphabet started in ancient Egypt. Egyptian writing had a set of some 24 hieroglyphs that are called uniliterals,[14] representing syllables that begin with a single consonant of their language, plus a vowel (or no vowel) to be supplied by the native speaker. These glyphs were used as pronunciation guides for logograms, to write grammatical inflections, and, later, to transcribe loan words and foreign names.[15]
In the Middle Bronze Age, an apparently "alphabetic" system known as the Proto-Sinaitic script appeared in Egyptian turquoise mines in the Sinai peninsula dated to circa the 15th century BC, apparently left by Canaanite workers. In 1999, John and Deborah Darnell discovered an earlier version of this first alphabet at Wadi el-Hol. Dating to circa 1800 BC and showing evidence of having been adapted from specific forms of Egyptian hieroglyphs that could be dated to circa 2000 BC, strongly suggesting that the first alphabet had developed about that time.[16] Based on letter appearances and names, believed to be based on Egyptian hieroglyphs.[5] This script had no characters representing vowels. Originally, it probably was a syllabary, with symbols that were not needed being removed. An alphabetic cuneiform script with 30 signs, including three that indicate the following vowel invented in Ugarit before the 15th century BC. This script was not used after the destruction of Ugarit.[17]
The Proto-Sinaitic script eventually developed into the Phoenician alphabet, conventionally called "Proto-Canaanite" before c. 1050 BC.[6] The oldest text in Phoenician script is an inscription on the sarcophagus of King Ahiram. This script is the parent script of all western alphabets. By the tenth century, two other forms distinguish themselves, Canaanite and Aramaic. The Aramaic gave rise to the Hebrew script.[18] The South Arabian alphabet, a sister script to the Phoenician alphabet, is the script from which the Ge'ez alphabet (an abugida) descended. Vowelless alphabets are called abjads, currently exemplified in others such as, Arabic, Hebrew, and Syriac. The omission of vowels was not always a satisfactory solution, and some "weak" consonants sometimes being used to indicate the vowel quality of a syllable (matres lectionis). These letters have a dual function since they can also be used as pure consonants.[19]
The Proto-Sinaitic or Proto-Canaanite script and the Ugaritic script were the first scripts with a limited number of signs, in contrast to the other widely used writing systems at the time, Cuneiform, Egyptian hieroglyphs, and Linear B. The Phoenician script was probably the first phonemic script,[5][6] and it contained only about two dozen distinct letters, making it a script simple enough for traders to learn. Another advantage of Phoenician was that it could write different languages since it recorded words phonemically.
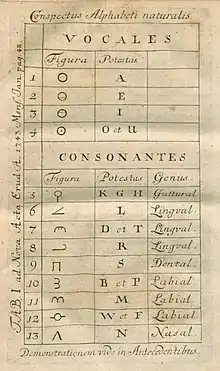
The script was spread across the Mediterranean by the Phoenicians.[6] In Greece, they added vowels to the alphabet, giving rise to the ancestor of all alphabets in the West. It was the first alphabet in which vowels have independent letter forms separate from those of consonants. The Greeks chose letters representing sounds that did not exist in Greek to represent vowels. Vowels are significant in the Greek language. The syllabical Linear B script that was used by the Mycenaean Greeks from the 16th century BC had 87 symbols, including five vowels. In its early years, there were many variants of the Greek alphabet, a situation that caused many different alphabets to evolve from it.
European alphabets

The Greek alphabet, in Euboean form, was carried over by Greek colonists to the Italian peninsula, giving rise to many different alphabets used to write the Italic languages. One of these became the Latin alphabet, which spread across Europe as the Romans expanded their empire. Even after the fall of the Roman state, the alphabet survived in intellectual and religious works. It eventually became used for the descendant languages of Latin (the Romance languages) and most of the other languages of western and central Europe.
Some adaptations of the Latin alphabet have ligatures, such as æ in Danish and Icelandic and Ȣ in Algonquian; borrowings from other alphabets, such as the thorn þ in Old English and Icelandic, which came from the Futhark runes; and modified existing letters, such as the eth ð of Old English and Icelandic, which is a modified d. Other alphabets only use a subset of the Latin alphabet, such as Hawaiian, and Italian, which uses the letters j, k, x, y, and w only in foreign words.
Another notable script is Elder Futhark, believed to have evolved out of one of the Old Italic alphabets. Elder Futhark gave rise to other alphabets known collectively as the Runic alphabets. The Runic alphabets were used for Germanic languages from AD 100 to the late Middle Ages being engraved on stone and jewelry, although inscriptions found on bone and wood occasionally appear. These alphabets have since gotten replaced with the Latin alphabet. The exception being for decorative use, where the runes remained in use until the 20th century.
The Old Hungarian script was the writing system of the Hungarians. It was in use during the entire history of Hungary, albeit not as an official writing system. From the 19th century, it once again became more and more popular.
The Glagolitic alphabet was the initial script of the liturgical language Old Church Slavonic and became, together with the Greek uncial script, the basis of the Cyrillic script. Cyrillic is one of the most widely used modern alphabetic scripts, and is notable for its use in Slavic languages and also for other languages within the former Soviet Union. Cyrillic alphabets include Serbian, Macedonian, Bulgarian, Russian, Belarusian, and Ukrainian. The Glagolitic alphabet believed to have been created by Saints Cyril and Methodius, while the Cyrillic alphabet was invented by Clement of Ohrid, their disciple. They feature many letters that appear to have been borrowed from or influenced by Greek and Hebrew.
The European alphabet with the most letters is the Latin-derived Slovak alphabet, which has 46 letters.
Asian alphabets
Beyond the logographic Chinese writing, many phonetic scripts exist in Asia. The Arabic alphabet, Hebrew alphabet, Syriac alphabet, and other abjads of the Middle East are developments of the Aramaic alphabet.
Most alphabetic scripts of India and Eastern Asia descend from the Brahmi script, believed to be a descendant of Aramaic.

In Korea, Sejong the Great created the Hangul alphabet [20] Hangul is a unique alphabet: it is a featural alphabet, where design of many of the letters comes from a sound's place of articulation (P to look like the widened mouth, L to look like the tongue pulled in); creation of Hangul was planned by the government of the day; and it places individual letters in syllable clusters with equal dimensions, in the same way as Chinese characters, to allow for mixed-script writing[21] (one syllable always takes up one type-space no matter how many letters get stacked into building that one sound-block).
Zhuyin (sometimes called Bopomofo) is a semi-syllabary. It transcribes Mandarin phonetically in the Republic of China. After the later establishment of the People's Republic of China and its adoption of Hanyu Pinyin, the use of Zhuyin today is limited. However, it is still widely used in Taiwan, where the Republic of China governs. Zhuyin developed from a form of Chinese shorthand based on Chinese characters in the early 1900s and has elements of both an alphabet and a syllabary. Like an alphabet, the phonemes of syllable initials get represented by individual symbols, but like a syllabary, the phonemes of the syllable finals are not; each possible final (excluding the medial glide) has its own character, an example being, luan written as ㄌㄨㄢ (l-u-an). The last symbol ㄢ takes place as the entire final -an. While Zhuyin is not a mainstream writing system, it is still often used in ways similar to a romanization system, for aiding pronunciation and as an input method for Chinese characters on computers and cellphones.
European alphabets, especially Latin and Cyrillic, have been adapted for many languages of Asia. Arabic is also widely used, sometimes as an abjad (as with Urdu and Persian) and sometimes as a complete alphabet (as with Kurdish and Uyghur).
Types

The term "alphabet" gets used by linguists and paleographers in both a wide and a narrow sense. In a larger sense, an alphabet is a segmental script at the phoneme level—that is, it has separate glyphs for individual sounds and not for larger units such as syllables or words. In the narrower sense, some scholars distinguish "true" alphabets from two other types of segmental script, abjads, and abugidas. These three differ in how they treat vowels. Abjads have letters for consonants and leave most vowels unexpressed. Abugidas are also consonant-based but indicate vowels with diacritics, a systematic graphic modification of the consonants. In alphabets in the narrow sense, on the other hand, consonants and vowels are written as independent letters.[22] The earliest known alphabet in the wider sense is the Wadi el-Hol script, believed to be an abjad. Its successor, Phoenician is the ancestor of modern alphabets, including Arabic, Greek, Latin (via the Old Italic alphabet), Cyrillic (via the Greek alphabet), and Hebrew (via Aramaic).
Examples of present-day abjads are the Arabic and Hebrew scripts; true alphabets include Latin, Cyrillic, and Korean hangul; and abugidas, used to write Tigrinya, Amharic, Hindi, and Thai. The Canadian Aboriginal syllabics are also an abugida rather than a syllabary as their name would imply, because each glyph stands for a consonant and is modified by rotation to represent the following vowel. (In a true syllabary, each consonant-vowel combination gets represented by a separate glyph.)
All three types may be augmented with syllabic glyphs. Ugaritic, for example, is basically an abjad but has syllabic letters for /ʔa, ʔi, ʔu/. (These are the only times that vowels are indicated.) Coptic has a letter for /ti/. Devanagari is typically an abugida augmented with dedicated letters for initial vowels, though some traditions use अ as a zero consonant as the graphic base for such vowels.
The boundaries between the three types of segmental scripts are not always clear-cut. For example, Sorani Kurdish is written in the Arabic script, which when used for other languages is an abjad. In Kurdish, writing the vowels is mandatory, and whole letters get used, so the script is a true alphabet. Other languages may use a Semitic abjad with forced vowel diacritics, effectively making them abugidas. On the other hand, the Phagspa script of the Mongol Empire was based closely on the Tibetan abugida, but vowel marks are written after the preceding consonant rather than as diacritic marks. Although short a not getting written, as in the Indic abugidas, one could argue that the linear arrangement made this a true alphabet. Ironically, the original source of the term "abugida", namely the Ge'ez abugida now used for Amharic and Tigrinya, has assimilated into their consonant modifications. It is now no longer systematic and must be learned as a syllabary rather than as a segmental script. Even more extreme, the Pahlavi abjad eventually became logographic. (See below.)
%252C_15th_century_(The_S.S._Teacher's_Edition-The_Holy_Bible_-_Plate_XII%252C_1).jpg.webp)
Thus the primary classification of alphabets reflects how they treat vowels. For tonal languages, further classification can be based on their treatment of tone, though names do not yet exist to distinguish the various types. Some alphabets disregard tone entirely, especially when it does not carry a heavy functional load, as in Somali and many other languages of Africa and the Americas. Such scripts are to tone what abjads are to vowels. Most commonly, tones are indicated with diacritics, the way vowels are treated in abugidas. This is the case for Vietnamese (a true alphabet) and Thai (an abugida). In Thai, the tone is determined primarily by the choice of consonant, with diacritics for disambiguation. In the Pollard script, an abugida, vowels are indicated by diacritics, but the placement of the diacritic relative to the consonant is modified to indicate the tone. More rarely, a script may have separate letters for tones, as is the case for Hmong and Zhuang. For many, regardless of whether letters or diacritics get used, the most common tone is not marked, just as the most common vowel is not marked in Indic abugidas. In Zhuyin not only is one of the tones unmarked but there is a diacritic to indicate lack of tone, like the virama of Indic.
Size
The number of letters in an alphabet can be quite small. The Book Pahlavi script, an abjad, had only twelve letters at one point, and may have had even fewer later on. Today the Rotokas alphabet has only twelve letters. (The Hawaiian alphabet is sometimes claimed to be as small, but it actually consists of 18 letters, including the ʻokina and five long vowels. However, Hawaiian Braille has only 13 letters.) While Rotokas has a small alphabet because it has few phonemes to represent (just eleven), Book Pahlavi was small because many letters had been conflated—that is, the graphic distinctions had been lost over time, and diacritics were not developed to compensate for this as they were in Arabic, another script that lost many of its distinct letter shapes. For example, a comma-shaped letter represented g, d, y, k, or j. However, such apparent simplifications can perversely make a script more complicated. In later Pahlavi papyri, up to half of the remaining graphic distinctions of these twelve letters were lost, and the script could no longer be read as a sequence of letters at all, but instead each word had to be learned as a whole—that is, they had become logograms as in Egyptian Demotic. Moreover, spellings of some words were heterograms, that is, those spellings did not reflect pronunciation of those words in Pahlavi but instead reflected their Aramaic equivalents used as logograms (as English e. g. for for example, from Latin exempli gratia).

The largest segmental script is probably an abugida, Devanagari. When written in Devanagari, Vedic Sanskrit has an alphabet of 53 letters, including the visarga mark for final aspiration and special letters for kš and jñ, though one of the letters is theoretical and not actually used. The Hindi alphabet must represent both Sanskrit and modern vocabulary, and so has been expanded to 58 with the khutma letters (letters with a dot added) to represent sounds from Persian and English. Thai has a total of 59 symbols, consisting of 44 consonants, 13 vowels and 2 syllabics, not including 4 diacritics for tone marks and one for vowel length.
The largest known abjad is Sindhi, with 52 letters. The largest alphabets in the narrow sense include Abkhaz and Kabardian (for Cyrillic), with 62 and 60 letters, respectively, and Slovak (for the Latin script), with 46. However, these scripts either count di- and tri-graphs as separate letters, as Spanish did with ch and ll until recently, or uses diacritics like Slovak č.

The Georgian alphabet is an alphabetic writing system. The modern Georgian alphabet has 33 letters. The original Georgian alphabet had 38 letters but 5 letters were removed in the 19th century by Ilia Chavchavadze.
The Armenian alphabet is a graphically unique alphabetical writing system that has been used to write the Armenian language. It was created in year 405 A.D. originally contained 36 letters. Two more letters, օ (o) and ֆ (f), were added in the Middle Ages. During the 1920s orthography reform, a new letter և (capital ԵՎ) was added, which was a ligature before ե+ւ, while the letter Ւ ւ was discarded and reintroduced as part of a new letter ՈՒ ու (which was a digraph before).
Syllabaries typically contain 50 to 400 glyphs, and the glyphs of logographic systems typically number from the many hundreds into the thousands. Thus a simple count of the number of distinct symbols is an important clue to the nature of an unknown script.
Alphabetical order
Alphabets often come to be associated with a standard ordering of their letters, which can then be used for purposes of collation—namely for the listing of words and other items in what is called alphabetical order.
The basic ordering of the Latin alphabet (A B C D E F G H I J K L M N O P Q R S T U V W X Y Z), which is derived from the Northwest Semitic "Abgad" order,[23] is well established, although languages using this alphabet have different conventions for their treatment of modified letters (such as the French é, à, and ô) and of certain combinations of letters (multigraphs). In French, these are not considered to be additional letters for the purposes of collation. However, in Icelandic, the accented letters such as á, í, and ö are considered distinct letters representing different vowel sounds from the sounds represented by their unaccented counterparts. In Spanish, ñ is considered a separate letter, but accented vowels such as á and é are not. The ll and ch were also considered single letters, but in 1994 the tenth congress of the Association of Spanish Language Academies changed the collating order so that ll is between lk and lm in the dictionary and ch is between cg and ci, and in 2010 the Real Academia Española changed it so they were no longer letters at all.[24][25]
In German, words starting with sch- (which spells the German phoneme /ʃ/) are inserted between words with initial sca- and sci- (all incidentally loanwords) instead of appearing after initial sz, as though it were a single letter—in contrast to several languages such as Albanian, in which dh-, ë-, gj-, ll-, rr-, th-, xh- and zh- (all representing phonemes and considered separate single letters) would follow the letters d, e, g, l, n, r, t, x and z respectively, as well as Hungarian and Welsh. Further, German words with an umlaut are collated ignoring the umlaut—contrary to Turkish that adopted the graphemes ö and ü, and where a word like tüfek, would come after tuz, in the dictionary. An exception is the German telephone directory where umlauts are sorted like ä = ae since names such as Jäger also appear with the spelling Jaeger, and are not distinguished in the spoken language.
The Danish and Norwegian alphabets end with æ—ø—å, whereas the Swedish and Finnish ones conventionally put å—ä—ö at the end.
It is unknown whether the earliest alphabets had a defined sequence. Some alphabets today, such as the Hanuno'o script, are learned one letter at a time, in no particular order, and are not used for collation where a definite order is required. However, a dozen Ugaritic tablets from the fourteenth century BC preserve the alphabet in two sequences. One, the ABCDE order later used in Phoenician, has continued with minor changes in Hebrew, Greek, Armenian, Gothic, Cyrillic, and Latin; the other, HMĦLQ, was used in southern Arabia and is preserved today in Ethiopic.[26] Both orders have therefore been stable for at least 3000 years.
Runic used an unrelated Futhark sequence, which was later simplified. Arabic uses its own sequence, although Arabic retains the traditional abjadi order for numbering.
The Brahmic family of alphabets used in India use a unique order based on phonology: The letters are arranged according to how and where they are produced in the mouth. This organization is used in Southeast Asia, Tibet, Korean hangul, and even Japanese kana, which is not an alphabet.
Names of letters
The Phoenician letter names, in which each letter was associated with a word that begins with that sound (acrophony), continue to be used to varying degrees in Samaritan, Aramaic, Syriac, Hebrew, Greek and Arabic.
The names were abandoned in Latin, which instead referred to the letters by adding a vowel (usually e) before or after the consonant; the two exceptions were Y and Z, which were borrowed from the Greek alphabet rather than Etruscan, and were known as Y Graeca "Greek Y" (pronounced I Graeca "Greek I") and zeta (from Greek)—this discrepancy was inherited by many European languages, as in the term zed for Z in all forms of English other than American English. Over time names sometimes shifted or were added, as in double U for W ("double V" in French), the English name for Y, and American zee for Z. Comparing names in English and French gives a clear reflection of the Great Vowel Shift: A, B, C and D are pronounced /eɪ, biː, siː, diː/ in today's English, but in contemporary French they are /a, be, se, de/. The French names (from which the English names are derived) preserve the qualities of the English vowels from before the Great Vowel Shift. By contrast, the names of F, L, M, N and S (/ɛf, ɛl, ɛm, ɛn, ɛs/) remain the same in both languages, because "short" vowels were largely unaffected by the Shift.
In Cyrillic originally the letters were given names based on Slavic words; this was later abandoned as well in favor of a system similar to that used in Latin.
Letters of Armenian alphabet also have distinct letter names.
Orthography and pronunciation
When an alphabet is adopted or developed to represent a given language, an orthography generally comes into being, providing rules for the spelling of words in that language. In accordance with the principle on which alphabets are based, these rules will generally map letters of the alphabet to the phonemes (significant sounds) of the spoken language. In a perfectly phonemic orthography there would be a consistent one-to-one correspondence between the letters and the phonemes, so that a writer could predict the spelling of a word given its pronunciation, and a speaker would always know the pronunciation of a word given its spelling, and vice versa. However, this ideal is not usually achieved in practice; some languages (such as Spanish and Finnish) come close to it, while others (such as English) deviate from it to a much larger degree.
The pronunciation of a language often evolves independently of its writing system, and writing systems have been borrowed for languages they were not designed for, so the degree to which letters of an alphabet correspond to phonemes of a language varies greatly from one language to another and even within a single language.
Languages may fail to achieve a one-to-one correspondence between letters and sounds in any of several ways:
- A language may represent a given phoneme by a combination of letters rather than just a single letter. Two-letter combinations are called digraphs and three-letter groups are called trigraphs. German uses the tetragraphs (four letters) "tsch" for the phoneme German pronunciation: [tʃ] and (in a few borrowed words) "dsch" for [dʒ]. Kabardian also uses a tetragraph for one of its phonemes, namely "кхъу". Two letters representing one sound occur in several instances in Hungarian as well (where, for instance, cs stands for [tʃ], sz for [s], zs for [ʒ], dzs for [dʒ]).
- A language may represent the same phoneme with two or more different letters or combinations of letters. An example is modern Greek which may write the phoneme Greek pronunciation: [i] in six different ways: ⟨ι⟩, ⟨η⟩, ⟨υ⟩, ⟨ει⟩, ⟨οι⟩, and ⟨υι⟩ (though the last is rare).
- A language may spell some words with unpronounced letters that exist for historical or other reasons. For example, the spelling of the Thai word for "beer" [เบียร์] retains a letter for the final consonant "r" present in the English word it was borrowed from, but silences it.
- Pronunciation of individual words may change according to the presence of surrounding words in a sentence (sandhi).
- Different dialects of a language may use different phonemes for the same word.
- A language may use different sets of symbols or different rules for distinct sets of vocabulary items, such as the Japanese hiragana and katakana syllabaries, or the various rules in English for spelling words from Latin and Greek, or the original Germanic vocabulary.
National languages sometimes elect to address the problem of dialects by simply associating the alphabet with the national standard. Some national languages like Finnish, Armenian, Turkish, Russian, Serbo-Croatian (Serbian, Croatian and Bosnian) and Bulgarian have a very regular spelling system with a nearly one-to-one correspondence between letters and phonemes. Strictly speaking, these national languages lack a word corresponding to the verb "to spell" (meaning to split a word into its letters), the closest match being a verb meaning to split a word into its syllables. Similarly, the Italian verb corresponding to 'spell (out)', compitare, is unknown to many Italians because spelling is usually trivial, as Italian spelling is highly phonemic. In standard Spanish, one can tell the pronunciation of a word from its spelling, but not vice versa, as certain phonemes can be represented in more than one way, but a given letter is consistently pronounced. French, with its silent letters and its heavy use of nasal vowels and elision, may seem to lack much correspondence between spelling and pronunciation, but its rules on pronunciation, though complex, are actually consistent and predictable with a fair degree of accuracy.
At the other extreme are languages such as English, where the pronunciations of many words simply have to be memorized as they do not correspond to the spelling in a consistent way. For English, this is partly because the Great Vowel Shift occurred after the orthography was established, and because English has acquired a large number of loanwords at different times, retaining their original spelling at varying levels. Even English has general, albeit complex, rules that predict pronunciation from spelling, and these rules are successful most of the time; rules to predict spelling from the pronunciation have a higher failure rate.
Sometimes, countries have the written language undergo a spelling reform to realign the writing with the contemporary spoken language. These can range from simple spelling changes and word forms to switching the entire writing system itself, as when Turkey switched from the Arabic alphabet to a Latin-based Turkish alphabet, and as when Kazakh changes from an Arabic script to a Cyrillic script due to the Soviet Union's influence, and in 2021, having a transition to the Latin alphabet, just like Turkish. The Cyrillic script used to be official in Uzbekistan and Turkmenistan before they all switched to the Latin alphabets, including Uzbekistan that is having a reform of the alphabet to use diacritics on the letters that is marked by apostrophes and the letters that are digraphs.
The standard system of symbols used by linguists to represent sounds in any language, independently of orthography, is called the International Phonetic Alphabet.
See also
- A Is For Aardvark
- Abecedarium
- Acrophony
- Akshara
- Alphabet book
- Alphabet effect
- Alphabet song
- Alphabetical order
- Butterfly Alphabet
- Character encoding
- Constructed script
- Cyrillic
- English alphabet
- Hangul
- ICAO (NATO) spelling alphabet
- Lipogram
- List of writing systems
- Pangram
- Thai script
- Thoth
- Transliteration
- Unicode
References
- Edwin JEANS (1860). A Catalogue of Books, in all Branches of Literature, both Ancient & Modern ... on sale at E. Jeans's, bookseller ... Norwich. J. Fletcher. pp. 33–.
- Pulgram, Ernst (1951). "Phoneme and Grapheme: A Parallel". WORD. 7 (1): 15–20. doi:10.1080/00437956.1951.11659389. ISSN 0043-7956.
- Daniels & Bright 1996, p. 4
- Taylor, Insup (1980), Kolers, Paul A.; Wrolstad, Merald E.; Bouma, Herman (eds.), "The Korean writing system: An alphabet? A syllabary? a logography?", Processing of Visible Language, Boston, MA: Springer US, pp. 67–82, doi:10.1007/978-1-4684-1068-6_5, ISBN 978-1-4684-1070-9, retrieved 19 June 2021
- Coulmas 1989, pp. 140–141
- Daniels & Bright 1996, pp. 92–96
- Goldwasser, O. (2012). "The Miners that Invented the Alphabet - a Response to Christopher Rollston". Journal of Ancient Egyptian Interconnections. 4 (3): 9–22. doi:10.2458/azu_jaei_v04i3_goldwasser.
- Goldwasser, O. (2010). "How the Alphabet was Born from Hieroglyphs". Biblical Archaeology Review. 36 (2): 40–53.
- Coulmas, Florian (1996). The Blackwell Encyclopedia of Writing Systems. Oxford: Blackwell Publishing. ISBN 978-0-631-21481-6.
- Millard 1986, p. 396
- Haarmann 2004, p. 96
- "What Language Has the Largest Alphabet?". 26 December 2014.
Languages like Chinese, technically, do not use an alphabet but have an ideographic writing system. There are thousands of symbols (pictographs) in Chinese representing different words, syllables and concepts. [..] The language with the most letters is Khmer, with 74 (including some without any current use). According to the Guinness Book of World Records, 1995, the Khmer alphabet is the largest alphabet in the world. It consists of 33 consonants, 23 vowels and 12 independent vowels.
- "alphabet". Merriam-Webster.com.
- Lynn, Bernadette (8 April 2004). "The Development of the Western Alphabet". h2g2. BBC. Retrieved 4 August 2008.
- Daniels & Bright 1996, pp. 74–75
- Darnell, J. C.; Dobbs-Allsopp, F. W.; Lundberg, Marilyn J.; McCarter, P. Kyle; Zuckerman, Bruce; Manassa, Colleen (2005). "Two Early Alphabetic Inscriptions from the Wadi el-Ḥôl: New Evidence for the Origin of the Alphabet from the Western Desert of Egypt". The Annual of the American Schools of Oriental Research. 59: 63, 65, 67–71, 73–113, 115–124. JSTOR 3768583.
- Ugaritic Writing online
- Coulmas 1989, p. 142
- Coulmas 1989, p. 147
- "上親制諺文二十八字...是謂訓民正音(His majesty created 28 characters himself... It is Hunminjeongeum (original name for Hangul))", 《세종실록 (The Annals of the Choson Dynasty : Sejong)》 25년 12월.
- Kuiwon (16 October 2013). "On Hangul Supremacy & Exclusivity—Mixed Script Predates the Japanese Colonial Period". kuiwon.wordpress.com. Archived from the original on 21 November 2018. Retrieved 5 March 2015.
- For critics of the abjad-abugida-alphabet distinction, see Reinhard G. Lehmann: "27-30-22-26. How Many Letters Needs an Alphabet? The Case of Semitic", in: The idea of writing: Writing across borders / edited by Alex de Voogt and Joachim Friedrich Quack, Leiden: Brill 2012, p. 11-52, esp p. 22-27
- Reinhard G. Lehmann: "27-30-22-26. How Many Letters Needs an Alphabet? The Case of Semitic", in: The idea of writing: Writing across borders / edited by Alex de Voogt and Joachim Friedrich Quack, Leiden: Brill 2012, p. 11-52
- Real Academia Española. Exclusión de «ch» y «ll» del abecedario.
- "La 'i griega' se llamará 'ye'". Cuba Debate. 2010-11-05. Retrieved 12 December 2010. Cubadebate.cu
- Millard 1986, p. 395
Bibliography
- Coulmas, Florian (1989). The Writing Systems of the World. Blackwell Publishers Ltd. ISBN 978-0-631-18028-9.
- Daniels, Peter T.; Bright, William (1996). The World's Writing Systems. Oxford University Press. ISBN 978-0-19-507993-7. Overview of modern and some ancient writing systems.
- Driver, G. R. (1976). Semitic Writing (Schweich Lectures on Biblical Archaeology S.) 3Rev Ed. Oxford University Press. ISBN 978-0-19-725917-7.
- Haarmann, Harald (2004). Geschichte der Schrift [History of Writing] (in German) (2nd ed.). München: C. H. Beck. ISBN 978-3-406-47998-4.
- Hoffman, Joel M. (2004). In the Beginning: A Short History of the Hebrew Language. NYU Press. ISBN 978-0-8147-3654-8. Chapter 3 traces and summarizes the invention of alphabetic writing.
- Logan, Robert K. (2004). The Alphabet Effect: A Media Ecology Understanding of the Making of Western Civilization. Hampton Press. ISBN 978-1-57273-523-1.
- McLuhan, Marshall; Logan, Robert K. (1977). "Alphabet, Mother of Invention". ETC: A Review of General Semantics. 34 (4): 373–383. JSTOR 42575278.
- Millard, A. R. (1986). "The Infancy of the Alphabet". World Archaeology. 17 (3): 390–398. doi:10.1080/00438243.1986.9979978. JSTOR 124703.
- Ouaknin, Marc-Alain; Bacon, Josephine (1999). Mysteries of the Alphabet: The Origins of Writing. Abbeville Press. ISBN 978-0-7892-0521-6.
- Powell, Barry (1991). Homer and the Origin of the Greek Alphabet. Cambridge University Press. ISBN 978-0-521-58907-9.
- Powell, Barry B. (2009). Writing: Theory and History of the Technology of Civilization. Oxford: Blackwell. ISBN 978-1-4051-6256-2.
- Sacks, David (2004). Letter Perfect: The Marvelous History of Our Alphabet from A to Z. Broadway Books. ISBN 978-0-7679-1173-3.
- Saggs, H. W. F. (1991). Civilization Before Greece and Rome. Yale University Press. ISBN 978-0-300-05031-8. Chapter 4 traces the invention of writing
External links
- The Origins of abc
- "Language, Writing and Alphabet: An Interview with Christophe Rico", Damqātum 3 (2007)
- Michael Everson's Alphabets of Europe
- Evolution of alphabets, animation by Prof. Robert Fradkin at the University of Maryland
- How the Alphabet Was Born from Hieroglyphs—Biblical Archaeology Review
- An Early Hellenic Alphabet
- Museum of the Alphabet
- The Alphabet, BBC Radio 4 discussion with Eleanor Robson, Alan Millard and Rosalind Thomas (In Our Time, 18 Dec. 2003)