Equidad (aprendizaje automático)
En aprendizaje automático, un algoritmo es justo, o tiene equidad si sus resultados son independientes de un cierto conjunto de variables que consideramos sensibles y no relacionadas con él (p.e.: género, etnia, orientación sexual, etc.).
Contexto
Las investigaciones sobre equidad en algoritmos de aprendizaje automático son bastante recientes. Sin ir más lejos la mayoría de los artículos publicados sobre este tema son de los últimos tres años.[1] Algunos de los hechos más destacados en este ámbito han sido los siguientes:
- En 2018 IBM introduce AI Fairness 360, una librería de Python con diversos algoritmos para redurcir el sesgo algorítmico de un programa, aumentando así su equidad. [2]
- Facebook afirmó en 2018 que hace uso de una herramienta, Fairness Flow, que detecta sesgos en su IA. Sin embargo, no se puede acceder al código de dicha herramienta ni se sabe si realmente corrige estos sesgos. [3]
- En 2019, Google publica un conjunto de herramientas en Github para estudiar los efectos de la equidad a largo plazo. [4]
A pesar de que se siguen perfeccionando los algoritmos utilizados, los principales avances vienen de la concienciación por parte de algunas grandes empresas de la importancia que va a tener en la sociedad la reducción del sesgo en los algoritmos de aprendizaje automático en un futuro.
Criterios de equidad en problemas de clasificación[5]
En problemas de clasificación, un algoritmo aprende una función para predecir una característica discreta , la variable objetivo, a partir de unas características conocidas . Modelizamos como una variable aleatoria que codifica algunas características contenidas o implícitamente codificadas en que consideramos características protegidas (género, etnia, orientación sexual, etc.). Por último, denotamos por la predicción del clasificador. Ahora pasamos a definir tres criterios principales para evaluar si un clasificador es justo, es decir, si sus predicciones no están influenciadas por algunas de las variables protegidas.




Independencia
Decimos que las variables aleatorias satisfacen la independencia si las características protegidas son estadísticamente independientes a la predicción , y escribimos .


También podemos expresar esta noción con la siguiente fórmula:

Esto significa que la probabilidad de ser clasificado por el algoritmo en cada uno de los grupos es la misma para dos individuos con características protegidas distintas.
Se puede dar otra noción equivalente de independencia utilizando el concepto de información mutua entre variables aleatorias, definida como

En esta fórmula, es la entropía de la variable estadística. Entonces satisface independencia si .


Una posible relajación de la definición de independencia pasa por la introducción de una variable positiva , y viene dada por la fórmula:


Por último, otra posible relajación pasa por requerir .

Separación
Decimos que las variables aleatorias satisfacen la separación si las características protegidas son estadísticamente independientes a la predicción dado el valor objetivo , y escribimos .


También podemos expresar esta noción con la siguiente fórmula:

Esto significa que la probabilidad de ser clasificado por el algoritmo en cada uno de los grupos es la misma para dos individuos con características protegidas distintas dado que ambos pertenecen al mismo grupo (tienen la misma variable objetivo).
Otra expresión equivalente, en el caso de tener una variable objetivo binaria, es la que exige que la tasa de verdaderos positivos y la tasa de falsos positivos sean iguales (y por tanto la tasa de falsos negativos y la tasa de verdaderos negativos también lo sean) para cada valor de las características protegidas:


Por último, una posible relajación de las definiciones dadas es que la diferencia entre tasas sea un número positivo menor que una cierta variable , en lugar de igual a cero.
Suficiencia
Decimos que las variables aleatorias satisfacen la suficiencia si las características protegidas son estadísticamente independientes al valor objetivo dada la predicción , y escribimos .

También podemos expresar esta noción con la siguiente fórmula:

Esto significa que la probabilidad de estar en realidad en cada uno de los grupos es la misma para dos individuos con características protegidas distintas dado que la predicción los englobe en el mismo grupo.
Relaciones entre definiciones
Por último, resumimos algunos de los principales resultados que relacionan las tres definiciones dadas arriba:
- Si y no son estadísticamente independientes, entonces la suficiencia y la independencia no pueden darse a la vez.
- Asumiendo que es binaria, si y no son estadísticamente independientes, y y tampoco son estadísticamente independientes, entonces la independencia y la separación no pueden darse a la vez.
- Si como distribución conjunta tiene probabilidad positiva para todos sus posibles valores y y no son estadísticamente independientes, entonces la separación y la suficiencia no pueden darse a la vez.
Métricas [6]
La mayoría de medidas de equidad dependen de diferentes métricas, de modo que comenzaremos por definirlas. Cuando trabajamos con un clasificador binario, tanto la clase predicha por el algoritmo como la real pueden tomar dos valores: positivo y negativo. Empecemos ahora explicando las posibles relaciones entre el resultado predicho y el real:
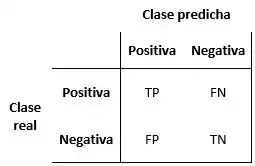
- Verdadero positivo (TP): Cuando el resultado predicho y el real pertenecen a la clase positiva.
- Verdadero negativo (TN): Cuando el resultado predicho y el real pertenecen a la clase negativa.
- Falso positivo (FP): Cuando el resultado predicho es positivo pero el real pertenece a la clase negativa.
- Falso negativo (FN): Cuando el resultado predicho es negativo pero el real pertenece a la clase positiva.
Estas relaciones pueden ser representadas fácilmente con una matriz de confusión, una tabla que describe la precisión de un modelo de clasificación. En esta matriz, las columnas y las filas representan instancias de las clases predichas y reales, respectivamente.
Utilizando estas relaciones, podemos definir múltiples métricas que podemos usar después para medir la equidad de un algoritmo:
- Valor predicho positivo (PPV): la fracción de casos positivos que han sido predichos correctamente de entre todas las predicciones positivas. Con frecuencia, se denomina como precisión, y representa la probabilidad de que una predicción positiva sea correcta. Viene dada por la siguiente fórmula:

- Tasa de descubrimiento de falsos (FDR): la fracción de predicciones positivas que eran en realidad negativas de entre todas las predicciones positivas. Representa la probabilidad de que una predicción positiva sea errónea, y viene dada por la siguiente fórmula:

- Valor predicho negativo (NPV): la fracción de casos negativos que han sido predichos correctamente de entre todas las predicciones negativas. Representa la probabilidad de que una predicción negativa sea correcta, y viene dada por la siguiente fórmula:

- Tasa de omisión de falsos (FOR): la fracción de predicciones negativas que eran en realidad positivas de entre todas las predicciones negativas. Representa la probabilidad de que una predicción negativa sea errónea, y viene dada por la siguiente fórmula:

- Tasa de verdaderos positivos (TPR): la fracción de casos positivos que han sido predichos correctamente de entre todos los casos positivos. Con frecuencia, se denomina como exhaustividad, y representa la probabilidad de que los sujetos positivos sean clasificados correctamente como tales. Viene dada por la fórmula:

- Tasa de falsos negativos (FNR): la fracción de casos positivos que han sido predichos de forma errónea como negativos de entre todos los casos positivos. Representa la probabilidad de que los sujetos positivos sean clasificados erróneamente como negativos, y viene dada por la fórmula:

- Tasa de verdaderos negativos (TNR): la fracción de casos negativos que han sido predichos correctamente de entre todos los casos negativos. Representa la probabilidad de que los sujetos negativos sean clasificados correctamente como tales, y viene dada por la fórmula:

- Tasa de falsos positivos (FPR): la fracción de casos negativos que han sido predichos de forma errónea como positivos de entre todos los casos negativos. Representa la probabilidad de que los sujetos negativos sean clasificados erróneamente como positivos, y viene dada por la fórmula:

Otros criterios de equidad
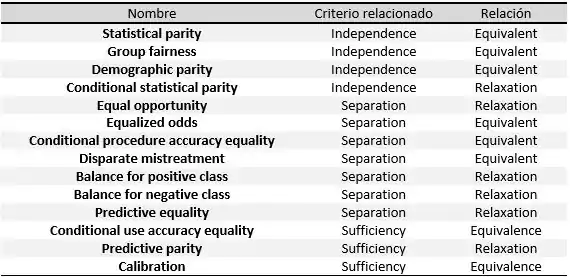
Los criterios siguientes se pueden entender como métricas de las tres definiciones dadas en la primera sección, o una relajación de las mismas. En la tabla [5] de la derecha podemos ver cómo se relacionan.
Para definir estas métricas específicamente, se dividen en tres grandes grupos como en el trabajo de Verma y otros.[6]: definiciones basadas en el resultado predicho, en el resultado predicho y el real, y definiciones basadas en las probabilidades predichas y el resultado real.
En la siguiente sección se trabaja con un clasificador binario y la siguiente notación: se refiere a la puntuación dada por el clasificador, la cual es la probabilidad que cierto sujeto se encuentre en la clase positiva o negativa. representa la clasificación final predicha por el algoritmo, y su valor es comúnmente derivado de , por ejemplo será positivo cuando esté por encima de cierto valor. representa el resultado real, es decir, la clasificación real del sujeto y, finalmente, denota las variables protegidas del sujeto.

Definiciones basadas en el resultado predicho
Las definiciones en estas secciones se centran en el resultado predicho para varias distribuciones de sujetos. Son las nociones más simples e intuitivas de equidad.
- Group fairness, también llamado statistical parity, demographic parity, acceptance rate y benchmarking. Un clasificador satisface esta definición si los sujetos en los grupos protegidos y en los no protegidos tienen la misma probabilidad de ser asignados a la clase positiva. Es decir, si se satisface la siguiente fórmula:

- Conditional statistical parity. Consiste básicamente en la definición anterior, pero restringida solo a un subconjunto de los atributos. En notación matemática:

Definiciones basadas en el resultado predicho y el real
Estas definiciones no sólo consideran el resultado predicho pero también lo comparan con el resultado real .
- Predictive parity, también llamado outcome test. Un clasificador satisface esta definición si los sujetos en los grupos protegidos y en los no protegidos tienen el mismo PPV. Es decir, si se satisface la siguiente fórmula:

- Matemáticamente, si un clasificador tiene el mismo PPV para ambos grupos, también tiene el mismo FDR, satisfaciendo la fórmula:

- False positive error rate balance, también llamado predictive equality. Un clasificador satisface esta definición si los sujetos en los grupos protegidos y en los no protegidos tienen el mismo FPR. Es decir, si se satisface la siguiente fórmula:

- Matemáticamente, si un clasificador tiene el mismo FPR para ambos grupos, también tiene el mismo TNR, satisfaciendo la fórmula:

- False negative error rate balance, también llamado equal opportunity. Un clasificador satisface esta definición si los sujetos en los grupos protegidos y en los no protegidos tienen el mismo FNR. Es decir, si se satisface la siguiente fórmula:

- Matemáticamente, si un clasificador tiene el mismo FNR para ambos grupos, también tiene el mismo TPR, satisfaciendo la fórmula:

- Equalized odds, también llamado conditional procedure accuracy equality and disparate mistreatment. Un clasificador satisface esta definición si los sujetos en los grupos protegidos y en los no protegidos tienen el mismo TPR y el mismo FPR, satisfaciendo la fórmula:

- Conditional use accuracy equality. Un clasificador satisface esta definición si los sujetos en los grupos protegidos y en los no protegidos tienen el mismo PPV y el mismo NPV, satisfaciendo la fórmula:

- Overall accuracy equality. Un clasificador satisface esta definición si los sujetos en los grupos protegidos y en los no protegidos tienen la misma precisión de predicción, es decir, la probabilidad de predecir correctamente a qué clase pertenece un sujeto. Es decir, si se satisface la siguiente fórmula:

- Treatment equality. Un clasificador satisface esta definición si los sujetos en los grupos protegidos y en los no protegidos tienen el mismo ratio de FN y FP, satisfaciendo la fórmula:

Definiciones basadas en las probabilidades predichas y el resultado real
Estas definiciones se basan en el resultado real y en la probabilidad predicha (la puntuación) .
- Test-fairness, también conocido como calibration o matching conditional frequencies. Un clasificador satisface esta definición si individuos con la misma puntuación tienen la misma probabilidad de ser clasificados en la clase positiva independientemente de si pertenecen a los grupos protegidos o no:

- Well-calibration. Es una extensión de la definición anterior. Añade que, cuando individuos dentro o fuera de los grupos protegidos tienen la misma puntuación deben tener la misma probabilidad de ser clasificados en la clase positiva, y esta probabilidad debe ser igual a :

- Balance for positive class. Un clasificador satisface esta definición si los individuos que constituyen la clase positiva pertenecientes tanto los grupos protegidos como de los no protegidos tienen la misma media de puntuación . Esto quiere decir que la esperanza de la puntuación para los grupos protegidos y los no protegidos con clase real positiva es la misma, satisfaciendo la fórmula:

- Balance for negative class. Un clasificador satisface esta definición si los individuos que constituyen la clase negativa pertenecientes tanto los grupos protegidos como de los no protegidos tienen la misma media de puntuación . Esto quiere decir que la esperanza de la puntuación para los grupos protegidos y los no protegidos con clase real negativa es la misma, satisfaciendo la fórmula:

Algoritmos
Se puede aplicar la equidad al aprendizaje automático desde tres perspectivas: pre-procesando los datos utilizados en el algoritmo, optimizando los objetivos durante el entrenamiento o procesando las respuestas tras la ejecución del algoritmo.
Preprocesamiento
Normalmente, el clasificador no es el único problema, el conjunto de datos también está sesgado. La discriminación de un conjunto de datos con respecto al grupo se puede definir como sigue:



Esto es, una aproximación de la diferencia entre las probabilidades de pertenecer a la clase positiva dado que el sujeto tiene una característica protegida distinta de a e igual a .

Los algoritmos que corrigen el sesgo mediante preprocesamiento intentan eliminar información sobre ciertos atributos de los datos que pueden provocar un comportamiento injusto de la IA, al mismo tiempo que tratan de alterar estos datos lo menos posible. Eliminar del conjunto de datos una variable protegida no es suficiente, ya que otras variables pueden estar correlacionadas con ella.
Una posible forma de hacerlo consiste en asociar cada individuo del conjunto de datos a una representación intermedia en la que sea imposible determinar si pertenece o no a un grupo protegido, a la vez que se mantiene el resto de la información tanto como sea posible. Después, se ajusta la nueva representación del conjunto de datos para buscando el máximo acierto del algoritmo.
De este modo, los individuos se vinculan a una nueva representación en la que la probabilidad de que un miembro de un grupo protegido sea asociado a cierto valor de la nueva representación es la misma que la de un individuo no protegido. Así, es la nueva representación la que se utiliza para obtener la predicción para el individuo en vez de los datos originales. Como la representación intermedia se ha construido dando la misma probabilidad a cada individuo independientemente de si pertenecen al grupo protegido o no, esto queda oculto para el clasificador.
Se puede encontrar un ejemplo en Zemel y otros [7] en el que se utiliza una variable aleatoria multinomial como representación intermedia. En el proceso, se preserva toda la información excepto la que pueda conducir a decisiones sesgadas a la vez que se busca una predicción lo más correcta que sea posible.
Por un lado, este procedimiento tiene la ventaja de que los datos preprocesados se pueden utilizar para cualquier tarea de aprendizaje automático. Además, no hay que modificar el código del clasificador, ya que la corrección se aplica a los datos que se van a introducir en él. Por otro lado, los otros métodos obtienen mejores resultados tanto en acierto como en equidad. [8]
Reweighing [9]
La técnica del reweighing, en español reasignación de pesos, es un ejemplo de algoritmo de preprocesamiento. La idea consiste en asignar un peso a cada punto del conjunto de datos de tal manera que la discriminación ponderada es 0 respecto al grupo de interés.
Si el conjunto de datos fuera no sesgado, la variable protegida y la variable objetivo serían estadísticamente independientes y la probabilidad de la distribución conjunta sería el producto de las probabilidades de la siguiente manera:

Sin embargo, en la vida real el conjunto de datos suele estar sesgado y las variables no son estadísticamente independientes por lo que la probabilidad observada es:

Para compensar el sesgo, se asignan mayores pesos a los puntos no favorecidos y menores a los favorecidos. Para cada obtenemos:


Una vez tenemos asignado a cada un peso asociado calculamos la discriminación ponderada con respecto al grupo de la siguiente manera:


Se puede demostrar que después de la asignación de los pesos la discriminación ponderada es 0.
Optimización durante el entrenamiento
Otra aproximación al problema es corregir el sesgo durante el entrenamiento. Esto puede hacerse añadiendo restricciones al objetivo del algoritmo.[10] Estas restricciones obligan al algoritmo a tener en cuenta la equidad, de forma que el máximo éxito no sea su único objetivo, sino también mantener ciertas métricas iguales tanto para el grupo protegido como para el resto de individuos. Por ejemplo, se puede añadir al algoritmo la condición de que la tasa de falsos positivos sea la misma para individuos del grupo protegido y para los que no lo son.
Las principales métricas que se utilizan en esta técnica son la tasa de falsos positivos, la tasa de falsos negativos y la tasa general de fallo. Es posible añadir sólo una o varias de estas restricciones al objetivo. Nótese que la igualdad de las tasas de falsos negativos implica la igualdad también de las tasas de verdaderos positivos, lo que significa igualdad de oportunidad. Tras añadir las restricciones al algoritmo, el problema puede volverse infactible y por tanto puede ser necesario relajarlas.
Esta técnica obtiene buenos resultados al mejorar la equidad, al mismo tiempo que mantiene una exactitud alta, y permite al programador elegir las métricas que mejor se ajusten a sus necesidades. Sin embargo, la técnica y las métricas utilizadas varían en función del problema y es necesario modificar el código del algoritmo, lo que no siempre es posible.[8]
Adversarial debiasing [11] [12]
Se entrenan dos clasificadores al mismo tiempo con algún método basado en el gradiente (p.e.: descenso de gradiente). El primero (el predictor) intenta resolver el problema de predecir la variable objetivo dada la entrada , modificando sus pesos para minimizar una función de pérdida . El segundo (el adversario) intenta resolver el problema de predecir la variable sensible , dado modificando sus pesos para minimizar otra función de pérdida .





Una puntualización importante es que, para que se propague correctamente, la variable de arriba debe referirse a la salida en bruto del clasificador y no a la salida discreta; por ejemplo, con una red neuronal artificial y un problema de clasificación , se podría referir a la salida de la capa softmax.
A continuación, actualizamos para minimizar en cada paso del entrenamiento según el gradiente y modificamos conforme a la expresión:



donde es un hiperparámetro a elegir que puede variar en cada paso.

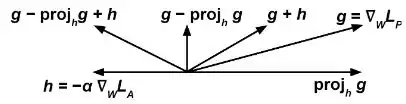
La idea intuitiva consiste en que el predictor intente minimizar ((y de ahí el término ) mientras, al mismo tiempo, maximice (y de ahí el término ), de tal manera que el adversario fracase al predecir la variable sensible a partir de .



El término evita que el predictor cambie de una forma que pueda ayudar al advesario disminuir su función de pérdida.

Se puede demostrar que entrenar un modelo de clasificación predictor con este algoritmo mejora la paridad demográfica con respecto a entrenarlo sin el adversario.
Post-procesamiento
La última técnica trata de corregir las respuestas del clasificador para alcanzar la equidad. En este método, necesitamos hacer una predicción binaria para los individuos y tenemos un clasificador que devuelve una puntuación asociada a cada uno de ellos. Los individuos con puntuaciones altas tenderán a obtener una respuesta positiva, mientras que aquellos con una puntuación baja tendrán una respuesta negativa, pero necesitamos determinar el umbral a partir del cual se responde positiva o negativamente. Nótese que variar el umbral afecta al compromiso entre la tasa de verdaderos positivos y la tasa de verdaderos negativos, y en función del problema nos puede interesar mejorar una a costa de la otra.
Si la función de puntuación es justa, en el sentido de que es independiente del atributo protegido, entonces cualquier elección del valor umbral será también justa, pero este tipo de clasificadores tienden a sesgarse con facilidad, por lo que puede que necesitemos especificar un umbral distinto para cada grupo protegido. Una forma de hacerlo es estudiar las gráficas de la tasa de verdaderos positivos frente a la de verdaderos negativos para distintos valores del umbral (a esto se le conoce como curva ROC) y comprobar para qué valor del umbral las tasas son iguales para el grupo protegido y para el resto de individuos.[13]
Entre las ventajas del post-procesamiento están que la técnica se puede aplicar después de usar cualquier clasificador, sin necesidad de modificarlo, y obtiene buenos resultados mejorando métricas de equidad. Entre los inconvenientes, es necesario consultar el valor del atributo protegido durante el post-procesamiento y se restringe la libertad del programador para regular el compromiso entre equidad y exactitud.[8]
Reject Option based Classification [14]
Dado un clasificador, sea la probabilidad calculada por este de que el sujeto pertenezca a la clase positiva. Cuando sea cercano a 1 o 0, el sujeto será clasificado, con un alto grado de seguridad, como perteneciente a la clase positiva o negativa respectivamente. Sin embargo, cuando está más próximo a 0.5 la clasificación no está clara.

Decimos que es un sujeto rechazado si con cierto tal que .



El algoritmo consiste en clasificar los sujetos no rechazados siguiendo la regla explicada al principio y los rechazados de la siguiente manera: si la instancia es un ejemplo de grupo desprivilegiado () entonces clasificarla como positivo, en el otro caso, clasificarla como negativo.

Podemos optimizar diferentes medidas de discriminación como funciones de para encontrar el óptimo para cada problema y evitar volvernos discriminatorios contra el grupo privilegiado.
Véase también
Referencias
- Moritz Hardt, Berkeley. Consultado el 18 de diciembre de 2019
- IBM AI Fairness 360 Archivado el 29 de junio de 2022 en Wayback Machine.. Consultado el 18 de diciembre de 2019
- Fairness Flow el detector de sesgos de Facebook. Consultado el 18 de diciembre de 2019
- ML-Fairness gym. Consultado el 18 de diciembre de 2019
- Solon Barocas; Moritz Hardt; Arvind Narayanan, Fairness and Machine Learning. Consultado el 15 de diciembre de 2019.
- Sahil Verma; Julia Rubin, Fairness Definitions Explained. Consultado el 15 de diciembre de 2019
- Richard Zemel; Yu (Ledell) Wu; Kevin Swersky; Toniann Pitassi; Cyntia Dwork, Learning Fair Representations. Consultado el 1 de Diciembre de 2019
- Ziyuan Zhong, Tutorial on Fairness in Machine Learning. Consultado el 1 de Diciembre de 2019
- Faisal Kamiran; Toon Calders, Data preprocessing techniques for classification without discrimination. Consultado el 17 de Diciembre de 2019
- Muhammad Bilal Zafar; Isabel Valera; Manuel Gómez Rodríguez; Krishna P. Gummadi, Fairness Beyond Disparate Treatment & Disparate Impact: Learning Classification without Disparate Mistreatment. Consultado el 1 de Diciembre de 2019
- Brian Hu Zhang; Blake Lemoine; Margaret Mitchell, Mitigating Unwanted Biases with Adversarial Learning. Consultado el 17 de diciembre de 2019
- Joyce Xu, Algorithmic Solutions to Algorithmic Bias: A Technical Guide. Consultado el 17 de diciembre de 2019
- Moritz Hardt; Eric Price; Nathan Srebro, Equality of Opportunity in Supervised Learning. Consultado el 1 de diciembre de 2019
- Faisal Kamiran; Asim Karim; Xiangliang Zhang, Decision Theory for Discrimination-aware Classification. Consultado el 17 de Diciembre de 2019
| Control de autoridades |
|
|---|
 Datos: Q80100972
Datos: Q80100972