Teoría de la resonancia adaptativa
La teoría de la resonancia adaptativa (en inglés: adaptive resonance theory, conocido por sus siglas inglesas ART), desarrollada por Stephen Grossberg y Gail Carpenter. Es un modelo de red neuronal artificial (RNA) que basa su funcionamiento en la manera en que el cerebro procesa información y que describe una serie de modelos de redes neuronales que utilizando métodos de aprendizaje supervisado y no supervisado abordan problemas tales como el reconocimiento y la predicción de patrones.
Dilema de la estabilidad y plasticidad del aprendizaje
Grossberg y Carpenter desarrollaron la teoría de la resonancia adaptativa en respuesta a este dilema, en el que se plantean las siguientes cuestiones:
- Plasticidad del aprendizaje: permite a una red neuronal poder aprender nuevos patrones.
- Estabilidad del aprendizaje: permite a una red neuronal poder retener los patrones aprendidos.
Conseguir que un modelo de RNA sea capaz de resolver uno solo de estos problemas es sencillo, el reto está en conseguir un modelo que sea capaz de dar respuesta a ambos. Las redes más conocidas, tales como el Perceptrón multicapa o el Adaline, son capaces de aprender como han de responder ante unos patrones de entrada pero, una vez entrenados, el intentar que aprendan nuevos patrones puede suponer el "olvido" de lo aprendido previamente.
Características
- El aprendizaje se produce mediante un mecanismo de realimentación creado por la competencia entre las neuronas de la capa de salida y la capa de entrada de la red.
- El aprendizaje es no supervisado, aunque existe una modalidad supervisada.
- La red crea su propia clasificación de lo que aprende.
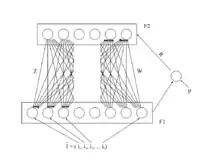
Arquitectura
Es una red formada por dos capas:
- Capa de entrada (F1): datos de entrada pasan a ser los valores de sus neuronas, en ella también se hace la comparación de similitud.
- Capa de salida (F2): es una capa de neuronas competitivas, o sea todas compiten para ser la ganadora, pero solo una puede ser la ganadora y esta inhibe a las demás.
- Parámetro de vigilancia (p): Dice cuan semejante debe ser la entrada con la categoría seleccionada. Este parámetro está dado por 0 < x > 1, si "x" es muy cercano a 0, muchas entradas serán categorizadas en una misma categoría, mientras si "x" en muy cercano a 1 se crearán muchas categorías (memorización)
- Sistema de orientación: Sirve para orientar la red, ya que las neuronas de ambas capas están totalmente interconectadas y hay una afluencia hacia adelante y hacia atrás.
- Sistema de reinicio: Sirve para inhibir la neurona ganadora cuando dicha no cumple con la vigilancia, en el proceso de comparación de similitud.
En algunos casos se puede agregar una capa más, para hacer preprocesamiento de los datos conocido como normalización de entradas, el cual puede consistir en agregarle a la entrada su complemento o dividir cada una de las entradas por su norma.
Concepto
El modelo ART soluciona el dilema de la estabilidad y plasticidad del aprendizaje mediante un mecanismo de realimentación entre las neuronas competitivas de la capa de salida.
Cuando a la red se le presenta un patrón de entrada este se hace resonar con los prototipos de las categorías conocidas por la red, si el patrón entra en resonancia con alguna clase entonces es asociado a esta y el centro de cluster es desplazado ligeramente para adaptarse mejor al nuevo patrón que le ha sido asignado. En caso contrario, si el patrón no entra en resonancia con ninguna clase, pueden suceder dos cosas: si la red posee una capa de salida estática entrará en saturación pues no puede crear una nueva clase para el patrón presentado pero tampoco puede asignarlo a una clase existente, si la red posee una capa de salida dinámica se creará una nueva clase para dicho patrón, esto no afectará a las clases ya existentes.
Funcionamiento general
En las redes ART existen dos tipos de pesos, los llamados W, que son pesos feedforward (alimentación hacia adelante) entre la capa de entrada y la capa de salida, y los llamados T, que son pesos feedback (alimentación hacia atrás ) entre la capa de salida y la capa de entrada.
Los pesos feedforward (W) son iguales que los pesos feedback (T), solo que estos están normalizados:

donde es un parámetro que toma generalmente el valor 0,5.

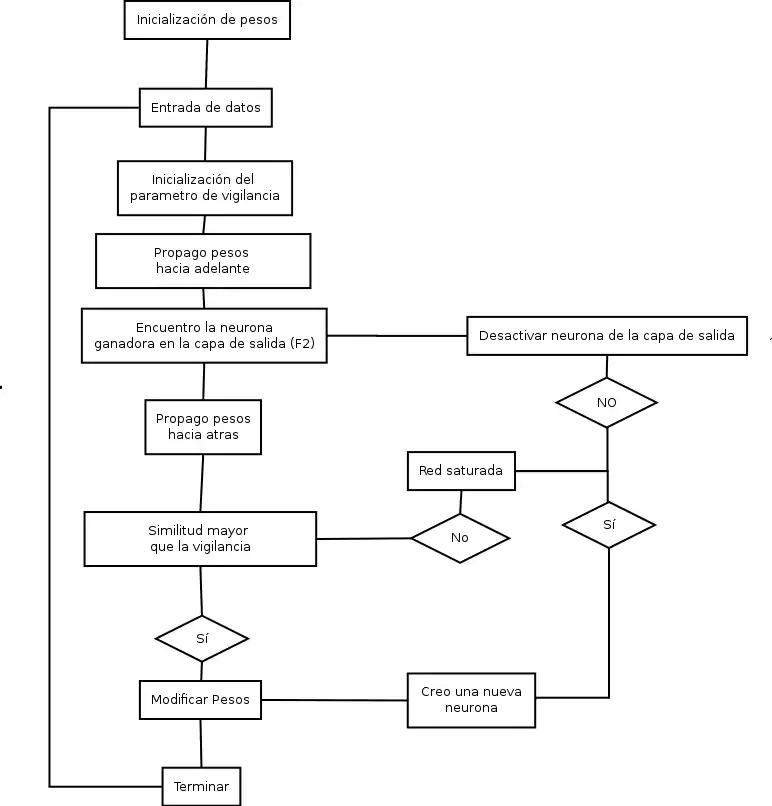
El funcionamiento de un modelo ART se divide en cuatro fases.
Fase de inicialización
Se inicializan los parámetros de la RNA y se establecen las señales de control.
Se inicializan los pesos de la siguiente manera:
- para conexiones hacia adelante, siendo el número de entradas a la RNA;
- para conexiones hacia atrás



Mediante las señales de control (ganancia y reinicio) se controla el flujo de datos a través de la RNA y se pasa a las distintas fases.
Fase de reconocimiento
En la fase de reconocimiento se efectúa una operación con los datos de entrada y los pesos W asociados a cada neurona de la capa de salida, el resultado de esta operación debe indicar qué clase tiene mayor prioridad para ver si los datos de entrada entran en resonancia con ella. Por ejemplo, se podría calcular la distancia euclídea entre los datos de entrada y los pesos W, la clase ganadora sería aquella cuyo W estuviese más cerca de los datos de entrada y por lo tanto sería la primera a la que se le intentaría asociar dicho patrón.
La fórmula propuesta por sus creadores[1] es:
- para cada neurona de la capa de salida

donde corresponde a cada una de las neuronas de la capa de entrada. Los índices i serán para las neuronas de la capa de entrada y los subíndices j para las neuronas de la capa de salida.

La selección de la neurona ganadora será como la neurona que obtenga el mayor valor, esto expresado en fórmula es:

Donde J corresponde al índice de la neurona ganadora en F2.
El vector generado en dicha capa serán entonces un vector binario con un único valor en 1 el cual indica la neurona ganadora y dada por:

Fase de comparación
El objetivo es obtener una medida de similitud entre el vector de entrada y el vector prototipo que surge de la capa de salida.
El vector de entrada y el vector producido por los feedback (T) de la neurona ganadora en la capa de salida son comparados en la capa de entrada generando el vector X.
El cálculo del vector X se realiza como sigue.
Sea I el vector de entrada.

O sea, se aplica un AND entre la entrada y el vector de pesos hacia atrás correspondientes a la neurona ganadora de la capa F2.
Si se cumple que la norma de "X" dividida entre la norma de la entrada es mayor o igual que p, entonces se puede concluir que dicha entrada forma parte de la categoría seleccionada y se debe proceder a ajustar los pesos tanto hacia adelante como hacia atrás:

De lo contrario, se envía una señal reinicio, para que inhiba la neurona ganadora y proceda de nuevo la selección de una ganadora, excluyendo la neurona inhibida.
Fase de búsqueda
De no representar la neurona ganadora la categoría del vector de entrada, esta neurona se desactiva y se empieza la búsqueda por otras categorías que ya posea la red. Se repiten entonces los pasos anteriores hasta que se encuentre una neurona ganadora que represente la categoría del vector de entrada.
Si se repitiera el proceso hasta que no quedara ninguna neurona se llegaría a una situación de saturación de la red que podría solucionarse ampliando el número de neuronas de la RNA de forma dinámica.
Diagrama de flujo de una red ART
Modelo de aprendizaje
Un sistema ART básico es un modelo de aprendizaje no supervisado. Normalmente consta de un campo de comparación y un campo de reconocimiento que a su vez se compone de un parámetro de vigilancia y de un módulo de reinicialización. El parámetro de vigilancia tiene una influencia considerable en el sistema: un mayor valor del parámetro de vigilancia produce recuerdos muy detallados, mientras que valores más pequeños de dicho parámetro producirá recuerdos más generales.
El campo de comparación toma un vector de entrada (una matriz bidimensional de valores) y transfiere su mejor coincidencia al campo de reconocimiento. Su mejor coincidencia estará en aquella neurona cuyo conjunto de pesos (vector de peso) se acerque más al vector de entrada. Cada neurona del campo de reconocimiento emite una señal negativa (proporcional a la calidad de coincidencia de dicha neurona con el vector de entrada) para cada una de las neuronas del campo de reconocimiento provocando una inhibición de su valor de salida. De esta manera el campo de reconocimiento exhibe una inhibición lateral, permitiendo que cada neurona en él represente una categoría en la que se clasifican los vectores de entrada. Después de que el vector de entrada es clasificado, el módulo de reinicialización compara la intensidad de la coincidencia encontrada por el campo de reconocimiento con el parámetro de vigilancia. Si el umbral de la vigilancia se cumple, se inicia el entrenamiento. De lo contrario, si el nivel de coincidencia no cumple con el parámetro de vigilancia, la neurona de reconocimiento disparada se inhibe hasta que un vector de entrada se aplique el nuevo.
El entrenamiento se inicia sólo al final del procedimiento de búsqueda, en el cual las neuronas de reconocimiento son desactivadas una a una por la función de reinicio hasta que el parámetro de vigilancia se satisface con una coincidencia de reconocimiento. Si ninguna coincidencia encontrada por las neurona de reconocimiento supera el umbral de vigilancia una neurona no comprometida se ajusta para que concuerde con el vector de entrada.
Entrenamiento
Hay dos métodos básicos de entrenar una red neural ART: lento y rápido. En el método lento el grado de entrenamiento de los pesos de la neurona de reconocimiento hacia el vector de entrada se calcula a valores continuos con ecuaciones diferenciales y por lo tanto depende del tiempo durante el cual el vector de entrada esté presente. Con el método rápido, se utilizan ecuaciones algebraicas para calcular el grado de ajustes de peso, usándose valores binarios. Si bien el aprendizaje rápido es eficaz y eficiente para ciertas tareas, el método de aprendizaje lento es biológicamente posible y puede usarse con redes en tiempo continuo (es decir, cuando el vector de entrada varía de forma continua).
Tipos de ART
ART 1
ART 1[2][3] Es el tipo más sencillo de red ART, sólo acepta entradas binarias.
Trabaja con un operador duro, el cual hace posible las salidas binarias.
Aplicaciones: Reconocimiento de letras y figuras con patrones de colores en blanco y negro.
ART 2
ART 2[4] Aumenta las capacidades de la red al soportar esta valores de entrada continuos.
ART 2-A
ART 2-A[5] es una forma simplificada de ART-2 con un tiempo de ejecución drásticamente acelerado, y con resultados cualitativos que rara vez son inferiores a los obtenidos por una red ART-2 completa
ART 3
ART 3[6] se basa en ART-2 mediante la simulación de rudimentarios neurotransmisores y regulación de actividad sináptica mediante la incorporación de simulaciones de concentraciones de iones de sodio (Na +) y calcio (Ca2+) en las ecuaciones del sistema, lo que origina más realismo en la simulación de las condiciones fisiológicas en las que se disparan las neuronas biológicas.
ART difuso
ART difuso[7] aplica la lógica difusa en el reconocimiento de patrones de ART, aumentando así la generalización. Una opcional y muy útil característica de ART difuso es el complemento de código, una forma de incorporar la ausencia de elementos en las clasificaciones de patrones que sirve para prevenir la creación de categorías ineficientes e innecesarias.
ARTMAP
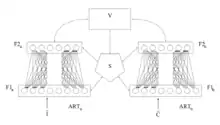
ARTMAP,[1] también conocido como ART Predictivo, combina de unidades de ART-1 o ART-2 ligeramente modificadas formando una estructura de aprendizaje supervisado, donde la primera unidad tiene los datos de entrada y la segunda unidad toma la salida de datos correctos, se utiliza para posibilitar el mínimo ajuste del parámetro de vigilancia en la primera unidad con el fin de obtener una clasificación correcta.
Funcionamiento en entrenamiento de la red ARTMAP con dos redes ART 1:
Se presentan dos representaciones, una para la red ART a y otra para la red ART b, en cada red, el vector de entrada, se multiplica por los pesos Ascendentes (hacia delante) de la capa F1 → F2, con el resultado se busca cual neurona de la capa F2 tiene el valor más grande (ganador se lleva todo), cuando se elige una neurona ganadora esta se multiplica por los pesos descendentes (hacia atrás ) F2 → F1, generando un vector prototipo, este vector prototipo se compara mediante un AND lógico con el vector de entrada, del vector resultante se suman todos los valores que tenga un 1 y esto se divide entre el tamaño de la capa de entrada, con esto se calcula la similitud entre el prototipo y la entrada. Si la similitud es menor la vigilancia entonces se descarta el prototipo, se marca el vector de actividad de la capa F2 de forma que no se contemple la neurona en las próximas elecciones de la neurona ganadora. Esto se repite hasta encontrar un patrón que cumpla con el parámetro de vigilancia. Si se comprueban todas las neuronas y no se encuentra una que cumpla con el parámetro de vigilancia, el vector de entrada se guarda en los pesos descendentes de una neurona libre de prototipos, y se devuelve como prototipo seleccionado. Si un prototipo cumple con el valor de vigilancia se activa la variable del campo de mapeo correspondiente a la red en cuestión. En el campo de mapeo se comprueba hay alguna neurona del campo de mapeo activa, si hay más de una quiere decir que no se cumple la relación entre las dos redes, por lo tanto se debe ajustar el parámetro de vigilancia, para que ese prototipo no cumpla con la vigilancia, se reinicia la red ART a y se vuelve a hacer la búsqueda de prototipos con el nuevo valor de vigilancia. Si se activa solo una neurona entonces quiere decir que el prototipo es adecuado y por lo tanto se debe hacer ajuste de pesos en la red ART a. y se reinician las variables de activación del campo de mapeo con el fin de que la red quede apta para seguir con el entrenamiento.
Funcionamiento en producción de la red ARTMAP con dos redes ART 1:
Se presenta una entrada a la capa F1 de la red Art a como el vector de entrada, se multiplica por los pesos Ascendentes de la capa F1 → F2, con el resultado se busca cual neurona de la capa F2 tiene el valor más grande (ganador se lleva todo), cuando se elige una neurona ganadora esta se multiplica por los pesos descendentes F2 → F1, generando un vector prototipo, este vector prototipo se compara mediante un AND lógico con el vector de entrada, del vector resultante se suman todos los valores que tenga un 1 y esto se divide entre el tamaño de la capa de entrada, con esto se calcula la similitud entre el prototipo y la entrada. Si la similitud es menor la vigilancia entonces se descarta el prototipo, se marca el vector de actividad de la capa F2 de forma que no se contemple la neurona en las próximas elecciones de la neurona ganadora. Esto se repite hasta encontrar un patrón que cumpla con el parámetro de vigilancia. Si no se encuentra la red propone la primera neurona como la ganadora y se ignora el parámetro de vigilancia. Si se encuentra uno que cumpla, este se propaga al campo de mapeo, en el campo de mapeo se propaga hacia la neurona correspondiente en la capa F2 b(recordar el campo de mapeo es 1 a 1 con la capa F2 b), los pesos descendentes de F2 b → F1 b pasan a ser la entrada de la red Art b, la cual se usa como salida del sistema.
ARTMAP difuso
ARTMAP difuso[8] como ARTMAP pero utilizando unidades ART difuso, dando como consecuencia un aumento de la eficacia.
Referencias
- Carpenter, G.A., Grossberg, S., & Reynolds, J.H. (1991), ARTMAP: Supervised real-time learning and classification of nonstationary data by a self-organizing neural network Archivado el 19 de mayo de 2006 en Wayback Machine., Neural Networks (Publication), 4, 565-588
- Carpenter, G.A. & Grossberg, S. (2003), Adaptive Resonance Theory Archivado el 19 de mayo de 2006 en Wayback Machine., In Michael A. Arbib (Ed.), The Handbook of Brain Theory and Neural Networks, Second Edition (pp. 87-90). Cambridge, MA: MIT Press
- Grossberg, S. (1987), Competitive learning: From interactive activation to adaptive resonance Archivado el 7 de septiembre de 2006 en Wayback Machine., Cognitive Science (Publication), 11, 23-63
- Carpenter, G.A. & Grossberg, S. (1987), ART 2: Self-organization of stable category recognition codes for analog input patterns Archivado el 4 de septiembre de 2006 en Wayback Machine., Applied Optics, 26(23), 4919-4930
- Carpenter, G.A., Grossberg, S., & Rosen, D.B. (1991a), ART 2-A: An adaptive resonance algorithm for rapid category learning and recognition Archivado el 19 de mayo de 2006 en Wayback Machine., Neural Networks (Publication), 4, 493-504
- Carpenter, G.A. & Grossberg, S. (1990), ART 3: Hierarchical search using chemical transmitters in self-organizing pattern recognition architectures Archivado el 6 de septiembre de 2006 en Wayback Machine., Neural Networks (Publication), 3, 129-152
- Carpenter, G.A., Grossberg, S., & Rosen, D.B. (1991b), Fuzzy ART: Fast stable learning and categorization of analog patterns by an adaptive resonance system Archivado el 19 de mayo de 2006 en Wayback Machine., Neural Networks (Publication), 4, 759-771
- Carpenter, G.A., Grossberg, S., Markuzon, N., Reynolds, J.H., & Rosen, D.B. (1992), Fuzzy ARTMAP: A neural network architecture for incremental supervised learning of analog multidimensional maps Archivado el 19 de mayo de 2006 en Wayback Machine., IEEE Transactions on Neural Networks, 3, 698-713
Bibliografía
- Wasserman, Philip D. (1989). Neural computing: theory and practice (en inglés). New York: Van Nostrand Reinhold. ISBN 0-442-20743-3.
- Freedman, David H. (1996). «Capítulo 3: El Arte del pensamiento». Hacedores de cerebros. (url con vista previa restringida). Editorial Andres Bello. pp. 83-130. ISBN 956-13-1324-3.
- Carpenter, G.A.; Grossberg, S. (1986). «Absolutely stable learning of recognition codes by a self-organizing neural network». Conference Proceedings 151: Neural Networks for Computing, 77-85. American Institute of Physic (AIP).
Enlaces externos
Sitio web de Stephen Grossberg.
BU Cognitive and Neural Systems Technology Lab
Implementación de ART para aprendizaje no supervisado (ART 1, ART 2A, ART 2A-C y ART distance) puede encontrarse en el sitio https://web.archive.org/web/20110728163234/http://users.visualserver.org/xhudik/art/
| Control de autoridades |
|
|---|
 Datos: Q352487
Datos: Q352487